Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
När dataflöden skrivs till mottagare sker alla anpassade partitioneringar omedelbart före skrivning. Precis som källan rekommenderar vi i de flesta fall att du behåller Använd aktuell partitionering som det valda partitionsalternativet. Partitionerade data skriver mycket snabbare än icke-partitionerade data, inte ens målet partitioneras. Följande är de enskilda övervägandena för olika mottagartyper.
Azure SQL Database-mottagare
Med Azure SQL Database bör standardpartitioneringen fungera i de flesta fall. Det finns en risk att mottagaren har för många partitioner för SQL-databasen att hantera. Om du stöter på det här minskar du antalet partitioner som matas ut av SQL Database-mottagaren.
Bästa praxis för att ta bort rader i mottagare baserat på saknade rader i källan
Här är en videogenomgång om hur du använder dataflöden med finns, ändrar rad- och mottagartransformeringar för att uppnå det här vanliga mönstret:
Effekten av felradshantering för prestanda
När du aktiverar felradshantering ("fortsätt vid fel") i mottagaromvandlingen tar tjänsten ett extra steg innan du skriver de kompatibla raderna till måltabellen. Det här extra steget har en liten prestandastraff som kan ligga i intervallet 5 % som lagts till för det här steget med en extra liten prestandaträff som också läggs till om du anger alternativet att också skriva de inkompatibla raderna till en loggfil.
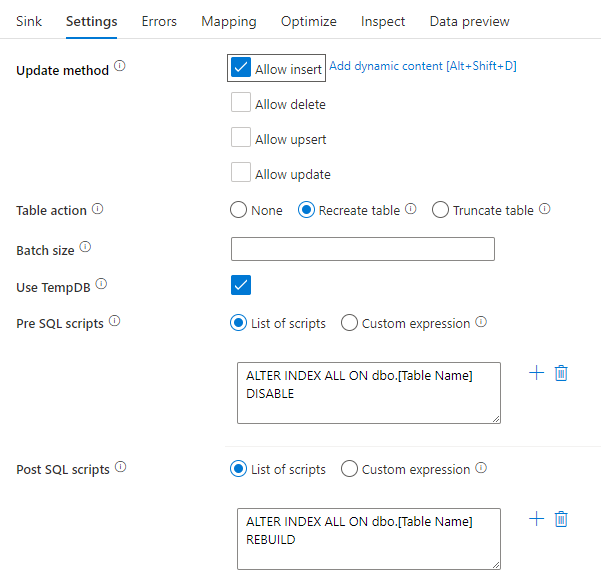
Inaktivera index med hjälp av ett SQL-skript
Om du inaktiverar index före en inläsning i en SQL-databas kan du avsevärt förbättra skrivningsprestandan till tabellen. Kör kommandot nedan innan du skriver till DIN SQL-mottagare.
ALTER INDEX ALL ON dbo.[Table Name] DISABLE
När skrivning har slutförts återskapar du indexen med hjälp av följande kommando:
ALTER INDEX ALL ON dbo.[Table Name] REBUILD
Båda dessa kan göras internt med hjälp av pre- och post-SQL-skript i en Azure SQL Database- eller Synapse-mottagare i mappning av dataflöden.
Varning
När du inaktiverar index tar dataflödet effektivt kontroll över en databas och frågor kommer sannolikt inte att lyckas just nu. Därför utlöses många ETL-jobb mitt i natten för att undvika den här konflikten. Mer information finns i begränsningarna för att inaktivera SQL-index
Skala upp databasen
Schemalägg en storleksändring av din käll- och mottagar-Azure SQL DB och DW innan pipelinekörningen för att öka dataflödet och minimera Azure-begränsningen när du når DTU-gränserna. När pipelinekörningen är klar ändrar du storlek på databaserna till den normala körningshastigheten.
Azure Synapse Analytics-mottagare
När du skriver till Azure Synapse Analytics kontrollerar du att Aktivera mellanlagring är inställt på sant. På så sätt kan tjänsten skriva med hjälp av SQL COPY-kommandot, som effektivt läser in data i bulk. Du måste referera till ett Azure Data Lake Storage gen2- eller Azure Blob Storage-konto för mellanlagring av data när du använder mellanlagring.
Förutom mellanlagring gäller samma metodtips för Azure Synapse Analytics som Azure SQL Database.
Filbaserade mottagare
Även om dataflöden stöder olika filtyper rekommenderas Det Spark-inbyggda Parquet-formatet för optimala läs- och skrivtider.
Om data är jämnt fördelade är Använd aktuell partitionering det snabbaste partitioneringsalternativet för att skriva filer.
Alternativ för filnamn
När du skriver filer har du ett val av namngivningsalternativ som var och en påverkar prestandan.
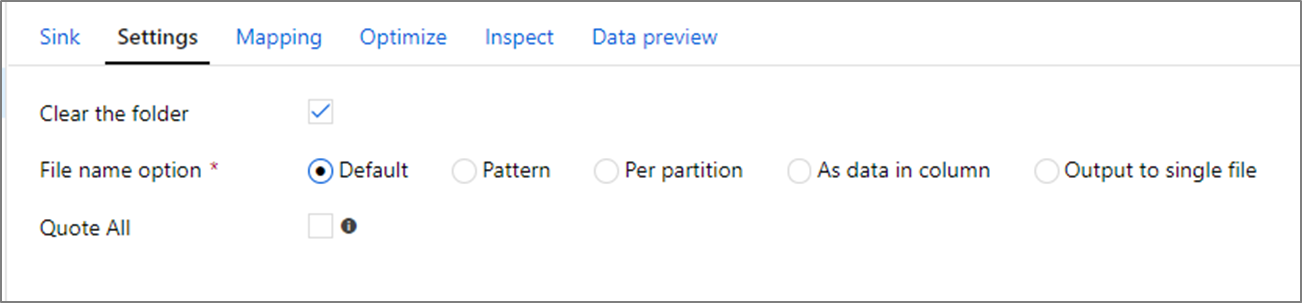
Om du väljer alternativet Standard skrivs det snabbaste alternativet. Varje partition motsvarar en fil med standardnamnet Spark. Det här är användbart om du bara läser från datamappen.
Om du anger ett namnmönster byts namn på varje partitionsfil till ett mer användarvänligt namn. Den här åtgärden sker efter skrivning och är något långsammare än att välja standardinställningen.
Med varje partition kan du namnge varje enskild partition manuellt.
Om en kolumn motsvarar hur du vill mata ut data kan du välja Namnfil som kolumndata. Detta omdelar data och kan påverka prestanda om kolumnerna inte är jämnt fördelade.
Om en kolumn motsvarar hur du vill generera mappnamn väljer du Namnmapp som kolumndata.
Utdata till en enskild fil kombinerar alla data till en enda partition. Detta leder till långa skrivtider, särskilt för stora datamängder. Det här alternativet rekommenderas inte om det inte finns en uttrycklig affärsorsak att använda det.
Azure Cosmos DB-mottagare
När du skriver till Azure Cosmos DB kan du förbättra prestandan genom att ändra dataflöde och batchstorlek under dataflödeskörningen. Dessa ändringar börjar gälla endast under körningen av dataflödesaktiviteten och återgår till de ursprungliga samlingsinställningarna efter avslutningen.
Batchstorlek: Vanligtvis räcker det att börja med standard batchstorleken. Om du vill justera det här värdet ytterligare beräknar du den grova objektstorleken för dina data och kontrollerar att objektstorleken * batchstorleken är mindre än 2 MB. I så fall kan du öka batchstorleken för att få bättre dataflöde.
Dataflöde: Ange en inställning för högre dataflöde här så att dokument kan skriva snabbare till Azure Cosmos DB. Tänk på de högre RU-kostnaderna baserat på en inställning för högt dataflöde.
Budget för skrivdataflöde: Använd ett värde som är mindre än totalt antal RU:er per minut. Om du har ett dataflöde med ett stort antal Spark-partitioner ger ett budgetgenomflöde mer balans mellan dessa partitioner.
Relaterat innehåll
- Översikt över dataflödesprestanda
- Optimera källor
- Optimera transformeringar
- Använda dataflöden i pipelines
Se andra Dataflöde artiklar om prestanda: