Optimera källor
För alla källor utom Azure SQL Database rekommenderar vi att du behåller Använd aktuell partitionering som valt värde. När du läser från alla andra källsystem partitionerar dataflöden automatiskt data jämnt baserat på datastorleken. En ny partition skapas för ungefär var 128 MB data. När datastorleken ökar ökar antalet partitioner.
All anpassad partitionering sker när Spark har läst in data och negativt påverkar dataflödesprestandan. Eftersom data är jämnt partitionerade vid läsning rekommenderas inte om du inte först förstår dina datas form och kardinalitet.
Kommentar
Läshastigheter kan begränsas av dataflödet i källsystemet.
Azure SQL Database-källor
Azure SQL Database har ett unikt partitioneringsalternativ som kallas källpartitionering. Om du aktiverar källpartitionering kan du förbättra lästiderna från Azure SQL Database genom att aktivera parallella anslutningar i källsystemet. Ange antalet partitioner och hur du partitionera dina data. Använd en partitionskolumn med hög kardinalitet. Du kan också ange en fråga som matchar partitioneringsschemat i källtabellen.
Dricks
För källpartitionering är I/O för SQL Server flaskhalsen. Om du lägger till för många partitioner kan källdatabasen bli mättad. Vanligtvis är fyra eller fem partitioner idealiska när du använder det här alternativet.
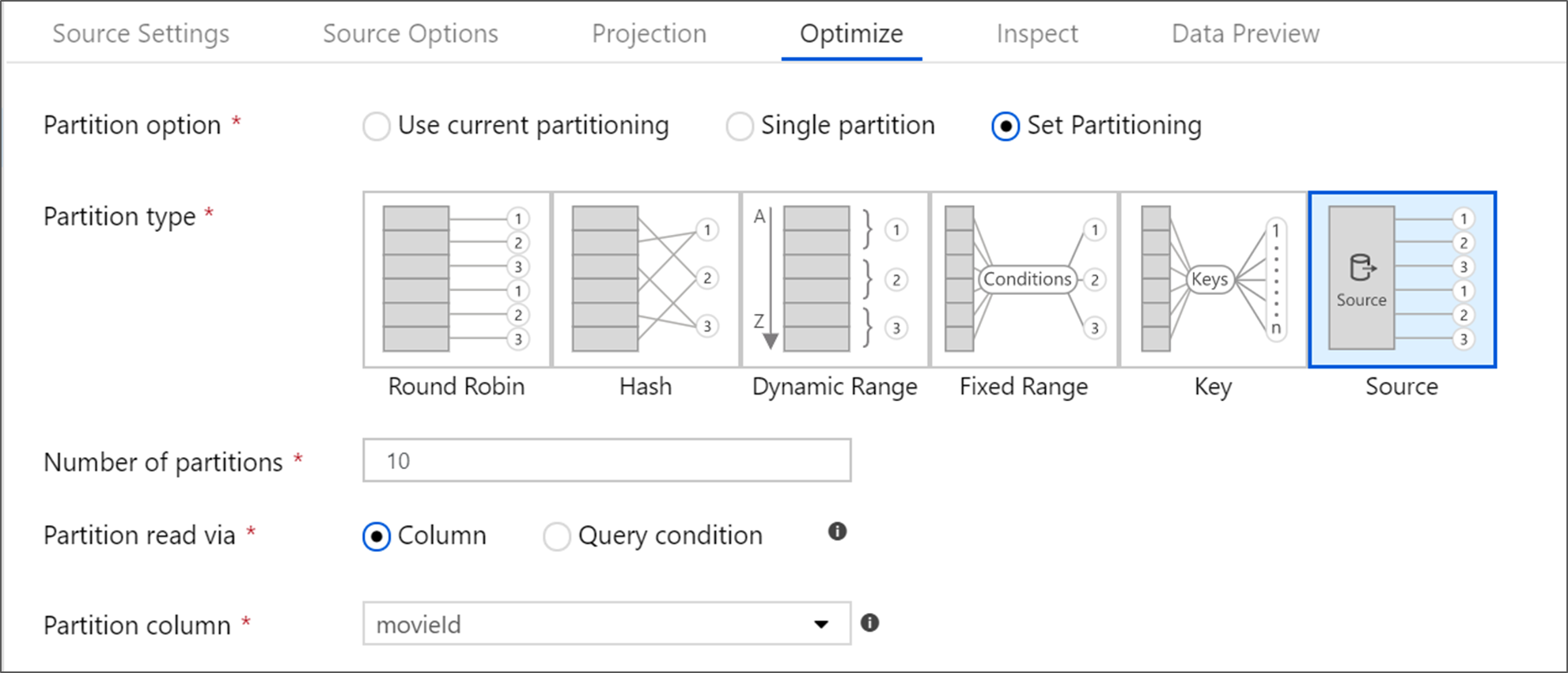
Isoleringsnivå
Isoleringsnivån för läsningen i ett Azure SQL-källsystem påverkar prestanda. Om du väljer "Läs obekräftade" får du den snabbaste prestandan och förhindrar databaslås. Mer information om SQL-isoleringsnivåer finns i Förstå isoleringsnivåer.
Läsa med hjälp av fråga
Du kan läsa från Azure SQL Database med hjälp av en tabell eller en SQL-fråga. Om du kör en SQL-fråga måste frågan slutföras innan omvandlingen kan starta. SQL-frågor kan vara användbara för att push-överföra åtgärder som kan köras snabbare och minska mängden data som lästs från en SQL Server, till exempel SELECT-, WHERE- och JOIN-instruktioner. När du trycker ned åtgärder förlorar du möjligheten att spåra ursprung och prestanda för transformeringar innan data kommer in i dataflödet.
Azure Synapse Analytics-källor
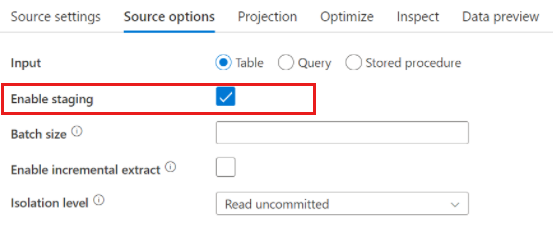
När du använder Azure Synapse Analytics finns en inställning med namnet Aktivera mellanlagring i källalternativen. På så sätt kan tjänsten läsa från Synapse med hjälp av Staging, vilket avsevärt förbättrar läsprestandan med hjälp av den mest högpresterande massinläsningsfunktionen, till exempel CETAS- och COPY-kommandot. Om du aktiverar Staging måste du ange en Mellanlagringsplats för Azure Blob Storage eller Azure Data Lake Storage gen2 i inställningarna för dataflödesaktivitet.
Filbaserade källor
Parquet kontra avgränsad text
Även om dataflöden stöder olika filtyper rekommenderas Det Spark-inbyggda Parquet-formatet för optimala läs- och skrivtider.
Om du kör samma dataflöde på en uppsättning filer rekommenderar vi att du läser från en mapp, använder sökvägar med jokertecken eller läser från en lista med filer. En enda dataflödesaktivitetskörning kan bearbeta alla dina filer i batch. Mer information om hur du konfigurerar de här inställningarna finns i avsnittet Källomvandling i dokumentationen för Azure Blob Storage-anslutningsappen.
Undvik om möjligt att använda aktiviteten For-Each för att köra dataflöden över en uppsättning filer. Detta gör att varje iteration av för-var och en startar sitt eget Spark-kluster, vilket ofta inte är nödvändigt och kan vara dyrt.
Infogade datauppsättningar jämfört med delade datauppsättningar
ADF- och Synapse-datauppsättningar är delade resurser i dina fabriker och arbetsytor. Men när du läser ett stort antal källmappar och filer med avgränsad text och JSON-källor kan du förbättra prestandan för identifiering av dataflödesfiler genom att ange alternativet "Användarprojekterat schema" i Projektion | Dialogrutan Schemaalternativ. Det här alternativet inaktiverar ADF:s standardschema för automatisk upptäckt och förbättrar avsevärt prestandan för filidentifiering. Innan du anger det här alternativet måste du importera projektionen så att ADF har ett befintligt schema för projektion. Det här alternativet fungerar inte med schemaavvikelse.
Relaterat innehåll
- Översikt över dataflödesprestanda
- Optimera mottagare
- Optimera transformeringar
- Använda dataflöden i pipelines
Se andra Dataflöde artiklar om prestanda: