hll_merge() (sammansättningsfunktion)
Sammanfogar HLL-resultat i gruppen till ett enda HLL-värde.
Anteckning
Den här funktionen används tillsammans med sammanfattningsoperatorn.
Mer information finns i den underliggande algoritmen (HyperLogLog) och uppskattningsprecision.
Viktigt
Resultatet av hll(), hll_if() och hll_merge() kan lagras och hämtas senare. Du kanske till exempel vill skapa en daglig sammanfattning av unika användare, som sedan kan användas för att beräkna veckoantal. Den exakta binära representationen av dessa resultat kan dock ändras med tiden. Det finns ingen garanti för att dessa funktioner ger identiska resultat för identiska indata, och därför rekommenderar vi inte att du förlitar oss på dem.
Syntax
hll_merge(Hll)
Läs mer om syntaxkonventioner.
Parametrar
| Namn | Typ | Obligatorisk | Beskrivning |
|---|---|---|---|
| Hll | string |
✔️ | Kolumnnamnet som innehåller HLL-värden som ska sammanfogas. |
Returer
Funktionen returnerar de sammanfogade HLL-värdena för hll i gruppen.
Tips
Använd funktionen dcount_hll för att beräkna aggregeringsfunktionerna dcount från hll() och hll_merge().
Exempel
I följande exempel visas HLL-resultat i en grupp som sammanfogats till ett enda HLL-värde.
StormEvents
| summarize hllRes = hll(DamageProperty) by bin(StartTime,10m)
| summarize hllMerged = hll_merge(hllRes)
Resultat
Resultaten visar endast de fem första resultaten i matrisen.
| hllMerged |
|---|
| [[1024,14],["-6903255281122589438","-7413697181929588220","-2396604341988936699","5824198135224880646","-6257421034880415225", ...],[]] |
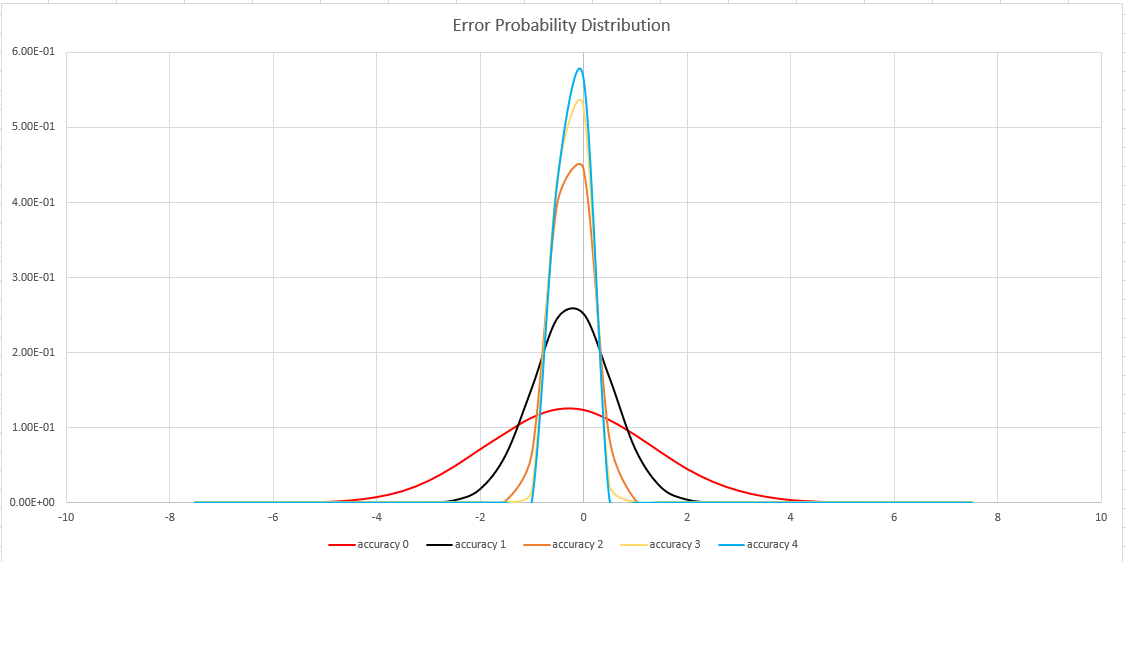
Uppskattningsnoggrannhet
Den här funktionen använder en variant av algoritmen HyperLogLog (HLL), som gör en stokastisk uppskattning av ange kardinalitet. Algoritmen tillhandahåller en "knopp" som kan användas för att balansera noggrannhet och körningstid per minnesstorlek:
| Noggrannhet | Fel (%) | Antal poster |
|---|---|---|
| 0 | 1.6 | 212 |
| 1 | 0,8 | 214 |
| 2 | 0,4 | 216 |
| 3 | 0,28 | 217 |
| 4 | 0,2 | 218 |
Anteckning
Kolumnen "antal poster" är antalet 1 byte-räknare i HLL-implementeringen.
Algoritmen innehåller vissa bestämmelser för att göra ett perfekt antal (noll fel), om den inställda kardinaliteten är tillräckligt liten:
- När noggrannhetsnivån är
1returneras 1 000 värden - När noggrannhetsnivån är
2returneras 8 000 värden
Felgränsen är probabilistisk, inte en teoretisk gräns. Värdet är standardavvikelsen för felfördelningen (sigma), och 99,7 % av uppskattningarna kommer att ha ett relativt fel på under 3 x sigma.
Följande bild visar sannolikhetsfördelningsfunktionen för det relativa uppskattningsfelet i procent för alla noggrannhetsinställningar som stöds:
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för