Uppslagstransformeringar i mappning av dataflöde
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Dataflöden är tillgängliga både i Azure Data Factory och Azure Synapse Pipelines. Den här artikeln gäller för mappning av dataflöden. Om du är nybörjare på transformeringar kan du läsa den inledande artikeln Transformera data med hjälp av ett mappningsdataflöde.
Använd uppslagstransformeringen för att referera till data från en annan källa i en dataflödesström. Uppslagstransformeringen lägger till kolumner från matchade data till dina källdata.
En uppslagstransformering liknar en vänster yttre koppling. Alla rader från den primära strömmen finns i utdataströmmen med ytterligare kolumner från uppslagsströmmen.
Konfiguration

Primär ström: Den inkommande dataströmmen. Den här strömmen motsvarar vänster sida av en koppling.
Uppslagsström: De data som läggs till i den primära dataströmmen. Vilka data som läggs till bestäms av uppslagsvillkoren. Den här strömmen motsvarar höger sida av en koppling.
Matcha flera rader: Om den är aktiverad returnerar en rad med flera matchningar i den primära dataströmmen flera rader. Annars returneras endast en enskild rad baserat på villkoret "Matcha på".
Matcha på: Visas endast om "Matcha flera rader" inte är markerat. Välj om du vill matcha på en rad, den första matchningen eller den sista matchningen. Alla rader rekommenderas eftersom den körs snabbast. Om första raden eller den sista raden är markerad måste du ange sorteringsvillkor.
Uppslagsvillkor: Välj vilka kolumner som ska matchas. Om likhetsvillkoret uppfylls betraktas raderna som en matchning. Hovra och välj "Beräknad kolumn" för att extrahera ett värde med dataflödesuttrycksspråket.
Alla kolumner från båda strömmarna ingår i utdata. Om du vill släppa dubbletter eller oönskade kolumner lägger du till en select-transformering efter din uppslagstransformering. Kolumner kan också tas bort eller byta namn i en mottagartransformering.
Icke-equi-kopplingar
Om du vill använda en villkorsoperator som inte är lika med (!=) eller större än (>) i uppslagsvillkoren ändrar du listrutan operator mellan de två kolumnerna. Icke-equi-kopplingar kräver att minst en av de två strömmarna sänds med fasta sändningar på fliken Optimera.

Analysera matchade rader
Efter uppslagstransformeringen kan funktionen isMatch() användas för att se om sökningen matchade för enskilda rader.

Ett exempel på det här mönstret är att använda den villkorsstyrda splittransformeringen för att dela på isMatch() funktionen. I exemplet ovan går matchande rader genom den översta strömmen och icke-matchande rader flödar genom NoMatch strömmen.
Testa uppslagsvillkor
När du testar uppslagstransformeringen med dataförhandsvisning i felsökningsläge använder du en liten uppsättning kända data. När du samplar rader från en stor datamängd kan du inte förutsäga vilka rader och nycklar som ska läsas för testning. Resultatet är icke-deterministiskt, vilket innebär att dina kopplingsvillkor kanske inte returnerar några matchningar.
Sändningsoptimering
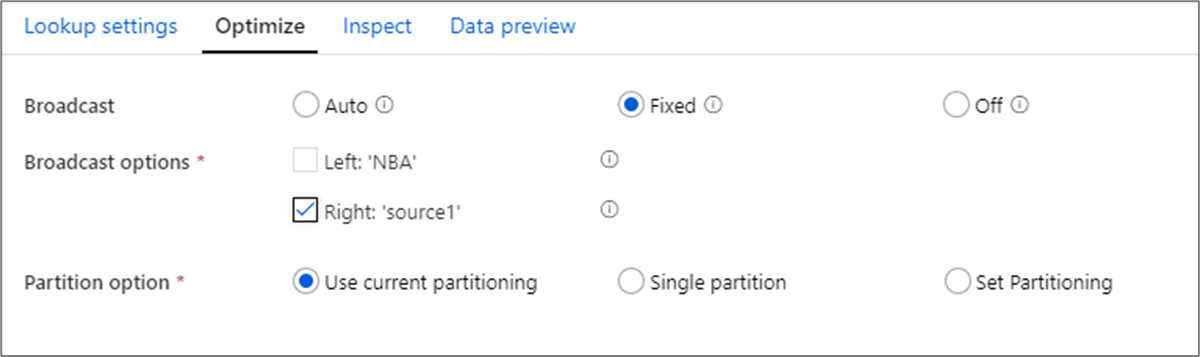
I kopplingar, sökningar och finns transformering, om en eller båda dataströmmarna passar in i arbetsnodminnet, kan du optimera prestanda genom att aktivera Sändning. Spark-motorn avgör som standard automatiskt om en sida ska sändas eller inte. Om du vill välja vilken sida som ska sändas manuellt väljer du Fast.
Vi rekommenderar inte att du inaktiverar sändning via alternativet Av om inte dina kopplingar får timeout-fel.
Cachelagrad sökning
Om du gör flera mindre sökningar på samma källa kanske en cachelagrad mottagare och sökning är ett bättre användningsfall än uppslagstransformeringen. Vanliga exempel där en cachemottagare kan vara bättre är att leta upp ett maxvärde i ett datalager och matcha felkoder till en databas med felmeddelanden. Mer information finns i cachemottagare och cachelagrade sökningar.
Dataflödesskript
Syntax
<leftStream>, <rightStream>
lookup(
<lookupConditionExpression>,
multiple: { true | false },
pickup: { 'first' | 'last' | 'any' }, ## Only required if false is selected for multiple
{ desc | asc }( <sortColumn>, { true | false }), ## Only required if 'first' or 'last' is selected. true/false determines whether to put nulls first
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <lookupTransformationName>
Exempel

Dataflödesskriptet för ovanstående uppslagskonfiguration finns i kodfragmentet nedan.
SQLProducts, DimProd lookup(ProductID == ProductKey,
multiple: false,
pickup: 'first',
asc(ProductKey, true),
broadcast: 'auto')~> LookupKeys
Relaterat innehåll
- Kopplingen och finns transformeringar tar båda in flera indata för dataströmmen
- Använd en villkorsstyrd splittransformering med
isMatch()för att dela rader på matchande och icke-matchande värden