Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Data Factory i Microsoft Fabric är nästa generations Azure Data Factory, med en enklare arkitektur, inbyggd AI och nya funktioner. Om dataintegrering är nytt för dig börjar du med Fabric Data Factory. Befintliga ADF-arbetsbelastningar kan uppgraderas till Fabric för att få åtkomst till nya funktioner inom datavetenskap, realtidsanalys och rapportering.
Dataflöden är tillgängliga i både Azure Data Factory pipelines och Azure Synapse Analytics pipelines. Den här artikeln gäller för mappning av dataflöden. Om du inte har använt transformeringar tidigare läser du introduktionsartikeln Transformera data med hjälp av mappning av dataflöden.
Dricks
För motsvarande transformering (tilläggsfrågor) i Dataflöde Gen2, se En guide till Dataflöde Gen2 för mappning av dataflödesanvändare.
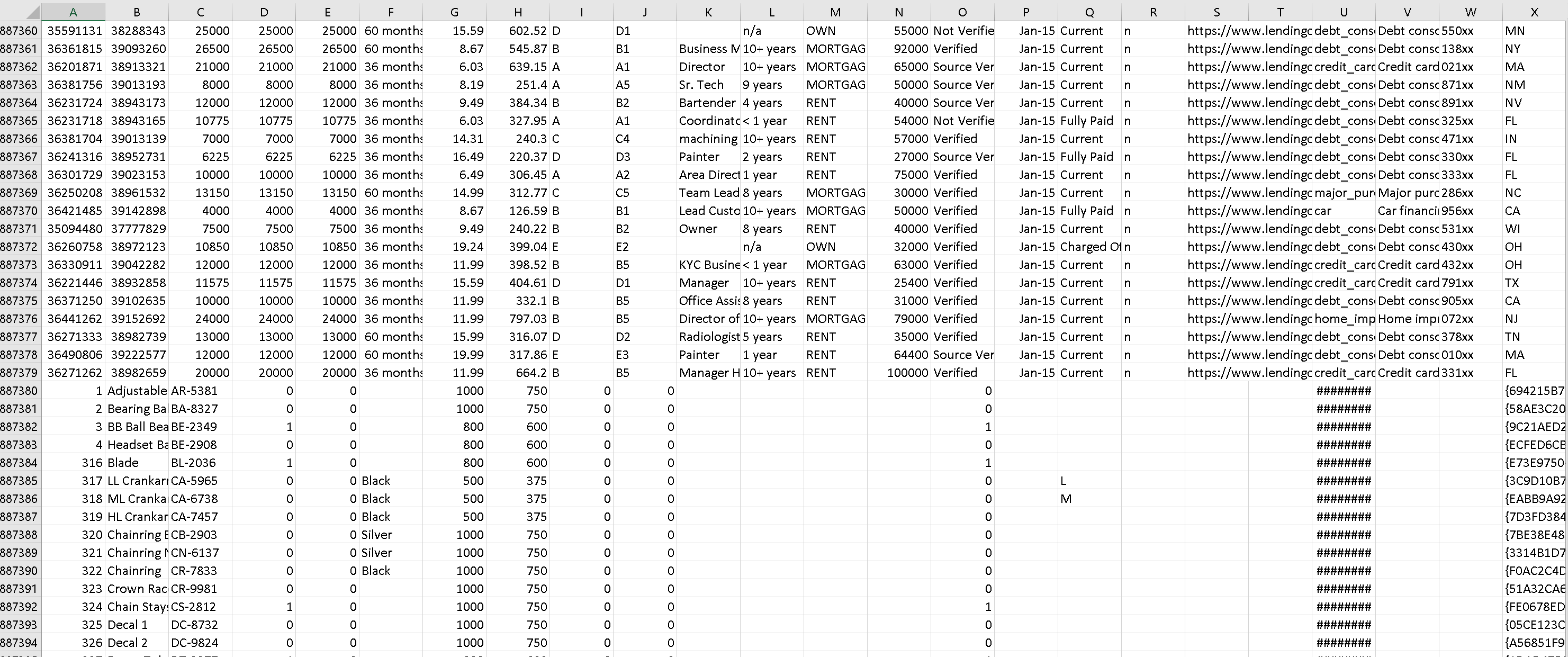
Union kombinerar flera dataströmmar till en, med SQL Union för dessa strömmar som nya utdata från unionomvandlingen. Alla scheman från varje indataström kombineras i dataflödet, utan att behöva ha en kopplingsnyckel.
Du kan kombinera n-antal strömmar i inställningstabellen genom att välja ikonen "+" bredvid varje konfigurerad rad, inklusive både källdata och strömmar från befintliga transformeringar i dataflödet.
Här är en kort video som visar unionstransformationen i mappningens dataflöde.
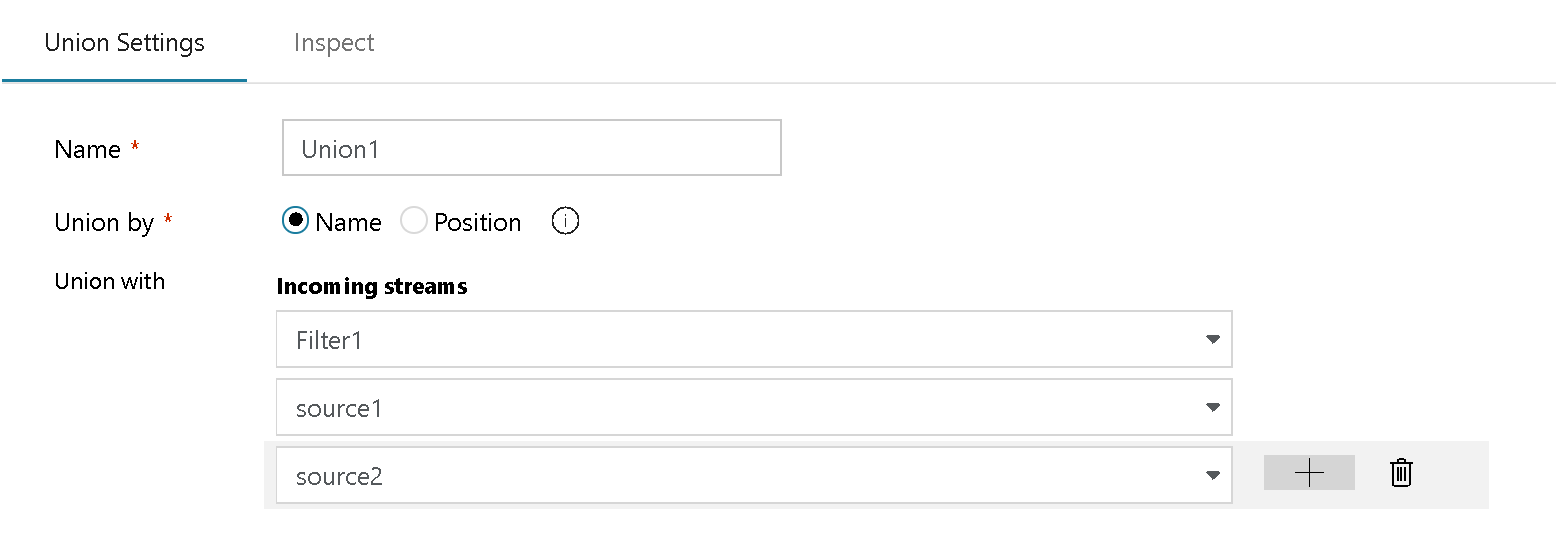
I det här fallet kan du kombinera olika metadata från flera källor (i det här exemplet tre olika källfiler) och kombinera dem till en enda ström:

För att uppnå detta lägger du till fler rader i Unionsinställningarna genom att inkludera alla källor som du vill lägga till. Det finns inget behov av en gemensam uppslags- eller kopplingsnyckel:
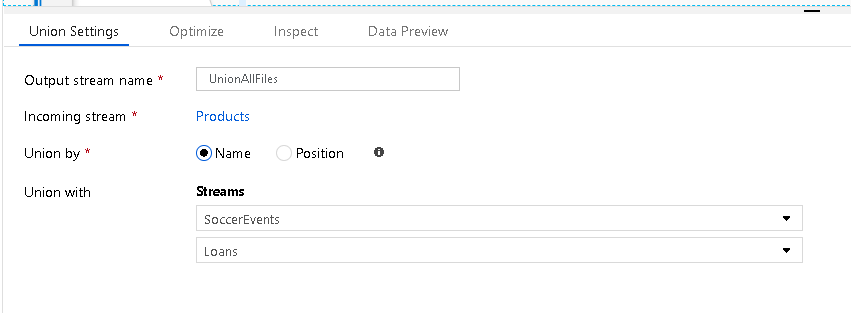
Om du anger en Select-transform efter din Union kan du byta namn på överlappande fält eller fält som inte har givits namn från källor utan rubriker. Välj "Inspektera" för att se de kombinerade metadata med totalt 132 kolumner i det här exemplet från tre olika källor:
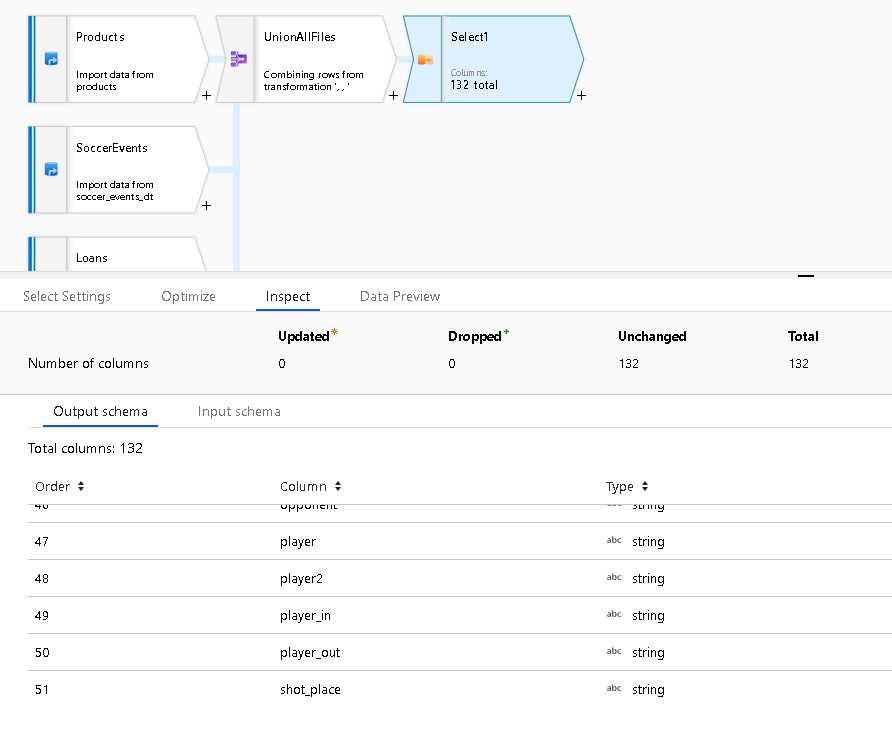
Namn och position
När du väljer "union by name" hamnar varje kolumnvärde i motsvarande kolumn från varje källa, med ett nytt sammanfogat metadataschema.
Om du väljer "union by position" hamnar varje kolumnvärde i den ursprungliga positionen från varje motsvarande källa, vilket resulterar i en ny kombinerad dataström där data från varje källa läggs till i samma ström: