GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
Azure CLI ml-tillägget v2 (aktuellt)
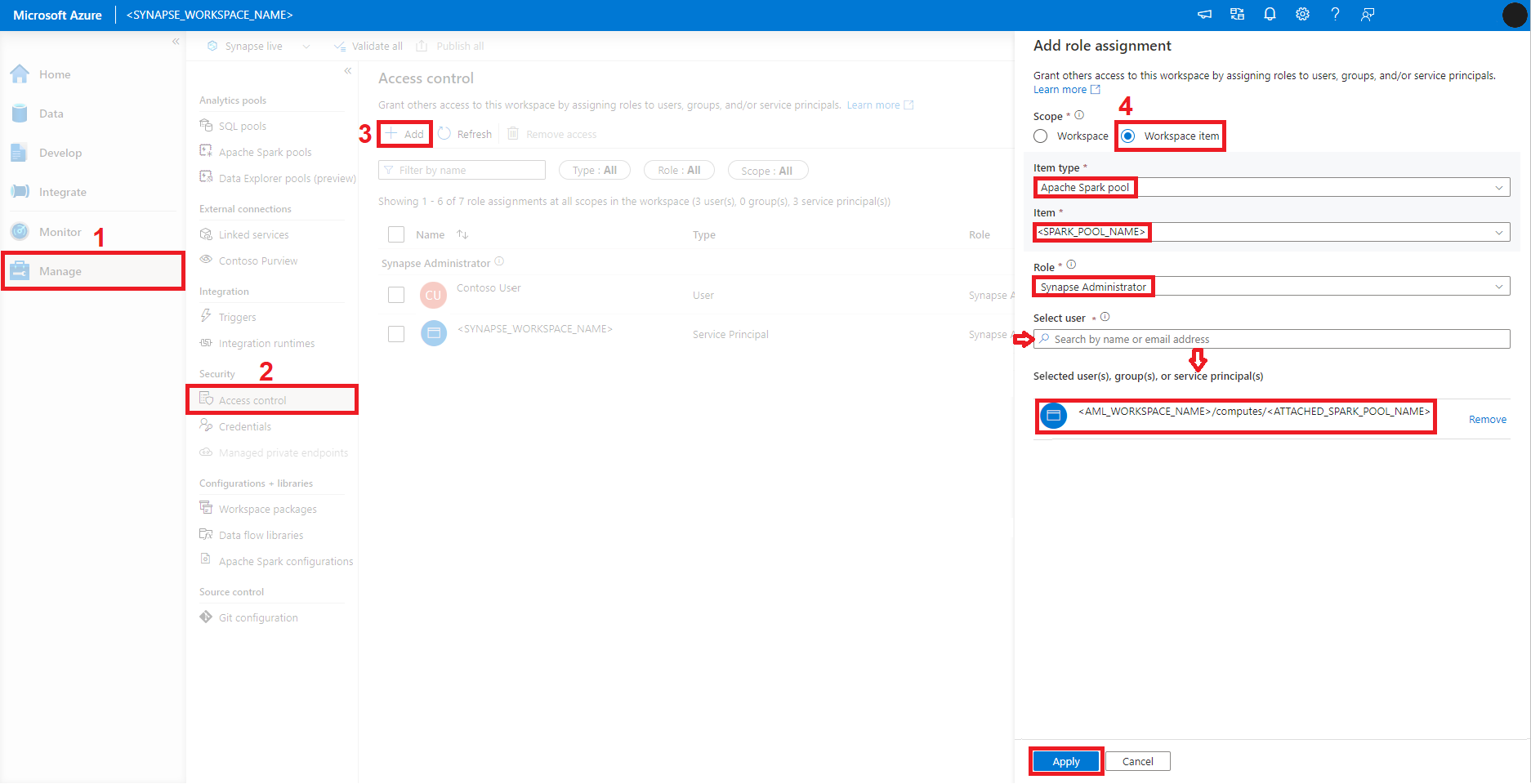
Med Azure Machine Learning CLI kan vi använda intuitiv YAML-syntax och kommandon från kommandoradsgränssnittet för att koppla och hantera en Synapse Spark-pool.
Om du vill definiera en bifogad Synapse Spark-pool med YAML-syntax bör YAML-filen omfatta följande egenskaper:
name – namnet på den bifogade Synapse Spark-poolen.
type – ange den här egenskapen till synapsespark.
resource_id – Den här egenskapen ska ange resurs-ID-värdet för Synapse Spark-poolen som skapats på Azure Synapse Analytics-arbetsytan. Azure-resurs-ID:t innehåller
Azure-prenumerations-ID,
resursgruppnamn,
Azure Synapse Analytics-arbetsytans namn och
namnet på Synapse Spark-poolen.
name: <ATTACHED_SPARK_POOL_NAME>
type: synapsespark
resource_id: /subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>
identity – den här egenskapen definierar identitetstypen som ska tilldelas till den anslutna Synapse Spark-poolen. Det kan krävas något av följande värden:
För typen identity user_assignedbör du också ange en lista med user_assigned_identities värden. Varje användartilldelad identitet ska deklareras som ett element i listan med hjälp resource_id av värdet för den användartilldelade identiteten. Den första användartilldelade identiteten i listan används för att skicka ett jobb som standard.
name: <ATTACHED_SPARK_POOL_NAME>
type: synapsespark
resource_id: /subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>
identity:
type: user_assigned
user_assigned_identities:
- resource_id: /subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>
YAML-filerna ovan kan användas i az ml compute attach kommandot som --file parameter. En Synapse Spark-pool kan kopplas till en Azure Machine Learning-arbetsyta i en angiven resursgrupp i en prenumeration med az ml compute attach kommandot som visas här:
az ml compute attach --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Det här exemplet visar förväntade utdata från kommandot ovan:
Class SynapseSparkCompute: This is an experimental class, and may change at any time. Please visit https://aka.ms/azuremlexperimental for more information.
{
"auto_pause_settings": {
"auto_pause_enabled": true,
"delay_in_minutes": 15
},
"created_on": "2022-09-13 19:01:05.109840+00:00",
"id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>/computes/<ATTACHED_SPARK_POOL_NAME>",
"location": "eastus2",
"name": "<ATTACHED_SPARK_POOL_NAME>",
"node_count": 5,
"node_family": "MemoryOptimized",
"node_size": "Small",
"provisioning_state": "Succeeded",
"resourceGroup": "<RESOURCE_GROUP>",
"resource_id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>",
"scale_settings": {
"auto_scale_enabled": false,
"max_node_count": 0,
"min_node_count": 0
},
"spark_version": "3.2",
"type": "synapsespark"
}
Om den bifogade Synapse Spark-poolen, med namnet som anges i YAML-specifikationsfilen, redan finns på arbetsytan, az ml compute attach uppdaterar kommandokörningen den befintliga poolen med informationen i YAML-specifikationsfilen. Du kan uppdatera
- identitetstyp
- användartilldelade identiteter
- taggar
värden via YAML-specifikationsfilen.
Kör kommandot för att visa information om en bifogad Synapse Spark-pool az ml compute show . Skicka namnet på den anslutna Synapse Spark-poolen med parametern --name enligt följande:
az ml compute show --name <ATTACHED_SPARK_POOL_NAME> --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Det här exemplet visar förväntade utdata från kommandot ovan:
<ATTACHED_SPARK_POOL_NAME>
{
"auto_pause_settings": {
"auto_pause_enabled": true,
"delay_in_minutes": 15
},
"created_on": "2022-09-13 19:01:05.109840+00:00",
"id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>/computes/<ATTACHED_SPARK_POOL_NAME>",
"location": "eastus2",
"name": "<ATTACHED_SPARK_POOL_NAME>",
"node_count": 5,
"node_family": "MemoryOptimized",
"node_size": "Small",
"provisioning_state": "Succeeded",
"resourceGroup": "<RESOURCE_GROUP>",
"resource_id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>",
"scale_settings": {
"auto_scale_enabled": false,
"max_node_count": 0,
"min_node_count": 0
},
"spark_version": "3.2",
"type": "synapsespark"
}
Om du vill se en lista över alla beräkningar, inklusive de bifogade Synapse Spark-poolerna på en arbetsyta, använder du az ml compute list kommandot . Använd namnparametern för att skicka namnet på arbetsytan enligt följande:
az ml compute list --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Det här exemplet visar förväntade utdata från kommandot ovan:
[
{
"auto_pause_settings": {
"auto_pause_enabled": true,
"delay_in_minutes": 15
},
"created_on": "2022-09-09 21:28:54.871251+00:00",
"id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>/computes/<ATTACHED_SPARK_POOL_NAME>",
"identity": {
"principal_id": "<PRINCIPAL_ID>",
"tenant_id": "<TENANT_ID>",
"type": "system_assigned"
},
"location": "eastus2",
"name": "<ATTACHED_SPARK_POOL_NAME>",
"node_count": 5,
"node_family": "MemoryOptimized",
"node_size": "Small",
"provisioning_state": "Succeeded",
"resourceGroup": "<RESOURCE_GROUP>",
"resource_id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>",
"scale_settings": {
"auto_scale_enabled": false,
"max_node_count": 0,
"min_node_count": 0
},
"spark_version": "3.2",
"type": "synapsespark"
},
...
]
GÄLLER FÖR: Python SDK azure-ai-ml v2 (aktuell)
Azure Machine Learning Python SDK tillhandahåller praktiska funktioner för att ansluta och hantera Synapse Spark-pooler med hjälp av Python-kod i Azure Machine Learning Notebooks.
Om du vill koppla en Synapse Compute med Python SDK skapar du först en instans av klassen azure.ai.ml.MLClient. Detta ger praktiska funktioner för interaktion med Azure Machine Learning-tjänster. Följande kodexempel använder azure.identity.DefaultAzureCredential för att ansluta till en arbetsyta i resursgruppen för en angiven Azure-prenumeration. I följande kodexempel definierar du SynapseSparkCompute med följande parametrar:
name – användardefinierat namn på den nya bifogade Synapse Spark-poolen.resource_id – resurs-ID för Synapse Spark-poolen som skapades tidigare på Azure Synapse Analytics-arbetsytan
Ett azure.ai.ml.MLClient.begin_create_or_update()-funktionsanrop kopplar den definierade Synapse Spark-poolen till Azure Machine Learning-arbetsytan.
from azure.ai.ml import MLClient
from azure.ai.ml.entities import SynapseSparkCompute
from azure.identity import DefaultAzureCredential
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace_name = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace_name
)
synapse_name = "<ATTACHED_SPARK_POOL_NAME>"
synapse_resource = "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>"
synapse_comp = SynapseSparkCompute(name=synapse_name, resource_id=synapse_resource)
ml_client.begin_create_or_update(synapse_comp)
Om du vill koppla en Synapse Spark-pool som använder systemtilldelad identitet skickar du IdentityConfiguration, med typen inställd på SystemAssigned, som identity parameter för SynapseSparkCompute klassen. Det här kodfragmentet bifogar en Synapse Spark-pool som använder systemtilldelad identitet:
# import required libraries
from azure.ai.ml import MLClient
from azure.ai.ml.entities import SynapseSparkCompute, IdentityConfiguration
from azure.identity import DefaultAzureCredential
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace_name = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace_name
)
synapse_name = "<ATTACHED_SPARK_POOL_NAME>"
synapse_resource = "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>"
synapse_identity = IdentityConfiguration(type="SystemAssigned")
synapse_comp = SynapseSparkCompute(
name=synapse_name, resource_id=synapse_resource, identity=synapse_identity
)
ml_client.begin_create_or_update(synapse_comp)
En Synapse Spark-pool kan också använda en användartilldelad identitet. För en användartilldelad identitet kan du skicka en definition för hanterad identitet med klassen IdentityConfiguration som identity parameter för SynapseSparkCompute klassen. För den hanterade identitetsdefinition som används på det här sättet anger du type till UserAssigned. Skicka dessutom en user_assigned_identities parameter. Parametern user_assigned_identities är en lista över objekt i klassen UserAssignedIdentity. Den resource_id användartilldelade identiteten fyller i varje UserAssignedIdentity klassobjekt. Det här kodfragmentet bifogar en Synapse Spark-pool som använder en användartilldelad identitet:
# import required libraries
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
SynapseSparkCompute,
IdentityConfiguration,
UserAssignedIdentity,
)
from azure.identity import DefaultAzureCredential
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace_name = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace_name
)
synapse_name = "<ATTACHED_SPARK_POOL_NAME>"
synapse_resource = "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>"
synapse_identity = IdentityConfiguration(
type="UserAssigned",
user_assigned_identities=[
UserAssignedIdentity(
resource_id="/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>"
)
],
)
synapse_comp = SynapseSparkCompute(
name=synapse_name, resource_id=synapse_resource, identity=synapse_identity
)
ml_client.begin_create_or_update(synapse_comp)
Kommentar
Funktionen azure.ai.ml.MLClient.begin_create_or_update() kopplar en ny Synapse Spark-pool, om en pool med det angivna namnet inte redan finns på arbetsytan. Men om en Synapse Spark-pool med det angivna namnet redan är kopplad till arbetsytan, uppdaterar ett anrop till azure.ai.ml.MLClient.begin_create_or_update() funktionen den befintliga anslutna poolen med den nya identiteten eller identiteterna.