Kopiera data till Azure Data Explorer med hjälp av Azure Data Factory
Viktigt
Den här anslutningsappen kan användas i Realtidsanalys i Microsoft Fabric. Använd anvisningarna i den här artikeln med följande undantag:
- Om det behövs skapar du databaser med hjälp av anvisningarna i Skapa en KQL-databas.
- Om det behövs skapar du tabeller med hjälp av anvisningarna i Skapa en tom tabell.
- Hämta fråge- eller inmatnings-URI:er med hjälp av anvisningarna i Kopiera URI.
- Kör frågor i en KQL-frågeuppsättning.
Azure Data Explorer är en snabb, fullständigt hanterad dataanalystjänst. Den erbjuder realtidsanalys på stora mängder data som strömmas från många källor, till exempel program, webbplatser och IoT-enheter. Med Azure Data Explorer kan du iterativt utforska data och identifiera mönster och avvikelser för att förbättra produkter, förbättra kundupplevelser, övervaka enheter och öka åtgärder. Det hjälper dig att utforska nya frågor och få svar på några minuter.
Azure Data Factory är en fullständigt hanterad, molnbaserad dataintegreringstjänst. Du kan använda den för att fylla i din Azure Data Explorer-databas med data från ditt befintliga system. Det kan hjälpa dig att spara tid när du skapar analyslösningar.
När du läser in data i Azure Data Explorer ger Data Factory följande fördelar:
- Enkel installation: Hämta en intuitiv guide i fem steg utan att skript krävs.
- Stöd för omfattande datalager: Få inbyggt stöd för en omfattande uppsättning lokala och molnbaserade datalager. En detaljerad lista finns i tabellen med datalager som stöds.
- Säker och kompatibel: Data överförs via HTTPS eller Azure ExpressRoute. Den globala tjänstnärvaron säkerställer att dina data aldrig lämnar den geografiska gränsen.
- Höga prestanda: Datainläsningshastigheten är upp till 1 gigabyte per sekund (GBIT/s) till Azure Data Explorer. Mer information finns i aktiviteten Kopiera prestanda.
I den här artikeln använder du verktyget Data Factory Copy Data för att läsa in data från Amazon Simple Storage Service (S3) till Azure Data Explorer. Du kan följa en liknande process för att kopiera data från andra datalager, till exempel:
Förutsättningar
- En Azure-prenumeration. Skapa ett kostnadsfritt Azure-konto.
- Ett Azure Data Explorer-kluster och en databas. Skapa ett kluster och en databas.
- En datakälla.
Skapa en datafabrik
Logga in på Azure-portalen.
I den vänstra rutan väljer du Skapa enresursanalysdatafabrik>>.

I fönstret Ny datafabrik anger du värden för fälten i följande tabell:
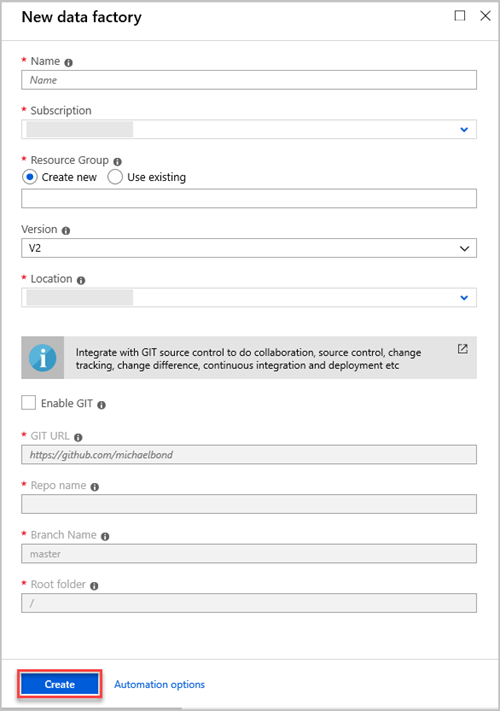
Inställning Värde att ange Namn I rutan anger du ett globalt unikt namn för datafabriken. Om du får ett fel är datafabriksnamnet "LoadADXDemo" inte tillgängligt. Ange ett annat namn för datafabriken. Regler för namngivning av Data Factory-artefakter finns i Namngivningsregler för Data Factory. Prenumeration I listrutan väljer du den Azure-prenumeration där datafabriken ska skapas. Resursgrupp Välj Skapa ny och ange sedan namnet på en ny resursgrupp. Om du redan har en resursgrupp väljer du Använd befintlig. Version I listrutan väljer du V2. Plats I listrutan väljer du platsen för datafabriken. Endast platser som stöds visas i listan. De datalager som används av datafabriken kan finnas på andra platser eller regioner. Välj Skapa.
Om du vill övervaka skapandeprocessen väljer du Meddelanden i verktygsfältet. När du har skapat datafabriken väljer du den.
Fönstret Datafabrik öppnas.
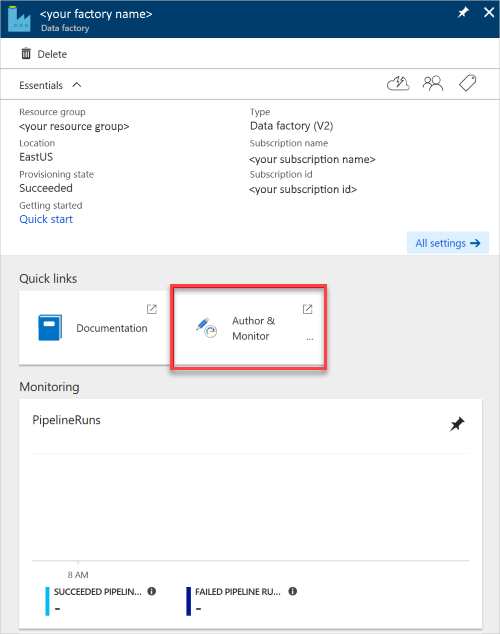
Om du vill öppna programmet i ett separat fönster väljer du panelen Författare & Övervakare .
Läs in data i Azure Data Explorer
Du kan läsa in data från många typer av datalager till Azure Data Explorer. Den här artikeln beskriver hur du läser in data från Amazon S3.
Du kan läsa in dina data på något av följande sätt:
- I det Azure Data Factory användargränssnittet går du till den vänstra rutan och väljer ikonen Författare. Detta visas i avsnittet "Skapa en datafabrik" i Skapa en datafabrik med hjälp av Azure Data Factory användargränssnitt.
- I verktyget Azure Data Factory Kopiera data, som du ser i Använd verktyget Kopiera data för att kopiera data.
Kopiera data från Amazon S3 (källa)
I fönstret Kom igång öppnar du verktyget Kopiera data genom att välja Kopiera data.
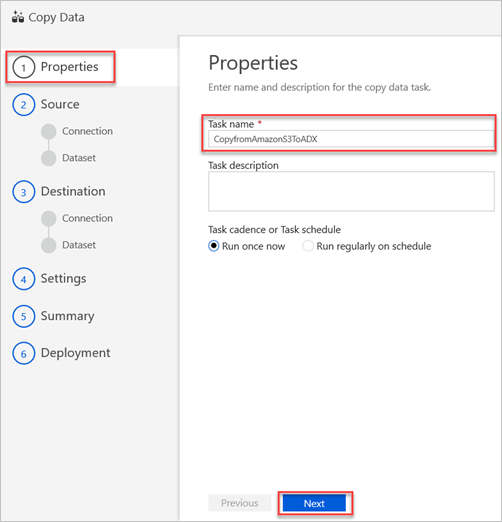
I fönstret Egenskaper i rutan Aktivitetsnamn anger du ett namn och väljer sedan Nästa.
I fönstret Källdatalager väljer du Skapa ny anslutning.
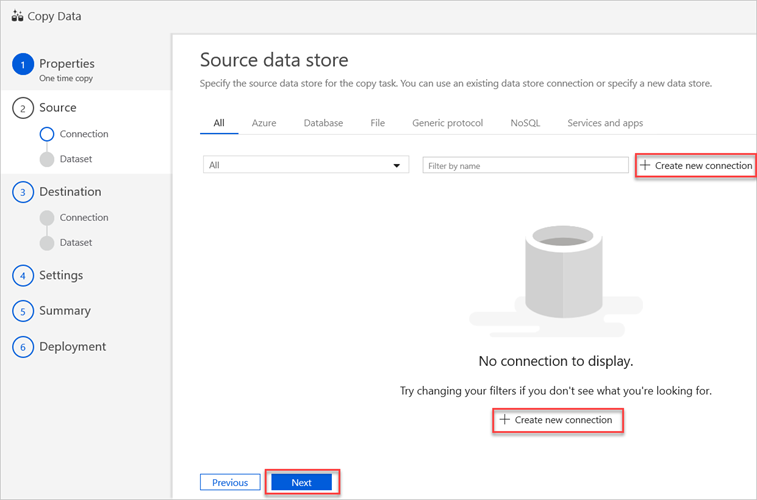
Välj Amazon S3 och välj sedan Fortsätt.
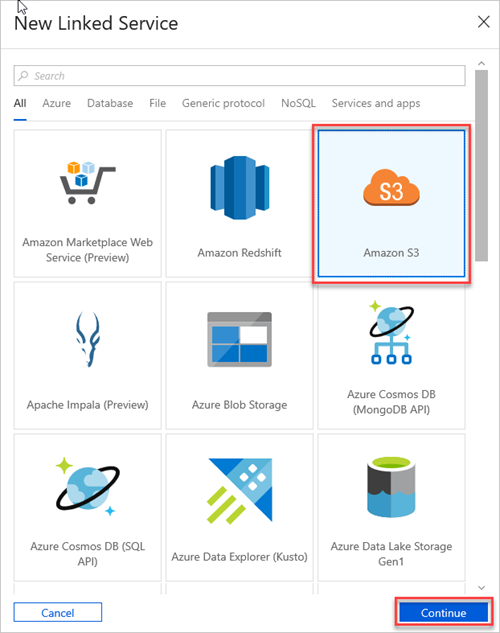
Gör följande i fönstret Ny länkad tjänst (Amazon S3 ):
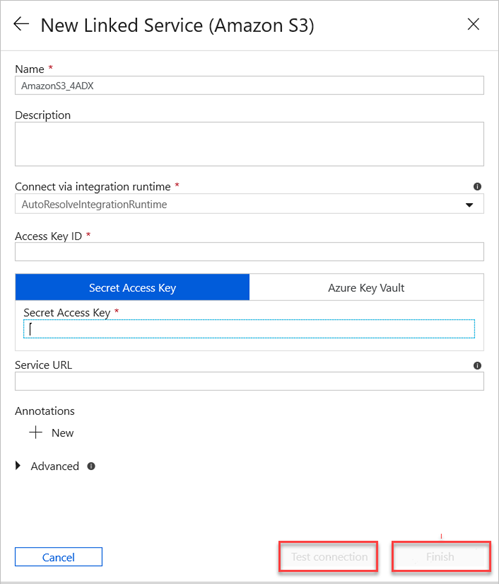
a. I rutan Namn anger du namnet på den nya länkade tjänsten.
b. I listrutan Anslut via integrationskörning väljer du värdet.
c. I rutan Åtkomstnyckel-ID anger du värdet.
Anteckning
I Amazon S3 letar du upp din åtkomstnyckel, väljer ditt Amazon-användarnamn i navigeringsfältet och väljer sedan Mina säkerhetsautentiseringsuppgifter.
d. I rutan Hemlig åtkomstnyckel anger du ett värde.
e. Om du vill testa den länkade tjänstanslutningen som du skapade väljer du Testa anslutning.
f. Välj Slutför.
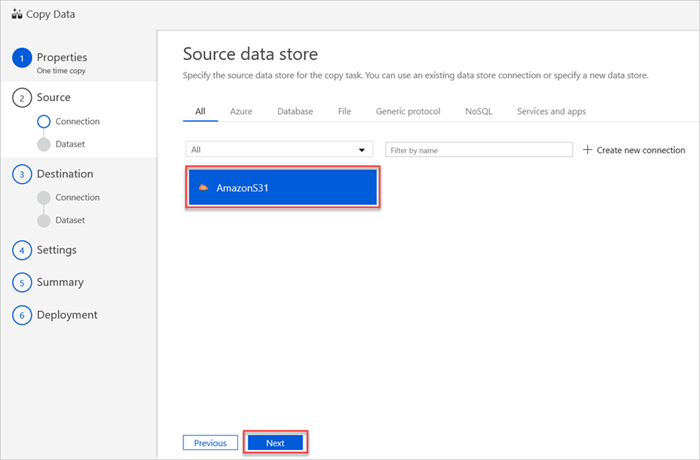
Fönstret Källdatalager visar din nya AmazonS31-anslutning.
Välj Nästa.
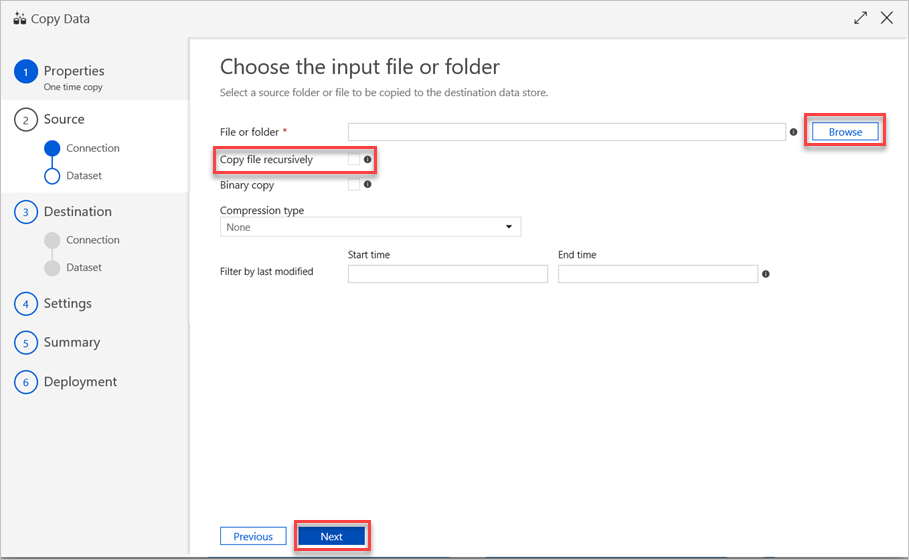
Gör följande i fönstret Välj indatafil eller mapp :
a. Bläddra till den fil eller mapp som du vill kopiera och välj den sedan.
b. Välj det kopieringsbeteende som du vill använda. Kontrollera att kryssrutan Binär kopia är avmarkerad.
c. Välj Nästa.
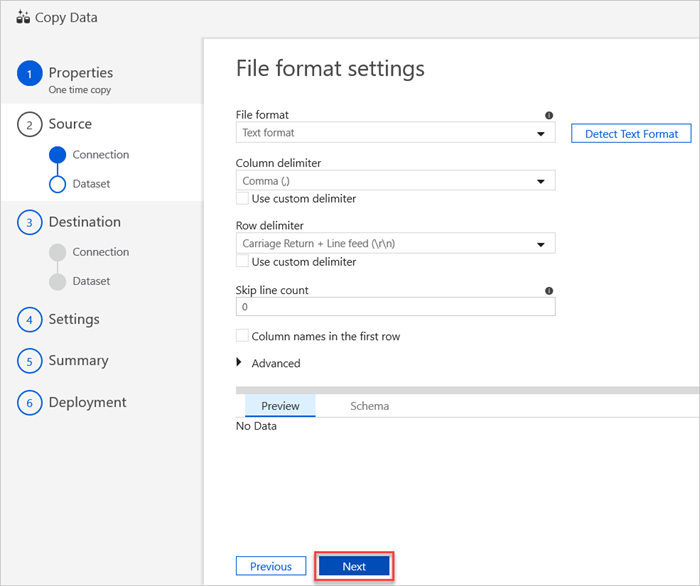
I fönstret Inställningar för filformat väljer du relevanta inställningar för filen. och välj sedan Nästa.
Kopiera data till Azure Data Explorer (mål)
Den nya länkade Azure Data Explorer-tjänsten skapas för att kopiera data till den Azure Data Explorer måltabell (mottagare) som anges i det här avsnittet.
Anteckning
Använd Azure Data Factory-kommandoaktiviteten för att köra Azure Data Explorer-hanteringskommandon och använda någon av inmatningarna från frågekommandon, till exempel .set-or-replace.
Skapa den länkade Azure Data Explorer-tjänsten
Gör följande för att skapa den länkade Azure Data Explorer-tjänsten:
Om du vill använda en befintlig datalageranslutning eller ange ett nytt datalager går du till fönstret Måldatalager och väljer Skapa ny anslutning.
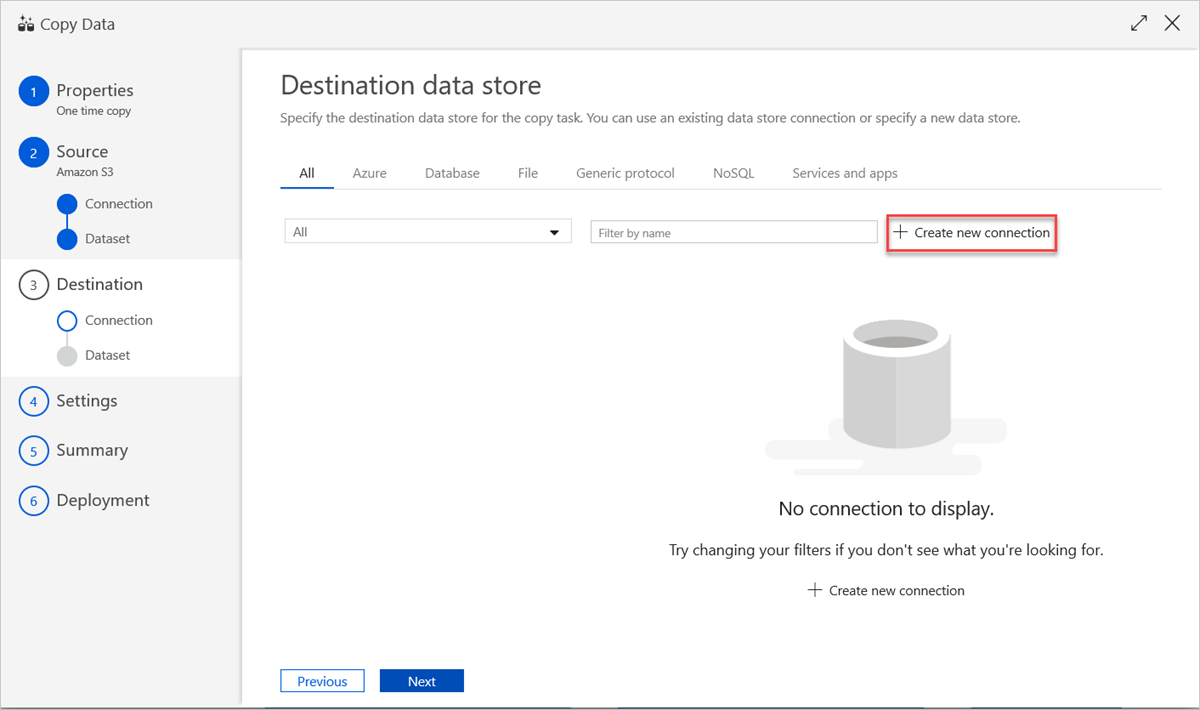
I fönstret Ny länkad tjänst väljer du Azure Data Explorer och sedan Fortsätt.

I fönstret Ny länkad tjänst (Azure Data Explorer) gör du följande:
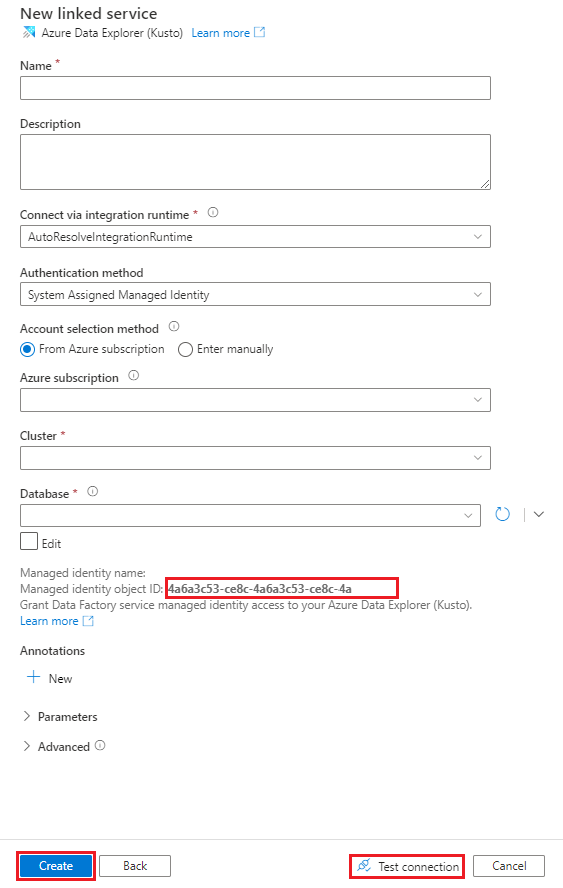
I rutan Namn anger du ett namn för den länkade Azure Data Explorer-tjänsten.
Under Autentiseringsmetod väljer du Systemtilldelad hanterad identitet eller tjänstens huvudnamn.
Om du vill autentisera med en hanterad identitet beviljar du den hanterade identiteten åtkomst till databasen med hjälp av det hanterade identitetsnamnet eller objekt-ID:t för hanterad identitet.
Så här autentiserar du med tjänstens huvudnamn:
- I rutan Klientorganisation anger du klientorganisationens namn.
- I rutan Tjänstens huvudnamns-ID anger du tjänstens huvudnamns-ID.
- Välj Nyckeln för tjänstens huvudnamn och ange sedan värdet för nyckeln i rutan Tjänstens huvudnamn .
Anteckning
- Tjänstens huvudnamn används av Azure Data Factory för åtkomst till Azure Data Explorer-tjänsten. Om du vill skapa ett huvudnamn för tjänsten går du till skapa ett Microsoft Entra tjänstens huvudnamn.
- Information om hur du tilldelar behörigheter till en hanterad identitet eller ett tjänsthuvudnamn eller finns i Hantera behörigheter.
- Använd inte metoden Azure Key Vault eller användartilldelad hanterad identitet.
Under Metod för kontoval väljer du något av följande alternativ:
Välj Från Azure-prenumeration och välj sedan din Azure-prenumeration och ditt kluster i listrutorna.
Anteckning
- Listrutan Kluster visar endast kluster som är associerade med din prenumeration.
- Klustret måste ha rätt SKU för bästa prestanda.
Välj Ange manuellt och ange sedan slutpunkten.
I listrutan Databas väljer du ditt databasnamn. Du kan också markera kryssrutan Redigera och sedan ange databasnamnet.
Om du vill testa den länkade tjänstanslutningen som du skapade väljer du Testa anslutning. Om du kan ansluta till den länkade tjänsten visar fönstret en grön bockmarkering och ett meddelande om att anslutningen lyckades .
Om du vill testa den länkade tjänstanslutningen som du skapade väljer du Testa anslutning. Om du kan ansluta till den länkade tjänsten visar fönstret en grön bockmarkering och ett meddelande om att anslutningen lyckades .
Välj Skapa för att slutföra skapandet av den länkade tjänsten.
Konfigurera Azure Data Explorer-dataanslutning
När du har skapat den länkade tjänstanslutningen öppnas fönstret Måldatalager och anslutningen som du skapade är tillgänglig för användning. Utför följande steg för att konfigurera anslutningen:
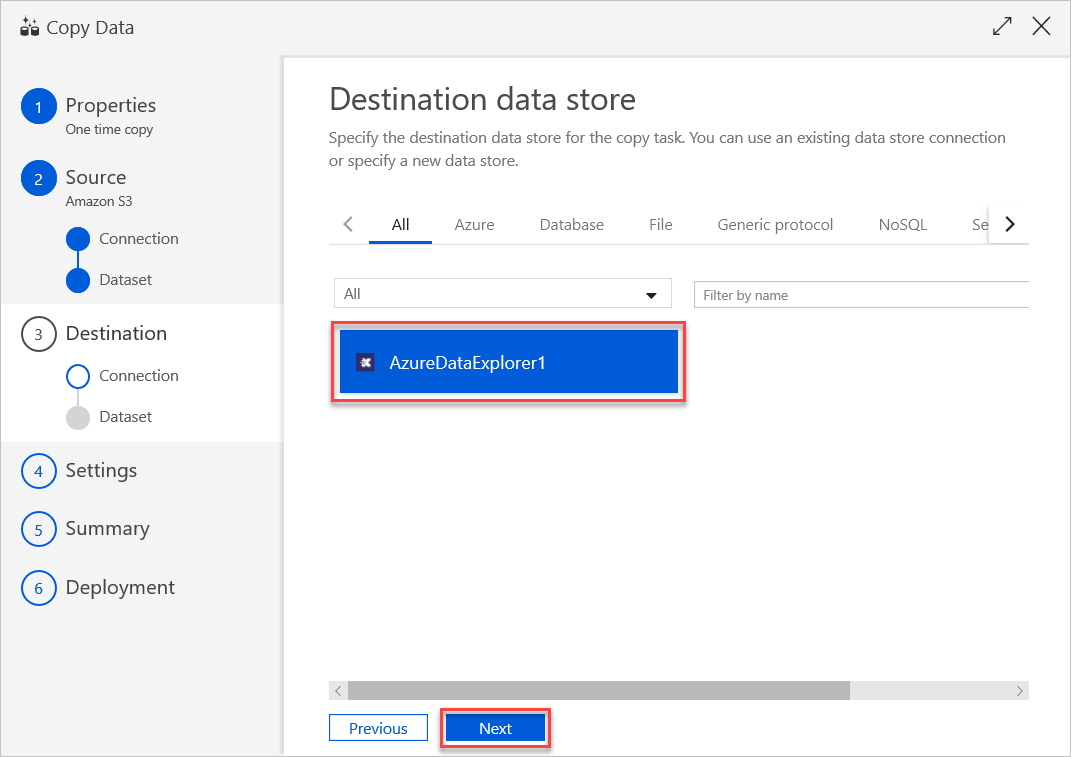
Välj Nästa.
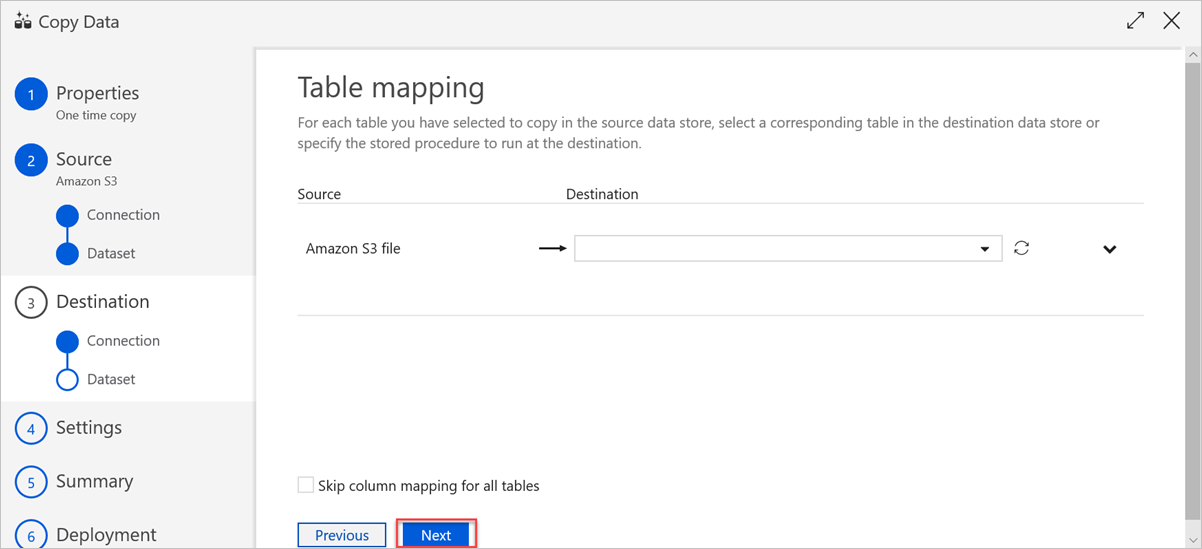
I fönstret Tabellmappning anger du måltabellnamnet och väljer sedan Nästa.
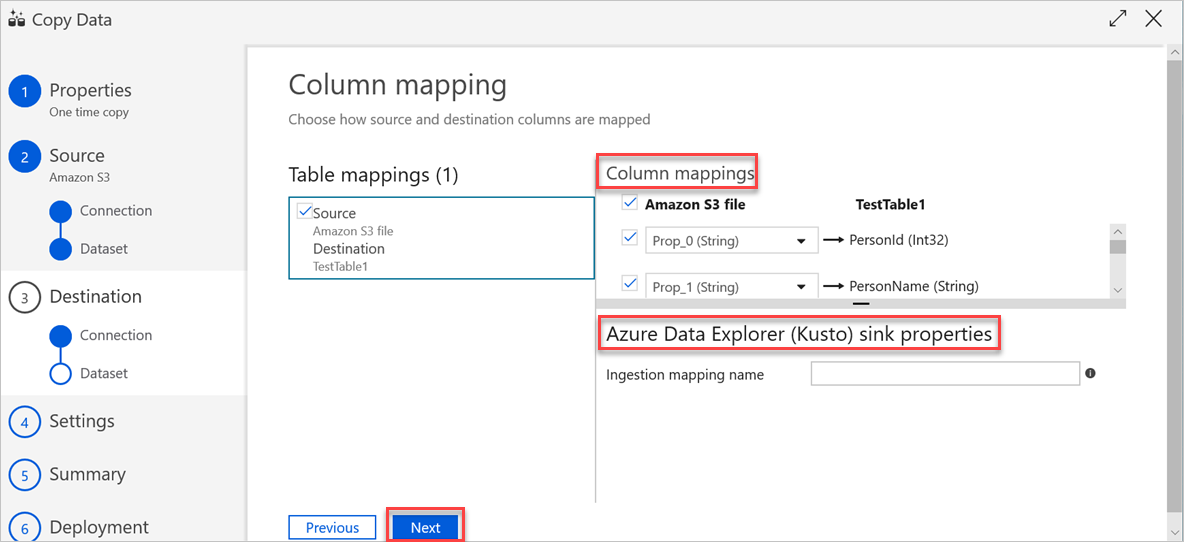
I fönstret Kolumnmappning sker följande mappningar:
a. Den första mappningen utförs av Azure Data Factory enligt Azure Data Factory schemamappning. Gör följande:
Ange kolumnmappningar för Azure Data Factory måltabell. Standardmappningen visas från källa till Azure Data Factory måltabell.
Avbryt valet av kolumner som du inte behöver definiera din kolumnmappning.
b. Den andra mappningen sker när dessa tabelldata matas in i Azure Data Explorer. Mappningen utförs enligt CSV-mappningsregler. Även om källdata inte är i CSV-format konverterar Azure Data Factory data till tabellformat. Därför är CSV-mappning den enda relevanta mappningen i det här skedet. Gör följande:
(Valfritt) Under Egenskaper för Azure Data Explorer -mottagare (Kusto) lägger du till det relevanta inmatningsmappningsnamnet så att kolumnmappning kan användas.
Om inmatningsmappningsnamnet inte har angetts används den by-name-mappningsordning som definieras i avsnittet Kolumnmappningar . Om det inte går att mappa efter namn försöker Azure Data Explorer mata in data i en placeringsordning efter kolumn (d.a. mappas efter position som standard).
Välj Nästa.
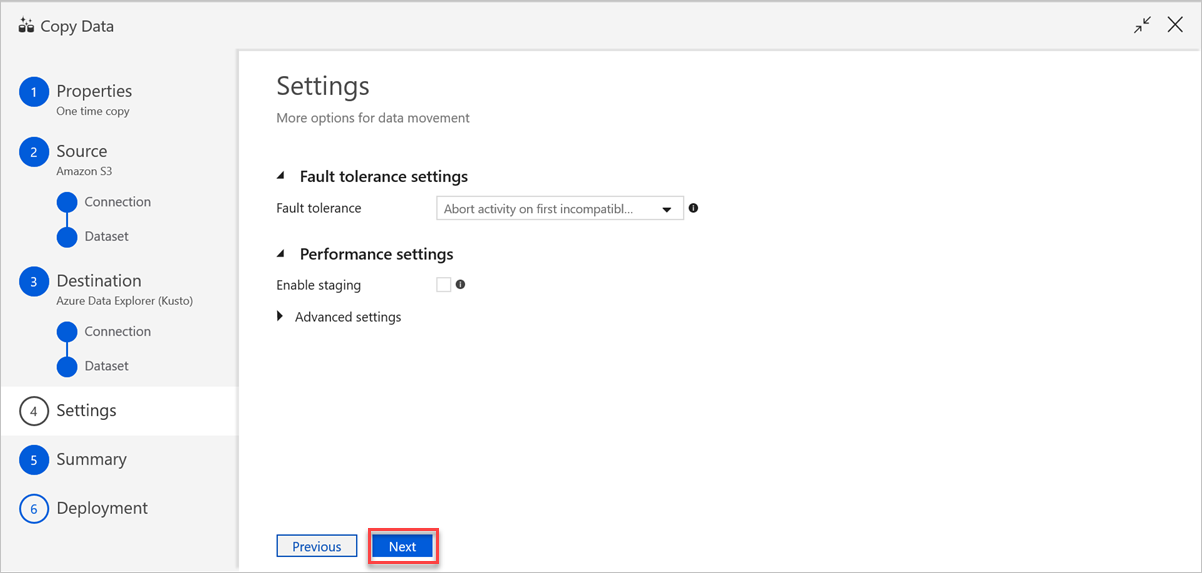
Gör följande i fönstret Inställningar :
a. Under Feltoleransinställningar anger du relevanta inställningar.
b. Under Prestandainställningar gäller inte Aktivera mellanlagring och Avancerade inställningar innehåller kostnadsöverväganden. Om du inte har några specifika krav lämnar du de här inställningarna som de är.
c. Välj Nästa.
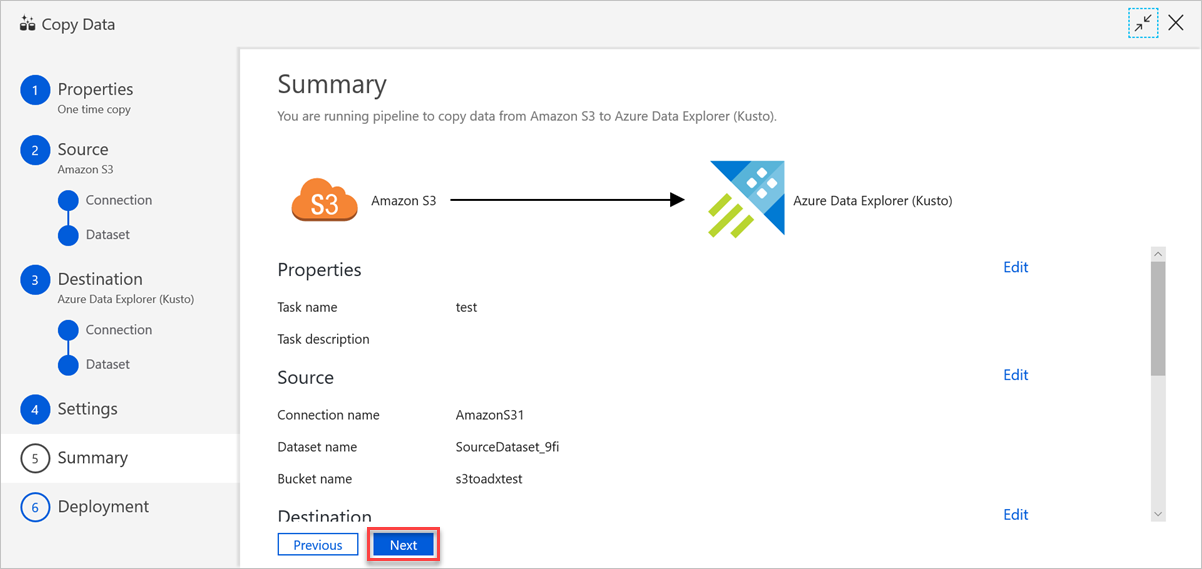
Granska inställningarna i fönstret Sammanfattning och välj sedan Nästa.
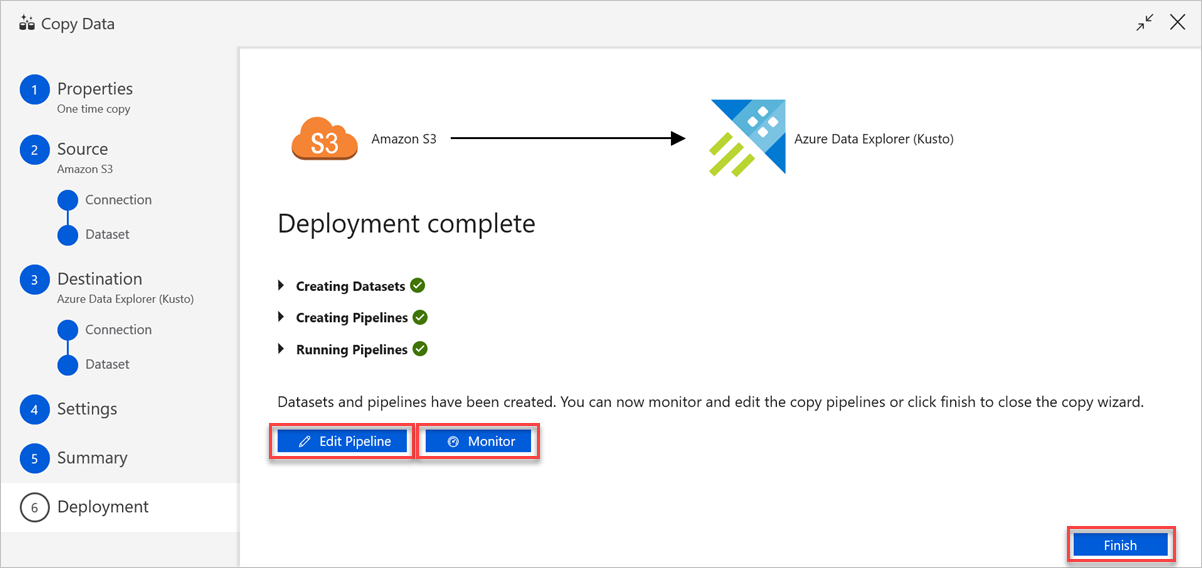
Gör följande i fönstret Distributionen är klar :
a. Om du vill växla till fliken Övervaka och visa status för pipelinen (dvs. förlopp, fel och dataflöde) väljer du Övervaka.
b. Om du vill redigera länkade tjänster, datauppsättningar och pipelines väljer du Redigera pipeline.
c. Välj Slutför för att slutföra kopieringsdataaktiviteten.
Relaterat innehåll
- Läs mer om Azure Data Explorer-anslutningsappen för Azure Data Factory.
- Redigera länkade tjänster, datauppsättningar och pipelines i Data Factory-användargränssnittet.
- Fråga efter data i Azure Data Explorer-webbgränssnittet.