Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här sidan beskriver alternativen för beräkningsresurser för notebook-datorer. Du kan köra en notebook på en beräkningsresurs för allmän användning, serverlös beräkning, eller, för SQL-kommandon, använda ett SQL-lager, en beräkningsresurs optimerad för SQL-analys. Mer information om beräkningstyper finns i Beräkning.
Standardberäkning
I arbetsytor som är aktiverade för Unity Catalog är nya notebook-filer standard för serverlös beräkning. Om du inte manuellt väljer en beräkningsresurs och kör en cell, ansluter notebook automatiskt till serverlös beräkning.
Bifoga beräkning automatiskt
I utvecklarinställningarna kan du konfigurera notebook-filer så att de automatiskt kopplas till en beräkningsresurs och starta en session när du interagerar med redigeraren:
Klicka på användarikonen längst upp till vänster.
Klicka på Inställningar.
Klicka på Utvecklare för att gå till utvecklarinställningarna.
Växla på Skapa session automatiskt i redigeringsprograminteraktion för att automatiskt starta en beräkningssession för redigeringsinteraktion. Databricks är som standard en beräkningsresurs baserat på dina inställningar (serverlöst eller SQL-lager) och den senaste beräkningsresursen som användes.
OR
Inaktivera den här inställningen om du inte vill att notebook automatiskt ska ansluta till och starta en beräkningsresurs.
Kodhjälpsfunktioner, inklusive automatisk komplettering, kodformatering och felsökningsprogrammet, kräver att notebook-filen kopplas till en aktiv beräkningssession. Om notebook-filen inte har startat en beräkningssession är funktionerna för kodhjälp inaktiva.
Serverlös beräkning för notebook-filer
Med serverfri beräkning kan du snabbt ansluta din notebook till beräkningsresurser på begäran.
Om du vill ansluta till den serverlösa beräkningen klickar du på den nedrullningsbara menyn för beräkning i anteckningsboken och väljer Serverlös.
Se Serverlös beräkning för notebooks för mer information.
Automatisk återställning av sessioner för serverlösa anteckningsböcker
Inaktiv avstängning av serverlös beräkning kan leda till att du förlorar pågående arbete, till exempel värden på Python-variabler, i dina notebooks. Undvik detta genom att aktivera automatisk sessionsåterställning för serverlösa notebook-filer.
- Klicka på ditt användarnamn längst upp till höger på arbetsytan och klicka sedan på Inställningar i listrutan.
- I sidofältet Inställningar väljer du Utvecklare.
- Under Experimentella funktioner växlar du på inställningen Automatisk sessionsåterställning för serverlösa notebook-filer .
Om du aktiverar den här inställningen kan Databricks ta en ögonblicksbild av den serverlösa notebookens minnestillstånd innan den inaktiva avslutas. När du återgår till en anteckningsbok efter en avbruten inaktiv session visas ett meddelande överst på sidan. Klicka på Återanslut för att återställa arbetstillståndet.
När du återansluter återställer Databricks hela din arbetsmiljö, inklusive:
- Python variabler, funktioner och klassdefinitioner: Python-programmets tillstånd serialiseras internt med pickle/cloudpickle och återställs till en ny REPL-instans, så du behöver inte importera om eller återdeklarera.
- Spark DataFrames, cachelagrade och temporära vyer: Data som du har läst in, transformerat eller cachelagrat (inklusive tillfälliga vyer) bevaras, så du undviker kostsam inläsning eller omberäkning.
- Spark-sessionstillstånd: Konfigurationsinställningar på Spark-nivå, tillfälliga vyer, katalogändringar och användardefinierade funktioner (UDF: er) återställs via Spark Connect-sessionsmigrering, så du behöver inte återställa dem.
Om miljön har ändrats på ett sätt som skulle göra deserialiseringen osäker, till exempel inkompatibel Python eller paketversioner, ogiltigförklaras ögonblicksbilden och notebook-filen återgår till en ny session.
Lagring av ögonblicksbilddata
Ögonblicksbilddata lagras i din arbetsytas standardlagring. Själva anteckningsboken lagrar endast metadata, inklusive en pekare med notebook-ID, en tidsstämpel och sessionsinformation. Datanyttolasten lagras inte i anteckningsboken. Blobsökvägar krypteras innan de lagras i attributen för anteckningsböcker, och ögonblicksbildssökvägar undantas från export och import av anteckningsböcker för att förhindra återställning av tillstånd i en annan arbetsyta.
Ögonblicksbilder följer dina TTL-standardvärden för molnlagring (ungefär en månad) och upphör att gälla automatiskt. Om du tar bort en notebook-fil tas även dess ögonblicksbilder bort. Ditt molnkonto medför lagringskostnader som en del av standardanvändningen för lagring av arbetsytor. Funktionen använder serialisering av Python-processer i stället för kontrollpunkter på containernivå, vilket gör ögonblicksbilderna mindre och snabbare att skapa.
Säkerhet och åtkomstkontroll
Återställning av ögonblicksbilder respekterar notebook-behörigheter. För att återställa tillstånd krävs kör-behörighet på notebooken. Krypterade metadata hindrar användare från att hämta ögonblicksbildblobar direkt och behörighetskontroller tillämpas vid återställning.
Begränsningar
Den här funktionen har begränsningar och stöder inte återställning av följande:
- Spark-tillstånd som är äldre än 4 dagar
- Spark-tillstånd större än 50 MB
- Data som rör SQL-skript
- Filhandtag
- Lås och andra samtidighetsprimiter
- Nätverksanslutningar
Koppla en notebook till en universal beräkningsresurs
Om du vill koppla en anteckningsbok till en allmän beräkningsresurs behöver du behörighet att koppla till på beräkningsresursen.
Viktigt!
Så länge en notebook-fil är kopplad till en beräkningsresurs har alla användare med behörigheten CAN RUN i notebook-filen implicit behörighet att komma åt beräkningsresursen.
Om du vill koppla en notebook-fil till en beräkningsresurs klickar du på beräkningsväljaren i notebook-verktygsfältet och väljer resursen på den nedrullningsbara menyn.
Menyn visar ett urval av beräknings- och SQL-lager för alla ändamål som du har använt nyligen eller som körs för närvarande.

Om du vill välja från alla tillgängliga beräkningar klickar du på Mer.... Välj från tillgängliga allmänna beräknings- eller SQL-lager.
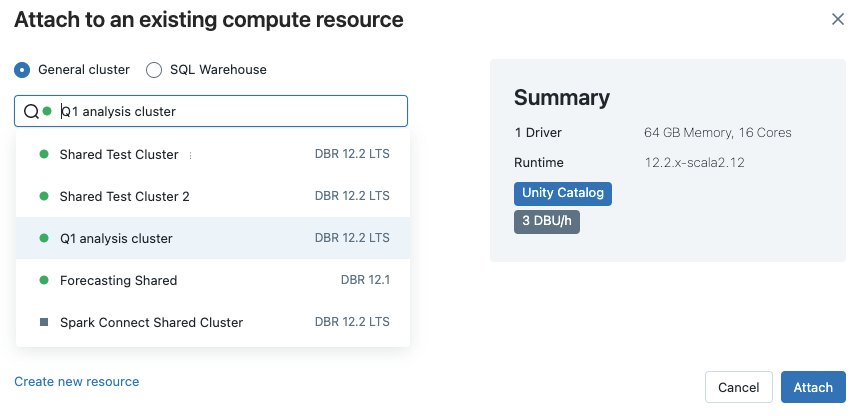
Du kan också skapa en ny beräkningsresurs för alla ändamål genom att välja Skapa ny resurs... i den nedrullningsbara menyn.
Viktigt!
En bifogad notebook-fil har följande Apache Spark-variabler definierade.
| Klass | Variabelnamn |
|---|---|
SparkContext |
sc |
SQLContext/HiveContext |
sqlContext |
SparkSession (Spark 2.x) |
spark |
Skapa inte en SparkSession, SparkContexteller SQLContext. Detta leder till inkonsekvent beteende.
Använd en notebook med ett SQL warehouse
När en notebook-fil är ansluten till ett SQL-lager kan du köra SQL- och Markdown-celler. Om du kör en cell på något annat språk (till exempel Python eller R) genereras ett fel. SQL-celler som körs på ett SQL-lager visas i SQL-lagrets frågehistorik. Användaren som körde en fråga kan visa frågeprofilen från notebook genom att klicka på den förflutna tiden längst ned i output.
Notebook-filer som är kopplade till SQL-lager stöder SQL-lagersessioner, där du kan definiera variabler, skapa tillfälliga vyer och bevara tillstånd för flera frågekörningar. Du kan skapa SQL-logik iterativt utan att behöva köra alla instruktioner samtidigt. Se Vad är SQL-lagersessioner?.
För att köra en notebook krävs ett pro eller serverlös SQL-datalager. Du måste ha åtkomst till arbetsytan och SQL-lagret.
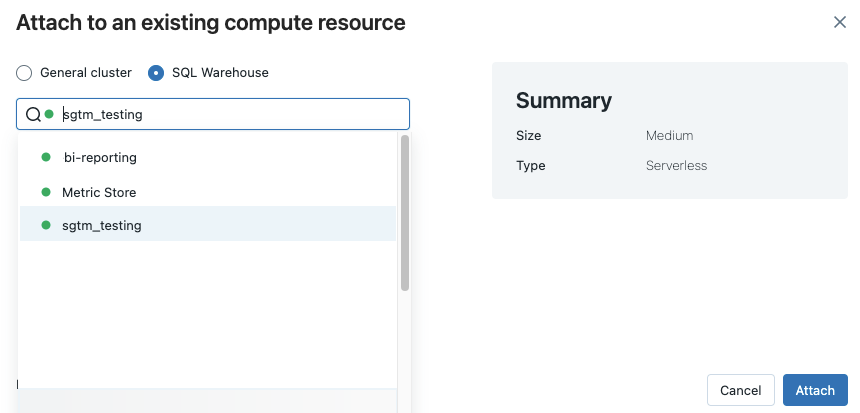
Så här kopplar du en notebook-fil till ett SQL-lager :
Klicka på beräkningsväljaren i notebook-verktygsfältet. Den nedrullningsbara menyn visar beräkningsresurser som för närvarande körs eller som du har använt nyligen. SQL-lager markeras med
 .
.Välj ett SQL-lager på menyn.
Om du vill se alla tillgängliga SQL-lager väljer du Mer... i den nedrullningsbara menyn. En dialogruta öppnas som visar de beräkningsresurser som är tillgängliga för anteckningsboken. Välj SQL Warehouse, välj det lager som du vill använda och klicka på Bifoga.
Du kan också välja ett SQL-lager som beräkningsresurs för en SQL-notebook-fil när du skapar ett arbetsflöde eller ett schemalagt jobb.
Begränsningar för SQL-lager
Mer information finns i Kända begränsningar av Databricks-notebooks .