Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tips
Data Factory i Microsoft Fabric är nästa generations Azure Data Factory, med en enklare arkitektur, inbyggd AI och nya funktioner. Om dataintegrering är nytt för dig börjar du med Fabric Data Factory. Befintliga ADF-arbetsbelastningar kan uppgraderas till Fabric för att få åtkomst till nya funktioner inom datavetenskap, realtidsanalys och rapportering.
HDInsight MapReduce-aktiviteten i ett Azure Data Factory- eller Synapse Analytics-pipeline anropar MapReduce-programmet på din egen HDInsight-kluster eller på ett på begäran HDInsight-kluster. Den här artikeln bygger på artikeln om datatransformeringsaktiviteter , som visar en allmän översikt över datatransformering och de omvandlingsaktiviteter som stöds.
Läs igenom introduktionsartiklarna för Azure Data Factory och Synapse Analytics och gör självstudien: Tutorial: transformera data innan du läser den här artikeln.
Se Pig och Hive för detaljer om hur du kör Pig/Hive-skript på ett HDInsight-kluster från en pipeline genom att använda HDInsight Pig och Hive-aktiviteter.
Lägga till en HDInsight MapReduce-aktivitet i en pipeline med användargränssnittet
Utför följande steg för att använda en HDInsight MapReduce-aktivitet till en pipeline:
Sök efter MapReduce i panelen för pipelineaktiviteter och dra en MapReduce-aktivitet till arbetsytan för pipeline.
Välj den nya MapReduce-aktiviteten på arbetsytan om den inte redan är markerad.
Välj fliken HDI-kluster för att välja eller skapa en ny länkad tjänst till ett HDInsight-kluster som ska användas för att köra MapReduce-aktiviteten.
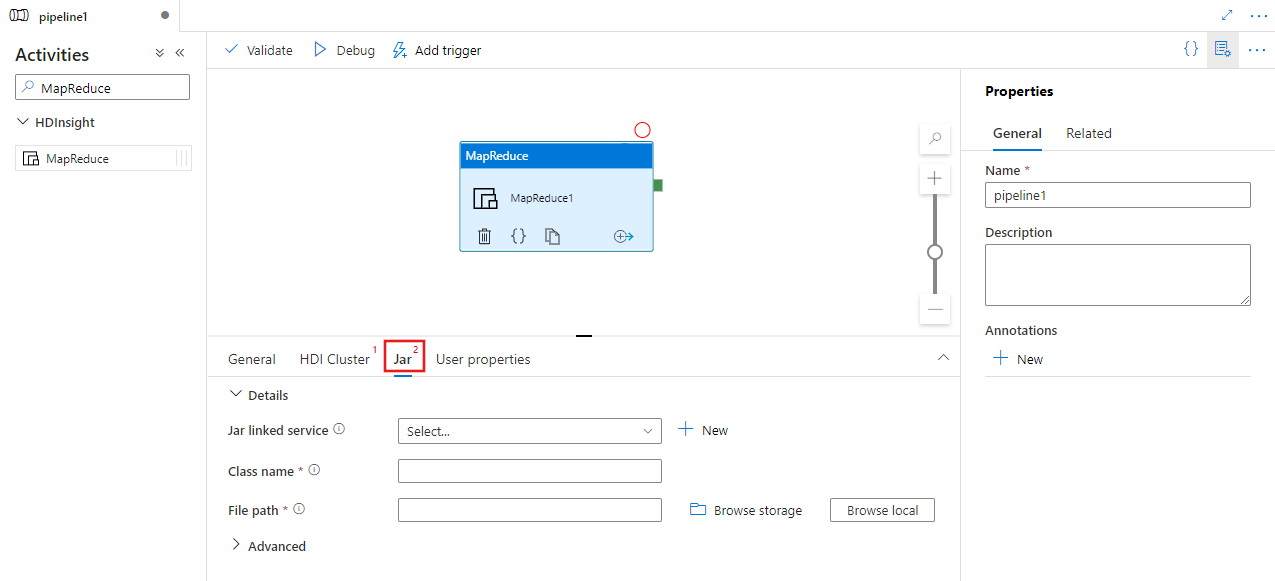
Välj fliken Jar för att välja eller skapa en ny länkad jar-tjänst till ett Azure Storage konto som ska vara värd för skriptet. Ange ett klassnamn som ska köras där och en filsökväg på lagringsplatsen. Du kan också konfigurera avancerad information, inklusive en Jar libs-plats, felsökningskonfiguration och argument och parametrar som ska skickas till skriptet.
Syntax
{
"name": "Map Reduce Activity",
"description": "Description",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.myorg.SampleClass",
"jarLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "MyAzureStorage/jars/sample.jar",
"getDebugInfo": "Failure",
"arguments": [
"-SampleHadoopJobArgument1"
],
"defines": {
"param1": "param1Value"
}
}
}
Syntaxinformation
| Egenskap | Beskrivning | Obligatoriskt |
|---|---|---|
| namn | Namnet på aktiviteten | Ja |
| beskrivning | Text som beskriver vad aktiviteten används för | Nej |
| typ | För MapReduce-aktivitet är aktivitetstypen HDinsightMapReduce | Ja |
| länkadTjänstNamn | Referens till HDInsight-klustret som registrerats som en länkad tjänst. Mer information om den här länkade tjänsten finns i artikeln Compute linked services (Beräkningslänkade tjänster ). | Ja |
| className | Namnet på den klass som ska köras | Ja |
| jarLinkedService | Referens till en Azure Storage länkad tjänst som används för att lagra Jar-filerna. Här stöds endast Azure Blob Storage och ADLS Gen2 länkade tjänster. Om du inte anger den här länkade tjänsten används den Azure Storage-länkade tjänsten som definieras i HDInsight-länkad tjänst. | Nej |
| jarFilePath | Ange sökvägen till jar-filerna som lagras i Azure Storage som refereras av jarLinkedService. Filnamnet är skiftlägeskänsligt. | Ja |
| jarlibs | Strängfält för sökvägen till Jar-biblioteksfiler som refereras av jobbet, lagrade i Azure Storage, definierat i jarLinkedService. Filnamnet är skiftlägeskänsligt. | Nej |
| getDebugInfo | Anger när loggfilerna kopieras till den Azure Storage som används av HDInsight-klustret (eller) som anges av jarLinkedService. Tillåtna värden: Ingen, Alltid eller Fel. Standardvärde: Ingen. | Nej |
| Argument | Anger en matris med argument för ett Hadoop-jobb. Argumenten skickas som kommandoradsargument till varje uppgift. | Nej |
| Definierar | Ange parametrar som nyckel/värde-par för referens i Hive-skriptet. | Nej |
Exempel
Du kan använda HDInsight MapReduce-aktiviteten för att köra valfri MapReduce-jar-fil i ett HDInsight-kluster. I följande JSON-exempeldefinition för en pipeline konfigureras HDInsight-aktiviteten för att köra en Mahout JAR-fil.
{
"name": "MapReduce Activity for Mahout",
"description": "Custom MapReduce to generate Mahout result",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.apache.mahout.cf.taste.hadoop.similarity.item.ItemSimilarityJob",
"jarLinkedService": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "adfsamples/Mahout/jars/mahout-examples-0.9.0.2.2.7.1-34.jar",
"arguments": [
"-s",
"SIMILARITY_LOGLIKELIHOOD",
"--input",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/input",
"--output",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/output/",
"--maxSimilaritiesPerItem",
"500",
"--tempDir",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/temp/mahout"
]
}
}
Du kan ange eventuella argument för MapReduce-programmet i avsnittet argument . Vid körning visas några extra argument (till exempel mapreduce.job.tags) från MapReduce-ramverket. Om du vill särskilja argumenten med MapReduce-argumenten bör du överväga att använda både alternativ och värde som argument som visas i följande exempel (-s,--input,--output osv., är alternativ omedelbart följt av deras värden).
Relaterat innehåll
Se följande artiklar som förklarar hur du transformerar data på andra sätt: