Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tips
Data Factory i Microsoft Fabric är nästa generations Azure Data Factory, med en enklare arkitektur, inbyggd AI och nya funktioner. Om dataintegrering är nytt för dig börjar du med Fabric Data Factory. Befintliga ADF-arbetsbelastningar kan uppgraderas till Fabric för att få åtkomst till nya funktioner inom datavetenskap, realtidsanalys och rapportering.
En pipeline i en Azure Data Factory- eller Synapse Analytics-arbetsyta bearbetar data i länkade lagringstjänster med hjälp av länkade beräkningstjänster. Den innehåller en sekvens med aktiviteter där varje aktivitet utför en specifik bearbetningsåtgärd. I den här artikeln beskrivs Data Lake Analytics U-SQL Activity som kör ett skript U-SQL på ett Azure Data Lake Analytics beräkningslänkad tjänst.
Skapa ett Azure Data Lake Analytics konto innan du skapar en pipeline med en Data Lake Analytics U-SQL-aktivitet. Mer information om Azure Data Lake Analytics finns i Komma igång med Azure Data Lake Analytics.
Lägga till en U-SQL-aktivitet för Azure Data Lake Analytics till en pipeline med användargränssnittet
Utför följande steg för att använda en U-SQL-aktivitet för Azure Data Lake Analytics i en pipeline:
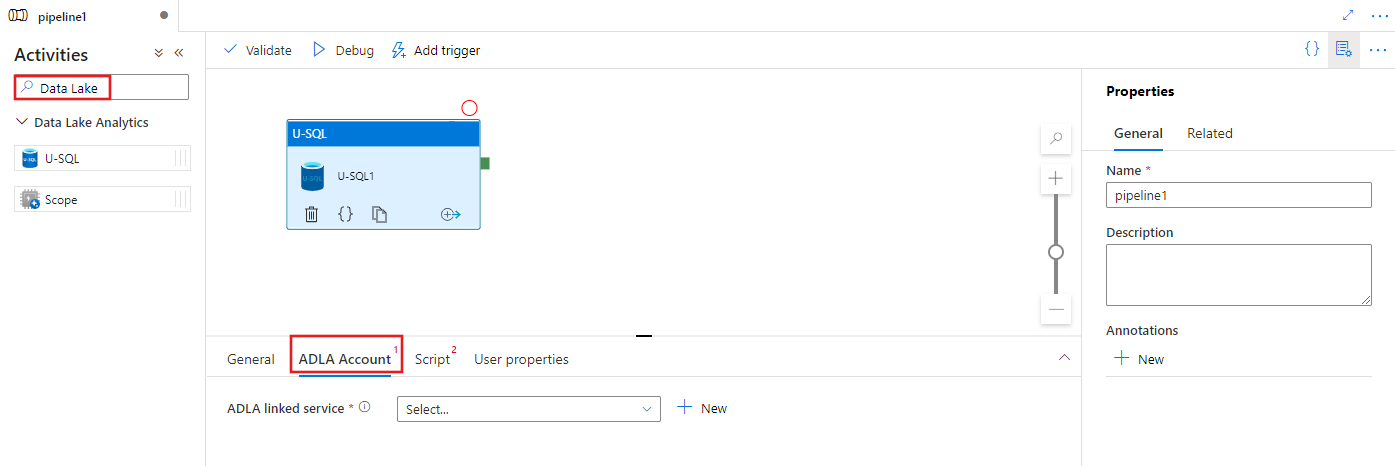
Sök efter Data Lake i panelet Pipelineaktiviteter och dra en U-SQL-aktivitet till arbetsytan för pipeline.
Välj den nya U-SQL-aktiviteten på arbetsytan om den inte redan är markerad.
Välj fliken ADLA-konto för att välja eller skapa en ny Azure Data Lake Analytics länkad tjänst som ska användas för att köra U-SQL-aktiviteten.
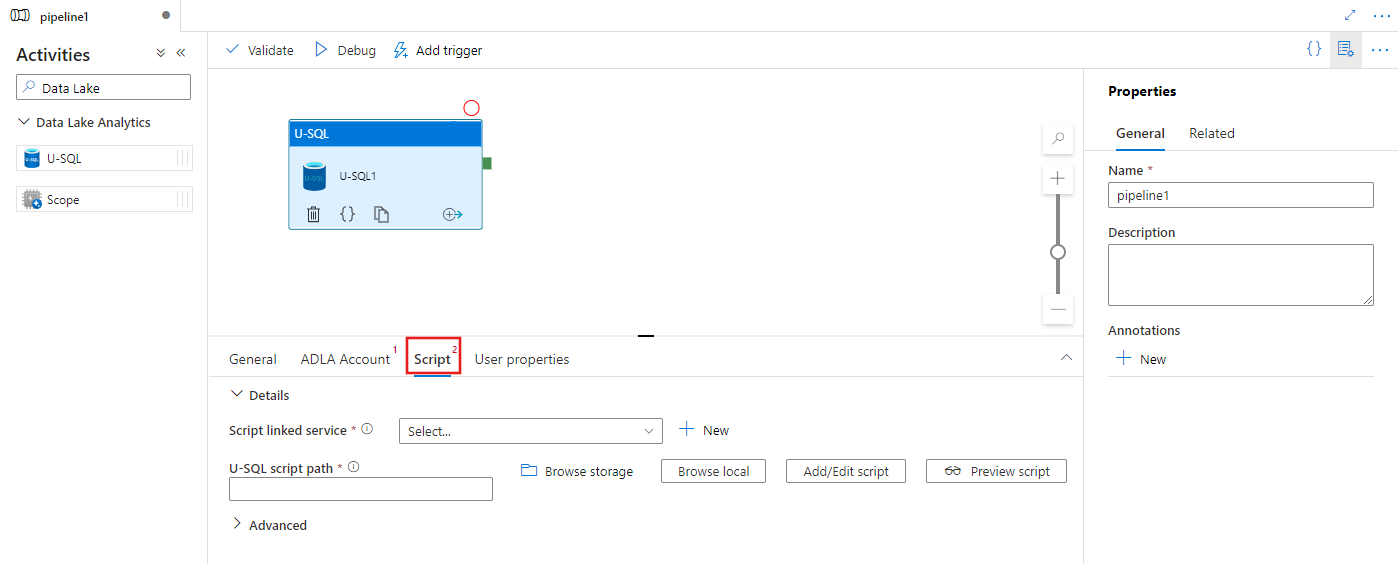
Välj fliken Skript för att välja eller skapa en ny länkad lagringstjänst och en sökväg på lagringsplatsen som ska vara värd för skriptet.
Azure Data Lake Analytics länkad tjänst
Du skapar en Azure Data Lake Analytics länkad tjänst för att länka en Azure Data Lake Analytics beräkningstjänst till en Azure Data Factory- eller Synapse Analytics-arbetsyta. Data Lake Analytics U-SQL-aktiviteten i pipelinen hänvisar till denna anslutna tjänst.
Följande tabell innehåller beskrivningar för de allmänna egenskaper som används i JSON-definitionen.
| Egenskap | Beskrivning | Obligatoriskt |
|---|---|---|
| typ | Typegenskapen ska anges till: AzureDataLakeAnalytics. | Ja |
| accountName | Azure Data Lake Analytics kontonamn. | Ja |
| dataLakeAnalyticsUri | Azure Data Lake Analytics URI. | Nej |
| subscriptionId | Azure prenumerations-ID | Nej |
| resourceGroupName | Azure resursgruppsnamn | Nej |
Tjänstens huvudautentisering
Azure Data Lake Analytics-länkad tjänst kräver tjänstehuvudautentisering för att ansluta till tjänsten. Om du vill använda autentisering med tjänstens huvudnamn registrerar du en programentitet i Microsoft Entra ID och ger den åtkomst till både Data Lake Analytics och Data Lake Store som används. Detaljerade steg finns i Tjänst-till-tjänst-autentisering. Anteckna följande värden som du använder för att definiera den länkade tjänsten:
- Applikations-ID
- Programnyckel
- Kund-ID
Ge huvudprincipen för tjänsten behörighet till Azure Data Lake Analytics med användning av guiden Lägg till användare.
Använd autentisering med tjänstens huvudkonto genom att ange dessa egenskaper.
| Egenskap | Beskrivning | Obligatoriskt |
|---|---|---|
| servicePrincipalId | Ange programmets klient-ID. | Ja |
| servicePrincipalKey | Ange programmets nyckel. | Ja |
| hyresgäst | Ange klientinformationen (domännamn eller klient-ID) som programmet finns under. Du kan hämta den genom att hovra musen i det övre högra hörnet i Azure portalen. | Ja |
Exempel: Autentisering med tjänstehuvudkonto
{
"name": "AzureDataLakeAnalyticsLinkedService",
"properties": {
"type": "AzureDataLakeAnalytics",
"typeProperties": {
"accountName": "<account name>",
"dataLakeAnalyticsUri": "<azure data lake analytics URI>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<optional, subscription id of ADLA>",
"resourceGroupName": "<optional, resource group name of ADLA>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Mer information om den länkade tjänsten finns i Beräkna länkade tjänster.
Data Lake Analytics U-SQL-aktivitet
Följande JSON-kodfragment definierar en pipeline med en Data Lake Analytics U-SQL-aktivitet. Aktivitetsdefinitionen har en referens till den Azure Data Lake Analytics länkade tjänst som du skapade tidigare. För att köra ett Data Lake Analytics U-SQL-skript skickar tjänsten det skript som du angav till Data Lake Analytics, och nödvändiga indata och utdata definieras i skriptet för Data Lake Analytics för att hämta och mata ut.
{
"name": "ADLA U-SQL Activity",
"description": "description",
"type": "DataLakeAnalyticsU-SQL",
"linkedServiceName": {
"referenceName": "<linked service name of Azure Data Lake Analytics>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptLinkedService": {
"referenceName": "<linked service name of Azure Data Lake Store or Azure Storage which contains the U-SQL script>",
"type": "LinkedServiceReference"
},
"scriptPath": "scripts\\kona\\SearchLogProcessing.txt",
"degreeOfParallelism": 3,
"priority": 100,
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
}
}
I följande tabell beskrivs namn och beskrivningar av egenskaper som är specifika för den här aktiviteten.
| Egenskap | Beskrivning | Obligatoriskt |
|---|---|---|
| namn | Namnet på aktiviteten i pipelinen | Ja |
| beskrivning | Text som beskriver vad aktiviteten gör. | Nej |
| typ | För Data Lake Analytics U-SQL-aktivitet är aktivitetstypen DataLakeAnalyticsU-SQL. | Ja |
| länkadTjänstNamn | Länkad tjänst till Azure Data Lake Analytics. Mer information om den här länkade tjänsten finns i artikeln Compute linked services (Beräkningslänkade tjänster ). | Ja |
| scriptPath | Sökväg till mappen som innehåller U-SQL-skriptet. Namnet på filen är skiftlägeskänsligt. | Ja |
| scriptLinkedService | Länkad tjänst som länkar Azure Data Lake Store eller Azure Storage som innehåller skriptet | Ja |
| parallellismnivå | Det maximala antalet noder som används samtidigt för att köra jobbet. | Nej |
| prioritet | Avgör vilka jobb av alla de som är i kö ska väljas för att köras först. Desto lägre tal, desto högre prioritet. | Nej |
| parametrar | Parametrar som ska skickas till U-SQL-skriptet. | Nej |
| runtimeVersion | Körningsversion av U-SQL-motorn som ska användas. | Nej |
| compilationMode | Kompileringsläge för U-SQL. Måste vara ett av följande värden: Semantisk: Utför endast semantiska kontroller och nödvändiga sanitetskontroller, Fullständig: Utför den fullständiga kompilering, inklusive syntaxkontroll, optimering, kodgenerering osv., SingleBox: Utför den fullständiga kompilering, med TargetType-inställningen till SingleBox. Om du inte anger något värde för den här egenskapen avgör servern det optimala kompileringsläget. |
Nej |
Se SearchLogProcessing.txt för skriptdefinitionen.
Exempel på U-SQL-skript
@searchlog =
EXTRACT UserId int,
Start DateTime,
Region string,
Query string,
Duration int,
Urls string,
ClickedUrls string
FROM @in
USING Extractors.Tsv(nullEscape:"#NULL#");
@rs1 =
SELECT Start, Region, Duration
FROM @searchlog
WHERE Region == "en-gb";
@rs1 =
SELECT Start, Region, Duration
FROM @rs1
WHERE Start <= DateTime.Parse("2012/02/19");
OUTPUT @rs1
TO @out
USING Outputters.Tsv(quoting:false, dateTimeFormat:null);
I skriptexemplet ovan definieras indata och utdata till skriptet i parametrarna @in och @out . Värdena för parametrarna @in och @out i U-SQL-skriptet skickas dynamiskt av tjänsten med hjälp av avsnittet parametrar.
Du kan ange andra egenskaper som degreeOfParallelism och prioritet samt i pipelinedefinitionen för jobben som körs på Azure Data Lake Analytics-tjänsten.
Dynamiska parametrar
I exempelpipelinedefinitionen tilldelas in- och utparametrar med hårdkodade värden.
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
Det går att använda dynamiska parametrar i stället. Till exempel:
"parameters": {
"in": "/datalake/input/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/data.tsv",
"out": "/datalake/output/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/result.tsv"
}
I det här fallet hämtas fortfarande indatafiler från mappen /datalake/input och utdatafiler genereras i mappen /datalake/output. Filnamnen är dynamiska beroende på starttiden för tidsfönstret som anges när pipelinen utlöses.
Relaterat innehåll
Se följande artiklar som förklarar hur du transformerar data på andra sätt: