Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här artikeln visar hur du utvärderar en chattapps svar mot en uppsättning korrekta eller idealiska svar (kallas grundsanning). När du ändrar chattprogrammet på ett sätt som påverkar svaren kör du en utvärdering för att jämföra ändringarna. Det här demoprogrammet erbjuder verktyg som du kan använda idag för att göra det enklare att köra utvärderingar.
Genom att följa anvisningarna i den här artikeln:
- Använd tillhandahållna exempelmeddelanden som är skräddarsydda för ämnesdomänen. De här anvisningarna finns redan på lagringsplatsen.
- Generera exempel på användarfrågor och grunda sanningssvar från dina egna dokument.
- Kör utvärderingar med hjälp av en exempelprompt med de genererade användarfrågorna.
- Granska analys av svar.
Kommentar
Den här artikeln använder en eller flera AI-appmallar som grund för exemplen och vägledningen i artikeln. MED AI-appmallar får du väl underhållna referensimplementeringar som är enkla att distribuera. De bidrar till att säkerställa en högkvalitativ startpunkt för dina AI-appar.
Arkitekturöversikt
Viktiga komponenter i arkitekturen är:
- Azure-värdbaserad chattapp: Chattappen körs i Azure App Service.
- Microsoft AI Chat Protocol: Protokollet tillhandahåller standardiserade API-kontrakt för AI-lösningar och -språk. Chattappen överensstämmer med Microsoft AI Chat Protocol, som gör att utvärderingsappen kan köras mot alla chattappar som överensstämmer med protokollet.
- Azure AI-sökning: Chattappen använder Azure AI-sökning för att lagra data från dina egna dokument.
- Exempel på frågegenerator: Verktyget kan generera många frågor för varje dokument tillsammans med det grundläggande sanningssvaret. Ju fler frågor det finns, desto längre utvärderingar.
- Utvärderare: Verktyget kör exempelfrågor och frågar mot chattappen och returnerar resultatet.
- Granskningsverktyg: Verktyget granskar resultaten av utvärderingarna.
- Diff-verktyget: Verktyget jämför svaren mellan utvärderingarna.
När du distribuerar den här utvärderingen till Azure skapas Azure OpenAI-tjänstslutpunkten för GPT-4 modellen med egen kapacitet. När du utvärderar chattprogram är det viktigt att utvärderaren har en egen Azure OpenAI-resurs med hjälp GPT-4 av sin egen kapacitet.
Förutsättningar
Azure-prenumeration. Skapa en kostnadsfritt
Distribuera en chattapp.
Dessa chattappar läser in data i Azure AI-sökning-resursen. Den här resursen krävs för att utvärderingsappen ska fungera. Slutför inte avsnittet Rensa resurser i föregående procedur.
Du behöver följande Azure-resursinformation från distributionen, som kallas chattappen i den här artikeln:
- URI för chatt-API: Tjänstens serverdelsslutpunkt som visas i slutet av
azd upprocessen. - Azure AI-sökning. Följande värden krävs:
- Resursnamn: Namnet på resursnamnet för Azure AI-sökning, som rapporterats som
Search serviceunderazd upprocessen. - Indexnamn: Namnet på Azure AI-sökning-indexet där dina dokument lagras. Du hittar indexnamnet i Azure-portalen för söktjänsten.
- Resursnamn: Namnet på resursnamnet för Azure AI-sökning, som rapporterats som
URL:en till chatt-API:et gör det möjligt för utvärderingar att skicka begäranden via din backend-applikation. Informationen om Azure AI-sökning gör att utvärderingsskripten kan använda samma installation som din backend, där dokumenten har lästs in.
När du har samlat in den här informationen behöver du inte använda chattappens utvecklingsmiljö igen. Den här artikeln refererar till chattappen flera gånger för att visa hur appen Utvärderingar använder den. Ta inte bort chattappens resurser förrän du har slutfört alla steg i den här artikeln.
- URI för chatt-API: Tjänstens serverdelsslutpunkt som visas i slutet av
En utvecklingscontainermiljö är tillgänglig med alla beroenden som krävs för att slutföra den här artikeln. Du kan köra utvecklingscontainern i GitHub Codespaces (i en webbläsare) eller lokalt med hjälp av Visual Studio Code.
- GitHub-konto
Öppna en utvecklingsmiljö
Följ de här anvisningarna för att konfigurera en förkonfigurerad utvecklingsmiljö med alla nödvändiga beroenden för att slutföra den här artikeln. Ordna din bildskärmsarbetsyta så att du kan se den här dokumentationen och utvecklingsmiljön samtidigt.
Den här artikeln har testats med regionen switzerlandnorth för utvärderingsdistributionen.
GitHub Codespaces kör en utvecklingscontainer som hanteras av GitHub med Visual Studio Code för webben som användargränssnitt. Använd GitHub Codespaces för den enklaste utvecklingsmiljön. Den levereras med rätt utvecklarverktyg och beroenden förinstallerade för att färdigställa denna artikel.
Viktigt!
Alla GitHub-konton kan använda GitHub Codespaces i upp till 60 timmar kostnadsfritt varje månad med två kärninstanser. Mer information finns i GitHub Codespaces månadsvis inkluderade lagrings- och kärntimmar.
Starta processen för att skapa ett nytt GitHub-kodområde på grenen
mainav GitHub-lagringsplatsen Azure-Samples/ai-rag-chat-evaluator .Om du vill visa utvecklingsmiljön och dokumentationen som är tillgänglig samtidigt högerklickar du på följande knapp och väljer Öppna länk i nytt fönster.

På sidan Skapa kodområde granskar du konfigurationsinställningarna för kodområdet och väljer sedan Skapa nytt kodområde.
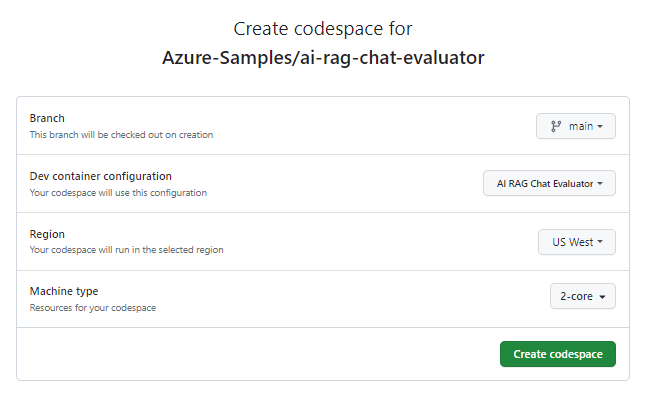
Vänta tills codespace har startat. Den här startprocessen kan ta några minuter.
Logga in på Azure med Azure Developer CLI i terminalen längst ned på skärmen:
azd auth login --use-device-codeKopiera koden från terminalen och klistra sedan in den i en webbläsare. Följ anvisningarna för att autentisera med ditt Azure-konto.
Etablera den Nödvändiga Azure-resursen, Azure OpenAI Service, för utvärderingsappen:
azd upDet här
AZDkommandot distribuerar inte utvärderingsappen, men den skapar Azure OpenAI-resursen med en nödvändigGPT-4distribution för att köra utvärderingarna i den lokala utvecklingsmiljön.
De återstående uppgifterna i den här artikeln sker i samband med den här utvecklingscontainern.
Namnet på GitHub-lagringsplatsen visas i sökfältet. Den här visuella indikatorn hjälper dig att skilja utvärderingsappen från chattappen. Den här ai-rag-chat-evaluator lagringsplatsen kallas utvärderingsappen i den här artikeln.

Förbereda miljövärden och konfigurationsinformation
Uppdatera miljövärdena och konfigurationsinformationen med den information du samlade in under Förhandskrav för utvärderingsappen.
Skapa en
.envfil baserat på.env.sample.cp .env.sample .envKör det här kommandot för att hämta nödvändiga värden för
AZURE_OPENAI_EVAL_DEPLOYMENTochAZURE_OPENAI_SERVICEfrån din distribuerade resursgrupp. Klistra in dessa värden i.envfilen.azd env get-value AZURE_OPENAI_EVAL_DEPLOYMENT azd env get-value AZURE_OPENAI_SERVICELägg till följande värden från chattappen för azure AI Search-instansen
.envi filen som du samlade in i avsnittet Förutsättningar .AZURE_SEARCH_SERVICE="<service-name>" AZURE_SEARCH_INDEX="<index-name>"
Använd Microsoft AI Chat Protocol för konfigurationsinformation
Chattappen och utvärderingsappen implementerar båda Microsoft AI Chat Protocol-specifikationen, ett API-kontrakt med öppen källkod, moln och språkagnostisk AI-slutpunkt som används för förbrukning och utvärdering. När klient- och mellannivåslutpunkterna följer den här API-specifikationen kan du konsekvent använda och köra utvärderingar på dina AI-serverdelar.
Skapa en ny fil med namnet
my_config.jsonoch kopiera följande innehåll till den:{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/experiment<TIMESTAMP>", "target_url": "http://localhost:50505/chat", "target_parameters": { "overrides": { "top": 3, "temperature": 0.3, "retrieval_mode": "hybrid", "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_refined.txt", "seed": 1 } } }Utvärderingsskriptet skapar
my_resultsmappen.Objektet
overridesinnehåller alla konfigurationsinställningar som behövs för programmet. Varje program definierar sin egen uppsättning inställningsegenskaper.Använd följande tabell för att förstå innebörden av de inställningsegenskaper som skickas till chattappen.
Inställningsegenskap beskrivning semantic_rankerOm du vill använda semantisk ranker, en modell som rangordnar sökresultaten på nytt baserat på semantisk likhet med användarens fråga. Vi stänger av det för den här handledningen för att minska kostnaderna. retrieval_modeDet hämtningsläge som ska användas. Standardvärdet är hybrid.temperatureTemperaturinställningen för modellen. Standardvärdet är 0.3.topAntalet sökresultat som ska returneras. Standardvärdet är 3.prompt_templateEn åsidosättning av uppmaningen som används för att generera svaret baserat på frågan och sökresultaten. seedStartvärdet för alla anrop till GPT-modeller. Om du ställer in ett frö resulterar det i mer konsekventa resultat i utvärderingar. Ändra värdet
target_urltill URI-värdet för chattappen, som du samlade in i avsnittet Förutsättningar . Chattappen måste följa chattprotokollet. URI:n har följande format:https://CHAT-APP-URL/chat. Kontrollera att protokollet ochchatvägen är en del av URI:n.
Generera exempeldata
För att utvärdera nya svar måste de jämföras med ett grundläggande sanningssvar , vilket är det idealiska svaret för en viss fråga. Generera frågor och svar från dokument som lagras i Azure AI-sökning för chattappen.
example_inputKopiera mappen till en ny mapp med namnetmy_input.I en terminal kör du följande kommando för att generera exempeldata:
python -m evaltools generate --output=my_input/qa.jsonl --persource=2 --numquestions=14
Fråge- och svarsparen genereras och lagras i my_input/qa.jsonl (i JSONL-format) som indata till utvärderaren som används i nästa steg. För en produktionsutvärdering genererar du fler par med frågor och svar. Mer än 200 genereras för den här datamängden.
Kommentar
Endast några få frågor och svar genereras per källa så att du snabbt kan slutföra den här proceduren. Det är inte tänkt att vara en produktionsutvärdering, som bör ha fler frågor och svar per källa.
Kör den första utvärderingen med en förfinad fråga
Redigera egenskaperna för konfigurationsfilen
my_config.json.Fastighet Nytt värde results_dirmy_results/experiment_refinedprompt_template<READFILE>my_input/prompt_refined.txtDen förfinade prompten är specifik om ämnesdomänen.
If there isn't enough information below, say you don't know. Do not generate answers that don't use the sources below. If asking a clarifying question to the user would help, ask the question. Use clear and concise language and write in a confident yet friendly tone. In your answers, ensure the employee understands how your response connects to the information in the sources and include all citations necessary to help the employee validate the answer provided. For tabular information, return it as an html table. Do not return markdown format. If the question is not in English, answer in the language used in the question. Each source has a name followed by a colon and the actual information. Always include the source name for each fact you use in the response. Use square brackets to reference the source, e.g. [info1.txt]. Don't combine sources, list each source separately, e.g. [info1.txt][info2.pdf].Kör utvärderingen genom att köra följande kommando i en terminal:
python -m evaltools evaluate --config=my_config.json --numquestions=14Det här skriptet skapade en ny experimentmapp i
my_results/med utvärderingen. Mappen innehåller resultatet av utvärderingen.Filnamn beskrivning config.jsonEn kopia av konfigurationsfilen som används för utvärderingen. evaluate_parameters.jsonParametrarna som används för utvärderingen. config.jsonLiknar men innehåller andra metadata som tidsstämpel.eval_results.jsonlVarje fråga och svar, tillsammans med GPT-måtten för varje par med frågor och svar. summary.jsonDe övergripande resultaten, till exempel de genomsnittliga GPT-måtten.
Kör den andra utvärderingen med en svag uppmaning
Redigera egenskaperna för konfigurationsfilen
my_config.json.Fastighet Nytt värde results_dirmy_results/experiment_weakprompt_template<READFILE>my_input/prompt_weak.txtDen svaga prompten har ingen kontext om ämnesdomänen.
You are a helpful assistant.Kör utvärderingen genom att köra följande kommando i en terminal:
python -m evaltools evaluate --config=my_config.json --numquestions=14
Kör den tredje utvärderingen med en specifik temperatur
Använd en uppmaning som ger mer kreativitet.
Redigera egenskaperna för konfigurationsfilen
my_config.json.Befintlig Fastighet Nytt värde Befintlig results_dirmy_results/experiment_ignoresources_temp09Befintlig prompt_template<READFILE>my_input/prompt_ignoresources.txtNytt temperature0.9Standardvärdet
temperatureär 0,7. Ju högre temperatur, desto mer kreativa svar.Uppmaningen
ignoreär kort.Your job is to answer questions to the best of your ability. You will be given sources but you should IGNORE them. Be creative!Konfigurationsobjektet bör se ut som i följande exempel, förutom att du ersatte
results_dirmed din sökväg:{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/prompt_ignoresources_temp09", "target_url": "https://YOUR-CHAT-APP/chat", "target_parameters": { "overrides": { "temperature": 0.9, "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_ignoresources.txt" } } }Kör utvärderingen genom att köra följande kommando i en terminal:
python -m evaltools evaluate --config=my_config.json --numquestions=14
Granska resultatet från utvärderingen
Du har utfört tre utvärderingar baserat på olika frågor och appinställningar. Resultaten lagras i my_results mappen. Granska hur resultaten skiljer sig åt baserat på inställningarna.
Använd granskningsverktyget för att se resultatet av utvärderingarna.
python -m evaltools summary my_resultsResultatet ser ut ungefär så här:

Varje värde returneras som ett tal och en procentandel.
Använd följande tabell för att förstå innebörden av värdena.
Värde beskrivning Förankring Kontrollerar hur väl modellens svar baseras på faktisk, verifierbar information. Ett svar anses grundat om det är faktamässigt korrekt och återspeglar verkligheten. Relevans Mäter hur nära modellens svar överensstämmer med kontexten eller prompten. Ett relevant svar adresserar direkt användarens fråga eller instruktion. Koherens Kontrollerar hur logiskt konsekventa modellens svar är. Ett sammanhängande svar upprätthåller ett logiskt flöde och motsäger inte sig självt. Hänvisning Anger om svaret returnerades i det format som begärdes i prompten. Längd Mäter svarets längd. Resultaten bör indikera att alla tre utvärderingarna hade hög relevans medan de
experiment_ignoresources_temp09hade den lägsta relevansen.Välj mappen för att se konfigurationen för utvärderingen.
Ange Ctrl + C för att avsluta appen och gå tillbaka till terminalen.
Jämför svaren
Jämför de returnerade svaren från utvärderingarna.
Välj två av utvärderingarna som ska jämföras och använd sedan samma granskningsverktyg för att jämföra svaren.
python -m evaltools diff my_results/experiment_refined my_results/experiment_ignoresources_temp09Granska resultaten. Dina resultat kan variera.

Ange Ctrl + C för att avsluta appen och gå tillbaka till terminalen.
Förslag på ytterligare utvärderingar
- Redigera anvisningarna i
my_inputför att skräddarsy svaren, till exempel ämnesdomän, längd och andra faktorer. -
my_config.jsonRedigera filen för att ändra parametrarna, till exempeltemperature, ochsemantic_rankeroch kör experimenten igen. - Jämför olika svar för att förstå hur prompten och frågan påverkar kvaliteten på svaren.
- Generera en separat uppsättning frågor och grundläggande sanningssvar för varje dokument i Azure AI-sökning-indexet. Kör sedan utvärderingarna igen för att se hur svaren skiljer sig åt.
- Ändra anvisningarna för att ange kortare eller längre svar genom att lägga till kravet i slutet av prompten. Ett exempel är
Please answer in about 3 sentences.
Rensa resurser och beroenden
Följande steg beskriver hur du rensar de resurser du använde.
Rensa Azure-resurser
De Azure-resurser som skapas i den här artikeln faktureras till din Azure-prenumeration. Om du inte förväntar dig att behöva dessa resurser i framtiden tar du bort dem för att undvika att debiteras mer.
Om du vill ta bort Azure-resurserna och ta bort källkoden kör du följande Azure Developer CLI-kommando:
azd down --purge
Rensa GitHub Codespaces och Visual Studio Code
Att ta bort GitHub Codespaces-miljön säkerställer att du kan maximera antalet kostnadsfria timmar per kärna som du får för ditt konto.
Viktigt!
Mer information om ditt GitHub-kontos rättigheter finns i GitHub Codespaces månadsvis inkluderade lagrings- och kärntimmar.
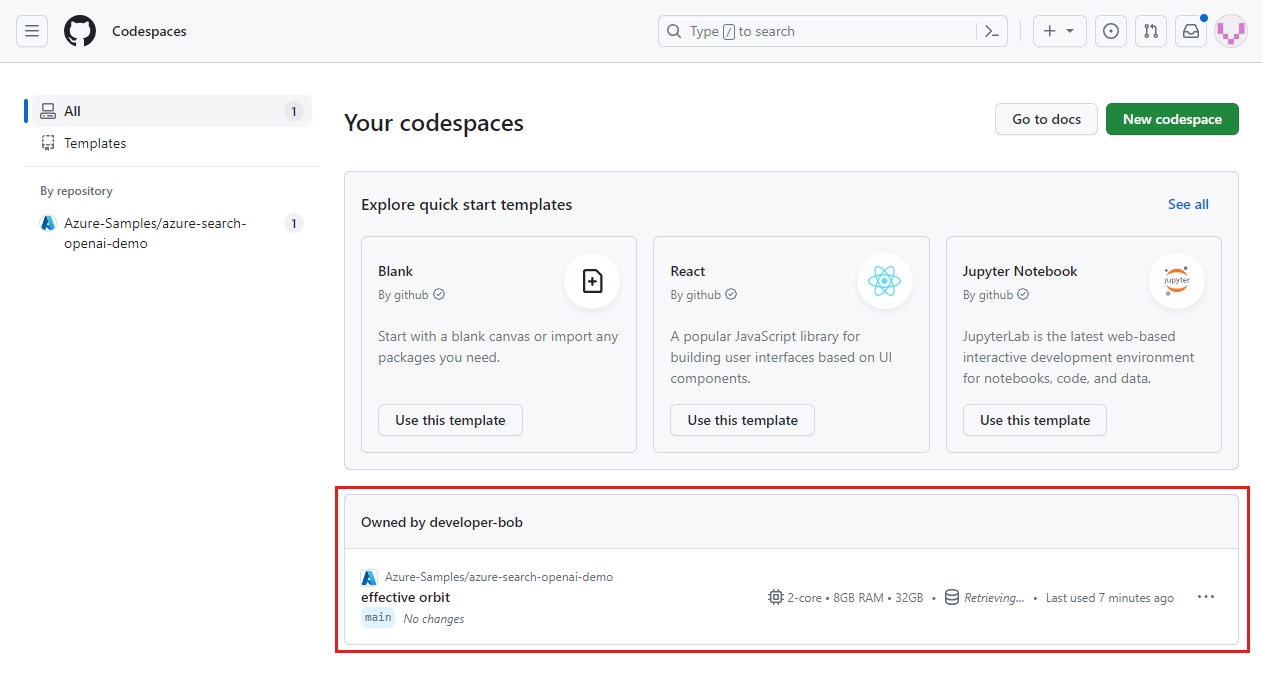
Leta upp dina kodområden som för närvarande körs och som är hämtade från GitHub-lagringsplatsen Azure-Samples/ai-rag-chat-evaluator.
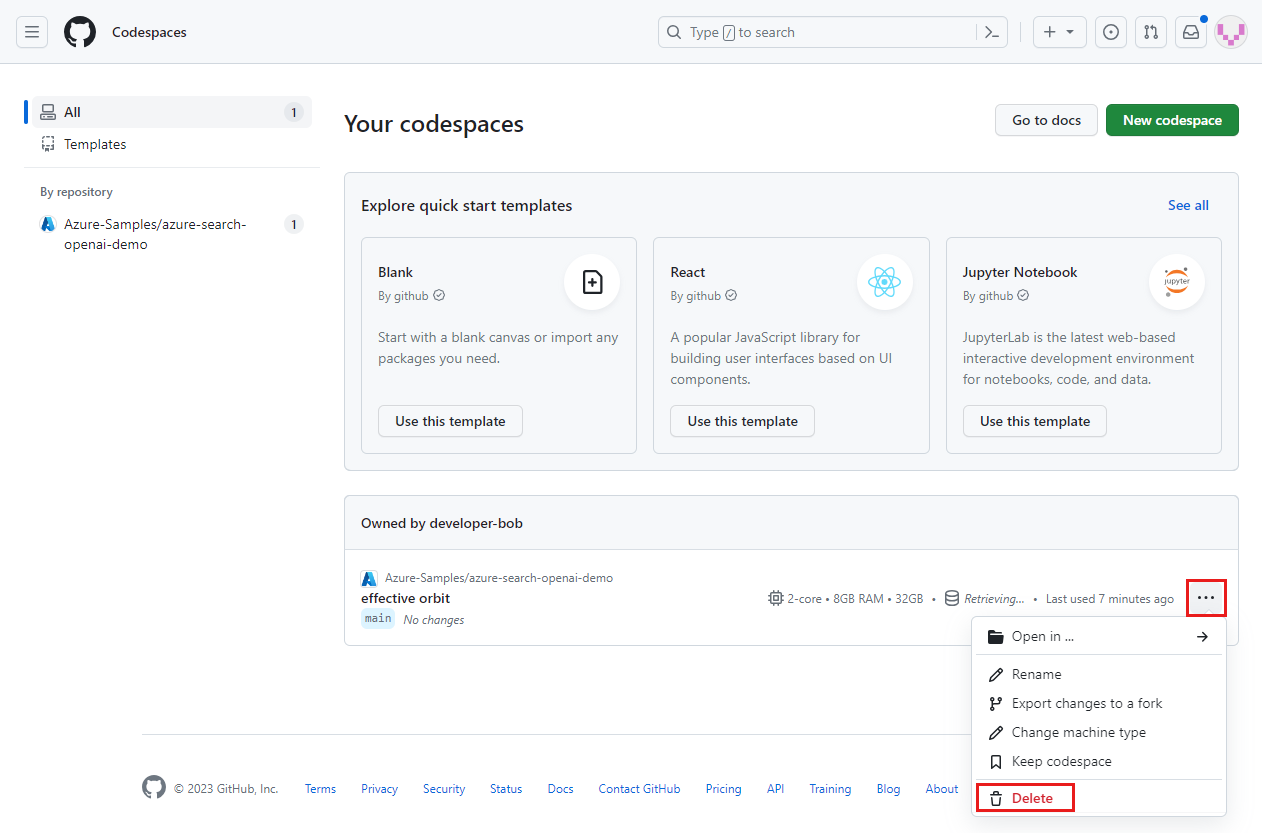
Öppna snabbmenyn för kodområdet och välj sedan Ta bort.
Gå tillbaka till chattappartikeln för att rensa resurserna.
Relaterat innehåll
- Se lagringsplatsen för utvärderingar.
- Se GitHub-arkivet för enterprise-chattappen.
- Skapa en chattapp med Azure OpenAI bästa praxis för lösningsarkitektur.
- Lär dig mer om åtkomstkontroll i generativa AI-appar med Azure AI-sökning.
- Skapa en företagsklar Azure OpenAI-lösning med Azure API Management.
- Se Azure AI-sökning: Överträffar vektorsökning med hybridåterhämtnings- och rankningsfunktioner.