Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory i Microsoft Fabric är nästa generations Azure Data Factory, med en enklare arkitektur, inbyggd AI och nya funktioner. Om dataintegrering är nytt för dig börjar du med Fabric Data Factory. Befintliga ADF-arbetsbelastningar kan uppgraderas till Fabric för att få åtkomst till nya funktioner inom datavetenskap, realtidsanalys och rapportering.
Ibland vill du utföra en storskalig datamigrering från Data Lake eller Enterprise Data Warehouse (EDW) för att Azure. Andra gånger vill du mata in stora mängder data, från olika källor till Azure, för stordataanalys. I varje fall är det viktigt att uppnå optimal prestanda och skalbarhet.
Azure Data Factory och Azure Synapse Analytics pipelines ger en mekanism för att mata in data med följande fördelar:
- Hanterar stora mängder data
- Är mycket högpresterande
- Är kostnadseffektivt
Dessa fördelar passar utmärkt för datatekniker som vill skapa skalbara pipelines för datainmatning som är mycket högpresterande.
När du har läst den här artikeln kan du svara på följande frågor:
- Vilken prestandanivå och skalbarhet kan jag uppnå med hjälp av kopieringsaktivitet för datamigrering och datainmatningsscenarier?
- Vilka åtgärder ska jag vidta för att justera kopieringsaktivitetens prestanda?
- Vilka prestandaoptimeringar kan jag använda för en enkelt körning av en kopieringsaktivitet?
- Vilka andra externa faktorer att tänka på när du optimerar kopieringsprestanda?
Note
Om du inte är bekant med kopieringsaktiviteten i allmänhet kan du läsa översikten över kopieringsaktiviteten innan du läser den här artikeln.
Kopiera prestanda och skalbarhet som kan uppnås med hjälp av Azure Data Factory- och Synapse-pipelines
Azure Data Factory- och Synapse-pipelines erbjuder en serverlös arkitektur som möjliggör parallellitet på olika nivåer.
Med den här arkitekturen kan du utveckla pipelines som maximerar genomströmningen av dataflytt för din miljö. Dessa pipelines använder följande resurser fullt ut:
- Nätverksbandbredd mellan käll- och måldatalager
- Käll- eller måldatalagerindata/utdataåtgärder per sekund (IOPS) och bandbredd
Den här fullständiga användningen innebär att du kan beräkna det totala dataflödet genom att mäta det minsta tillgängliga dataflödet med följande resurser:
- Källdatalager
- Destinationsdatalager
- Nätverksbandbredd mellan käll- och måldatalager
Tabellen nedan visar beräkningen av dataförflyttningens varaktighet. Varaktigheten i varje cell beräknas baserat på en viss bandbredd för nätverk och datalager och en viss datanyttolaststorlek.
Note
Varaktigheten nedan är avsedd att representera uppnåeliga prestanda i en lösning för dataintegrering från slutpunkt till slutpunkt med hjälp av en eller flera tekniker för prestandaoptimering som beskrivs i Funktioner för kopieringsprestandaoptimering, inklusive användning av ForEach för att partitionera och skapa flera samtidiga kopieringsaktiviteter. Vi rekommenderar att du följer stegen i Prestandajusteringssteg för att optimera kopieringsprestanda för din specifika datauppsättning och systemkonfiguration. Du bör använda de siffror som erhålls i prestandajusteringstesterna för planering av produktionsdistribution, kapacitetsplanering och faktureringsprognos.
| Datastorlek/ bandwidth |
50 Mbit/s | 100 Mbit/s | 500 Mbit/s | 1 Gbit/s | 5 Gbit/s | 10 Gbit/s | 50 Gbit/s |
|---|---|---|---|---|---|---|---|
| 1 GB | 2,7 min | 1,4 min | 0,3 min | 0,1 min | 0,03 min | 0,01 min | 0,0 min |
| 10 GB | 27,3 min | 13,7 min | 2,7 min | 1,3 min | 0,3 min | 0,1 min | 0,03 min |
| 100 GB | 4,6 timmar | 2,3 timmar | 0,5 timmar | 0,2 timmar | 0,05 timmar | 0,02 timmar | 0,0 timmar |
| 1 TB | 46,6 timmar | 23,3 timmar | 4,7 timmar | 2,3 timmar | 0,5 timmar | 0,2 timmar | 0,05 timmar |
| 10 TB | 19,4 dagar | 9,7 dagar | 1,9 dagar | 0,9 dagar | 0,2 dagar | 0,1 dagar | 0,02 dagar |
| 100 TB | 194,2 dagar | 97,1 dagar | 19,4 dagar | 9,7 dagar | 1,9 dagar | 1 dag | 0,2 dagar |
| 1 PB | 64,7 mån | 32,4 mån | 6,5 mån | 3,2 månader | 0,6 mån | 0,3 mån | 0,06 mo |
| 10 PB | 647,3 mån | 323,6 månader | 64,7 mån | 31,6 mån | 6,5 mån | 3,2 månader | 0,6 mån |
Kopiering är skalbar på olika nivåer:
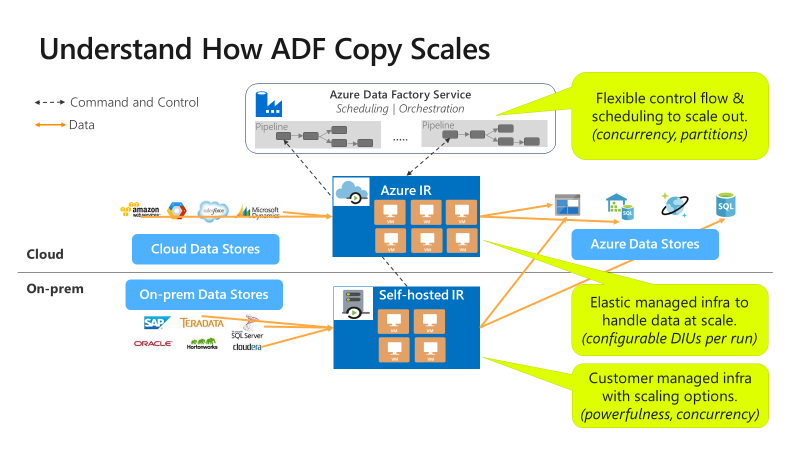
Kontrollflödet kan starta flera kopieringsaktiviteter parallellt, till exempel med hjälp av For Each-loopen.
En enskild kopieringsaktivitet kan dra nytta av skalbara beräkningsresurser.
- När du använder Azure integreringskörning (IR) kan du ange upp till 256 dataintegreringsenheter (DIUs) för varje kopieringsaktivitet på ett serverlöst sätt.
- När du använder lokalt installerad IR kan du använda någon av följande metoder:
- Skala upp datorn manuellt.
- Skala ut till flera datorer (upp till 4 noder), och en enskild kopieringsaktivitet kommer att partitionera filuppsättningen över alla noder.
En enskild kopieringsaktivitet läser från och skriver till datalagret med flera trådar parallellt.
Steg för prestandajustering
Utför följande steg för att justera tjänstens prestanda med kopieringsaktiviteten:
Hämta en testdatauppsättning och upprätta en baslinje.
Under utvecklingen testar du pipelinen med hjälp av kopieringsaktiviteten mot ett representativt dataexempel. Den datauppsättning du väljer bör representera dina typiska datamönster längs följande attribut:
- Mappstrukturen
- Filmönster
- Datamodell
Och datamängden bör vara tillräckligt stor för att utvärdera kopieringsprestanda. En bra storlek tar minst 10 minuter innan kopieringsaktiviteten slutförs. Samla in körningsinformation och prestandaegenskaper efter kopieringsaktivitetsövervakning.
Så här maximerar du prestanda för en enskild kopieringsaktivitet:
Vi rekommenderar att du först maximerar prestandan med hjälp av en enda kopieringsaktivitet.
Om kopieringsaktiviteten körs på en Azure integrationskörning:
Börja med standardvärden för Dataintegration-enheter (DIU) och parallella kopieringsinställningar.
Om kopieringsaktiviteten körs på en lokalt installerad integrationskörning :
Vi rekommenderar att du använder en dedikerad dator som värd för IR. Datorn ska vara separat från servern som är värd för datalagret. Börja med standardvärden för parallell kopieringsinställning och använd en enda nod för den lokalt installerade IR:en.
Utför en prestandatestkörning. Anteckna den uppnådda prestandan. Inkludera de faktiska värden som används, till exempel DIU:er och parallella kopior. Se 'övervakning av kopieringsaktivitet' för information om hur du samlar in körningsresultat och vilka prestandainställningar som används. Lär dig hur du felsöker prestanda för kopieringsaktivitet för att identifiera och lösa flaskhalsen.
Iterera för att utföra fler prestandatestkörningar enligt vägledningen för felsökning och justering. När enstaka kopieringsaktivitet inte uppnår bättre dataflöde kan du överväga att maximera det sammanlagda dataflödet genom att köra flera kopieringsaktiviteter samtidigt. Det här alternativet beskrivs i nästa numrerade punkt.
Så här maximerar du aggregerat dataflöde genom att köra flera kopior samtidigt:
Nu har du maximerat prestandan för en enskild kopieringsaktivitet. Om du ännu inte har uppnått den övre gränsen för dataflödet i din miljö kan du köra flera kopieringsaktiviteter parallellt. Du kan köra parallellt med hjälp av kontrollflödeskonstruktioner. En sådan konstruktion är For Each-loopen. Mer information finns i följande artiklar om lösningsmallar:
Expandera konfigurationen till hela datauppsättningen.
När du är nöjd med körningsresultatet och prestandan kan du expandera definitionen och pipelinen för att täcka hela datamängden.
Felsök prestandaproblem vid kopieringsaktivitet
Följ stegen för prestandajustering för att planera och utföra prestandatest för ditt scenario. Och lär dig hur du felsöker prestandaproblem vid varje körning av en kopieringsaktivitet från Felsöka kopieringsaktivitetens prestanda.
Kopiera prestandaoptimeringsfunktioner
Tjänsten tillhandahåller följande funktioner för prestandaoptimering:
- Dataintegrationsenheter
- Skalbarhet för lokalt installerad integrationskörning
- Parallel kopiering
- Mellanlagrad kopia
Dataintegrationsenheter
En dataintegreringsenhet (DIU) är ett mått som representerar kraften i en enda enhet i Azure Data Factory- och Synapse-pipelines. Ström är en kombination av processor-, minnes- och nätverksresursallokering. DIU gäller endast för Azure integration runtime. DIU gäller inte för lokalt installerad integrationskörning. Mer information finns här.
Skalbarhet för lokalt installerad integrationskörning
Du kanske vill hantera en samtidigt ökande arbetsbelastning. Eller så kanske du vill uppnå högre prestanda på din nuvarande arbetsbelastningsnivå. Du kan förbättra bearbetningens skala med hjälp av följande metoder:
- Du kan skala upp den lokalt installerade IR:en genom att öka antalet samtidiga jobb som kan köras på en nod.
Uppskalning fungerar bara om nodens processor och minne är mindre än fullt utnyttjat. - Du kan skala ut den lokalt installerade IR:en genom att lägga till fler noder (datorer).
Mer information finns i:
- Funktioner för prestandaoptimering av kopieringsaktiviteter: Skalbarhet för självhanterad integrationsmiljö
- Skapa och konfigurera en lokalt installerad integrationskörning: Skalningsöverväganden
Parallell kopiering
Du kan ange egenskapen parallelCopies för att ange den parallellitet som du vill att kopieringsaktiviteten ska använda. Tänk på den här egenskapen som det maximala antalet trådar i kopieringsaktiviteten. Trådarna fungerar parallellt. Trådarna läser antingen från källan eller skriver till dina mottagardatalager.
Läs mer.
Förberedd kopia
En datakopieringsåtgärd kan skicka data direkt till mottagardatalager. Du kan också välja att använda Blob Storage som ett mellanlagringslager . Läs mer.
Relaterat innehåll
Se de andra artiklarna om kopieringsaktivitet: