Använd Apache Ambari Hive-vyn med Apache Hadoop i HDInsight
Lär dig hur du kör Hive-frågor med hjälp av Apache Ambari Hive View. Med Hive-vyn kan du skapa, optimera och köra Hive-frågor från webbläsaren.
Förutsättningar
Ett Hadoop-kluster i HDInsight. Se Komma igång med HDInsight i Linux.
Köra en Hive-fråga
Välj ditt kluster från Azure Portal. Anvisningar finns i Lista och visa kluster . Klustret öppnas i en ny portalvy.
Från Klusterinstrumentpaneler väljer du Ambari-vyer. När du uppmanas att autentisera använder du klusterinloggningen (standard
admin) kontonamn och lösenord som du angav när du skapade klustret. Du kan också navigera tillhttps://CLUSTERNAME.azurehdinsight.net/#/main/viewsi webbläsaren därCLUSTERNAMEär namnet på klustret.Välj Hive View i listan med vyer.
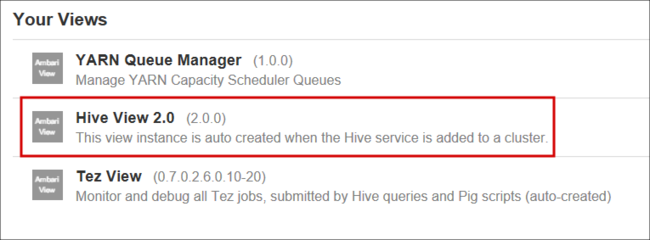
Hive-vysidan liknar följande bild:
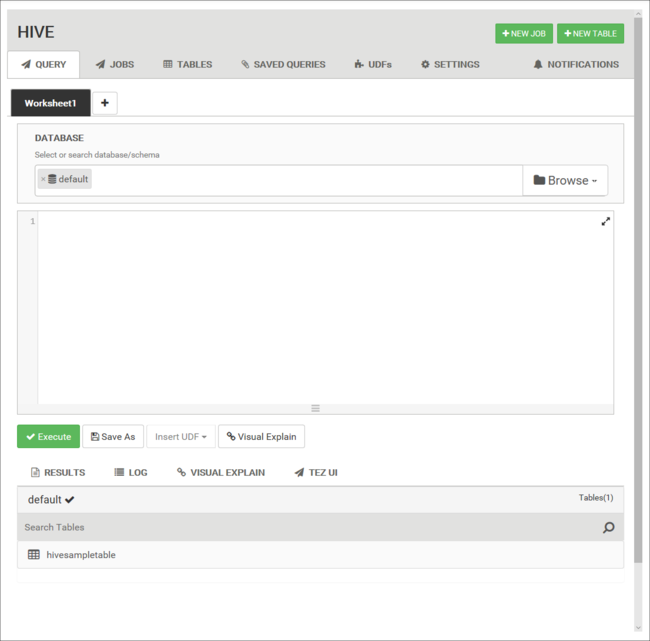
På fliken Fråga klistrar du in följande HiveQL-instruktioner i kalkylbladet:
DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS loglevel, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' GROUP BY t4;Dessa instruktioner utför följande åtgärder:
Utdrag beskrivning DROP TABLE Tar bort tabellen och datafilen, om tabellen redan finns. SKAPA EXTERN TABELL Skapar en ny "extern" tabell i Hive. Externa tabeller lagrar endast tabelldefinitionen i Hive. Data finns kvar på den ursprungliga platsen. RADFORMAT Visar hur data formateras. I det här fallet avgränsas fälten i varje logg med ett blanksteg. LAGRAD SOM TEXTFILPLATS Visar var data lagras och att de lagras som text. SELECT Väljer ett antal av alla rader där kolumn t4 innehåller värdet [ERROR]. Viktigt!
Låt databasvalet vara kvar som standard. I exemplen i det här dokumentet används standarddatabasen som ingår i HDInsight.
Starta frågan genom att välja Kör under kalkylbladet. Knappen blir orange och texten ändras till Stoppa.
När frågan är klar visar fliken Resultat resultatet av åtgärden. Följande text är resultatet av frågan:
loglevel count [ERROR] 3Du kan använda fliken LOGG för att visa loggningsinformationen som jobbet skapade.
Dricks
Ladda ned eller spara resultat från listrutan Åtgärder under fliken Resultat .
Visuell förklaring
Om du vill visa en visualisering av frågeplanen väljer du fliken Visuell förklaring under kalkylbladet.
Den visuella förklaringsvyn för frågan kan vara till hjälp när du ska förstå flödet av komplexa frågor.
Användargränssnitt för Tez
Om du vill visa Tez-användargränssnittet för frågan väljer du fliken Tez-användargränssnitt under kalkylbladet.
Viktigt!
Tez används inte för att lösa alla frågor. Du kan lösa många frågor utan att använda Tez.
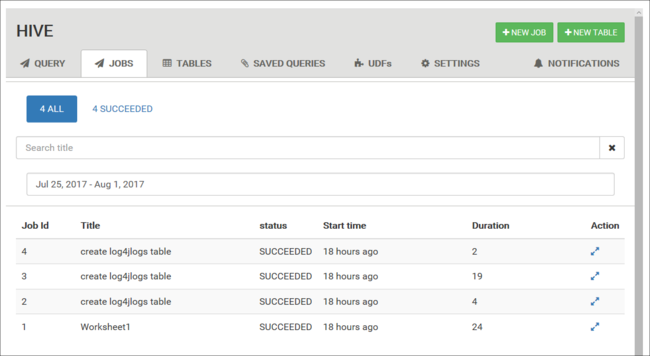
Visa jobbhistorik
Fliken Jobb visar en historik över Hive-frågor.
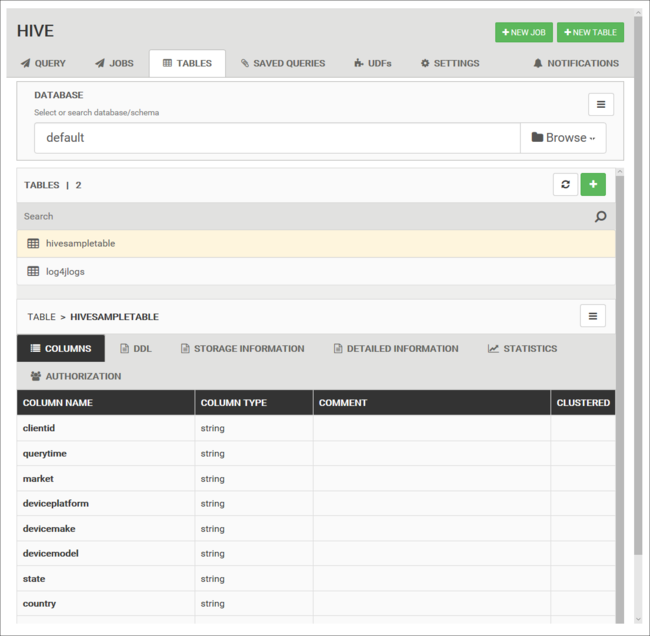
Databastabeller
Du kan använda fliken Tabeller för att arbeta med tabeller i en Hive-databas.
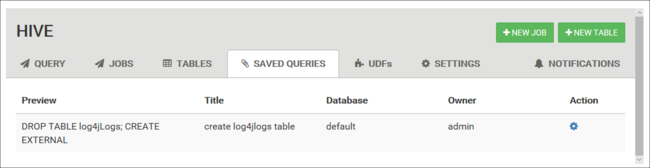
Sparade frågor
På fliken Fråga kan du också spara frågor. När du har sparat en fråga kan du återanvända den från fliken Sparade frågor .
Dricks
Sparade frågor lagras i standardklusterlagringen. Du hittar de sparade frågorna under sökvägen /user/<username>/hive/scripts. Dessa lagras som oformaterade filer .hql .
Om du tar bort klustret, men behåller lagringen, kan du använda ett verktyg som Azure Storage Explorer eller Data Lake Storage Explorer (från Azure-portalen) för att hämta frågorna.
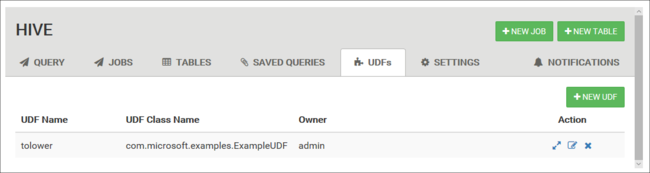
Användardefinierade funktioner
Du kan utöka Hive via användardefinierade funktioner (UDF). Använd en UDF för att implementera funktioner eller logik som inte är lätt att modellera i HiveQL.
Deklarera och spara en uppsättning UDF:er med hjälp av fliken UDF överst i Hive-vyn. Dessa UDF:er kan användas med Power Query-redigeraren.
Knappen Infoga udf visas längst ned i Power Query-redigeraren. Den här posten visar en listruta med UDF:er som definierats i Hive-vyn. Om du väljer en UDF läggs HiveQL-uttryck till i din fråga för att aktivera UDF.
Om du till exempel har definierat en UDF med följande egenskaper:
Resursnamn: myudfs
Resurssökväg: /myudfs.jar
UDF-namn: myawesomeudf
UDF-klassnamn: com.myudfs.Awesome
Med knappen Infoga udfs visas en post med namnet myudfs, med en annan listruta för varje UDF som definierats för den resursen. I det här fallet är det myawesomeudf. Om du väljer den här posten läggs följande till i början av frågan:
add jar /myudfs.jar;
create temporary function myawesomeudf as 'com.myudfs.Awesome';
Du kan sedan använda UDF i din fråga. Exempel: SELECT myawesomeudf(name) FROM people;
Mer information om hur du använder UDF:er med Hive i HDInsight finns i följande artiklar:
- Använda Python med Apache Hive och Apache Pig i HDInsight
- Använda en Java UDF med Apache Hive i HDInsight
Hive-inställningar
Du kan ändra olika Hive-inställningar, till exempel ändra körningsmotorn för Hive från Tez (standard) till MapReduce.
Nästa steg
Allmän information om Hive i HDInsight: