Kopiera data från Azure Data Lake Storage Gen1 till Gen2 med Azure Data Factory
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Azure Data Lake Storage Gen2 är en uppsättning funktioner som är dedikerade till stordataanalys som är inbyggda i Azure Blob Storage. Med den här lösningen kan du interagera med data med hjälp av både filsystem- och objektlagringsparadigm.
Om du för närvarande använder Azure Data Lake Storage Gen1 kan du utvärdera Azure Data Lake Storage Gen2 genom att kopiera data från Data Lake Storage Gen1 till Gen2 med hjälp av Azure Data Factory.
Azure Data Factory är en fullständigt hanterad molnbaserad dataintegreringstjänst. Du kan använda tjänsten för att fylla sjön med data från en omfattande uppsättning lokala och molnbaserade datalager och spara tid när du skapar dina analyslösningar. En lista över anslutningsappar som stöds finns i tabellen med datalager som stöds.
Azure Data Factory erbjuder en utskalningslösning för hanterad dataflytt. På grund av datafabrikens utskalningsarkitektur kan den mata in data med ett högt dataflöde. Mer information finns i Kopiera aktivitetsprestanda.
Den här artikeln visar hur du använder dataverktyget För datafabrikskopiering för att kopiera data från Azure Data Lake Storage Gen1 till Azure Data Lake Storage Gen2. Du kan följa liknande steg för att kopiera data från andra typer av datalager.
Förutsättningar
- En Azure-prenumeration. Om du inte har någon Azure-prenumeration kan du skapa ett kostnadsfritt konto innan du börjar.
- Azure Data Lake Storage Gen1-konto med data i.
- Azure Storage-konto med Data Lake Storage Gen2 aktiverat. Om du inte har något lagringskonto skapar du ett konto.
Skapa en datafabrik
Om du inte har skapat din datafabrik ännu följer du stegen i Snabbstart: Skapa en datafabrik med hjälp av Azure-portalen och Azure Data Factory Studio för att skapa en. När du har skapat den bläddrar du till datafabriken i Azure-portalen.

Välj Öppna på panelen Öppna Azure Data Factory Studio för att starta dataintegreringsprogrammet på en separat flik.
Läsa in data i Azure Data Lake Storage Gen2
På startsidan väljer du panelen Mata in för att starta verktyget kopiera data.
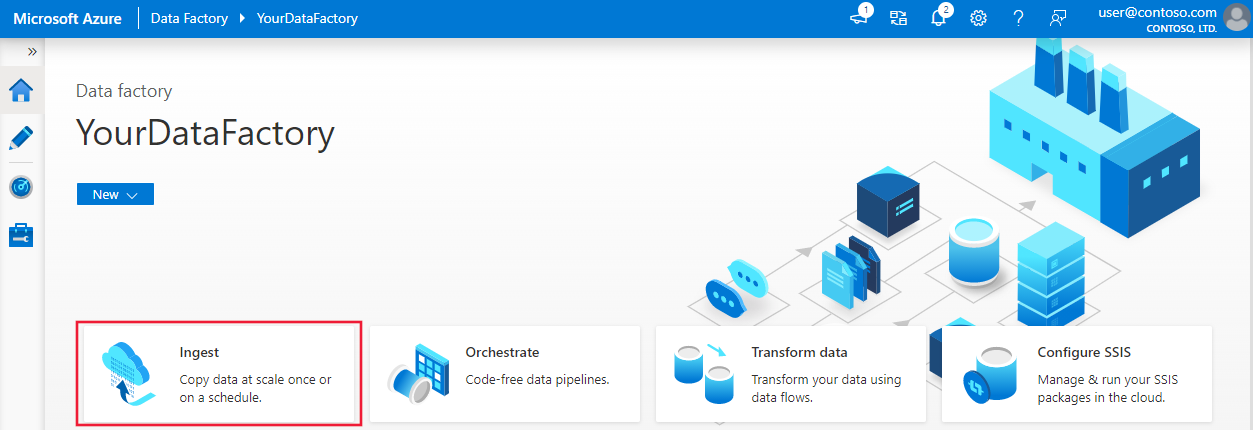
På sidan Egenskaper väljer du Inbyggd kopieringsaktivitet under Aktivitetstyp och väljer Kör en gång nu under Aktivitetstakt eller aktivitetsschema och väljer sedan Nästa.
På sidan Källdatalager väljer du + Ny anslutning.
Välj Azure Data Lake Storage Gen1 i galleriet med anslutningsappar och välj Fortsätt.
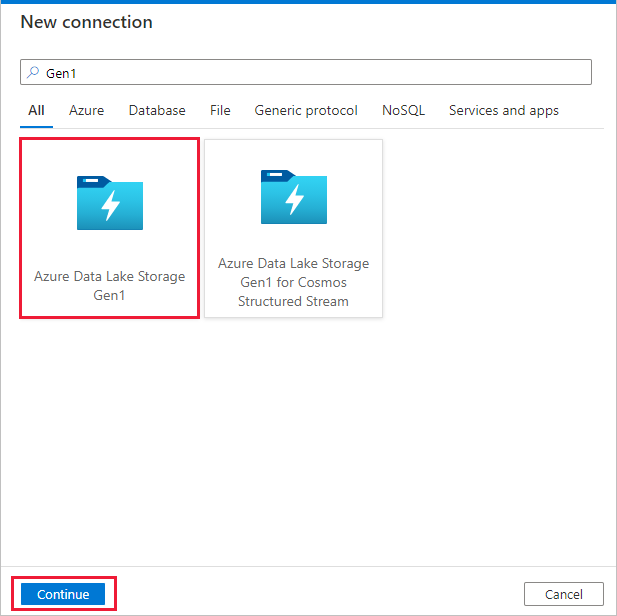
På sidan Ny anslutning (Azure Data Lake Storage Gen1) följer du dessa steg:
- Välj Data Lake Storage Gen1 som kontonamn och ange eller verifiera klientorganisationen.
- Välj Testa anslutning för att verifiera inställningarna. Välj sedan Skapa.
Viktigt!
I den här genomgången använder du en hanterad identitet för Azure-resurser för att autentisera din Azure Data Lake Storage Gen1. Följ dessa instruktioner för att ge den hanterade identiteten rätt behörigheter i Azure Data Lake Storage Gen1.
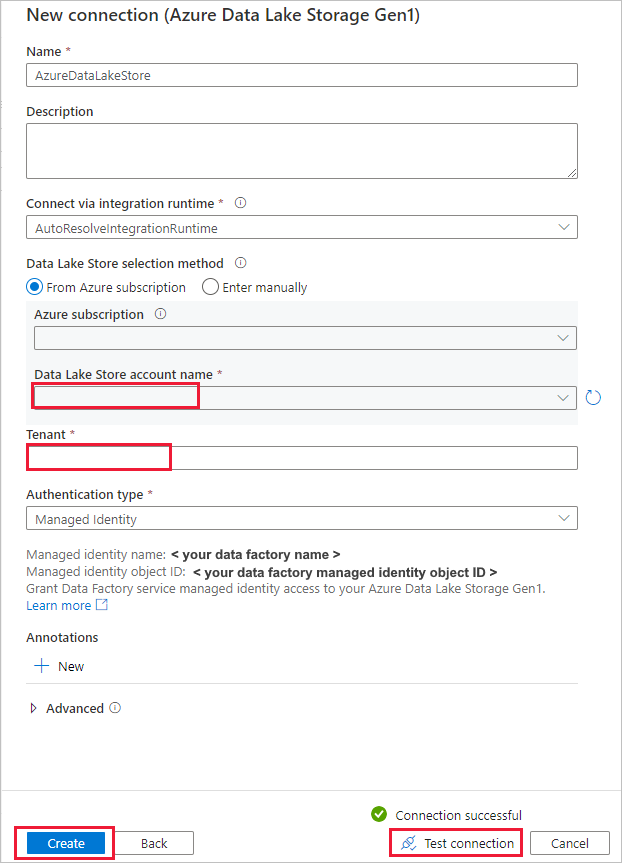
Slutför följande steg på sidan Källdatalager .
- Välj den nyligen skapade anslutningen i avsnittet Anslutning .
- Under Fil eller mapp bläddrar du till den mapp och fil som du vill kopiera över. Välj mappen eller filen och välj OK.
- Ange kopieringsbeteendet genom att välja alternativen Rekursivt och Binär kopiering . Välj Nästa.
På sidan Måldatalager väljer du + Ny anslutning>Azure Data Lake Storage Gen2>Fortsätt.
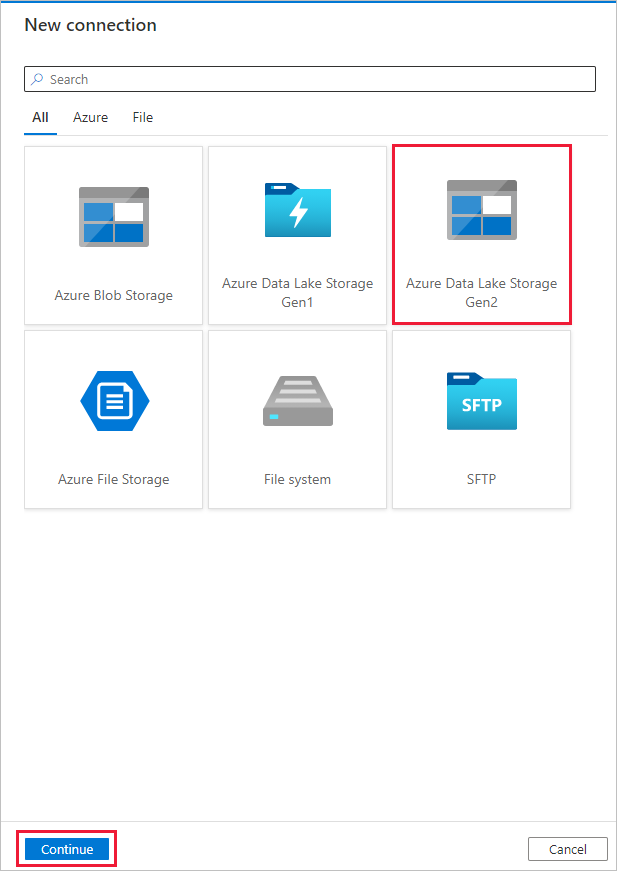
Följ dessa steg på sidan Ny anslutning (Azure Data Lake Storage Gen2 ):
- Välj ditt Data Lake Storage Gen2-kompatibla konto i listrutan Lagringskontonamn .
- Skapa anslutningen genom att välja Skapa.
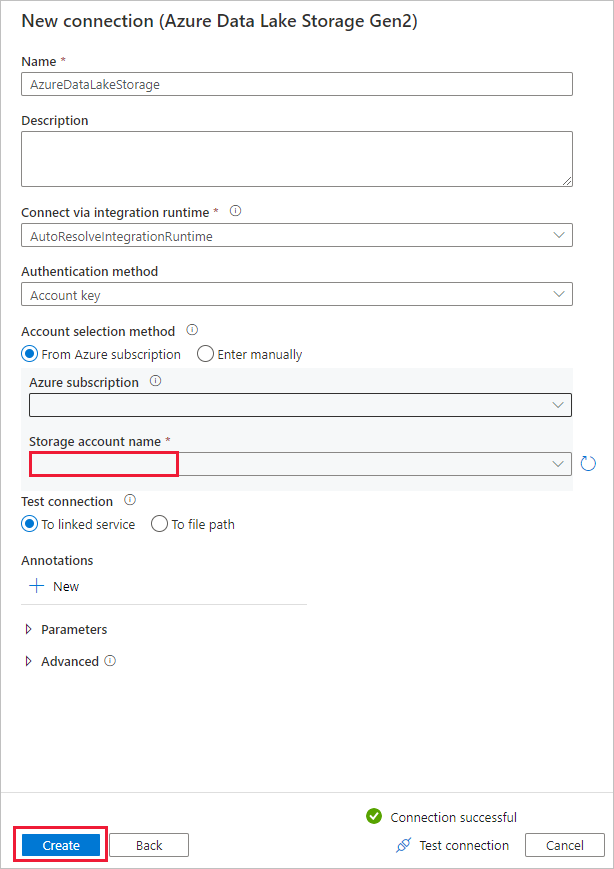
Slutför följande steg på sidan Måldatalager .
- Välj den nyligen skapade anslutningen i anslutningsblocket.
- Under Mappsökväg anger du copyfromadlsgen1 som namn på utdatamappen och väljer Nästa. Data Factory skapar motsvarande Azure Data Lake Storage Gen2-filsystem och undermappar under kopiering om de inte finns.
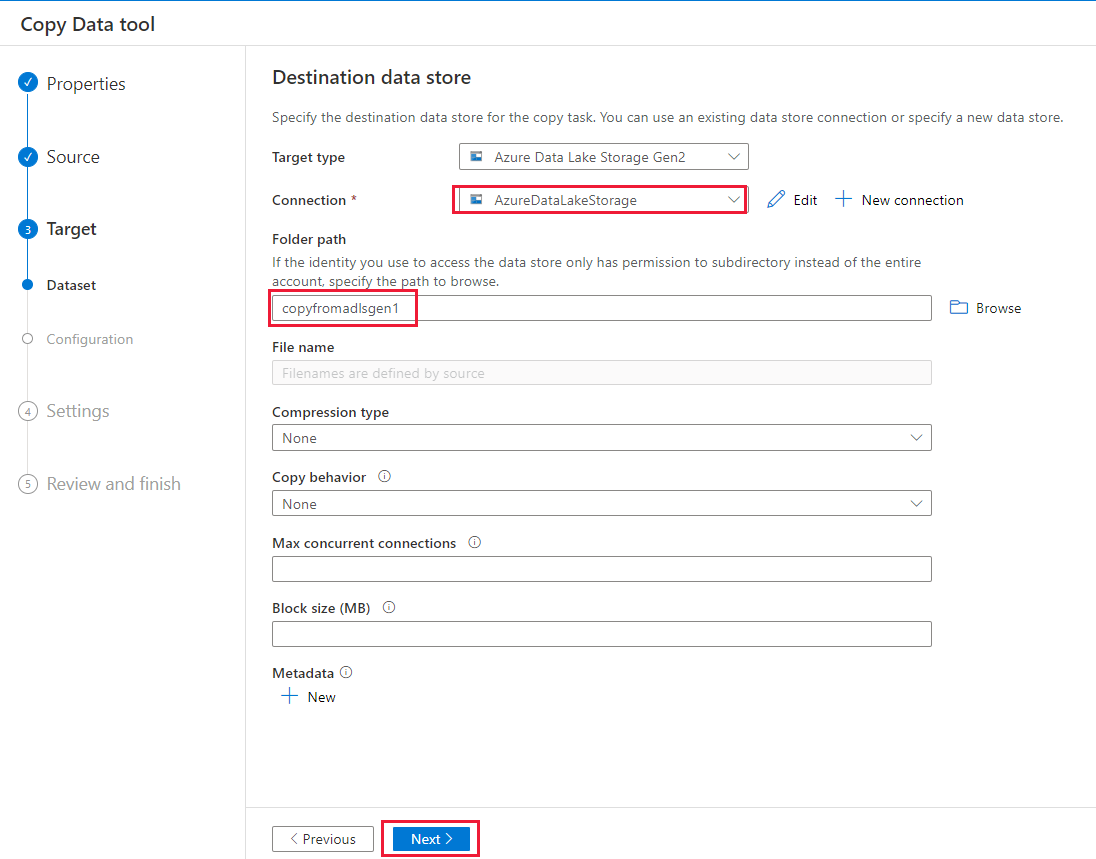
På sidan Inställningar anger du CopyFromADLSGen1ToGen2 för fältet Aktivitetsnamn och väljer sedan Nästa för att använda standardinställningarna.
På sidan Sammanfattning granskar du inställningarna och väljer Nästa.
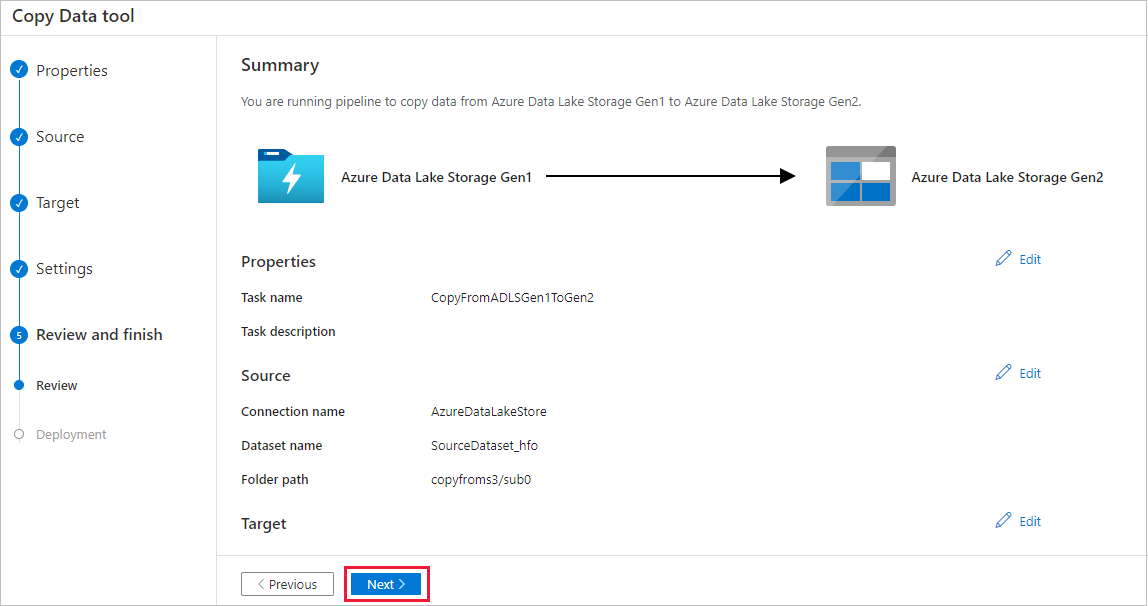
På sidan Distribution väljer du Övervaka för att övervaka pipelinen.
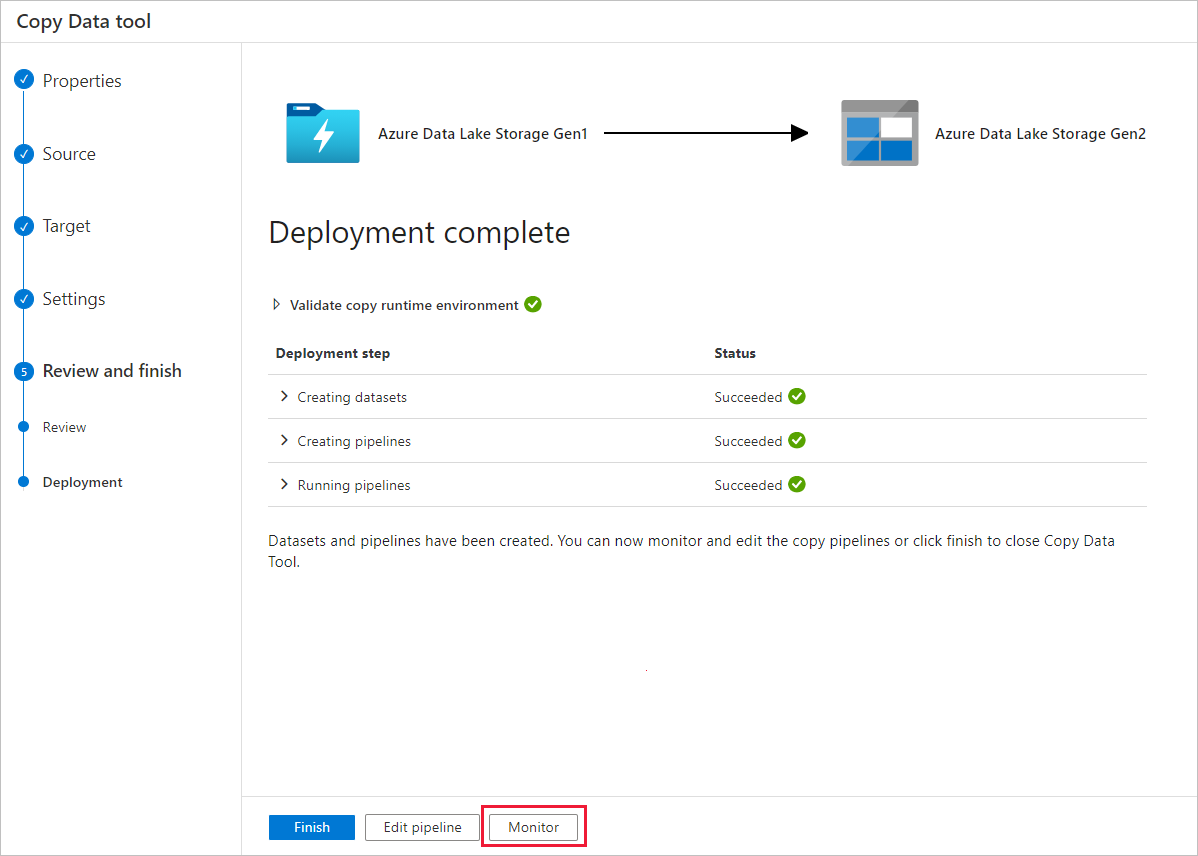
Observera att fliken Övervaka till vänster väljs automatiskt. Kolumnen Pipelinenamn innehåller länkar för att visa aktivitetskörningsinformation och köra pipelinen igen.
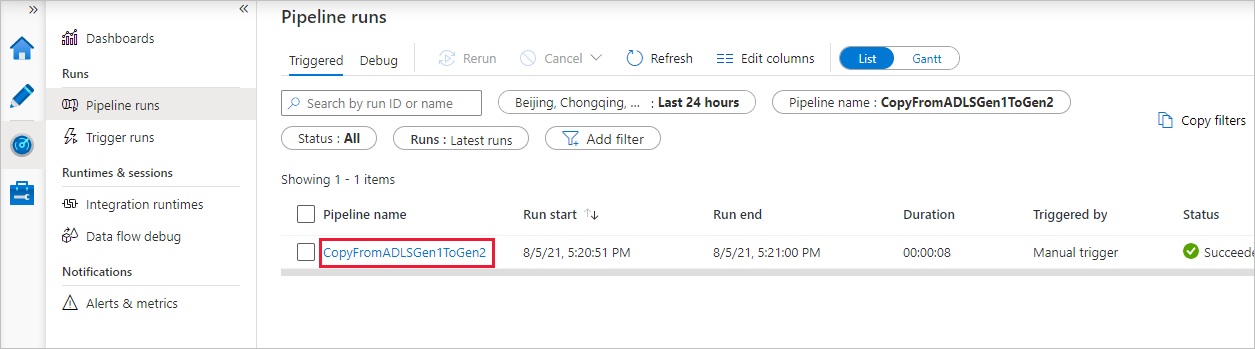
Om du vill visa aktivitetskörningar som är associerade med pipelinekörningen väljer du länken i kolumnen Pipelinenamn . Det finns bara en aktivitet (kopieringsaktiviteten) i pipelinen. Därför visas bara en post. Om du vill växla tillbaka till pipelinekörningsvyn väljer du länken Alla pipelinekörningar i menyn breadcrumb högst upp. Om du vill uppdatera listan väljer du Refresh (Uppdatera).
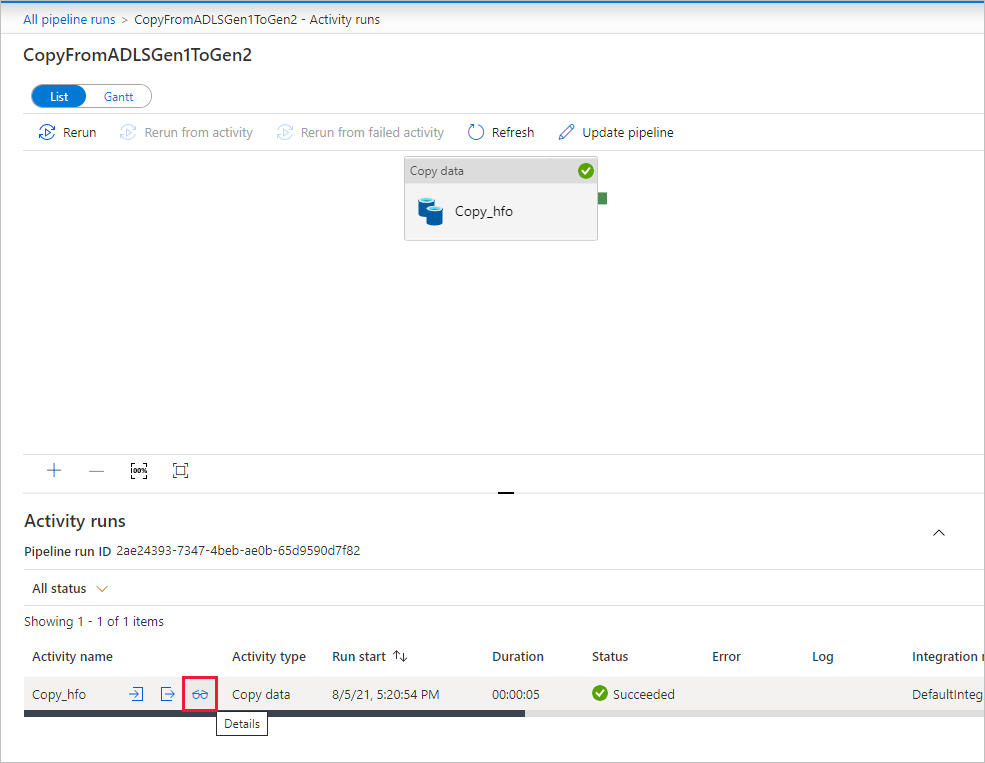
Om du vill övervaka körningsinformationen för varje kopieringsaktivitet väljer du länken Information (glasögonbild) under kolumnen Aktivitetsnamn i aktivitetsövervakningsvyn. Du kan övervaka information som mängden data som kopieras från källan till mottagaren, dataflödet, körningsstegen med motsvarande varaktighet och använda konfigurationer.
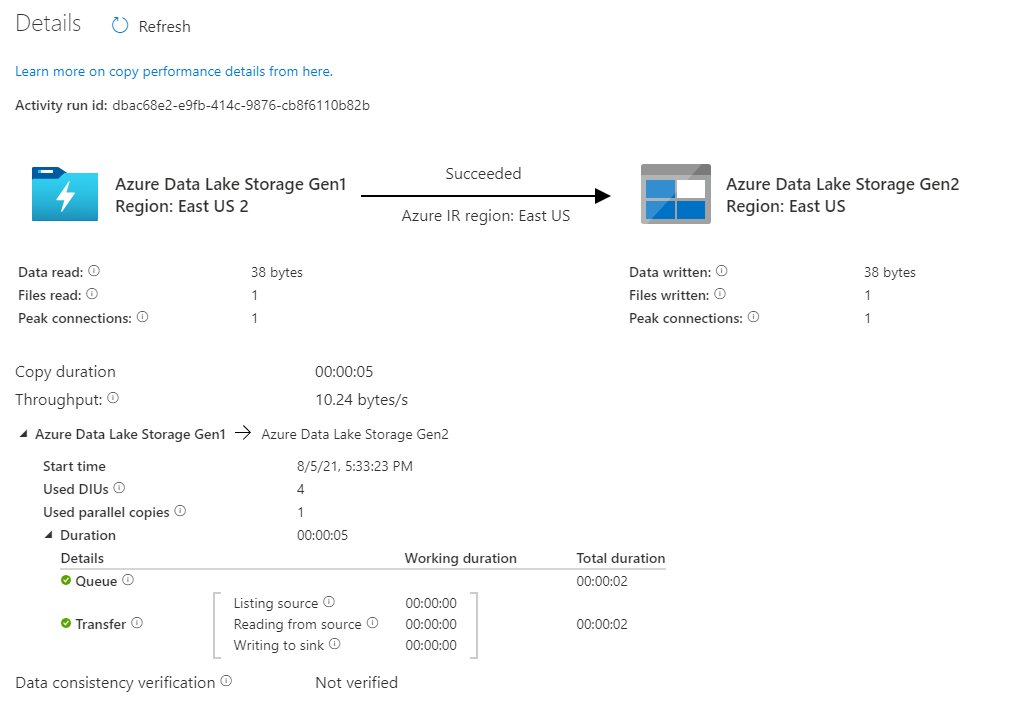
Kontrollera att data kopieras till ditt Azure Data Lake Storage Gen2-konto.
Bästa praxis
Information om hur du utvärderar uppgradering från Azure Data Lake Storage Gen1 till Azure Data Lake Storage Gen2 i allmänhet finns i Uppgradera dina lösningar för stordataanalys från Azure Data Lake Storage Gen1 till Azure Data Lake Storage Gen2. I följande avsnitt beskrivs metodtips för att använda Data Factory för en datauppgradering från Data Lake Storage Gen1 till Data Lake Storage Gen2.
Initial datamigrering av ögonblicksbilder
Prestanda
ADF erbjuder en serverlös arkitektur som möjliggör parallellitet på olika nivåer, vilket gör att utvecklare kan skapa pipelines för att fullt ut utnyttja din nätverksbandbredd samt lagrings-IOPS och bandbredd för att maximera dataflyttens dataflöde för din miljö.
Kunder har migrerat petabyte med data som består av hundratals miljoner filer från Data Lake Storage Gen1 till Gen2, med ett varaktigt dataflöde på 2 GBIT/s och högre.
Du kan uppnå högre dataförflyttningshastigheter genom att tillämpa olika parallellitetsnivåer:
- En enskild kopieringsaktivitet kan dra nytta av skalbara beräkningsresurser: när du använder Azure Integration Runtime kan du ange upp till 256 dataintegreringsenheter (DIUs) för varje kopieringsaktivitet på ett serverlöst sätt. När du använder lokalt installerad integrationskörning kan du skala upp datorn manuellt eller skala ut till flera datorer (upp till 4 noder). och en enskild kopieringsaktivitet partitioneras dess filuppsättning över alla noder.
- En enskild kopieringsaktivitet läser från och skriver till datalagret med hjälp av flera trådar.
- ADF-kontrollflödet kan starta flera kopieringsaktiviteter parallellt, till exempel med hjälp av For Each-loopen.
Datapartitioner
Om din totala datastorlek i Data Lake Storage Gen1 är mindre än 10 TB och antalet filer är mindre än 1 miljon kan du kopiera alla data i en enda kopieringsaktivitet. Om du har en större mängd data att kopiera, eller om du vill ha flexibiliteten att hantera datamigrering i batchar och göra var och en av dem komplett inom en viss tidsram, partitionerar du data. Partitionering minskar också risken för oväntade problem.
Sättet att partitionera filerna är att använda namnintervallet listAfter/listBefore i egenskapen kopiera aktivitet. Varje kopieringsaktivitet kan konfigureras för att kopiera en partition i taget, så att flera kopieringsaktiviteter kan kopiera data från ett enda Data Lake Storage Gen1-konto samtidigt.
Frekvensbegränsning
Vi rekommenderar att du utför en poc-prestanda med en representativ exempeldatauppsättning så att du kan fastställa en lämplig partitionsstorlek.
Börja med en enskild partition och en enskild kopieringsaktivitet med standardinställningen DIU. Parallellkopian föreslås alltid vara tom (standard). Om kopieringsdataflödet inte är bra för dig identifierar och löser du flaskhalsarna i prestanda genom att följa stegen för prestandajustering.
Öka diu-inställningen gradvis tills du når bandbreddsgränsen för nätverket eller IOPS/bandbreddsgränsen för datalager, eller så har du nått max 256 DIU som tillåts för en enda kopieringsaktivitet.
Om du har maximerat prestandan för en enskild kopieringsaktivitet, men ännu inte har uppnått den övre gränsen för dataflödet i din miljö, kan du köra flera kopieringsaktiviteter parallellt.
När du ser ett stort antal begränsningsfel från kopieringsaktivitetsövervakningen indikerar det att du har nått kapacitetsgränsen för ditt lagringskonto. ADF försöker igen automatiskt för att lösa varje begränsningsfel för att se till att inga data går förlorade, men för många återförsök kan också försämra ditt kopieringsdataflöde. I sådana fall uppmanas du att minska antalet kopieringsaktiviteter som körs samtidigt för att undvika betydande mängder begränsningsfel. Om du har använt enstaka kopieringsaktivitet för att kopiera data uppmanas du att minska DIU:et.
Deltadatamigrering
Du kan använda flera metoder för att endast läsa in de nya eller uppdaterade filerna från Data Lake Storage Gen1:
- Läs in nya eller uppdaterade filer efter tid partitionerad mapp eller filnamn. Ett exempel är /2019/05/13/*.
- Läs in nya eller uppdaterade filer av LastModifiedDate. Om du kopierar stora mängder filer ska du först göra partitioner för att undvika låga dataflödesresultat för kopiering från en enda kopieringsaktivitet genom att söka igenom hela Data Lake Storage Gen1-kontot för att identifiera nya filer.
- Identifiera nya eller uppdaterade filer med verktyg eller lösningar från tredje part. Skicka sedan fil- eller mappnamnet till Data Factory-pipelinen via parametern eller en tabell eller fil.
Rätt frekvens för inkrementell belastning beror på det totala antalet filer i Azure Data Lake Storage Gen1 och volymen av nya eller uppdaterade filer som ska läsas in varje gång.
Nätverkssäkerhet
Som standard överför ADF data från Azure Data Lake Storage Gen1 till Gen2 med krypterad anslutning via HTTPS-protokollet. HTTPS tillhandahåller datakryptering under överföring och förhindrar avlyssning och man-in-the-middle-attacker.
Om du inte vill att data ska överföras via offentligt Internet kan du också uppnå högre säkerhet genom att överföra data via ett privat nätverk.
Bevara ACL:er
Om du vill replikera ACL:er tillsammans med datafiler när du uppgraderar från Data Lake Storage Gen1 till Data Lake Storage Gen2 kan du läsa Bevara ACL:er från Data Lake Storage Gen1.
Elasticitet
I en enda kopieringsaktivitetskörning har ADF inbyggd mekanism för återförsök så att den kan hantera en viss nivå av tillfälliga fel i datalager eller i det underliggande nätverket. Om du migrerar mer än 10 TB data uppmanas du att partitionera data för att minska risken för oväntade problem.
Du kan också aktivera feltolerans i kopieringsaktiviteten för att hoppa över de fördefinierade felen. Verifieringen av datakonsekvens i kopieringsaktiviteten kan också aktiveras för att göra ytterligare verifiering för att säkerställa att data inte bara kopieras från källa till målarkiv, utan även verifieras vara konsekventa mellan käll- och målarkivet.
Behörigheter
I Data Factory stöder Data Lake Storage Gen1-anslutningsappen tjänstens huvudnamn och hanterade identitet för Azure-resursautentiseringar. Data Lake Storage Gen2-anslutningsappen stöder kontonyckel, tjänstens huvudnamn och hanterade identitet för Azure-resursautentiseringar. För att datafabriken ska kunna navigera och kopiera alla filer eller åtkomstkontrollistor (ACL:er) måste du ge kontot tillräckligt hög behörighet för att komma åt, läsa eller skriva alla filer och ange ACL:er om du vill. Du bör ge kontot en superanvändare eller ägarroll under migreringsperioden och ta bort de utökade behörigheterna när migreringen har slutförts.
Relaterat innehåll
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för