Felsök ett jobb som är långsamt eller som inte fungerar i ett HDInsight-kluster
Om ett program som bearbetar data i ett HDInsight-kluster antingen körs långsamt eller misslyckas med en felkod, har du flera felsökningsalternativ. Om dina jobb tar längre tid att köra än förväntat, eller om du ser långsamma svarstider i allmänhet, kan det finnas fel uppströms från klustret, till exempel de tjänster som klustret körs på. Den vanligaste orsaken till dessa avmattningar är dock otillräcklig skalning. När du skapar ett nytt HDInsight-kluster väljer du lämpliga storlekar för virtuella datorer.
Om du vill diagnostisera ett långsamt eller felande kluster samlar du in information om alla aspekter av miljön, till exempel tillhörande Azure-tjänster, klusterkonfiguration och jobbkörningsinformation. En användbar diagnostik är att försöka återskapa feltillståndet i ett annat kluster.
- Steg 1: Samla in data om problemet.
- Steg 2: Verifiera HDInsight-klustermiljön.
- Steg 3: Visa klustrets hälsa.
- Steg 4: Granska miljöstacken och versionerna.
- Steg 5: Granska klusterloggfilerna.
- Steg 6: Kontrollera konfigurationsinställningarna.
- Steg 7: Återskapa felet på ett annat kluster.
Steg 1: Samla in data om problemet
HDInsight innehåller många verktyg som du kan använda för att identifiera och felsöka problem med kluster. Följande steg vägleder dig genom de här verktygen och ger förslag på hur du kan identifiera problemet.
Identifiera problemet
Tänk på följande frågor för att identifiera problemet:
- Vad förväntade jag mig att hända? Vad hände i stället?
- Hur lång tid tog det att köra processen? Hur länge ska den ha körts?
- Har mina uppgifter alltid körts långsamt i det här klustret? Kördes de snabbare på ett annat kluster?
- När uppstod det här problemet först? Hur ofta har det hänt sedan dess?
- Har något ändrats i klusterkonfigurationen?
Klusterinformation
Viktig klusterinformation omfattar:
- Klusternamn.
- Klusterregion – sök efter regionavbrott.
- HDInsight-klustertyp och -version.
- Typ och antal HDInsight-instanser som angetts för huvud- och arbetsnoderna.
Azure Portal kan ange följande information:
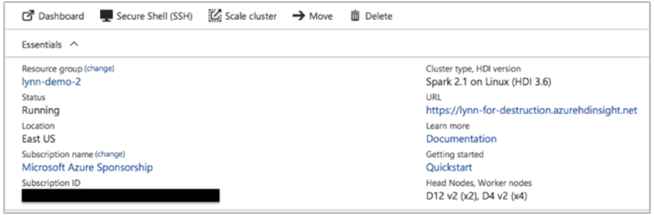
Du kan också använda Azure CLI:
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
Ett annat alternativ är att använda PowerShell. Mer information finns i Hantera Apache Hadoop-kluster i HDInsight med Azure PowerShell.
Steg 2: Verifiera HDInsight-klustermiljön
Varje HDInsight-kluster förlitar sig på olika Azure-tjänster och på programvara med öppen källkod, till exempel Apache HBase och Apache Spark. HDInsight-kluster kan också anropa andra Azure-tjänster, till exempel Azure Virtual Networks. Ett klusterfel kan orsakas av någon av de tjänster som körs i klustret eller av en extern tjänst. En konfigurationsändring av klustertjänsten kan också orsaka att klustret misslyckas.
Tjänstinformation
- Kontrollera versionerna av bibliotek med öppen källkod.
- Sök efter avbrott i Azure-tjänsten.
- Sök efter användningsgränser för Azure-tjänsten.
- Kontrollera konfigurationen av Azure Virtual Network-undernätet.
Visa konfigurationsinställningar för kluster med Ambari-användargränssnittet
Apache Ambari tillhandahåller hantering och övervakning av ett HDInsight-kluster med ett webbgränssnitt och ett REST-API. Ambari ingår i Linux-baserade HDInsight-kluster. Välj fönstret Klusterinstrumentpanel på sidan Azure Portal HDInsight. Välj instrumentpanelen för HDInsight-klustret för att öppna Ambari-användargränssnittet och ange autentiseringsuppgifterna för klusterinloggning.
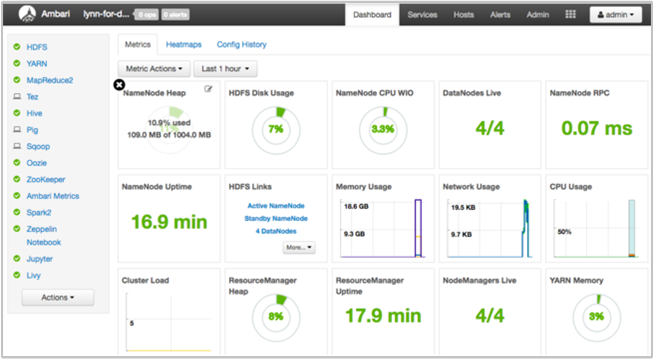
Om du vill öppna en lista över tjänstvyer väljer du Ambari-vyer på sidan Azure Portal. Den här listan beror på vilka bibliotek som är installerade. Du kan till exempel se YARN Queue Manager, Hive View och Tez View. Välj en tjänstlänk för att se konfigurations- och tjänstinformation.
Sök efter avbrott i Azure-tjänsten
HDInsight förlitar sig på flera Azure-tjänster. Den kör virtuella servrar på Azure HDInsight, lagrar data och skript på Azure Blob Storage eller Azure Data Lake Storage och indexerar loggfiler i Azure Table Storage. Störningar i dessa tjänster, även om de är sällsynta, kan orsaka problem i HDInsight. Om du har oväntade avmattningar eller fel i klustret kontrollerar du Instrumentpanelen för Azure-status. Status för varje tjänst visas efter region. Kontrollera klustrets region och även regioner för relaterade tjänster.
Kontrollera användningsgränser för Azure-tjänsten
Om du startar ett stort kluster eller har startat många kluster samtidigt kan ett kluster misslyckas om du har överskridit en Gräns för Azure-tjänsten. Tjänstbegränsningarna varierar beroende på din Azure-prenumeration. Läs mer i Azure-prenumeration och tjänstbegränsningar, kvoter och begränsningar. Du kan begära att Microsoft ökar antalet tillgängliga HDInsight-resurser (till exempel VM-kärnor och VM-instanser) med en Resource Manager-begäran om kärnkvotökning.
Kontrollera versionsversionen
Jämför klusterversionen med den senaste HDInsight-versionen. Varje HDInsight-version innehåller förbättringar som nya program, funktioner, korrigeringar och felkorrigeringar. Problemet som påverkar klustret kan ha åtgärdats i den senaste versionen. Kör om möjligt klustret med den senaste versionen av HDInsight och associerade bibliotek som Apache HBase, Apache Spark och andra.
Starta om dina klustertjänster
Om du upplever en avmattning i klustret kan du överväga att starta om dina tjänster via Ambari-användargränssnittet eller det klassiska Azure CLI.If you are experiencings in your cluster, consider restarting your services through the Ambari UI or the Azure Classic CLI. Klustret kan ha tillfälliga fel och omstart är det snabbaste sättet att stabilisera miljön och eventuellt förbättra prestandan.
Steg 3: Visa klustrets hälsa
HDInsight-kluster består av olika typer av noder som körs på virtuella datorinstanser. Varje nod kan övervakas för resurssvält, problem med nätverksanslutningen och andra problem som kan göra klustret långsammare. Varje kluster innehåller två huvudnoder och de flesta klustertyper innehåller en kombination av arbets- och kantnoder.
En beskrivning av de olika noder som varje klustertyp använder finns i Konfigurera kluster i HDInsight med Apache Hadoop, Apache Spark, Apache Kafka med mera.
I följande avsnitt beskrivs hur du kontrollerar hälsotillståndet för varje nod och det övergripande klustret.
Hämta en ögonblicksbild av klusterhälsan med Ambari UI-instrumentpanelen
Instrumentpanelen för Ambari-användargränssnittet (https://<clustername>.azurehdinsight.net) ger en översikt över klusterhälsa, till exempel drifttid, minne, nätverk och CPU-användning, HDFS-diskanvändning och så vidare. Använd avsnittet Värdar i Ambari för att visa resurser på värdnivå. Du kan också stoppa och starta om tjänster.
Kontrollera din WebHCat-tjänst
Ett vanligt scenario för Apache Hive-, Apache Pig- eller Apache Sqoop-jobb som misslyckas är ett fel med Tjänsten WebHCat (eller Templeton). WebHCat är ett REST-gränssnitt för fjärrjobbkörning, till exempel Hive, Pig, Scoop och MapReduce. WebHCat översätter begäranden om jobböverföring till Apache Hadoop YARN-program och returnerar en status som härleds från YARN-programstatusen. I följande avsnitt beskrivs vanliga HTTP-statuskoder för WebHCat.
BadGateway (502-statuskod)
Den här koden är ett allmänt meddelande från gatewaynoder och är de vanligaste felstatuskoderna. En möjlig orsak till detta är att WebHCat-tjänsten ligger nere på den aktiva huvudnoden. Om du vill söka efter den här möjligheten använder du följande CURL-kommando:
curl -u admin:{HTTP PASSWD} https://{CLUSTERNAME}.azurehdinsight.net/templeton/v1/status?user.name=admin
Ambari visar en avisering som visar de värdar där WebHCat-tjänsten är nere. Du kan prova att säkerhetskopiera WebHCat-tjänsten genom att starta om tjänsten på dess värd.
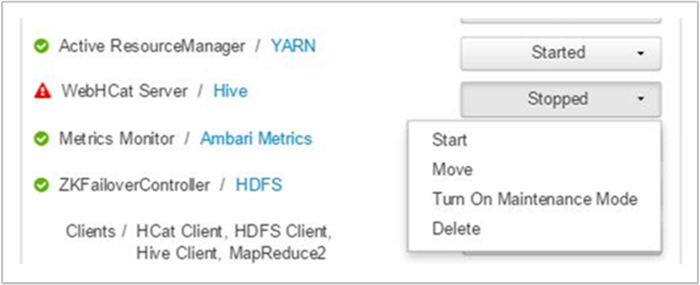
Om en WebHCat-server fortfarande inte visas kontrollerar du om det finns felmeddelanden i driftloggen. Mer detaljerad information finns i filerna stderr och stdout som refereras till på noden.
Tidsgränsen för WebHCat
En HDInsight Gateway överskrider svar som tar längre tid än två minuter och returnerar 502 BadGateway. WebHCat frågar YARN-tjänster efter jobbstatusar, och om YARN tar längre tid än två minuter att svara kan den begäran överskrida tidsgränsen.
I det här fallet granskar du följande loggar i /var/log/webhcat katalogen:
- webhcat.log är Log4j-loggen som servern skriver loggar till
- webhcat-console.log är serverns stdout när den startas
- webhcat-console-error.log är stderr för serverprocessen
Kommentar
Var och webhcat.log en rullas över dagligen och genererar filer med namnet webhcat.log.YYYY-MM-DD. Välj lämplig fil för det tidsintervall som du undersöker.
I följande avsnitt beskrivs några möjliga orsaker till Tidsgränser för WebHCat.
Tidsgräns för WebHCat-nivå
När WebHCat är under belastning, med fler än 10 öppna socketar, tar det längre tid att upprätta nya socketanslutningar, vilket kan resultera i en tidsgräns. Om du vill visa en lista över nätverksanslutningar till och från WebHCat använder du netstat den aktuella aktiva huvudnoden:
netstat | grep 30111
30111 är porten WebHCat lyssnar på. Antalet öppna socketar ska vara mindre än 10.
Om det inte finns några öppna socketar ger det tidigare kommandot inte något resultat. Om du vill kontrollera om Templeton är igång och lyssnar på port 30111 använder du:
netstat -l | grep 30111
Tidsgräns för YARN-nivå
Templeton anropar YARN för att köra jobb, och kommunikationen mellan Templeton och YARN kan orsaka en tidsgräns.
På YARN-nivån finns det två typer av timeouter:
Det kan ta tillräckligt lång tid att skicka ett YARN-jobb för att orsaka en tidsgräns.
Om du öppnar
/var/log/webhcat/webhcat.logloggfilen och söker efter "köat jobb" kan du se flera poster där körningstiden är för lång (>2 000 ms), med poster som visar ökande väntetider.Tiden för de köade jobben fortsätter att öka eftersom den hastighet med vilken nya jobb skickas är högre än den hastighet med vilken de gamla jobben slutförs. När YARN-minnet har använts till 100 %
joblauncher queuekan du inte längre låna kapacitet från standardkön. Därför kan inga fler nya jobb accepteras i jobbstartkön. Det här beteendet kan leda till att väntetiden blir längre och längre, vilket orsakar ett timeout-fel som vanligtvis följs av många andra.Följande bild visar jobbstartkön på 714,4 % överanvänd. Detta är acceptabelt så länge det fortfarande finns ledig kapacitet i standardkön att låna från. Men när klustret används fullt ut och YARN-minnet har en kapacitet på 100 % måste nya jobb vänta, vilket så småningom orsakar tidsgränser.

Det finns två sätt att lösa det här problemet: antingen minska hastigheten för nya jobb som skickas eller öka förbrukningshastigheten för gamla jobb genom att skala upp klustret.
YARN-bearbetning kan ta lång tid, vilket kan orsaka timeouter.
Lista alla jobb: Det här är ett tidskrävande anrop. Det här anropet räknar upp programmen från YARN Resource Manager och för varje slutfört program hämtas statusen från YARN JobHistoryServer. Med ett högre antal jobb kan det här anropet överskrida tidsgränsen.
Lista jobb som är äldre än sju dagar: HDInsight YARN JobHistoryServer har konfigurerats för att behålla slutförd jobbinformation i sju dagar (
mapreduce.jobhistory.max-age-msvärde). Om du försöker räkna upp rensade jobb resulterar det i en timeout.
Så här diagnostiserar du följande problem:
- Fastställa UTC-tidsintervallet som ska felsökas
- Välj lämpliga
webhcat.logfiler - Leta efter varnings- och felmeddelanden under den tiden
Andra WebHCat-fel
HTTP-statuskod 500
I de flesta fall där WebHCat returnerar 500 innehåller felmeddelandet information om felet. I annat fall letar du efter
webhcat.logWARN- och ERROR-meddelanden.Jobbfel
Det kan finnas fall där interaktioner med WebHCat lyckas, men jobben misslyckas.
Templeton samlar in jobbkonsolens utdata som
stderristatusdir, vilket ofta är användbart för felsökning.stderrinnehåller YARN-programidentifieraren för den faktiska frågan.
Steg 4: Granska miljöstacken och versionerna
Sidan Ambari UI Stack och Version innehåller information om konfiguration av klustertjänster och tjänstversionshistorik. Felaktiga versioner av Hadoop-tjänstbiblioteket kan vara en orsak till klusterfel. I Ambari-användargränssnittet väljer du menyn Admin och sedan Stacks och Versions. Välj fliken Versioner på sidan för att se information om tjänstversion:
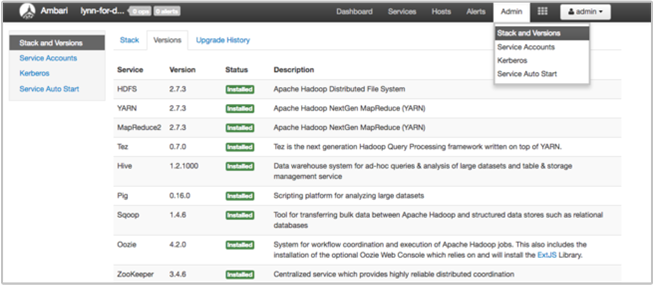
Steg 5: Granska loggfilerna
Det finns många typer av loggar som genereras från de många tjänster och komponenter som utgör ett HDInsight-kluster. WebHCat-loggfiler beskrivs tidigare. Det finns flera andra användbara loggfiler som du kan undersöka för att begränsa problem med klustret, enligt beskrivningen i följande avsnitt.
HDInsight-kluster består av flera noder, varav de flesta har till uppgift att köra skickade jobb. Jobb körs samtidigt, men loggfiler kan bara visa resultat linjärt. HDInsight kör nya uppgifter och avslutar andra som inte kan slutföras först. All den här aktiviteten loggas till
stderrfilerna ochsyslog.Loggfilerna för skriptåtgärden visar fel eller oväntade konfigurationsändringar när klustret skapas.
Hadoop-stegloggarna identifierar Hadoop-jobb som startats som en del av ett steg som innehåller fel.
Kontrollera skriptåtgärdsloggarna
HDInsight-skriptåtgärder kör skript i klustret manuellt eller när de anges. Skriptåtgärder kan till exempel användas för att installera ytterligare programvara i klustret eller för att ändra konfigurationsinställningarna från standardvärdena. Kontroll av skriptåtgärdsloggarna kan ge insikter om fel som inträffade under klusterkonfigurationen och konfigurationen. Du kan visa status för en skriptåtgärd genom att välja knappen ops i Ambari-användargränssnittet eller genom att komma åt loggarna från standardlagringskontot.
Skriptåtgärdsloggarna finns i \STORAGE_ACCOUNT_NAME\DEFAULT_CONTAINER_NAME\custom-scriptaction-logs\CLUSTER_NAME\DATE katalogen.
Visa HDInsight-loggar med hjälp av Ambari-snabblänkar
HDInsight Ambari-användargränssnittet innehåller ett antal snabblänkar . Om du vill komma åt logglänkarna för en viss tjänst i HDInsight-klustret öppnar du Ambari-användargränssnittet för klustret och väljer sedan tjänstlänken i listan till vänster. Välj listrutan Snabblänkar, sedan noden HDInsight av intresse och välj sedan länken för den associerade loggen.
Till exempel för HDFS-loggar:
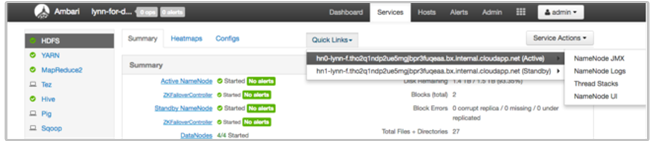
Visa Hadoop-genererade loggfiler
Ett HDInsight-kluster genererar loggar som skrivs till Azure-tabeller och Azure Blob Storage. YARN skapar sina egna körningsloggar. Mer information finns i Hantera loggar för ett HDInsight-kluster.
Granska heapdumpar
Heap-dumpar innehåller en ögonblicksbild av programmets minne, inklusive värdena för variabler vid den tidpunkten, som är användbara för att diagnostisera problem som uppstår vid körning. Mer information finns i Aktivera heapdumpar för Apache Hadoop-tjänster på Linux-baserade HDInsight.
Steg 6: Kontrollera konfigurationsinställningarna
HDInsight-kluster är förkonfigurerade med standardinställningar för relaterade tjänster, till exempel Hadoop, Hive, HBase och så vidare. Beroende på typen av kluster, dess maskinvarukonfiguration, dess antal noder, vilka typer av jobb du kör och de data du arbetar med (och hur dessa data bearbetas) kan du behöva optimera konfigurationen.
Detaljerade anvisningar om hur du optimerar prestandakonfigurationer för de flesta scenarier finns i Optimera klusterkonfigurationer med Apache Ambari. När du använder Spark kan du läsa Optimera Apache Spark-jobb för prestanda.
Steg 7: Återskapa felet i ett annat kluster
För att diagnostisera källan till ett klusterfel startar du ett nytt kluster med samma konfiguration och lägger sedan till det misslyckade jobbets steg igen en i taget. Kontrollera resultatet av varje steg innan du bearbetar nästa. Den här metoden ger dig möjlighet att korrigera och köra ett enda misslyckat steg igen. Den här metoden har också fördelen att du bara läser in dina indata en gång.
- Skapa ett nytt testkluster med samma konfiguration som det misslyckade klustret.
- Skicka det första jobbsteget till testklustret.
- När steget är klart kontrollerar du om det finns fel i stegloggfilerna. Anslut till testklustrets huvudnod och visa loggfilerna där. Stegloggfilerna visas bara efter att steget har körts under en viss tid, slutförts eller misslyckas.
- Om det första steget lyckades kör du nästa steg. Om det finns fel undersöker du felet i loggfilerna. Om det var ett fel i koden gör du korrigeringen och kör steget igen.
- Fortsätt tills alla steg körs utan fel.
- När du är klar med felsökningen av testklustret tar du bort det.