Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Azure Machine Learning stöder fristående inlämningar av maskininlärningsjobb och skapande av maskininlärningspipelines som omfattar flera steg i arbetsflödet för maskininlärning. Azure Machine Learning hanterar både skapande av fristående Spark-jobb och skapandet av återanvändbara Spark-komponenter som Azure Machine Learning-pipelines kan använda. I den här artikeln får du lära dig hur du skickar Spark-jobb med:
- Azure Machine Learning-studio användargränssnitt
- Azure Machine Learning CLI
- Azure Machine Learning SDK
Mer information om Apache Spark i Azure Machine Learning-begreppfinns i den här resursen.
Förutsättningar
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
- En Azure-prenumeration; Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
- En Azure Machine Learning-arbetsyta. Mer information finns i Skapa arbetsyteresurser .
- Skapa en Azure Machine Learning-beräkningsinstans.
- Installera Azure Machine Learning CLI.
- (Valfritt): En bifogad Synapse Spark-pool på Azure Machine Learning-arbetsytan.
Kommentar
- Mer information om resursåtkomst när du använder Serverlös Spark-beräkning i Azure Machine Learning och bifogad Synapse Spark-pool finns i Säkerställa resursåtkomst för Spark-jobb.
- Azure Machine Learning tillhandahåller en delad kvotpool , från vilken alla användare kan komma åt beräkningskvoten för att utföra testning under en begränsad tid. När du använder den serverlösa Spark-beräkningen ger Azure Machine Learning dig åtkomst till den här delade kvoten under en kort tid.
Koppla användartilldelad hanterad identitet med CLI v2
- Skapa en YAML-fil som definierar den användartilldelade hanterade identiteten som ska kopplas till arbetsytan:
identity: type: system_assigned,user_assigned tenant_id: <TENANT_ID> user_assigned_identities: '/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>': {} - Med parametern
--fileanvänder du YAML-filen iaz ml workspace updatekommandot för att koppla den användartilldelade hanterade identiteten:az ml workspace update --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --name <AML_WORKSPACE_NAME> --file <YAML_FILE_NAME>.yaml
Koppla användartilldelad hanterad identitet med hjälp av ARMClient
- Installera
ARMClient, ett enkelt kommandoradsverktyg som anropar Azure Resource Manager-API:et. - Skapa en JSON-fil som definierar den användartilldelade hanterade identiteten som ska kopplas till arbetsytan:
{ "properties":{ }, "location": "<AZURE_REGION>", "identity":{ "type":"SystemAssigned,UserAssigned", "userAssignedIdentities":{ "/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>": { } } } } - Om du vill koppla den användartilldelade hanterade identiteten till arbetsytan kör du följande kommando i PowerShell-prompten eller kommandotolken.
armclient PATCH https://management.azure.com/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>?api-version=2022-05-01 '@<JSON_FILE_NAME>.json'
Kommentar
- För att säkerställa en lyckad körning av Spark-jobbet tilldelar du rollerna Deltagare och Lagringsblobdatadeltagare på azure-lagringskontot som används för dataindata och utdata till den identitet som Spark-jobbet använder
- Offentlig nätverksåtkomst bör aktiveras i Azure Synapse-arbetsytan för att säkerställa att Spark-jobbet körs med hjälp av en ansluten Synapse Spark-pool.
- Om en ansluten Synapse Spark-pool pekar på en Synapse Spark-pool på en Azure Synapse-arbetsyta som har ett hanterat virtuellt nätverk associerat med den, bör du konfigurera en hanterad privat slutpunkt för lagringskontot för att säkerställa dataåtkomst.
- Serverlös Spark-beräkning stöder azure Machine Learning-hanterat virtuellt nätverk. Om ett hanterat nätverk etableras för den serverlösa Spark-beräkningen bör motsvarande privata slutpunkter för lagringskontot också etableras för att säkerställa dataåtkomst.
Skicka ett fristående Spark-jobb
När du har gjort nödvändiga ändringar för Python-skriptparameterisering kan du använda ett Python-skript som utvecklats med interaktiv dataomvandling för att skicka ett batchjobb för att bearbeta en större mängd data. Du kan skicka ett batchjobb för dataomvandling som ett fristående Spark-jobb.
Ett Spark-jobb kräver ett Python-skript som tar argument. Du kan ändra Python-koden som ursprungligen utvecklades från interaktiv dataomvandling för att utveckla skriptet. Ett Python-exempelskript visas här.
# titanic.py
import argparse
from operator import add
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
parser = argparse.ArgumentParser()
parser.add_argument("--titanic_data")
parser.add_argument("--wrangled_data")
args = parser.parse_args()
print(args.wrangled_data)
print(args.titanic_data)
df = pd.read_csv(args.titanic_data, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy(
"mean"
) # Replace missing values in Age column with the mean value
df.fillna(
value={"Cabin": "None"}, inplace=True
) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
df.to_csv(args.wrangled_data, index_col="PassengerId")
Kommentar
Det här Python-kodexemplet använder pyspark.pandas. Endast Spark-körningsversionen 3.2 eller senare stöder detta.
Det här skriptet tar två argument som skickar sökvägen till indata respektive utdatamappen:
--titanic_data--wrangled_data
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
För att skapa ett jobb kan du definiera ett fristående Spark-jobb som en YAML-specifikationsfil som du kan använda i az ml job create kommandot med parametern --file . Definiera dessa egenskaper i YAML-filen:
YAML-egenskaper i Spark-jobbspecifikationen
type- inställd påspark.code– definierar platsen för mappen som innehåller källkod och skript för det här jobbet.entry– definierar startpunkten för jobbet. Den bör omfatta någon av följande egenskaper:-
file– definierar namnet på Python-skriptet som fungerar som en startpunkt för jobbet. -
class_name– definierar namnet på klassen som servrar som en startpunkt för jobbet.
-
py_files– definierar en lista över.zip,.eggeller.pyfiler som ska placeras iPYTHONPATH, för lyckad körning av jobbet. Den här egenskapen är valfri.jars– definierar en lista över.jarfiler som ska inkluderas på Spark-drivrutinen och körenCLASSPATHför att jobbet ska kunna köras. Den här egenskapen är valfri.files– definierar en lista över filer som ska kopieras till arbetskatalogen för varje köre för lyckad jobbkörning. Den här egenskapen är valfri.archives– definierar en lista över arkiv som ska extraheras till arbetskatalogen för varje utförare för lyckad jobbkörning. Den här egenskapen är valfri.conf– definierar dessa Egenskaper för Spark-drivrutin och körkörning:-
spark.driver.cores: antalet kärnor för Spark-drivrutinen. -
spark.driver.memory: allokerat minne för Spark-drivrutinen i gigabyte (GB). -
spark.executor.cores: antalet kärnor för Spark-kören. -
spark.executor.memory: minnesallokeringen för Spark-kören i gigabyte (GB). -
spark.dynamicAllocation.enabled– om exekutorer ska allokeras dynamiskt, som ettTrueellerFalse-värde. - Om dynamisk allokering av exekutorer är aktiverad definierar du följande egenskaper:
-
spark.dynamicAllocation.minExecutors– det minsta antalet Spark-körinstanser för dynamisk allokering. -
spark.dynamicAllocation.maxExecutors– det maximala antalet Spark-körinstanser för dynamisk allokering.
-
- Om dynamisk allokering av exekutorer är inaktiverad definierar du den här egenskapen:
-
spark.executor.instances– antalet Spark-körinstanser.
-
-
environment– en Azure Machine Learning-miljö för att köra jobbet.args– de kommandoradsargument som ska skickas till python-skriptet för jobbinmatningspunkten. Ett exempel finns i YAML-specifikationsfilen som finns här.resources– Den här egenskapen definierar de resurser som ska användas av en serverlös Spark-beräkning utan Azure Machine Learning. Den använder följande egenskaper:-
instance_type– den beräkningsinstanstyp som ska användas för Spark-poolen. Följande instanstyper stöds för närvarande:standard_e4s_v3standard_e8s_v3standard_e16s_v3standard_e32s_v3standard_e64s_v3
-
runtime_version– definierar Spark-körningsversionen. Följande Spark-körningsversioner stöds för närvarande:3.33.4Viktigt!
Azure Synapse Runtime för Apache Spark: Meddelanden
- Azure Synapse Runtime för Apache Spark 3.3:
- EOLA-meddelandedatum: 12 juli 2024
- Supportdatum: 31 mars 2025. Efter det här datumet inaktiveras körningen.
- För fortsatt support och optimala prestanda rekommenderar vi att du migrerar till Apache Spark 3.4.
- Azure Synapse Runtime för Apache Spark 3.3:
Det här är en YAML-exempelfil:
resources: instance_type: standard_e8s_v3 runtime_version: "3.4"-
compute– Den här egenskapen definierar namnet på en bifogad Synapse Spark-pool, som du ser i det här exemplet:compute: mysparkpoolinputs– Den här egenskapen definierar indata för Spark-jobbet. Indata för ett Spark-jobb kan vara antingen ett literalvärde eller data som lagras i en fil eller mapp.- Ett literalvärde kan vara ett tal, ett booleskt värde eller en sträng. Några exempel visas här:
inputs: sampling_rate: 0.02 # a number hello_number: 42 # an integer hello_string: "Hello world" # a string hello_boolean: True # a boolean value -
Data som lagras i en fil eller mapp bör definieras med hjälp av följande egenskaper:
-
type– ange den här egenskapen tilluri_file, elleruri_folder, för indata som finns i en fil eller en mapp. -
path– URI för indata, till exempelazureml://,abfss://ellerwasbs://. -
mode- ställ in den här egenskapen pådirect. Det här exemplet visar definitionen av ett jobbindata, som kan kallas$${inputs.titanic_data}}:inputs: titanic_data: type: uri_file path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv mode: direct
-
- Ett literalvärde kan vara ett tal, ett booleskt värde eller en sträng. Några exempel visas här:
outputs– den här egenskapen definierar Spark-jobbutdata. Utdata för ett Spark-jobb kan skrivas till antingen en fil eller en mappplats, som definieras med hjälp av följande tre egenskaper:-
type– du kan ange den här egenskapen tilluri_fileelleruri_folder, för att skriva utdata till en fil eller en mapp. -
path– den här egenskapen definierar utdataplats-URI:n, till exempelazureml://,abfss://ellerwasbs://. -
mode- ställ in den här egenskapen pådirect. Det här exemplet visar definitionen av ett jobbutdata, som du kan referera till som${{outputs.wrangled_data}}:outputs: wrangled_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/data/wrangled/ mode: direct
-
identity– Den här valfria egenskapen definierar den identitet som används för att skicka det här jobbet. Det kan hauser_identityochmanagedvärden. Om YAML-specifikationen inte definierar en identitet använder Spark-jobbet standardidentiteten.
Fristående Spark-jobb
I det här exemplet visar YAML-specifikationen ett fristående Spark-jobb. Den använder en serverlös Spark-beräkning i Azure Machine Learning:
$schema: http://azureml/sdk-2-0/SparkJob.json
type: spark
code: ./
entry:
file: titanic.py
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.executor.instances: 2
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
identity:
type: user_identity
resources:
instance_type: standard_e4s_v3
runtime_version: "3.4"
Kommentar
Om du vill använda en bifogad Synapse Spark-pool definierar du compute egenskapen i yaml-exempelspecifikationsfilen som visades tidigare, i stället för egenskapen resources .
Du kan använda YAML-filerna som visades tidigare i az ml job create kommandot med parametern --file för att skapa ett fristående Spark-jobb enligt följande:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Du kan köra kommandot ovan från:
- terminalen för en Azure Machine Learning-beräkningsinstans.
- en Visual Studio Code-terminal som är ansluten till en Azure Machine Learning-beräkningsinstans.
- din lokala dator som har Azure Machine Learning CLI installerat.
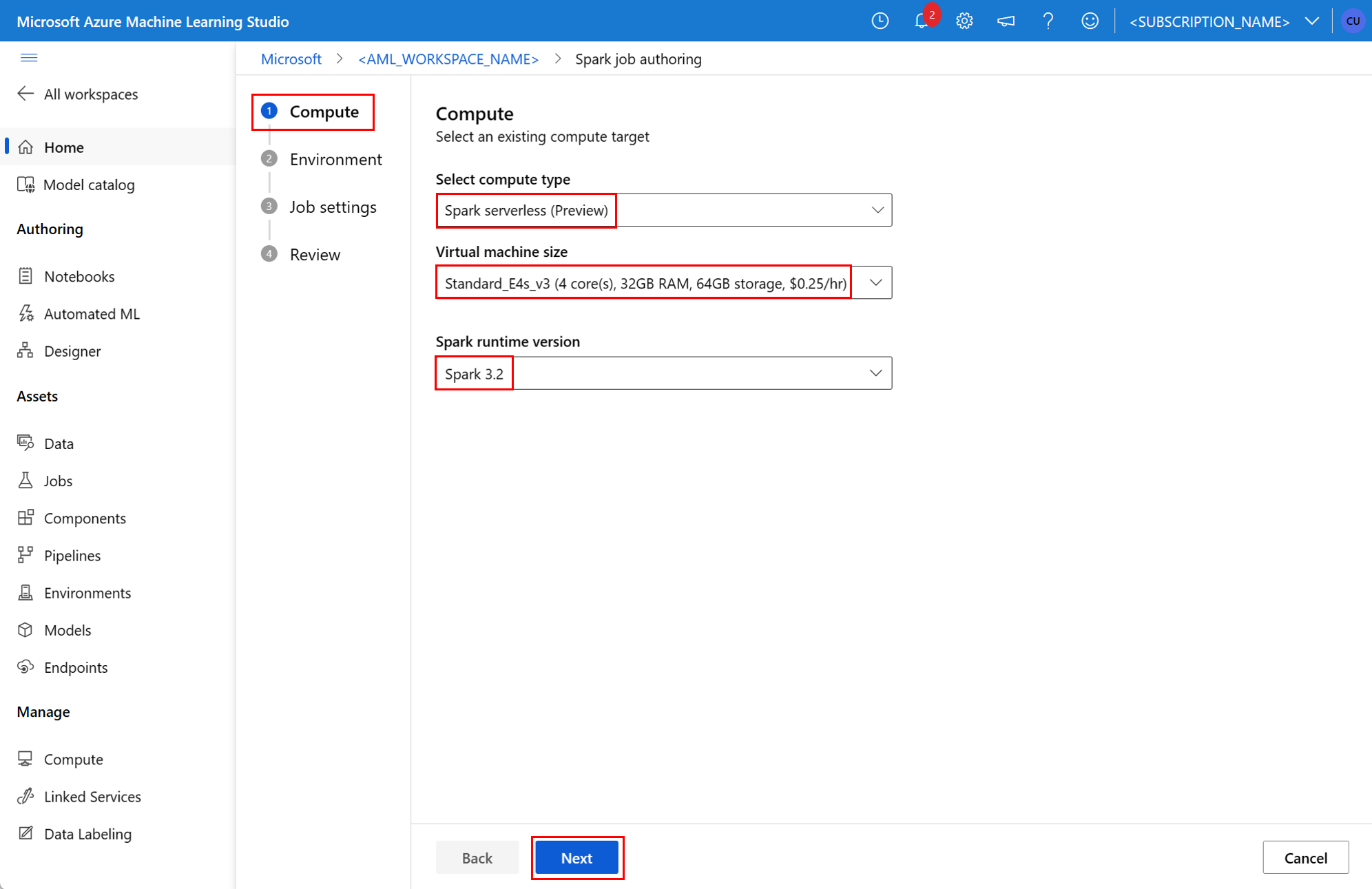
Spark-komponent i ett pipelinejobb
En Spark-komponent ger flexibiliteten att använda samma komponent i flera Azure Machine Learning-pipelines som ett pipelinesteg.
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
YAML-syntaxen för en Spark-komponent liknar YAML-syntaxen för Spark-jobbspecifikationen på de flesta sätt. Dessa egenskaper definieras på olika sätt i YAML-specifikationen för Spark-komponenten:
name- Namnet på Spark-komponenten.version– versionen av Spark-komponenten.display_name– namnet på Spark-komponenten som ska visas i användargränssnittet och någon annanstans.description– beskrivningen av Spark-komponenten.inputs– den här egenskapen liknar egenskapeninputssom beskrivs i YAML-syntaxen för Spark-jobbspecifikationen, förutom att denpathinte definierar egenskapen. Det här kodfragmentet visar ett exempel på egenskapen Spark-komponentinputs:inputs: titanic_data: type: uri_file mode: directoutputs– den här egenskapen liknar egenskapenoutputssom beskrivs i YAML-syntaxen för Spark-jobbspecifikationen, förutom att denpathinte definierar egenskapen. Det här kodfragmentet visar ett exempel på egenskapen Spark-komponentoutputs:outputs: wrangled_data: type: uri_folder mode: direct
Kommentar
En Spark-komponent definierar identityinte egenskaperna , compute eller resources . YAML-specifikationsfilen för pipeline definierar dessa egenskaper.
Den här YAML-specifikationsfilen innehåller ett exempel på en Spark-komponent:
$schema: http://azureml/sdk-2-0/SparkComponent.json
name: titanic_spark_component
type: spark
version: 1
display_name: Titanic-Spark-Component
description: Spark component for Titanic data
code: ./src
entry:
file: titanic.py
inputs:
titanic_data:
type: uri_file
mode: direct
outputs:
wrangled_data:
type: uri_folder
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.dynamicAllocation.enabled: True
spark.dynamicAllocation.minExecutors: 1
spark.dynamicAllocation.maxExecutors: 4
Du kan använda Spark-komponenten som definierats i yaml-specifikationsfilen ovan i ett Azure Machine Learning-pipelinejobb. Besök YAML-schemaresursen för pipelinejobbet för att lära dig mer om YAML-syntaxen som definierar ett pipelinejobb. Det här exemplet visar en YAML-specifikationsfil för ett pipelinejobb, med en Spark-komponent och en Serverlös Spark-beräkning utan Azure Machine Learning:
$schema: http://azureml/sdk-2-0/PipelineJob.json
type: pipeline
display_name: Titanic-Spark-CLI-Pipeline
description: Spark component for Titanic data in Pipeline
jobs:
spark_job:
type: spark
component: ./spark-job-component.yaml
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
identity:
type: managed
resources:
instance_type: standard_e8s_v3
runtime_version: "3.4"
Kommentar
Om du vill använda en bifogad Synapse Spark-pool definierar du compute egenskapen i yaml-exempelspecifikationsfilen som visas ovan, i stället resources för egenskapen.
Du kan använda YAML-specifikationsfilen som visas ovan i az ml job create kommandot med hjälp av parametern --file för att skapa ett pipelinejobb enligt följande:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Du kan köra kommandot ovan från:
- terminalen för en Azure Machine Learning-beräkningsinstans.
- terminalen för Visual Studio Code som är ansluten till en Azure Machine Learning-beräkningsinstans.
- din lokala dator som har Azure Machine Learning CLI installerat.
Felsöka Spark-jobb
Om du vill felsöka ett Spark-jobb kan du komma åt loggarna som genererats för jobbet i Azure Machine Learning-studio. Så här visar du loggarna för ett Spark-jobb:
- Navigera till Jobb från den vänstra panelen i användargränssnittet för Azure Machine Learning-studio
- Välj fliken Alla jobb
- Välj visningsnamnvärdet för jobbet
- På sidan jobbinformation väljer du fliken Utdata + loggar
- I utforskaren expanderar du loggmappen och expanderar sedan mappen azureml
- Få åtkomst till Spark-jobbloggarna i mapparna för drivrutins- och bibliotekshanteraren
Kommentar
Om du vill felsöka Spark-jobb som skapats under interaktiv dataomvandling i en notebook-session väljer du Jobbinformation i det övre högra hörnet i notebook-användargränssnittet. Ett Spark-jobb från en interaktiv notebook-session skapas under experimentnamnet notebook-runs.