Använda Apache Hive-replikering i Azure HDInsight-kluster
När det gäller databaser och lager är replikering processen att duplicera entiteter från ett lager till ett annat. Duplicering kan gälla för en hel databas eller på en mindre nivå, till exempel en tabell eller partition. Målet är att ha en replik som ändras när basentiteten ändras. Replikering på Apache Hive fokuserar på haveriberedskap och erbjuder enkelriktad primär kopieringsreplikering. I HDInsight-kluster kan Hive Replication användas för att endirigering replikera Hive-metaarkivet och den associerade underliggande datasjön på Azure Data Lake Storage Gen2.
Hive Replication har utvecklats under åren med nyare versioner som ger bättre funktioner och är snabbare och mindre resursintensiva. I den här artikeln diskuterar vi Hive Replication (Replv2) som stöds i klustertyperna HDInsight 3.6 och HDInsight 4.0.
Fördelar med replv2
Hive ReplicationV2 (kallas även Replv2) har följande fördelar jämfört med den första versionen av Hive-replikering som använde Hive IMPORT-EXPORT:
- Händelsebaserad inkrementell replikering
- Replikering vid tidpunkt
- Krav på minskad bandbredd
- Minskning av antalet mellanliggande kopior
- Replikeringstillståndet bibehålls
- Begränsad replikering
- Stöd för en hubb- och ekermodell
- Stöd för ACID-tabeller (i HDInsight 4.0)
Replikeringsfaser
Hive-händelsebaserad replikering konfigureras mellan de primära och sekundära klustren. Den här replikeringen består av två distinkta faser: bootstrapping och inkrementella körningar.
Bootstrapping
Bootstrapping är avsett att köras en gång för att replikera databasernas bastillstånd från primär till sekundär. Du kan konfigurera bootstrapping om det behövs för att inkludera en delmängd av tabellerna i måldatabasen där replikeringen måste aktiveras.
Inkrementella körningar
Efter bootstrapping automatiseras inkrementella körningar i det primära klustret och händelser som genereras under dessa inkrementella körningar spelas upp på det sekundära klustret. När det sekundära klustret kommer ikapp det primära klustret blir sekundären konsekvent med den primäras händelser.
Replikeringskommandon
Hive erbjuder en uppsättning REPL-kommandon – DUMP, LOADoch STATUS – för att samordna händelseflödet. Kommandot DUMP genererar en lokal logg över alla DDL/DML-händelser i det primära klustret. Kommandot LOAD är en metod för att snabbt kopiera metadata och data som loggas till de extraherade replikeringsdumputdata och körs i målklustret. Kommandot STATUS körs från målklustret för att ange det senaste händelse-ID som den senaste replikeringsbelastningen replikerades.
Ange replikeringskälla
Innan du börjar med replikering ska du se till att databasen som ska replikeras anges som replikeringskälla. Du kan använda DESC DATABASE EXTENDED <db_name> kommandot för att avgöra om parametern repl.source.for har angetts med principnamnet.
Om principen är schemalagd och parametern repl.source.for inte har angetts måste du först ange den här parametern med hjälp av ALTER DATABASE <db_name> SET DBPROPERTIES ('repl.source.for'='<policy_name>').
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source.for'='replpolicy1')
Dumpa metadata till datasjön
Kommandot REPL DUMP [database name]. => location / event_id används i bootstrap-fasen för att dumpa relevanta metadata till Azure Data Lake Storage Gen2. event_id Anger den minsta händelse som relevanta metadata har placerats till i Azure Data Lake Storage Gen2.
repl dump tpcds_orc;
Exempel på utdata>
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0 | 2925 |
Läsa in data till målklustret
Kommandot REPL LOAD [database name] FROM [ location ] { WITH ( ‘key1’=‘value1’{, ‘key2’=‘value2’} ) } används för att läsa in data i målklustret för både bootstrap- och inkrementella faser av replikering. [database name] Kan vara samma som källan eller ett annat namn på målklustret. [location] Representerar platsen från utdata från tidigare REPL DUMP kommando. Det innebär att målklustret ska kunna kommunicera med källklustret. WITH Satsen lades främst till för att förhindra en omstart av målklustret, vilket tillåter replikering.
repl load tpcds_orc from '/tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0';
Mata ut det senaste replikerade händelse-ID:t
Kommandot REPL STATUS [database name] körs på målkluster och matar ut den senast replikerade event_id. Kommandot gör det också möjligt för användare att veta vilket tillstånd deras målkluster replikeras till. Du kan använda utdata från det här kommandot för att konstruera nästa REPL DUMP kommando för inkrementell replikering.
repl status tpcds_orc;
Exempel på utdata>
| last_repl_id |
|---|
| 2925 |
Dumpa relevanta data och metadata till datasjön
Kommandot REPL DUMP [database name] FROM [event-id] { TO [event-id] } { LIMIT [number of events] } används för att dumpa relevanta metadata och data till Azure Data Lake Storage. Det här kommandot används i den inkrementella fasen och körs på källlagret. FROM [event-id] Krävs för den inkrementella fasen och värdet event-id för kan härledas genom att köra REPL STATUS [database name] kommandot på mållagret.
repl dump tpcds_orc from 2925;
Exempel på utdata>
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-466466agad0 | 2960 |
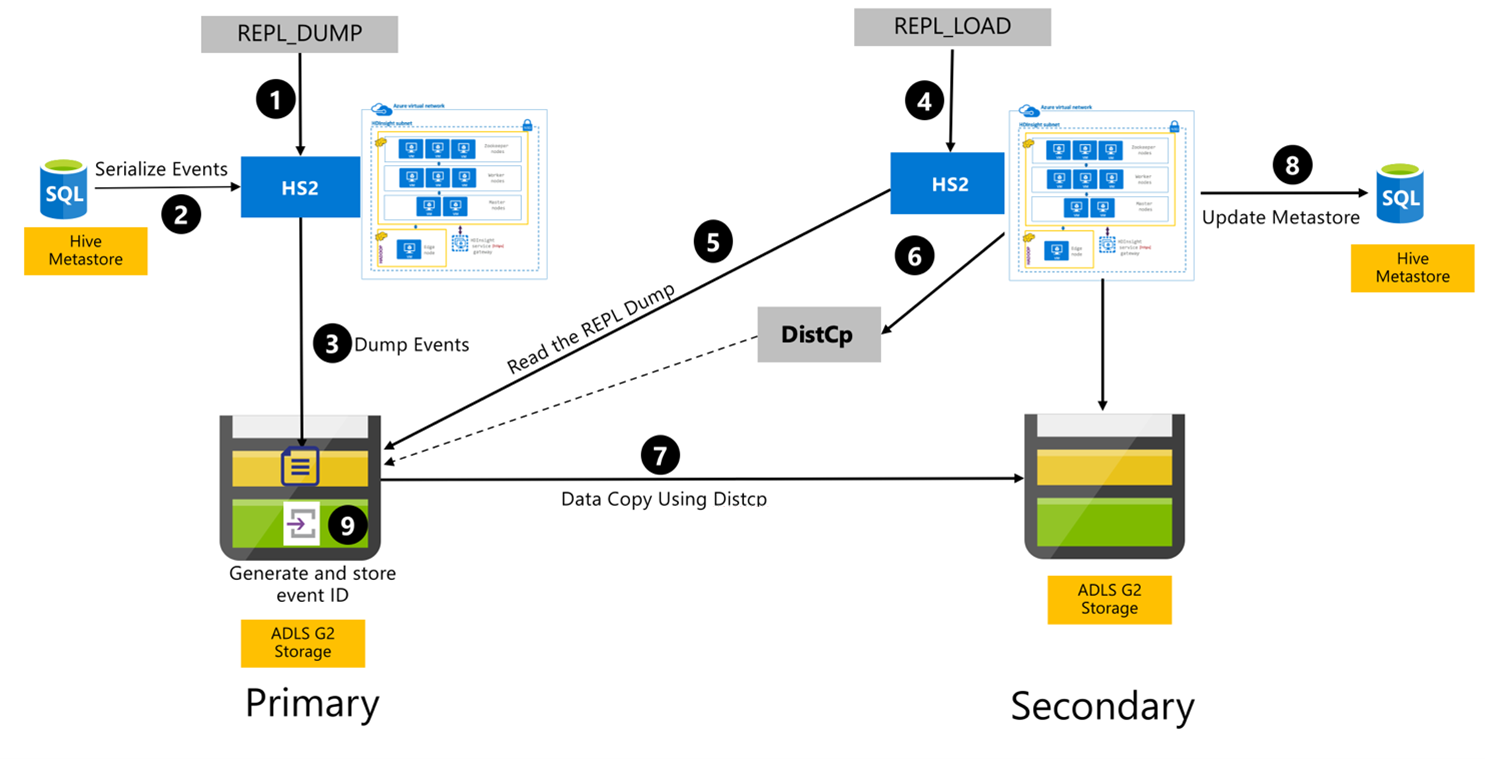
Hive-replikeringsprocess
Följande steg är de sekventiella händelser som äger rum under Hive Replication-processen.
Se till att de tabeller som ska replikeras anges som replikeringskälla för en viss princip.
Kommandot
REPL_DUMPutfärdas till det primära klustret med associerade begränsningar som databasnamn, händelse-ID-intervall och Azure Data Lake Storage Gen2-lagrings-URL.Systemet serialiserar en dump av alla spårade händelser från metaarkivet till det senaste. Den här dumpen lagras i Azure Data Lake Storage Gen2-lagringskontot i det primära klustret på den URL som anges av
REPL_DUMP.Det primära klustret bevarar replikeringsmetadata till det primära klustrets Azure Data Lake Storage Gen2-lagring. Sökvägen kan konfigureras i Hive Config-användargränssnittet i Ambari. Processen tillhandahåller sökvägen där metadata lagras och ID för den senaste spårade DML/DDL-händelsen.
Kommandot
REPL_LOADutfärdas från det sekundära klustret. Kommandot pekar på den sökväg som konfigurerades i steg 3.Det sekundära klustret läser metadatafilen med spårade händelser som skapades i steg 3. Kontrollera att det sekundära klustret har nätverksanslutning till Azure Data Lake Storage Gen2-lagringen för det primära klustret där de spårade händelserna lagras
REPL_DUMP.Det sekundära klustret skapar distribuerad kopieringsberäkning (
DistCP).Det sekundära klustret kopierar data från det primära klustrets lagring.
Metaarkivet på det sekundära klustret uppdateras.
Det senast spårade händelse-ID:t lagras i det primära metaarkivet.
Inkrementell replikering följer samma process och kräver det senaste replikerade händelse-ID:t som indata. Detta leder till en inkrementell kopia sedan den senaste replikeringshändelsen. Inkrementella replikering automatiseras normalt med en förutbestämd frekvens för att uppnå nödvändiga mål för återställningspunkter (RPO).
Replikeringsmönster
Replikeringen konfigureras normalt på ett enkelriktat sätt mellan den primära och den sekundära, där den primära hanterar läs- och skrivbegäranden. Det sekundära klustret hanterar endast skrivskyddade begäranden. Skrivningar tillåts på den sekundära om det uppstår en katastrof, men omvänd replikering måste konfigureras tillbaka till den primära.
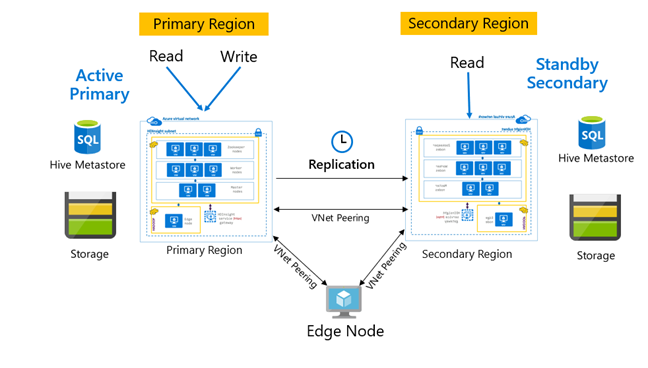
Det finns många mönster som lämpar sig för Hive-replikering, inklusive primär – sekundär, hubb och eker och relä.
I HDInsight Active Primary – Standby Secondary är ett vanligt BCDR-mönster (affärskontinuitet och haveriberedskap) och HiveReplicationV2 kan använda det här mönstret med regionalt avgränsade HDInsight Hadoop-kluster med VNet-peering. En vanlig virtuell dator som är peer-kopplad till båda klustren kan användas som värd för replikeringsautomatiseringsskripten. Mer information om möjliga HDInsight BCDR-mönster finns i dokumentationen om affärskontinuitet i HDInsight.
Hive-replikering med Enterprise Security Package
I de fall där Hive-replikering planeras i HDInsight Hadoop-kluster med Enterprise Security Package måste du ta hänsyn till replikeringsmekanismer för Ranger-metaarkiv och Microsoft Entra Domain Services.
Använd replikuppsättningsfunktionen Microsoft Entra Domain Services för att skapa fler än en Microsoft Entra Domain Services-replikuppsättning per Microsoft Entra-klientorganisation i flera regioner. Varje enskild replikuppsättning måste peerkopplas med virtuella HDInsight-nätverk i respektive region. I den här konfigurationen tillämpas ändringar i Microsoft Entra Domain Services, inklusive konfiguration, användaridentitet och autentiseringsuppgifter, grupper, grupprincipobjekt, datorobjekt och andra ändringar på alla replikuppsättningar i den hanterade domänen med hjälp av Replikering av Microsoft Entra Domain Services.
Ranger-principer kan regelbundet säkerhetskopieras och replikeras från den primära till den sekundära med hjälp av Ranger Import-Export-funktioner. Du kan välja att replikera alla eller en delmängd av Ranger-principer beroende på vilken auktoriseringsnivå du vill implementera i det sekundära klustret.
Exempelkod
Följande kodsekvens innehåller ett exempel på hur bootstrapping och inkrementell replikering kan implementeras i en exempeltabell med namnet tpcds_orc.
Ange tabellen som källa för en replikeringsprincip.
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source. for'='replpolicy1');Bootstrap dumpar i det primära klustret.
repl dump tpcds_orc with ('hive.repl.rootdir'='/tmpag/hiveag/replag');Exempel på utdata>
dump_dir last_repl_id /tmpag/hiveag/replag/675d1bea-2361-4cad-bcbf-8680d305a27a 2925 Bootstrap-belastning i det sekundära klustret.
repl load tpcds_orc from '/tmpag/hiveag/replag 675d1bea-2361-4cad-bcbf-8680d305a27a';Kontrollera statusen
REPLi det sekundära klustret.repl status tpcds_orc;last_repl_id 2925 Inkrementell dump i det primära klustret.
repl dump tpcds_orc from 2925 with ('hive.repl.rootdir'='/tmpag/hiveag/ replag');Exempel på utdata>
dump_dir last_repl_id /tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31 2960 Inkrementell belastning på sekundärt kluster.
repl load tpcds_orc from '/tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31';Kontrollera
REPLstatus i det sekundära klustret.repl status tpcds_orc;last_repl_id 2960
Nästa steg
Mer information om de objekt som beskrivs i den här artikeln finns i:
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för