Prestandaoptimeringsfunktioner för kopieringsaktivitet
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Den här artikeln beskriver funktionerna för prestandaoptimering av kopieringsaktivitet som du kan använda i Azure Data Factory- och Synapse-pipelines.
Konfigurera prestandafunktioner med användargränssnittet
När du väljer en kopieringsaktivitet på pipelineredigerarens arbetsyta och väljer fliken Inställningar i aktivitetskonfigurationsområdet under arbetsytan visas alternativ för att konfigurera alla prestandafunktioner som beskrivs nedan.
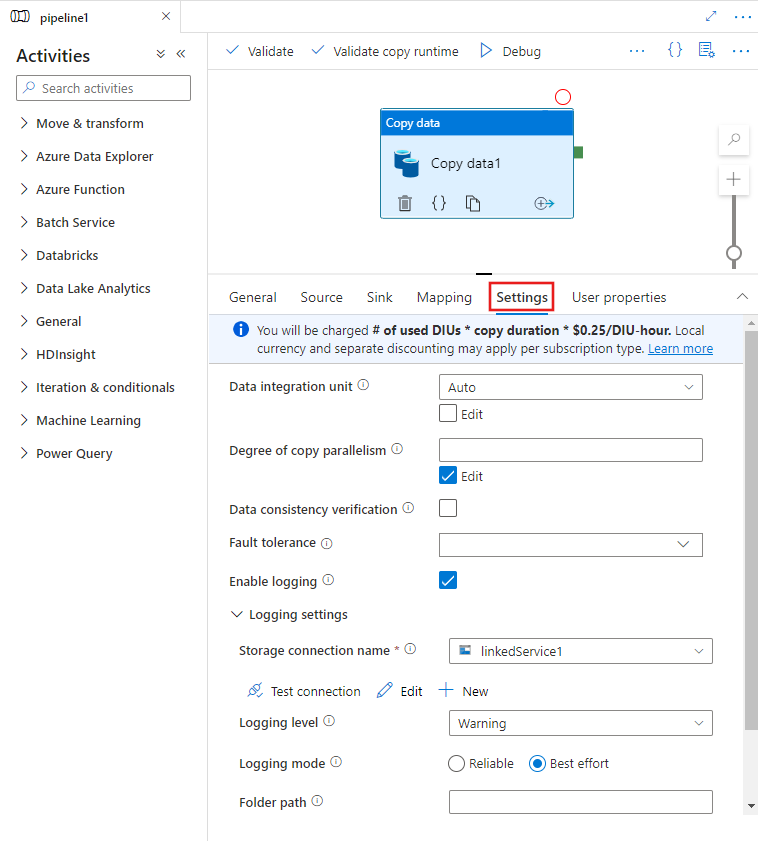
Dataintegrationsenheter
En dataintegreringsenhet är ett mått som representerar kraften (en kombination av PROCESSOR, minne och resursallokering av nätverk) för en enda enhet i tjänsten. Dataintegreringsenheten gäller endast för Azure Integration Runtime, men inte lokalt installerad integrationskörning.
Tillåtna DIUs för att ge en kopieringsaktivitetskörning mellan 4 och 256. Om det inte anges eller om du väljer "Auto" i användargränssnittet tillämpar tjänsten dynamiskt den optimala DIU-inställningen baserat på ditt käll-mottagarpar och datamönster. I följande tabell visas de DIU-intervall som stöds och standardbeteendet i olika kopieringsscenarier:
| Kopiera scenario | DIU-intervall som stöds | Standard-DIU:er som bestäms av tjänsten |
|---|---|---|
| Mellan fillager | - Kopiera från eller till en enskild fil: 4 - Kopiera från och till flera filer: 4–256 beroende på antalet och storleken på filerna Om du till exempel kopierar data från en mapp med 4 stora filer och väljer att bevara hierarkin är den maximala effektiva DIU:en 16. När du väljer att sammanfoga filen är den maximala effektiva DIU:en 4. |
Mellan 4 och 32 beroende på antalet och storleken på filerna |
| Från filarkiv till icke-filarkiv | - Kopiera från en enskild fil: 4 - Kopiera från flera filer: 4–256 beroende på antalet och storleken på filerna Om du till exempel kopierar data från en mapp med 4 stora filer är den maximala effektiva DIU:en 16. |
- Kopiera till Azure SQL Database eller Azure Cosmos DB: mellan 4 och 16 beroende på mottagarnivån (DTU:er/RU:er) och källfilmönstret - Kopiera till Azure Synapse Analytics med polybase- eller COPY-instruktion: 2 – Annat scenario: 4 |
| Från arkiv som inte är fil till filarkiv | - Kopiera från partitionsalternativaktiverade datalager (inklusive Azure Database for PostgreSQL, Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SQL Server och Teradata): 4–256 när du skriver till en mapp och 4 när du skriver till en enda fil. Observera att datapartitionen per källa kan använda upp till 4 DIU:er. - Andra scenarier: 4 |
- Kopiera från REST eller HTTP: 1 - Kopiera från Amazon Redshift med HJÄLP av UNLOAD: 4 - Annat scenario: 4 |
| Mellan icke-fillager | - Kopiera från partitionsalternativaktiverade datalager (inklusive Azure Database for PostgreSQL, Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SQL Server och Teradata): 4–256 när du skriver till en mapp och 4 när du skriver till en enda fil. Observera att datapartitionen per källa kan använda upp till 4 DIU:er. - Andra scenarier: 4 |
- Kopiera från REST eller HTTP: 1 - Annat scenario: 4 |
Du kan se de DIU:er som används för varje kopieringskörning i övervakningsvyn för kopieringsaktivitet eller aktivitetsutdata. Mer information finns i Kopiera aktivitetsövervakning. Om du vill åsidosätta den här standardinställningen anger du ett värde för egenskapen enligt dataIntegrationUnits följande. Det faktiska antalet DIU:er som kopieringsåtgärden använder vid körning är lika med eller mindre än det konfigurerade värdet, beroende på ditt datamönster.
Du debiteras antal använda DIU:er * kopieringstid * enhetspris/DIU-timme. Se aktuella priser här. Lokal valuta och separat rabatt kan gälla per prenumerationstyp.
Exempel:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"dataIntegrationUnits": 128
}
}
]
Skalbarhet för lokalt installerad integrationskörning
Om du vill uppnå högre dataflöde kan du antingen skala upp eller skala ut lokalt installerad IR:
- Om processorn och det tillgängliga minnet på den lokalt installerade IR-noden inte används fullt ut, men körningen av samtidiga jobb når gränsen, bör du skala upp genom att öka antalet samtidiga jobb som kan köras på en nod. Se här för instruktioner.
- Om processorn å andra sidan är hög på IR-noden med egen värd eller om det finns ont om minne kan du lägga till en ny nod för att skala ut belastningen över flera noder. Se här för instruktioner.
Observera att i följande scenarier kan körning av enstaka kopieringsaktivitet utnyttja flera IR-noder med egen värd:
- Kopiera data från filbaserade lager, beroende på antalet och storleken på filerna.
- Kopiera data från partitionsalternativaktiverat datalager (inklusive Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server och Teradata), beroende på antalet datapartitioner.
Parallell kopiering
Du kan ange parallell kopiering (parallelCopiesegenskap i JSON-definitionen för kopieringsaktiviteten eller Degree of parallelism inställningen på fliken Inställningar i egenskaperna för kopieringsaktiviteten i användargränssnittet) för kopieringsaktiviteten för att ange den parallellitet som du vill att kopieringsaktiviteten ska använda. Du kan se den här egenskapen som det maximala antalet trådar i kopieringsaktiviteten som läser från källan eller skriver till dina mottagardatalager parallellt.
Den parallella kopian är ortoggonisk för dataintegreringsenheter eller lokalt installerade IR-noder. Den räknas över alla DIU:er eller IR-noder med egen värd.
För varje kopieringsaktivitetskörning tillämpar tjänsten som standard dynamiskt den optimala parallella kopieringsinställningen baserat på ditt käll-mottagarpar och datamönster.
Dricks
Standardbeteendet för parallell kopiering ger dig vanligtvis det bästa dataflödet, vilket bestäms automatiskt av tjänsten baserat på ditt käll-mottagarpar, datamönster och antalet DIU:er eller antalet lokalt installerade IR:er cpu/minne/noder. Se Felsöka prestanda för kopieringsaktivitet när parallell kopiering ska justeras.
I följande tabell visas det parallella kopieringsbeteendet:
| Kopiera scenario | Parallell kopieringsbeteende |
|---|---|
| Mellan fillager | parallelCopies avgör parallelliteten på filnivå. Segmenteringen i varje fil sker under automatiskt och transparent. Den är utformad för att använda den bästa lämpliga segmentstorleken för en viss datalagertyp för att läsa in data parallellt. Det faktiska antalet parallella kopior som kopieringsaktiviteten använder vid körning är inte mer än antalet filer som du har. Om kopieringsbeteendet är mergeFile i filmottagaren kan kopieringsaktiviteten inte dra nytta av parallellitet på filnivå. |
| Från filarkiv till icke-filarkiv | – När du kopierar data till Azure SQL Database eller Azure Cosmos DB beror standardparallell kopiering också på mottagarnivån (antal DTU:er/RU:er). – När du kopierar data till Azure Table är standardparallell kopiering 4. |
| Från arkiv som inte är fil till filarkiv | – När du kopierar data från partitionsalternativaktiverat datalager (inklusive Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Amazon RDS för Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server, Amazon RDS för SQL Server och Teradata) är standardparallell kopiering 4. Det faktiska antalet parallella kopior som kopieringsaktiviteten använder vid körning är inte mer än det antal datapartitioner som du har. Observera att den maximala effektiva parallella kopian är 4 eller 5 per IR-nod när du använder lokalt installerad integrationskörning och kopierar till Azure Blob/ADLS Gen2. – För andra scenarier börjar parallellkopiering inte gälla. Även om parallellitet anges tillämpas den inte. |
| Mellan icke-fillager | – När du kopierar data till Azure SQL Database eller Azure Cosmos DB beror standardparallell kopiering också på mottagarnivån (antal DTU:er/RU:er). – När du kopierar data från partitionsalternativaktiverat datalager (inklusive Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Amazon RDS för Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server, Amazon RDS för SQL Server och Teradata) är standardparallell kopiering 4. – När du kopierar data till Azure Table är standardparallell kopiering 4. |
Om du vill styra belastningen på datorer som är värdar för dina datalager eller justera kopieringsprestandan kan du åsidosätta standardvärdet och ange ett värde för parallelCopies egenskapen. Värdet måste vara ett heltal som är större än eller lika med 1. Vid körning använder kopieringsaktiviteten för bästa prestanda ett värde som är mindre än eller lika med det värde som du anger.
När du anger ett värde för parallelCopies egenskapen tar du hänsyn till belastningsökningen på dina käll- och mottagardatalager. Tänk också på belastningsökningen till den lokalt installerade integrationskörningen om kopieringsaktiviteten är aktiverad av den. Den här belastningsökningen sker särskilt när du har flera aktiviteter eller samtidiga körningar av samma aktiviteter som körs mot samma datalager. Om du märker att antingen datalagret eller den lokalt installerade integrationskörningen är överbelastad med belastningen parallelCopies minskar du värdet för att minska belastningen.
Exempel:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"parallelCopies": 32
}
}
]
Mellanlagrad kopia
När du kopierar data från ett källdatalager till ett datalager för mottagare kan du välja att använda Azure Blob Storage eller Azure Data Lake Storage Gen2 som ett mellanlagringslager. Mellanlagring är särskilt användbart i följande fall:
- Du vill mata in data från olika datalager i Azure Synapse Analytics via PolyBase, kopiera data från/till Snowflake eller mata in data från Amazon Redshift/HDFS med hög prestanda. Läs mer om:
- Du vill inte öppna andra portar än port 80 och port 443 i brandväggen på grund av företagets IT-principer. När du till exempel kopierar data från ett lokalt datalager till en Azure SQL Database eller en Azure Synapse Analytics måste du aktivera utgående TCP-kommunikation på port 1433 för både Windows-brandväggen och företagets brandvägg. I det här scenariot kan mellanlagrade kopior dra nytta av den lokala integrationskörningen för att först kopiera data till en mellanlagring via HTTP eller HTTPS på port 443 och sedan läsa in data från mellanlagringen till SQL Database eller Azure Synapse Analytics. I det här flödet behöver du inte aktivera port 1433.
- Ibland tar det ett tag att utföra en hybriddataflytt (det vill: att kopiera från ett lokalt datalager till ett molndatalager) via en långsam nätverksanslutning. För att förbättra prestandan kan du använda mellanlagrad kopia för att komprimera data lokalt så att det tar mindre tid att flytta data till mellanlagringsdatalagret i molnet. Sedan kan du dekomprimera data i mellanlagringslagret innan du läser in i måldatalagret.
Så här fungerar mellanlagrad kopiering
När du aktiverar mellanlagringsfunktionen kopieras först data från källdatalagret till mellanlagringen (ta med din egen Azure Blob eller Azure Data Lake Storage Gen2). Därefter kopieras data från mellanlagringen till datalagret för mottagare. Kopieringsaktiviteten hanterar automatiskt tvåstegsflödet åt dig och rensar även tillfälliga data från mellanlagringen när dataflytten är klar.

Du måste bevilja borttagningsbehörighet till Din Azure Data Factory i mellanlagringen så att temporära data kan rensas när kopieringsaktiviteten har körts.
När du aktiverar dataflytt med hjälp av ett mellanlagringslager kan du ange om du vill att data ska komprimeras innan du flyttar data från källdatalagret till mellanlagringslagret och sedan dekomprimeras innan du flyttar data från ett mellanliggande datalager eller mellanlagringsdatalager till datalagret för mottagare.
För närvarande kan du inte kopiera data mellan två datalager som är anslutna via olika lokalt installerade IR:er, varken med eller utan mellanlagrad kopiering. I ett sådant scenario kan du konfigurera två explicit länkade kopieringsaktiviteter för att kopiera från källa till mellanlagring och sedan från mellanlagring till mottagare.
Konfiguration
Konfigurera inställningen enableStaging i kopieringsaktiviteten för att ange om du vill att data ska mellanlagras i lagring innan du läser in dem i ett måldatalager. När du anger enableStaging till TRUEanger du de ytterligare egenskaper som anges i följande tabell.
| Property | Beskrivning | Standardvärde | Obligatoriskt |
|---|---|---|---|
| enableStaging | Ange om du vill kopiera data via ett mellanlagringslager. | Falsk | Nej |
| linkedServiceName | Ange namnet på en länkad Azure Blob Storage - eller Azure Data Lake Storage Gen2-tjänst , som refererar till den lagringsinstans som du använder som ett mellanlagringslager. | Ej tillämpligt | Ja, när enableStaging är inställt på TRUE |
| path | Ange den sökväg som du vill innehålla mellanlagrade data. Om du inte anger någon sökväg skapar tjänsten en container för att lagra temporära data. | Ej tillämpligt | Nej (Ja när storageIntegration i Snowflake-anslutningsprogrammet har angetts) |
| enableCompression | Anger om data ska komprimeras innan de kopieras till målet. Den här inställningen minskar mängden data som överförs. | Falsk | Nej |
Kommentar
Om du använder mellanlagrad kopia med komprimering aktiverat stöds inte tjänstens huvudnamn eller MSI-autentisering för mellanlagring av länkade blobar.
Här är en exempeldefinition av en kopieringsaktivitet med de egenskaper som beskrivs i föregående tabell:
"activities":[
{
"name": "CopyActivityWithStaging",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "OracleSource",
},
"sink": {
"type": "SqlDWSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "stagingcontainer/path"
}
}
}
]
Faktureringspåverkan mellanlagrad kopiering
Du debiteras baserat på två steg: kopieringstid och kopieringstyp.
- När du använder mellanlagring under en molnkopia, som kopierar data från ett molndatalager till ett annat molndatalager, båda stegen som möjliggörs av Azure Integration Runtime, debiteras du [summan av kopieringstiden för steg 1 och steg 2] x [enhetspris för molnkopiering].
- När du använder mellanlagring under en hybridkopia, som kopierar data från ett lokalt datalager till ett molndatalager, en fas som möjliggörs av en lokalt installerad integrationskörning, debiteras du för [hybridkopieringsvaraktighet] x [hybridkopieringsenhetspris] + [varaktighet för molnkopiering] x [pris för molnkopieringsenhet].
Relaterat innehåll
Se de andra artiklarna om kopieringsaktivitet:
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för