Snabbstart: Interaktiv dataomvandling med Apache Spark i Azure Machine Learning
Azure Machine Learning-integrering med Azure Synapse Analytics ger enkel åtkomst till Apache Spark-ramverket för att hantera interaktiva dataomvandlingar i Azure Machine Learning. Den här åtkomsten möjliggör interaktiv dataomvandling i Azure Machine Learning Notebook.
I den här snabbstartsguiden får du lära dig hur du utför interaktiva dataomvandlingar med Serverlös Spark-beräkning i Azure Machine Learning, Azure Data Lake Storage (ADLS) Gen 2-lagringskonto och genomströmning av användaridentitet.
Förutsättningar
- En Azure-prenumeration; Om du inte har en Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
- En Azure Machine Learning-arbetsyta. Besök Skapa arbetsyteresurser.
- Ett Azure Data Lake Storage(ADLS) Gen 2-lagringskonto. Besök Skapa ett ADLS Gen 2-lagringskonto (Azure Data Lake Storage).
Lagra autentiseringsuppgifter för Azure-lagringskonto som hemligheter i Azure Key Vault
Så här lagrar du autentiseringsuppgifter för Azure-lagringskontot som hemligheter i Azure Key Vault med azure-portalens användargränssnitt:
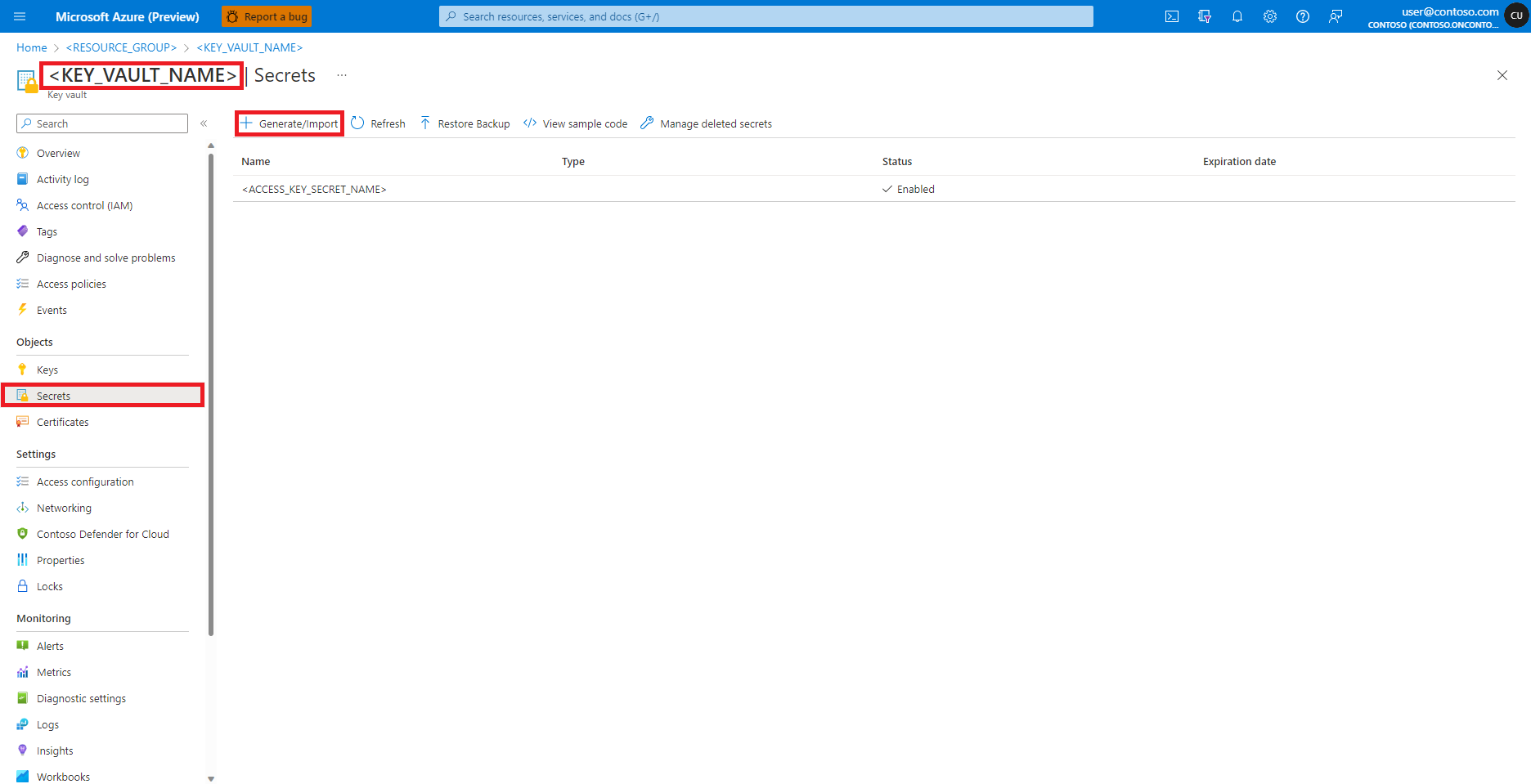
Gå till ditt Azure Key Vault i Azure-portalen
Välj Hemligheter i den vänstra panelen
Välj + Generera/importera
På skärmen Skapa en hemlighet anger du ett Namn för den hemlighet som du vill skapa
Gå till Azure Blob Storage-kontot i Azure-portalen, som du ser i den här bilden:
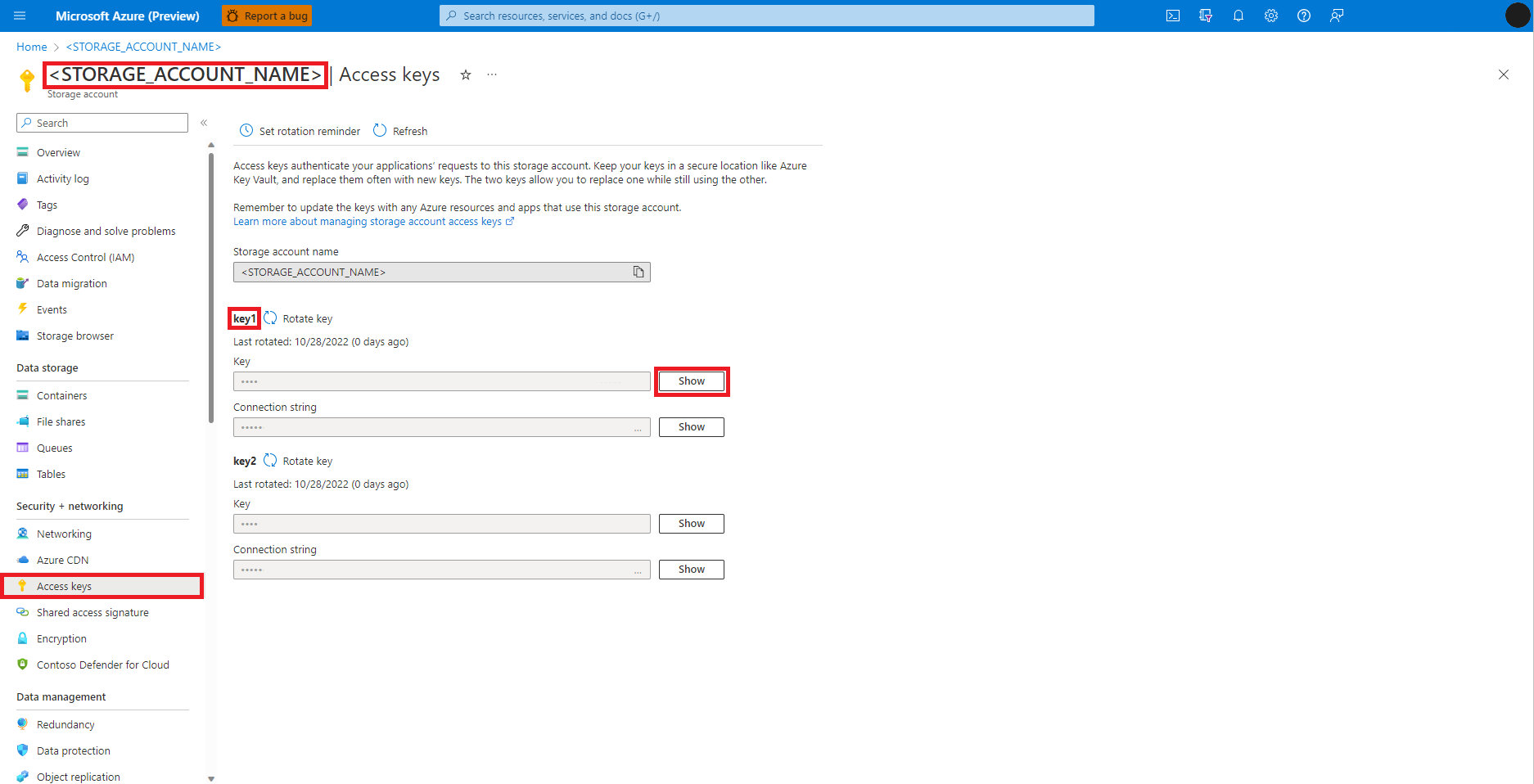
Välj Åtkomstnycklar på sidan Azure Blob Storage-konto till vänster
Välj Visa bredvid Nyckel 1 och sedan Kopiera till Urklipp för att hämta åtkomstnyckeln för lagringskontot
Kommentar
Välj lämpliga alternativ för att kopiera
- Azure Blob Storage-token för signatur för delad åtkomst (SAS) för container med delad åtkomst
- Autentiseringsuppgifter för Azure Data Lake Storage (ADLS) Gen 2-lagringskontots huvudnamn
- klientorganisations-ID:
- klient-ID och
- hemlighet
på respektive användargränssnitt när du skapar Azure Key Vault-hemligheterna åt dem
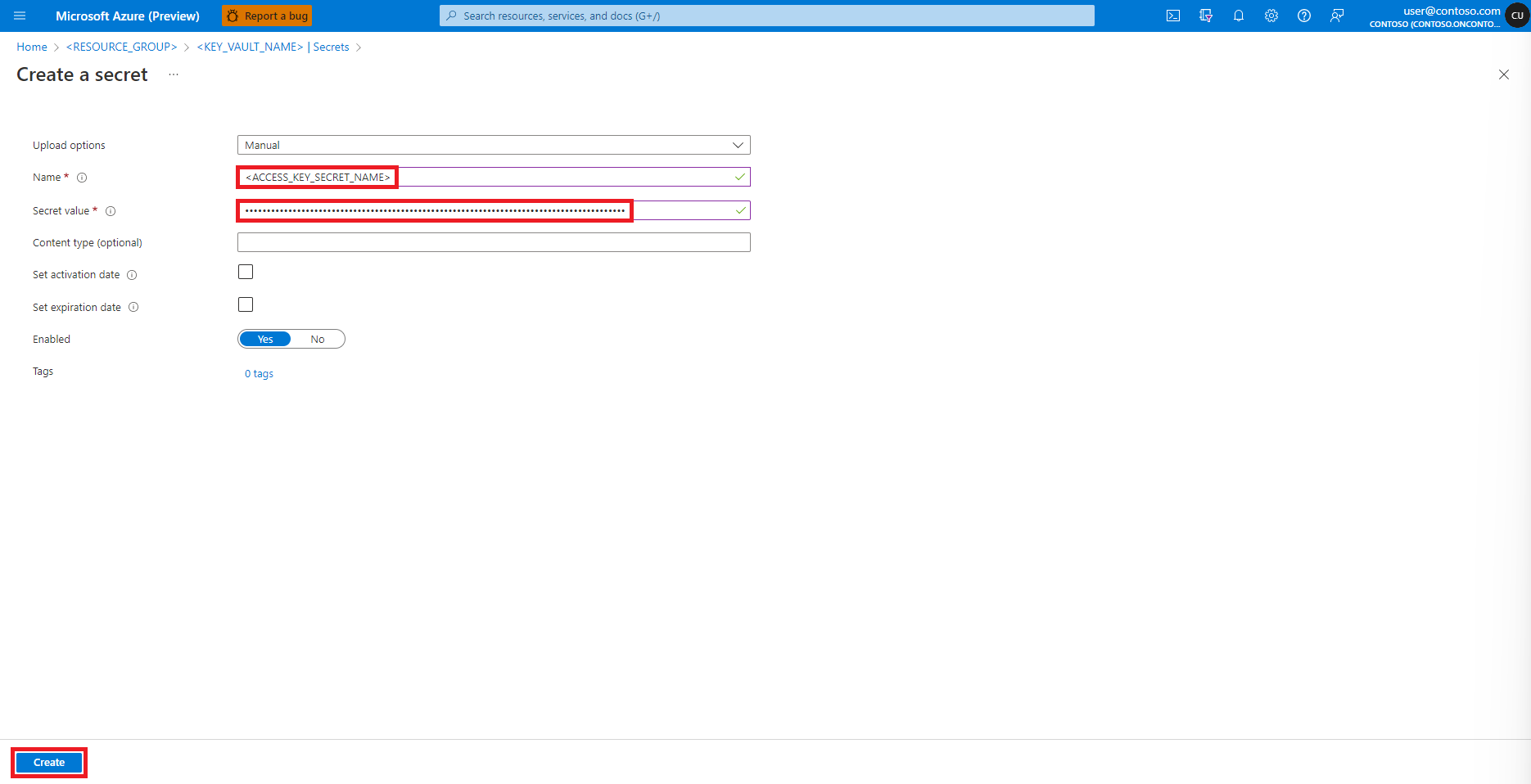
Gå tillbaka till skärmen Skapa en hemlighet
I textrutan Hemligt värde anger du åtkomstnyckelns autentiseringsuppgifter för Azure Storage-kontot, som kopierades till Urklipp i föregående steg
Välj Skapa
Dricks
Azure CLI och Azure Key Vault hemligt klientbibliotek för Python kan också skapa Azure Key Vault-hemligheter.
Lägga till rolltilldelningar i Azure Storage-konton
Vi måste se till att sökvägarna för indata och utdata är tillgängliga innan vi startar interaktiv dataomvandling. För det första för
användaridentiteten för notebook-sessionens inloggade användare
eller
ett huvudnamn för tjänsten
tilldela roller för läsare och lagringsblobdataläsare till användaridentiteten för den inloggade användaren. Men i vissa scenarier kanske vi vill skriva tillbaka de vridna data till Azure-lagringskontot. Rollerna Läsare och Lagringsblobdataläsare ger skrivskyddad åtkomst till användaridentiteten eller tjänstens huvudnamn. Om du vill aktivera läs- och skrivåtkomst tilldelar du rollerna Deltagare och Lagringsblobdatadeltagare till användaridentiteten eller tjänstens huvudnamn. Så här tilldelar du lämpliga roller till användaridentiteten:
Sök och välj tjänsten Lagringskonton

På sidan Lagringskonton väljer du Azure Data Lake Storage (ADLS) Gen 2-lagringskontot i listan. En sida som visar översikten över lagringskontot öppnas
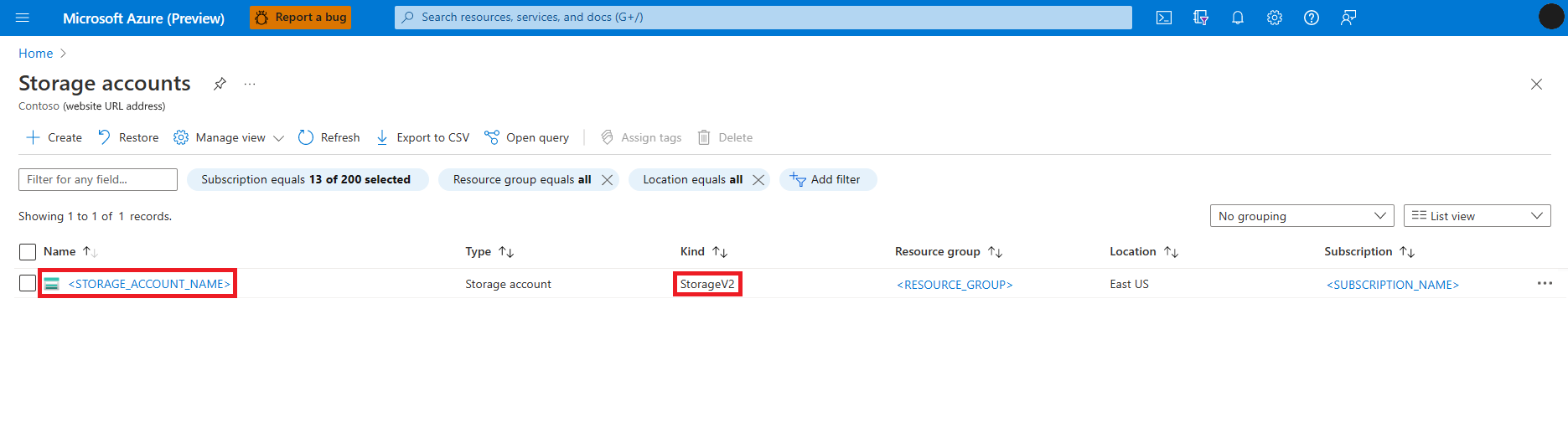
Välj Åtkomstkontroll (IAM) på den vänstra panelen
Välj Lägg till rolltilldelning
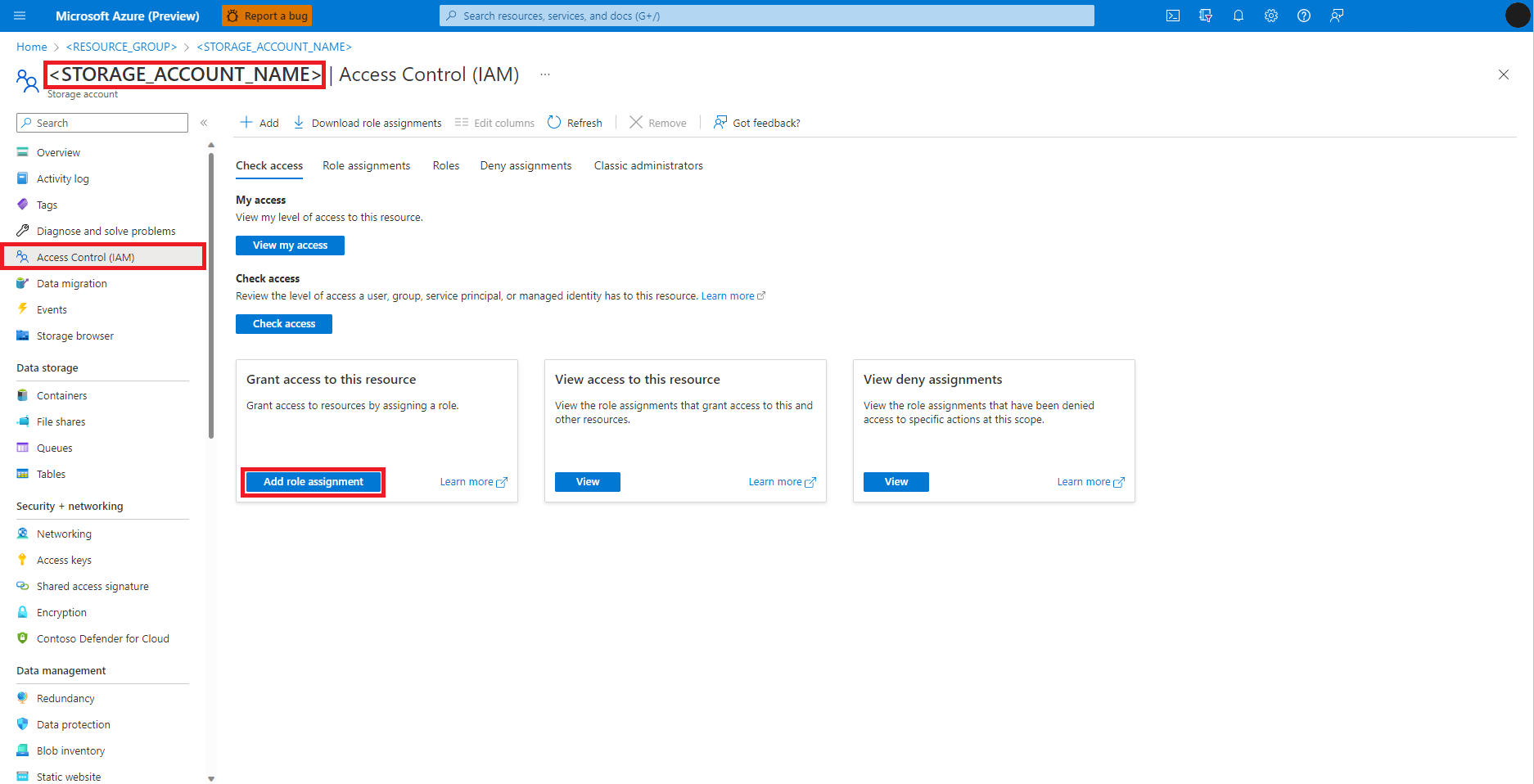
Hitta och välj rollen Storage Blob Data Contributor
Välj Nästa
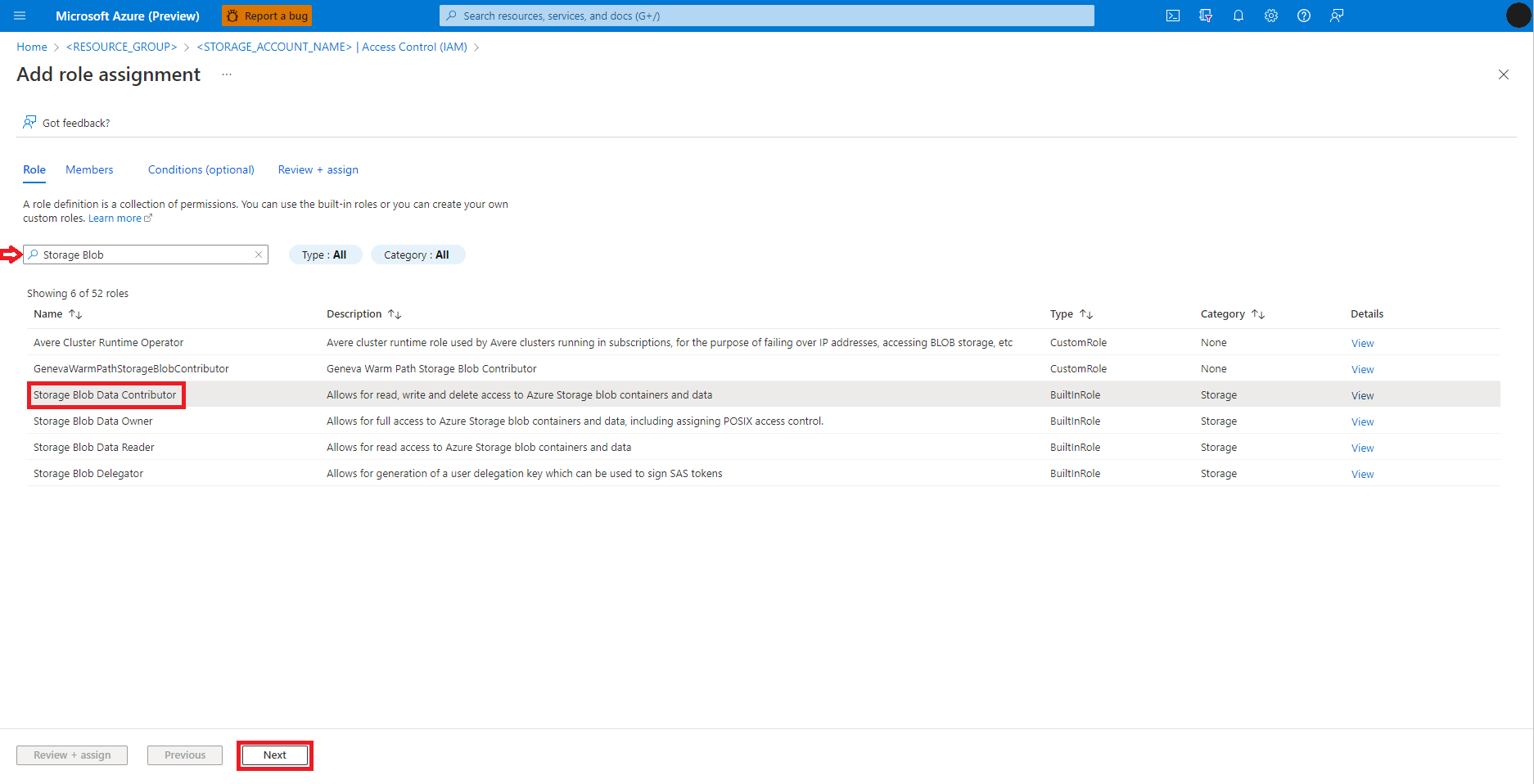
Välj Användare, grupp eller tjänstens huvudnamn
Välj + Välj medlemmar
Sök efter användaridentiteten nedan Välj
Välj användaridentiteten i listan så att den visas under Valda medlemmar
Välj lämplig användaridentitet
Välj Nästa
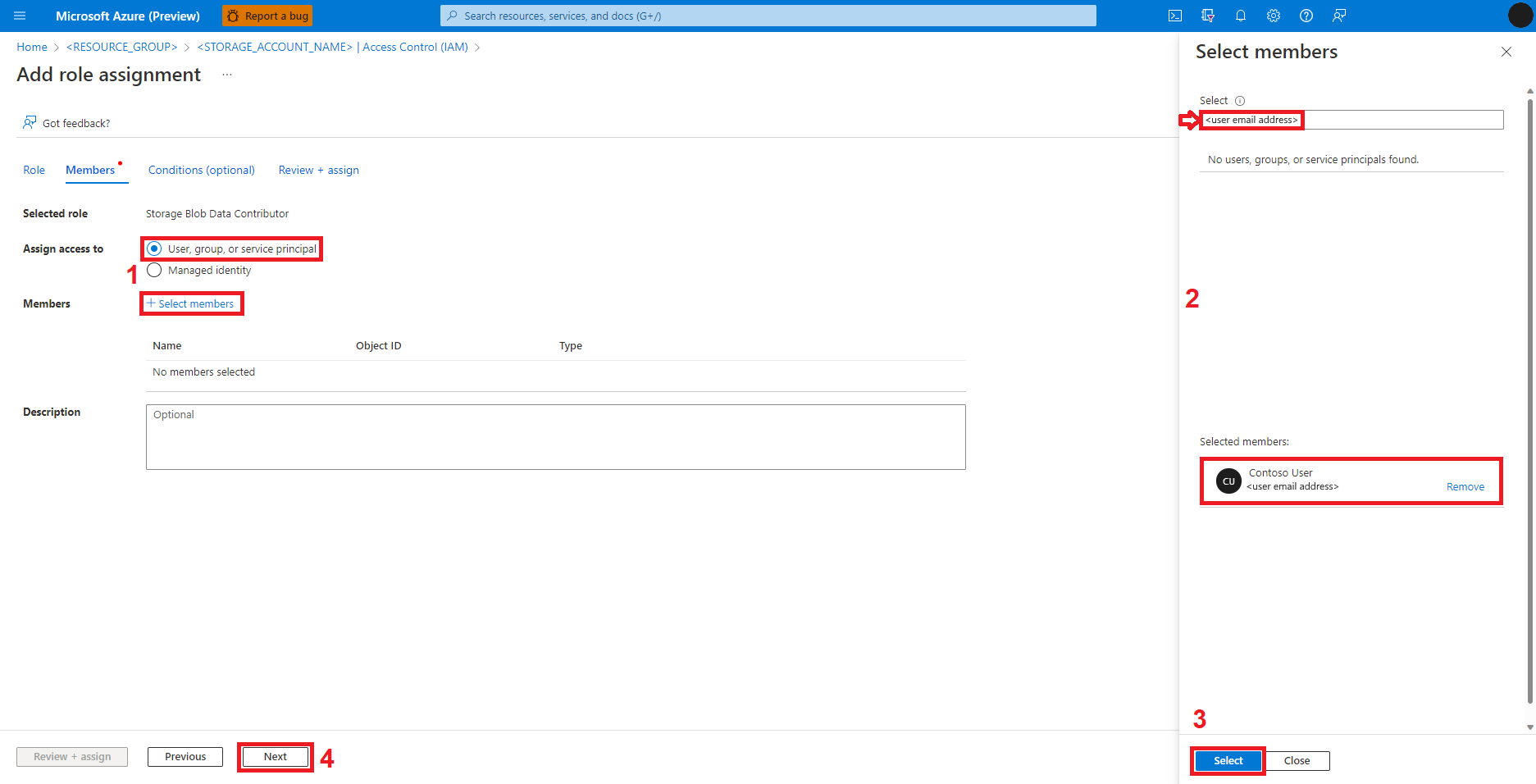
Välj Granska + tilldela
Upprepa steg 2–13 för rolltilldelning för deltagare






När användaridentiteten har tilldelats lämpliga roller bör data i Azure Storage-kontot bli tillgängliga.
Kommentar
Om en ansluten Synapse Spark-pool pekar på en Synapse Spark-pool, på en Azure Synapse-arbetsyta som har ett hanterat virtuellt nätverk associerat med den, bör du konfigurera en hanterad privat slutpunkt till ett lagringskonto för att säkerställa dataåtkomst.
Säkerställa resursåtkomst för Spark-jobb
För att komma åt data och andra resurser kan Spark-jobb använda antingen en hanterad identitet eller genomströmning av användaridentitet. I följande tabell sammanfattas de olika mekanismerna för resursåtkomst när du använder Azure Machine Learning serverlös Spark-beräkning och bifogad Synapse Spark-pool.
| Spark-pool | Identiteter som stöds | Standardidentitet |
|---|---|---|
| Serverlös Spark-beräkning | Användaridentitet, användartilldelad hanterad identitet kopplad till arbetsytan | Användaridentitet |
| Bifogad Synapse Spark-pool | Användaridentitet, användartilldelad hanterad identitet kopplad till den anslutna Synapse Spark-poolen, systemtilldelad hanterad identitet för den anslutna Synapse Spark-poolen | Systemtilldelad hanterad identitet för den anslutna Synapse Spark-poolen |
Om CLI- eller SDK-koden definierar ett alternativ för att använda hanterad identitet förlitar sig Azure Machine Learning serverlös Spark-beräkning på en användartilldelad hanterad identitet som är kopplad till arbetsytan. Du kan koppla en användartilldelad hanterad identitet till en befintlig Azure Machine Learning-arbetsyta med Azure Machine Learning CLI v2 eller med ARMClient.
Nästa steg
- Apache Spark i Azure Machine Learning
- Bifoga och hantera en Synapse Spark-pool i Azure Machine Learning
- Interaktiv dataomvandling med Apache Spark i Azure Machine Learning
- Skicka Spark-jobb i Azure Machine Learning
- Kodexempel för Spark-jobb med Hjälp av Azure Machine Learning CLI
- Kodexempel för Spark-jobb med Hjälp av Azure Machine Learning Python SDK
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för