Läsa in data i Azure Data Lake Storage Gen2 med Azure Data Factory
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Azure Data Lake Storage Gen2 är en uppsättning funktioner som är dedikerade till stordataanalys, inbyggda i Azure Blob Storage. Det gör att du kan interagera med dina data med hjälp av både filsystem och objektlagringsparadigm.
Azure Data Factory (ADF) är en fullständigt hanterad molnbaserad dataintegreringstjänst. Du kan använda tjänsten för att fylla sjön med data från en omfattande uppsättning lokala och molnbaserade datalager och spara tid när du skapar dina analyslösningar. En detaljerad lista över anslutningsappar som stöds finns i tabellen med datalager som stöds.
Azure Data Factory erbjuder en utskalningslösning för hanterad dataflytt. På grund av ADF:s utskalningsarkitektur kan den mata in data med ett högt dataflöde. Mer information finns i Kopiera aktivitetsprestanda.
Den här artikeln visar hur du använder verktyget Data Factory Copy Data för att läsa in data från Amazon Web Services S3-tjänsten till Azure Data Lake Storage Gen2. Du kan följa liknande steg för att kopiera data från andra typer av datalager.
Dricks
Information om hur du kopierar data från Azure Data Lake Storage Gen1 till Gen2 finns i den här specifika genomgången.
Förutsättningar
- Azure-prenumeration: Om du inte har en Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
- Azure Storage-konto med Data Lake Storage Gen2 aktiverat: Om du inte har ett lagringskonto skapar du ett konto.
- AWS-konto med en S3-bucket som innehåller data: Den här artikeln visar hur du kopierar data från Amazon S3. Du kan använda andra datalager genom att följa liknande steg.
Skapa en datafabrik
Om du inte har skapat din datafabrik ännu följer du stegen i Snabbstart: Skapa en datafabrik med hjälp av Azure-portalen och Azure Data Factory Studio för att skapa en. När du har skapat den bläddrar du till datafabriken i Azure-portalen.

Välj Öppna på panelen Öppna Azure Data Factory Studio för att starta dataintegreringsprogrammet på en separat flik.
Läsa in data i Azure Data Lake Storage Gen2
På startsidan för Azure Data Factory väljer du panelen Mata in för att starta verktyget Kopiera data.
På sidan Egenskaper väljer du Inbyggd kopieringsaktivitet under Aktivitetstyp och väljer Kör en gång nu under Aktivitetstakt eller aktivitetsschema och väljer sedan Nästa.
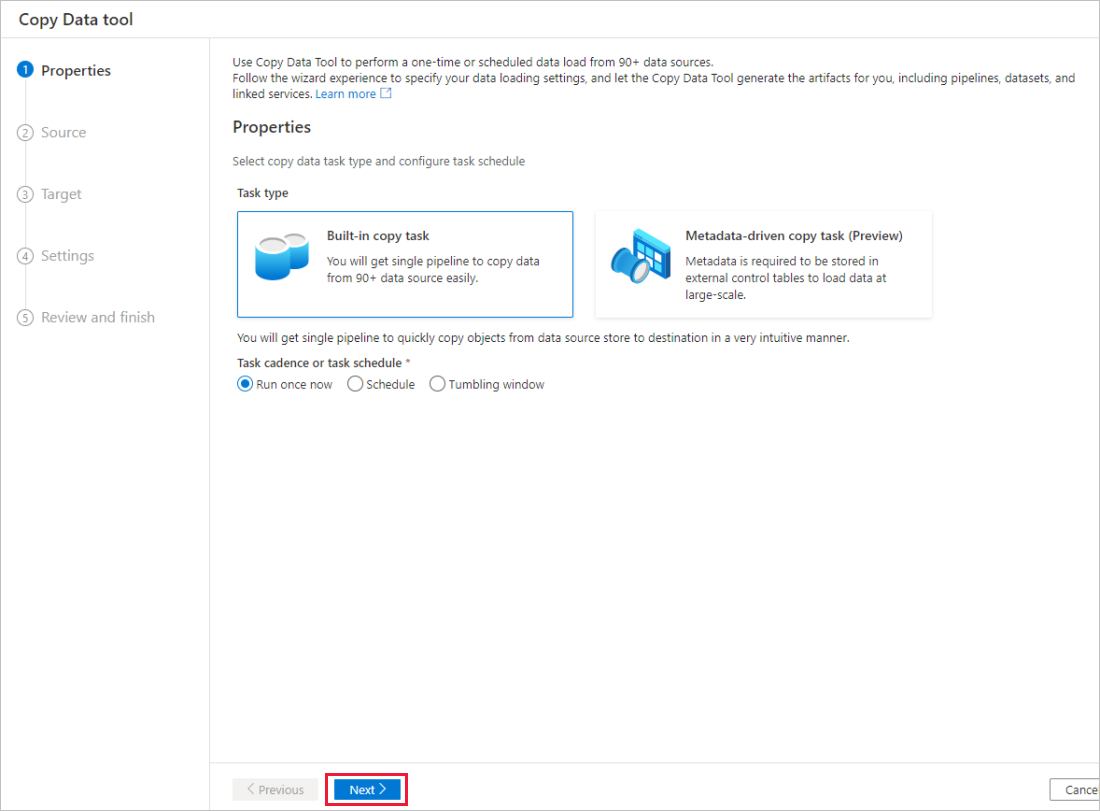
Slutför följande steg på sidan Källdatalager :
Välj + Ny anslutning. Välj Amazon S3 i anslutningsgalleriet och välj Fortsätt.

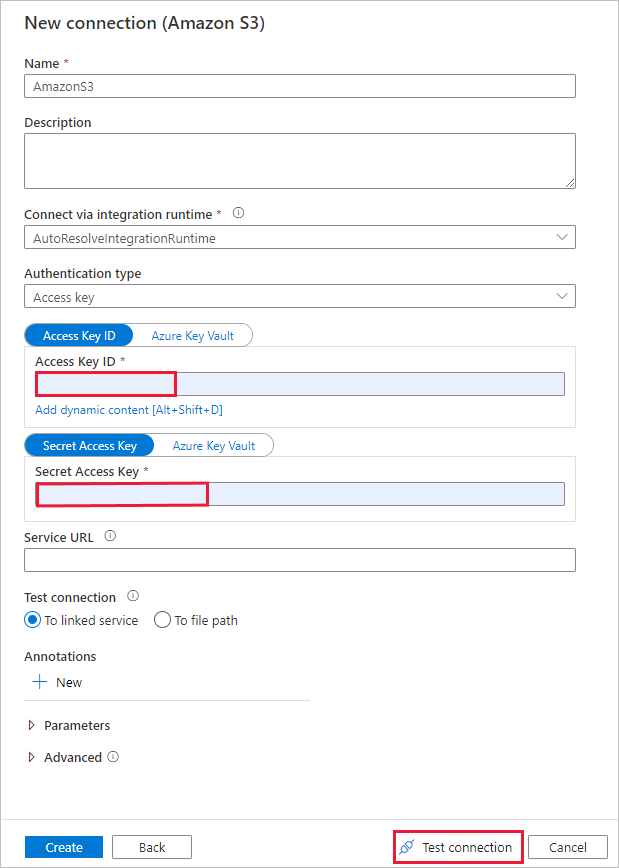
På sidan Ny anslutning (Amazon S3) gör du följande:
- Ange värdet för åtkomstnyckelns ID .
- Ange värdet hemlig åtkomstnyckel.
- Välj Testa anslutning för att verifiera inställningarna och välj sedan Skapa.
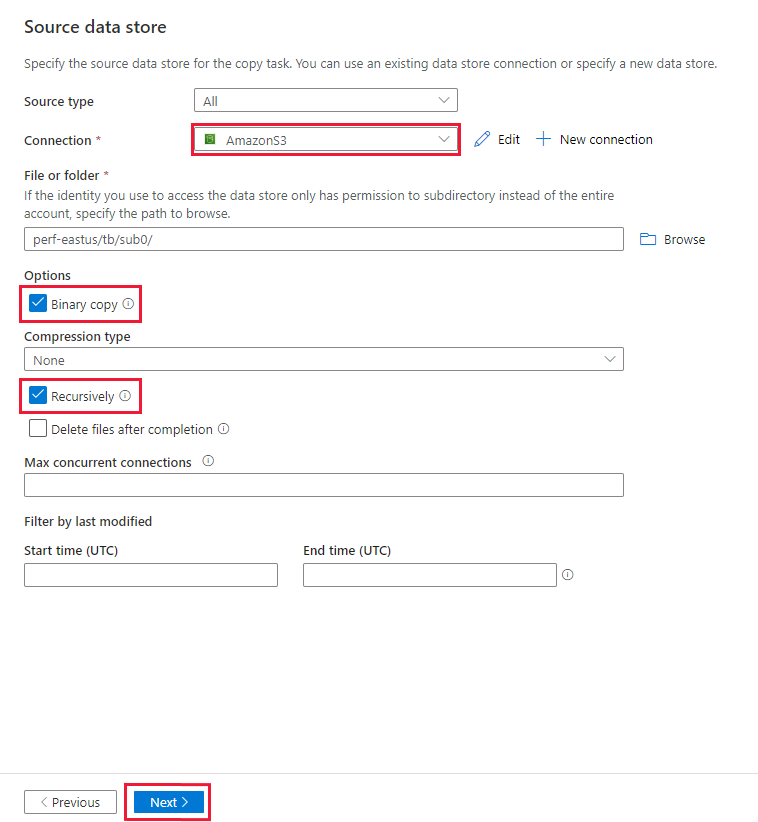
På sidan Källdatalager kontrollerar du att den nyligen skapade Amazon S3-anslutningen har valts i anslutningsblocket.
I avsnittet Fil eller mapp bläddrar du till den mapp och fil som du vill kopiera över. Välj mappen/filen och välj sedan OK.
Ange kopieringsbeteendet genom att kontrollera alternativen Rekursivt och Binär kopiering . Välj Nästa.
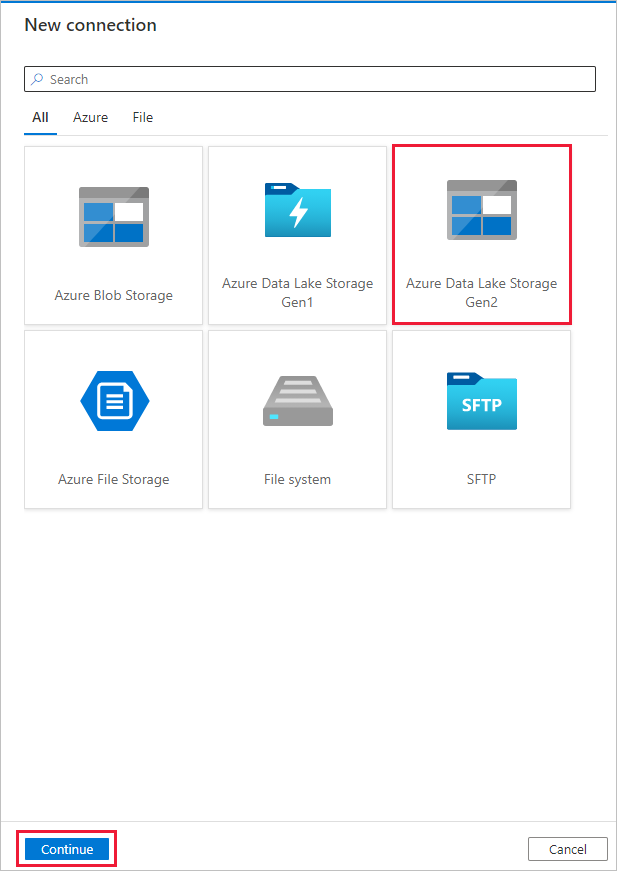
Slutför följande steg på sidan Måldatalager .
Välj + Ny anslutning och välj sedan Azure Data Lake Storage Gen2 och välj Fortsätt.
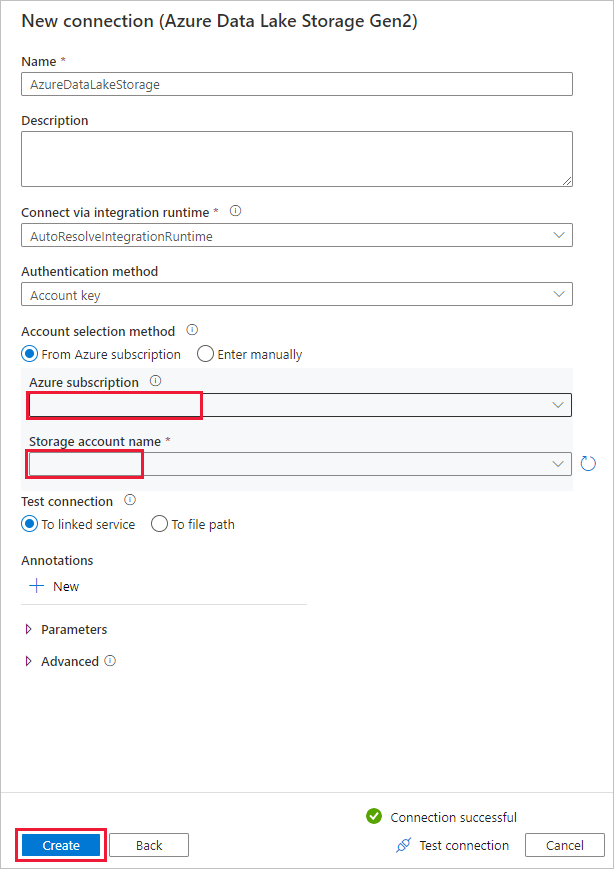
På sidan Ny anslutning (Azure Data Lake Storage Gen2) väljer du ditt Data Lake Storage Gen2-kompatibla konto i listrutan "Lagringskontonamn" och väljer Skapa för att skapa anslutningen.
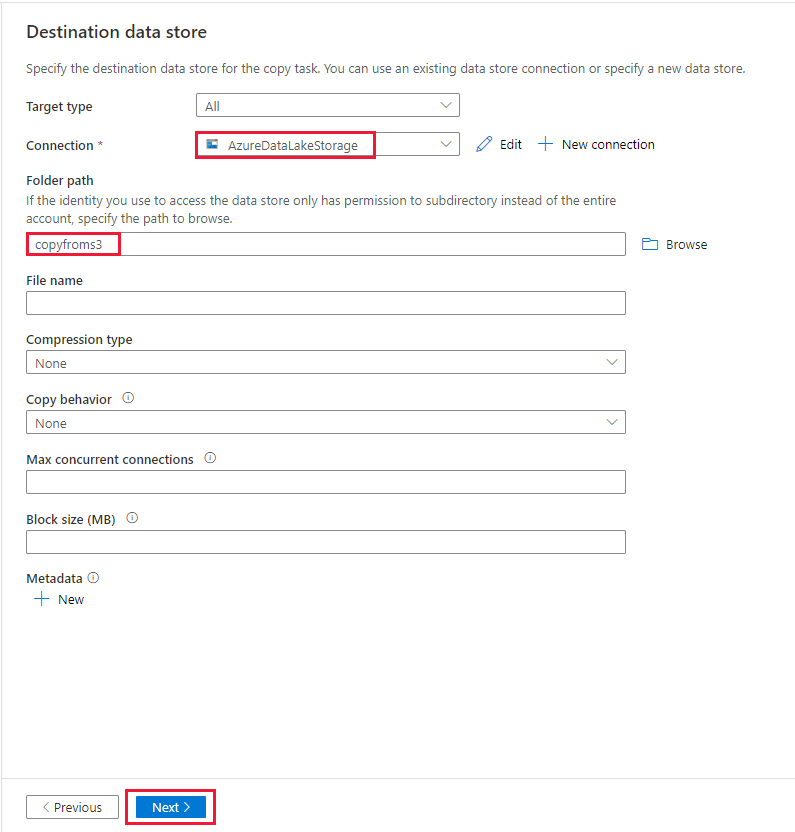
På sidan Måldatalager väljer du den nyligen skapade anslutningen i anslutningsblocket. Under Mappsökväg anger du copyfroms3 som namn på utdatamappen och väljer Nästa. ADF skapar motsvarande ADLS Gen2-filsystem och undermappar under kopiering om det inte finns.
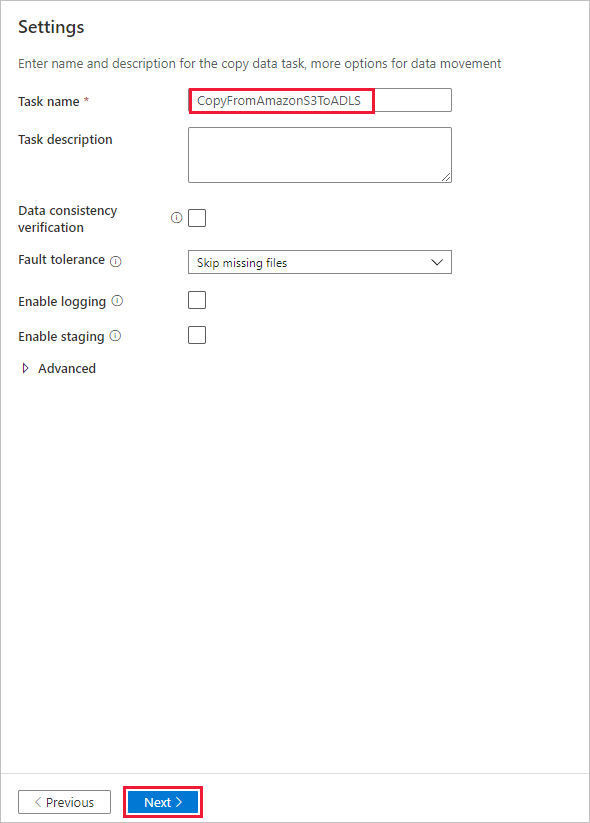
På sidan Inställningar anger du CopyFromAmazonS3ToADLS för fältet Aktivitetsnamn och väljer Nästa för att använda standardinställningarna.
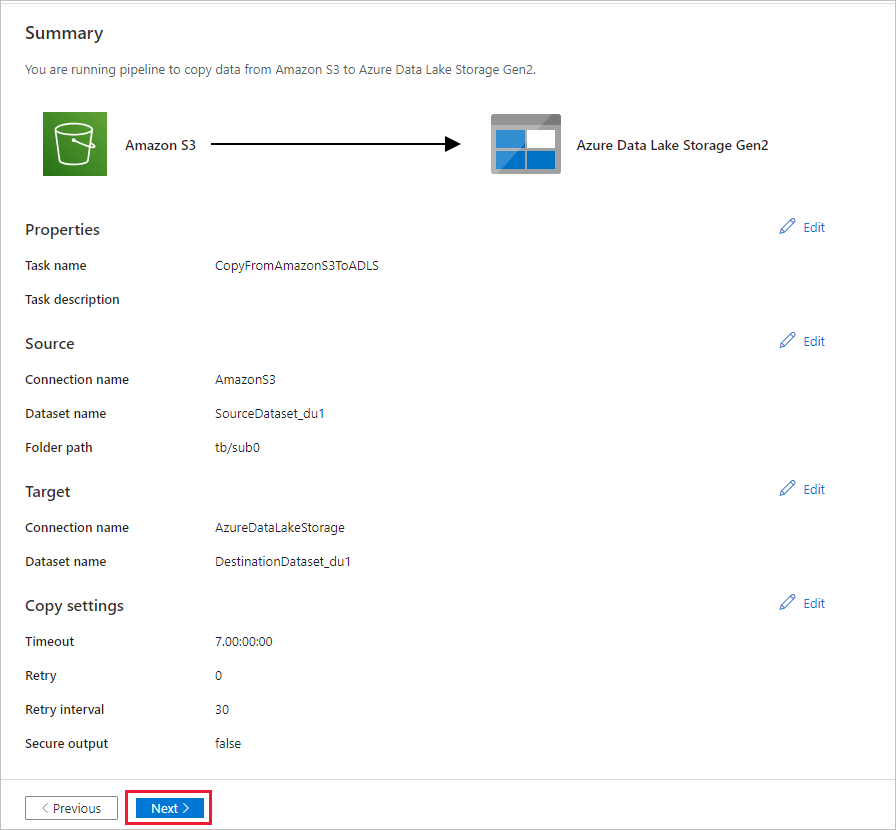
På sidan Sammanfattning granskar du inställningarna och väljer Nästa.
Välj Övervaka på sidan Distribution för att övervaka pipelinen (aktiviteten).
När pipelinekörningen har slutförts visas en pipelinekörning som utlöses av en manuell utlösare. Du kan använda länkar under kolumnen Pipelinenamn för att visa aktivitetsinformation och köra pipelinen igen.
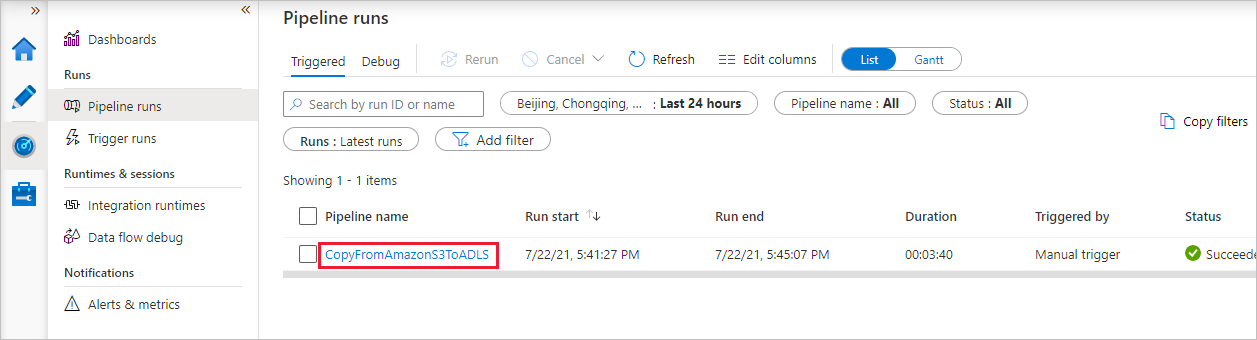
Om du vill se aktivitetskörningar som är associerade med pipelinekörningen väljer du länken CopyFromAmazonS3ToADLS under kolumnen Pipelinenamn . Om du vill ha mer information om kopieringsåtgärden väljer du länken Information (glasögonikonen) under kolumnen Aktivitetsnamn . Du kan övervaka information som mängden data som kopieras från källan till mottagaren, dataflöde, körningssteg med motsvarande varaktighet och använd konfiguration.
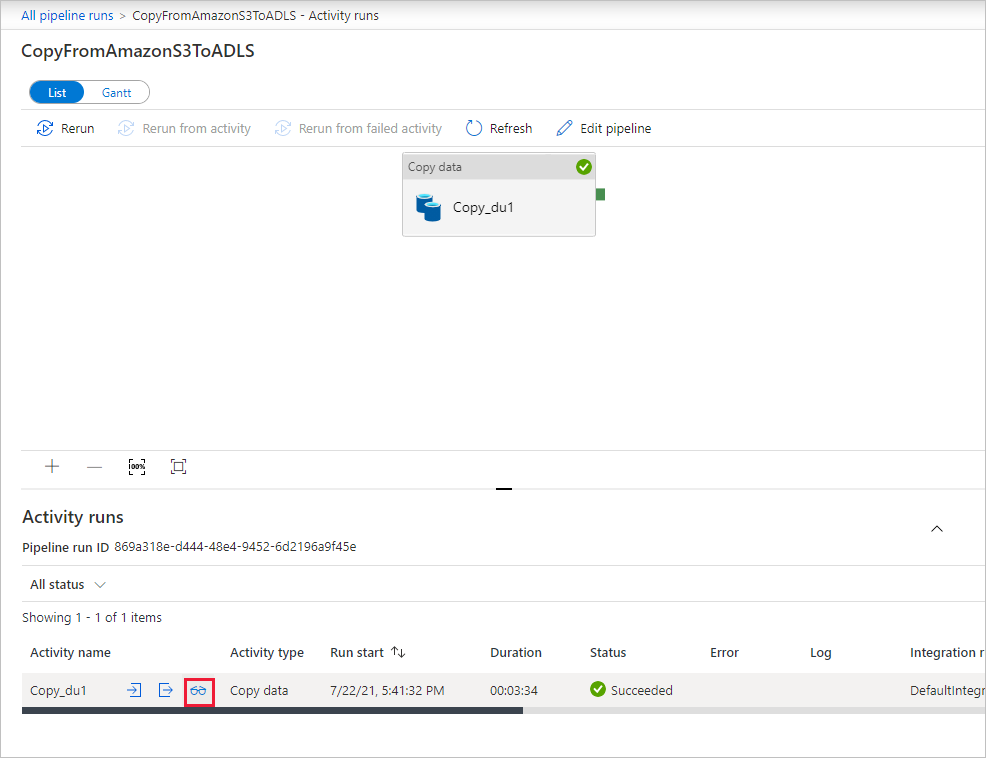
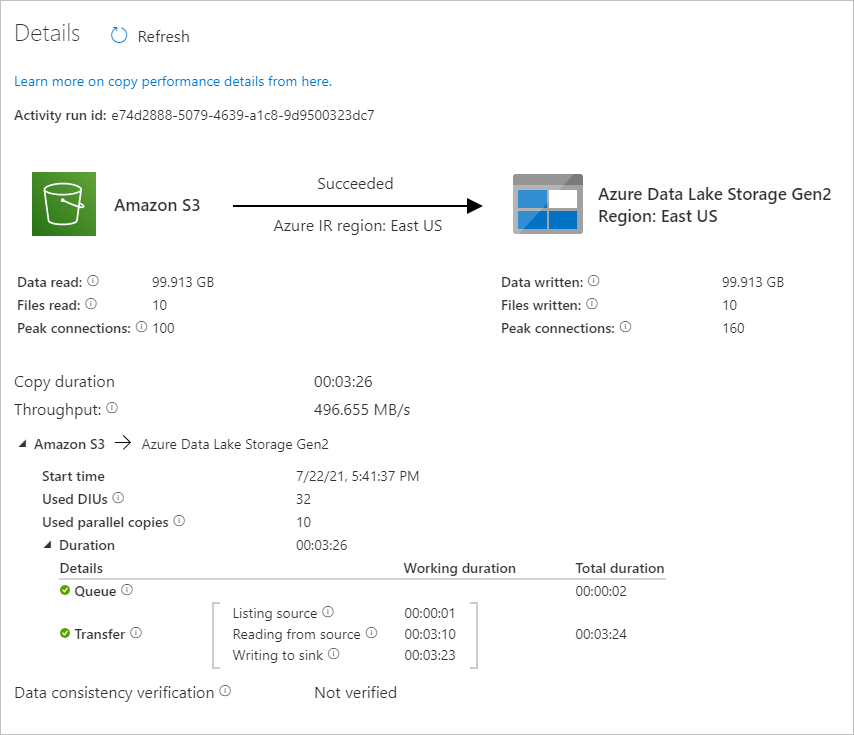
Välj Uppdatera för att uppdatera vyn. Välj Alla pipelinekörningar överst för att gå tillbaka till vyn Pipelinekörningar.
Kontrollera att data kopieras till ditt Data Lake Storage Gen2-konto.