Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
I den här artikeln får du lära dig vilka alternativ som är tillgängliga för att skriva frågeförfrågningar för grundmodeller och hur du skickar dem till din modell som betjänar slutpunkten. Du kan köra frågor mot grundmodeller som hanteras av Databricks och grundmodeller som finns utanför Databricks.
För traditionella ML- eller Python-modellers frågebegäranden, se Frågeserverslutpunkter för anpassade modeller.
Mosaic AI Model Serving stöder API:er för Foundation-modeller och externa modeller för åtkomst till grundmodeller. Modellservern använder ett enhetligt OpenAI-kompatibelt API och SDK för att köra frågor mot dem. Detta gör det möjligt att experimentera med och anpassa grundmodeller för produktion i moln och leverantörer som stöds.
Frågealternativ
Mosaic AI Model Serving innehåller följande alternativ för att skicka frågebegäranden till slutpunkter som hanterar grundmodeller:
| Metod | Detaljer |
|---|---|
| OpenAI-klient | Fråga en modell som hanteras av en Mosaic AI Model Serving-slutpunkt med hjälp av OpenAI-klienten. Ange modellens betjäningsslutpunktsnamn som model input. Stöds för chatt-, inbäddnings- och slutförandemodeller som görs tillgängliga av Foundation Model-API:er eller externa modeller. |
| AI-funktioner | Anropa modellinferens direkt från SQL med hjälp av ai_query SQL-funktionen. Se Exempel: Hämta data från en grundmodell. |
| Serveringsgränssnitt | Välj Frågeändpunkt på sidan Serverändpunkt. Infoga indata för JSON-formatmodellen och klicka på Skicka begäran. Om modellen har ett indataexempel loggat använder du Visa exempel för att läsa in det. |
| REST-API | Anropa och fråga modellen med hjälp av REST-API:et. Mer information finns i POST /serving-endpoints/{name}/invocations . Information om bedömning av begäranden till slutpunkter som betjänar flera modeller finns i Fråga efter enskilda modeller bakom en slutpunkt. |
| SDK för MLflow-distributioner | Använd SDK:s predict () -funktion för MLflow Deployments för att fråga modellen. |
| Databricks Python SDK | Databricks Python SDK är ett lager ovanpå REST-API:et. Den hanterar information på låg nivå, till exempel autentisering, vilket gör det enklare att interagera med modellerna. |
Krav
- En modell som betjänar slutpunkten.
- En Databricks-arbetsyta i en region som stöds.
- Om du vill skicka en bedömningsbegäran via OpenAI-klienten, REST API eller MLflow Deployment SDK måste du ha en Databricks API-token.
Viktigt!
Som bästa säkerhet för produktionsscenarier rekommenderar Databricks att du använder OAuth-token från dator till dator för autentisering under produktion.
För testning och utveckling rekommenderar Databricks att du använder en personlig åtkomsttoken som tillhör tjänstens huvudnamn i stället för arbetsyteanvändare. Information om hur du skapar token för tjänstens huvudnamn finns i Hantera token för tjänstens huvudnamn.
Installera paket
När du har valt en frågemetod måste du först installera rätt paket i klustret.
OpenAI-klient
Om du vill använda OpenAI-klienten databricks-openai måste paketet installeras i klustret. Det här paketet tillhandahåller en OpenAI-klient med auktorisering automatiskt konfigurerad för att fråga generativa AI-modeller. Kör följande i anteckningsboken eller den lokala terminalen:
pip install -U databricks-openai
Följande krävs endast när du installerar paketet på en Databricks Notebook
dbutils.library.restartPython()
REST-API
Åtkomst till SERVERINGs-REST-API:et finns i Databricks Runtime for strojové učenie.
SDK för MLflow-distributioner
!pip install mlflow
Följande krävs endast när du installerar paketet på en Databricks Notebook
dbutils.library.restartPython()
Databricks Python SDK
Databricks SDK för Python är redan installerat på alla Azure Databricks-kluster som använder Databricks Runtime 13.3 LTS eller senare. För Azure Databricks-kluster som använder Databricks Runtime 12.2 LTS och nedan måste du först installera Databricks SDK för Python. Se Databricks SDK för Python.
Grundmodelltyper
I följande tabell sammanfattas de grundmodeller som stöds baserat på aktivitetstyp.
Viktigt!
Meta-Llama-3.1-405B-Instruct kommer att dras tillbaka,
- Från och med den 15 februari 2026 för belastningar med betalning per token.
- Från och med den 15 maj 2026 för tilldelade genomströmningsarbetsbelastningar.
Se Tillbakadragna modeller för den rekommenderade ersättningsmodellen och vägledning om hur du migrerar under utfasningsperioden.
| Aktivitetstyp | Beskrivning | Modeller som stöds | När ska jag använda? Rekommenderade användningsfall |
|---|---|---|---|
| Generell användning | Modeller som är utformade för att förstå och delta i naturliga konversationer i flera omgångar. De är finjusterade på stora datamängder av mänsklig dialog, vilket gör det möjligt för dem att generera kontextuellt relevanta svar, spåra konversationshistorik och tillhandahålla sammanhängande, människoliknande interaktioner i olika ämnen. | Följande är Databricks-värdbaserade grundmodeller som stöds:
Följande är externa modeller som stöds:
|
Rekommenderas för scenarier där naturlig dialog med flera vändningar och sammanhangsberoende förståelse behövs.
|
| Inbäddningar | Inbäddningsmodeller är maskininlärningssystem som omvandlar komplexa data, till exempel text, bilder eller ljud, till kompakta numeriska vektorer som kallas inbäddningar. Dessa vektorer samlar in viktiga funktioner och relationer i data, vilket möjliggör effektiv jämförelse, klustring och semantisk sökning. | En Databricks-hostad grundmodell stöds: Följande är externa modeller som stöds:
|
Rekommenderas för program där semantisk förståelse, likhetsjämförelse och effektiv hämtning eller klustring av komplexa data är viktiga:
|
| Vision | Modeller som är utformade för att bearbeta, tolka och analysera visuella data, till exempel bilder och videor så att datorer kan "se" och förstå den visuella världen. | Följande är Databricks-värdbaserade grundmodeller som stöds:
Följande är externa modeller som stöds:
|
Rekommenderas oavsett var automatiserad, korrekt och skalbar analys av visuell information behövs:
|
| Resonemang | Avancerade AI-system som är utformade för att simulera mänskligt logiskt tänkande. Resonemangsmodeller integrerar tekniker som symbolisk logik, probabilistiska resonemang och neurala nätverk för att analysera kontext, dela upp uppgifter och förklara deras beslutsfattande. | En Databricks-hostad grundmodell stöds:
Följande är externa modeller som stöds:
|
Rekommenderas oavsett var automatiserad, korrekt och skalbar analys av visuell information behövs:
|
Funktionsanrop
Databricks-funktionsanrop är OpenAI-kompatibelt och är endast tillgängligt under modeller som fungerar som en del av Foundation Model-API:er och serverslutpunkter som betjänar externa modeller. Mer information finns i Funktionsanrop i Azure Databricks.
Strukturerade utdata
Strukturerade utdata är OpenAI-kompatibla och är endast tillgängliga under modeller som fungerar som en del av Foundation Model-API:er. Mer information finns i Strukturerade utdata på Azure Databricks.
Promptcachelagring
Snabbcachelagring stöds för Databricks-värdbaserade Claude-modeller som en del av Foundation Model-API:er.
Du kan ange parametern cache_control i dina frågebegäranden för att cachelagera följande:
- Textinnehållsmeddelanden i matrisen
messages.content. - Med tanke på meddelandeinnehållet i matrisen
messages.content. - Avbildningar av innehållsblock i matrisen
messages.content. - Verktygsanvändning, resultat och definitioner i matrisen
tools.
Se referens för Foundation-modellens REST API.
Textinnehåll
{
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What's the date today?",
"cache_control": { "type": "ephemeral" }
}
]
}
]
}
Orsaksinnehåll
{
"messages": [
{
"role": "assistant",
"content": [
{
"type": "reasoning",
"summary": [
{
"type": "summary_text",
"text": "Thinking...",
"signature": "[optional]"
},
{
"type": "summary_encrypted_text",
"data": "[encrypted text]"
}
]
}
]
}
]
}
ImageContent
Innehållet i bildmeddelandet måste använda kodade data som källa. URL:er stöds inte.
{
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What’s in this image?"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpeg;base64,[content]"
},
"cache_control": { "type": "ephemeral" }
}
]
}
]
}
Verktygsanropinnehåll
{
"messages": [
{
"role": "assistant",
"content": "Ok, let’s get the weather in New York.",
"tool_calls": [
{
"type": "function",
"id": "123",
"function": {
"name": "get_weather",
"arguments": "{\"location\":\"New York, NY\"}"
},
"cache_control": { "type": "ephemeral" }
}
]
}
]
}
Anmärkning
Databricks REST API är OpenAI-kompatibelt och skiljer sig från det antropiska API:et. Dessa skillnader påverkar även svarsobjekt som följande:
- Utdata returneras i fältet
choices. - Segmentformat för direktuppspelning. Alla segment följer samma format där
choicesinnehåller svaretdeltaoch användningen returneras i varje segment. - Stopporsaken returneras i fältet
finish_reason.- Antropiska användningsområden:
end_turn,stop_sequence,max_tokensochtool_use - Databricks använder:
stop,stop,lengthochtool_calls
- Antropiska användningsområden:
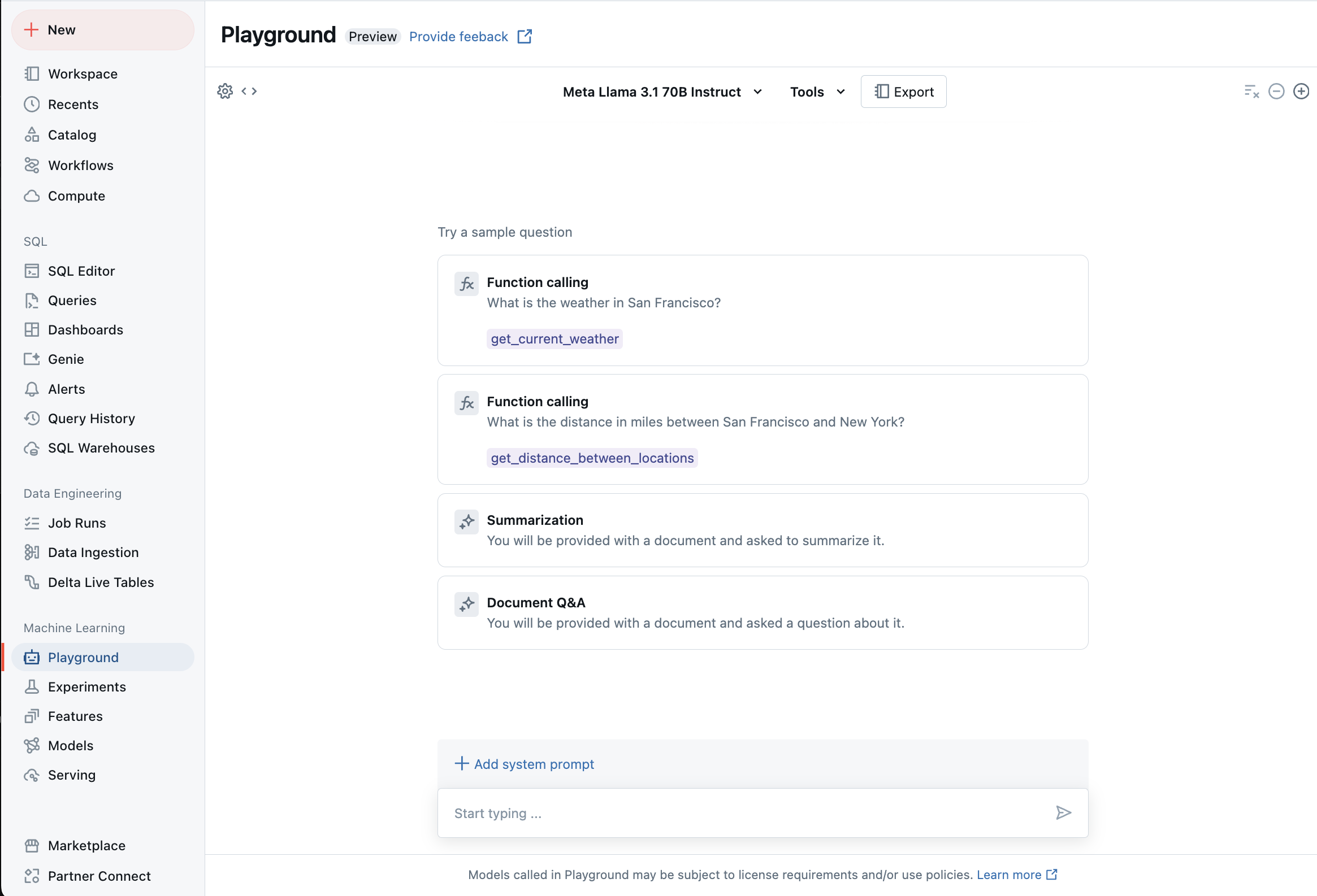
Chatta med LLM:er som stöds med AI Playground
Du kan interagera med stora språkmodeller som stöds med hjälp av AI Playground. AI Playground är en chattliknande miljö där du kan testa, fråga och jämföra LLM:er från din Azure Databricks-arbetsyta.
Ytterligare resurser
- Övervaka hanterade modeller med hjälp av Unity AI Gateway-aktiverade slutsatsdragningstabeller
- Distribuera batchinferenspipelines
- Grundmodell-API:er för Databricks
- Externa modeller i Mosaic AI Model Serving
- Självstudie: Skapa externa modellslutpunkter för att fråga OpenAI-modeller
- Databricks-värdbaserade grundmodeller som är tillgängliga i Foundation Model-API:er
- API-referens för foundationmodell