Schemaavvikelse i dataflödesmappning
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Schemaavvikelse är det fall där dina källor ofta ändrar metadata. Fält, kolumner och typer kan läggas till, tas bort eller ändras i farten. Utan hantering av schemaavvikelser blir ditt dataflöde sårbart för ändringar i överordnade datakällor. Vanliga ETL-mönster misslyckas när inkommande kolumner och fält ändras eftersom de tenderar att vara knutna till dessa källnamn.
För att skydda mot schemaavvikelse är det viktigt att ha anläggningarna i ett dataflödesverktyg så att du som Dataingenjör kan:
- Definiera källor som har föränderliga fältnamn, datatyper, värden och storlekar
- Definiera transformeringsparametrar som kan fungera med datamönster i stället för hårdkodade fält och värden
- Definiera uttryck som förstår mönster för att matcha inkommande fält i stället för att använda namngivna fält
Azure Data Factory har inbyggt stöd för flexibla scheman som ändras från körning till körning så att du kan skapa allmän datatransformeringslogik utan att behöva kompilera om dina dataflöden.
Du måste fatta ett arkitektoniskt beslut i dataflödet för att acceptera schemaavvikelse i hela flödet. När du gör det kan du skydda mot schemaändringar från källorna. Du förlorar dock tidig bindning av dina kolumner och typer i hela dataflödet. Azure Data Factory behandlar schemaavvikelseflöden som senbindningsflöden, så när du skapar dina transformeringar blir de utdrivna kolumnnamnen inte tillgängliga för dig i schemavyerna i hela flödet.
Den här videon ger en introduktion till några av de komplexa lösningar som du enkelt kan skapa i Azure Data Factory- eller Synapse Analytics-pipelines med dataflödets schemaavvikelsefunktion . I det här exemplet skapar vi återanvändbara mönster baserat på flexibla databasscheman:
Schemaavvikelse i källan
Kolumner som kommer in i dataflödet från källdefinitionen definieras som "drifted" när de inte finns i källprojektionen. Du kan visa källprojektionen från projektionsfliken i källomvandlingen. När du väljer en datauppsättning för din källa tar tjänsten automatiskt schemat från datauppsättningen och skapar en projektion från datauppsättningens schemadefinition.
I en källtransformering definieras schemaavvikelse som läskolumner som inte definieras i datauppsättningsschemat. Om du vill aktivera schemaavvikelse kontrollerar du Tillåt schemaavvikelse i källtransformeringen.
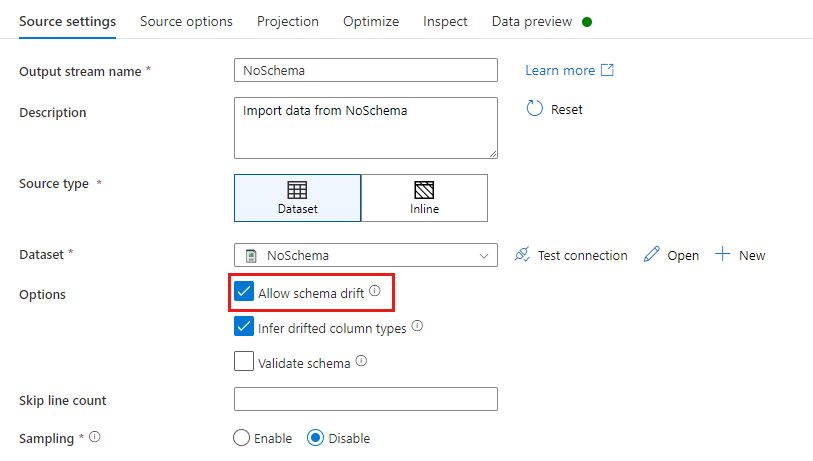
När schemaavvikelsen är aktiverad läss alla inkommande fält från källan under körningen och skickas genom hela flödet till mottagaren. Som standard anländer alla nyligen identifierade kolumner, så kallade drivande kolumner, som en strängdatatyp. Om du vill att dataflödet automatiskt ska härleda datatyper av glidande kolumner kontrollerar du Infer-typer av utdrivna kolumner i dina källinställningar.
Schemaavvikelse i mottagare
I en mottagartransformering är schemaavvikelse när du skriver ytterligare kolumner ovanpå det som definieras i schemat för mottagardata. Om du vill aktivera schemaavvikelse kontrollerar du Tillåt schemaavvikelse i din mottagartransformering.
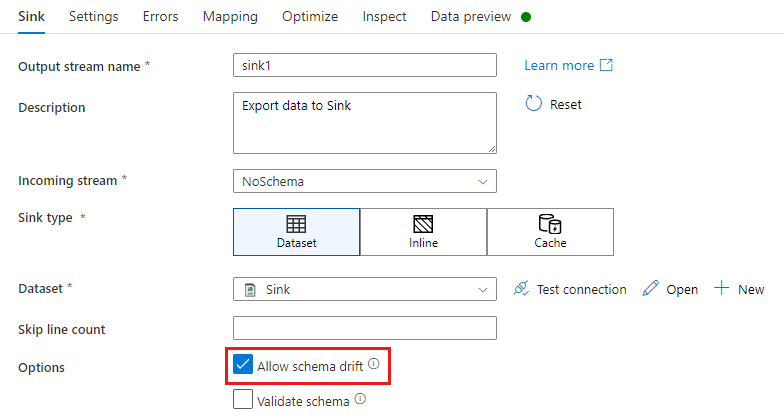
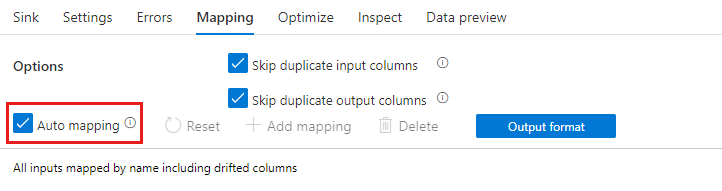
Om schemaavvikelsen är aktiverad kontrollerar du att skjutreglaget För automatisk mappning på fliken Mappning är aktiverat. Med skjutreglaget på skrivs alla inkommande kolumner till ditt mål. Annars måste du använda regelbaserad mappning för att skriva drivande kolumner.
Transformera drivande kolumner
När dataflödet har glidande kolumner kan du komma åt dem i dina transformeringar med följande metoder:
- Använd uttrycken
byPositionochbyNameför att explicit referera till en kolumn efter namn eller positionsnummer. - Lägg till ett kolumnmönster i en transformering av härledd kolumn eller aggregering som matchar en kombination av namn, dataström, position, ursprung eller typ
- Lägg till regelbaserad mappning i en Select- eller Sink-transformering för att matcha glidande kolumner med kolumnalias via ett mönster
Mer information om hur du implementerar kolumnmönster finns i Kolumnmönster i mappning av dataflöde.
Snabbåtgärd för att mappa driftade kolumner
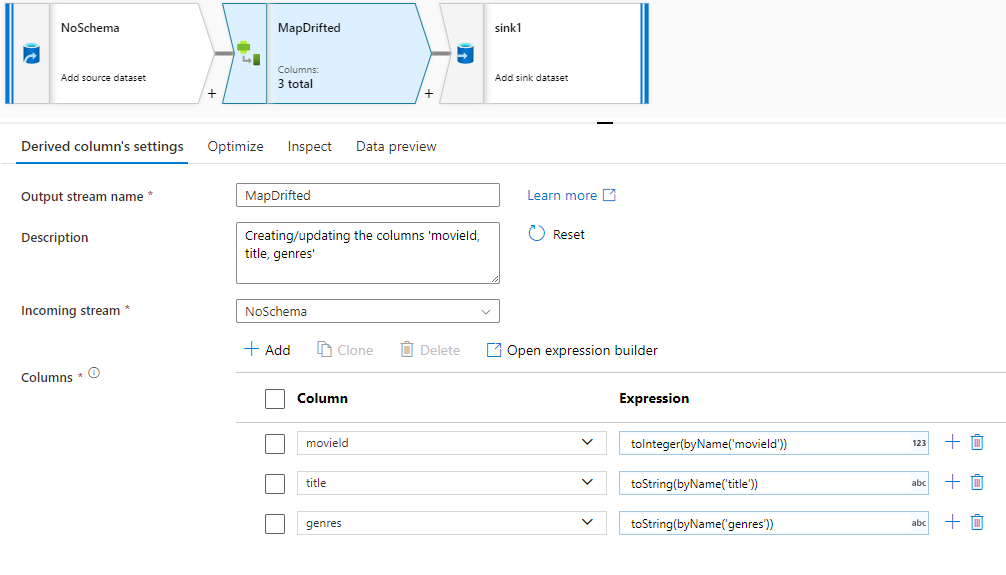
Om du uttryckligen vill referera till inaktiverade kolumner kan du snabbt generera mappningar för dessa kolumner via en snabbåtgärd för dataförhandsgranskning. När felsökningsläget är aktiverat går du till fliken Dataförhandsgranskning och klickar på Uppdatera för att hämta en förhandsgranskning av data. Om datafabriken upptäcker att det finns avvikelsekolumner kan du klicka på Mappa drifted och generera en härledd kolumn som gör att du kan referera till alla underordnade kolumner i schemavyer.
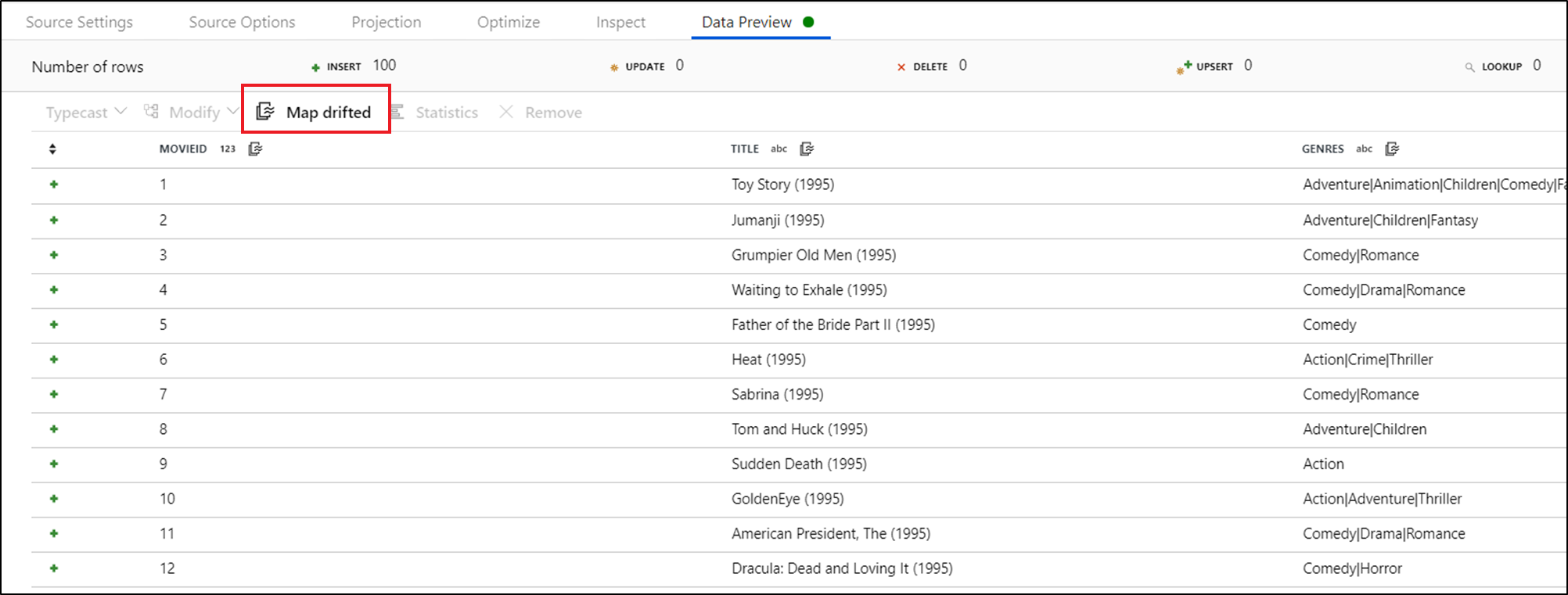
I transformeringen av den genererade härledda kolumnen mappas varje avvikelsekolumn till dess identifierade namn och datatyp. I dataförhandsgranskningen ovan identifieras kolumnen "movieId" som ett heltal. När Map Drifted har klickats definieras movieId i den härledda kolumnen som toInteger(byName('movieId')) och ingår i schemavyer i nedströmstransformeringar.
Relaterat innehåll
I Dataflöde uttrycksspråk hittar du ytterligare funktioner för kolumnmönster och schemaavvikelser, inklusive "byName" och "byPosition".