Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
APPLIES TO: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
I Azure Machine Learning kan du använda en anpassad container för att distribuera en modell till en onlineslutpunkt. Anpassade containerdistributioner kan använda andra webbservrar än den Python Flask-standardserver som Azure Machine Learning använder.
När du använder en anpassad distribution kan du:
- Använd olika verktyg och tekniker, till exempel TensorFlow Serving (TF Serving), TorchServe, Triton Inference Server, Plumber R-paketet och minimibilden för Azure Machine Learning-inferens.
- Dra fortfarande nytta av den inbyggda övervakning, skalning, avisering och autentisering som Azure Machine Learning erbjuder.
Den här artikeln visar hur du använder en TF-serveringsbild för att hantera en TensorFlow-modell.
Prerequisites
En Azure Machine Learning-arbetsyta. Anvisningar för hur du skapar en arbetsyta finns i Skapa arbetsytan.
Azure CLI och
mltillägget eller Azure Machine Learning Python SDK v2:Information om hur du installerar Azure CLI och
mltillägget finns i Installera och konfigurera CLI (v2).Exemplen i den här artikeln förutsätter att du använder ett Bash-gränssnitt eller ett kompatibelt gränssnitt. Du kan till exempel använda ett gränssnitt på ett Linux-system eller Windows-undersystem för Linux.
En Azure-resursgrupp som innehåller din arbetsyta och som du eller din tjänstehuvudman har bidragsgivartillgång till. Om du använder stegen i Skapa arbetsytan för att konfigurera din arbetsyta uppfyller du det här kravet.
Docker Engine, installed and running locally. This prerequisite is highly recommended. Du behöver den för att distribuera en modell lokalt och det är användbart för felsökning.
Deployment examples
The following table lists deployment examples that use custom containers and take advantage of various tools and technologies.
| Example | Azure CLI-skript | Description |
|---|---|---|
| minimal/multimodel | deploy-custom-container-minimal-multimodel | Distribuerar flera modeller till en enda distribution genom att utöka Azure Machine Learning-slutsatsdragningens minimala avbildning. |
| minimal/single-model | deploy-custom-container-minimal-single-model | Distribuerar en enskild modell genom att utöka den minimala avbildningen av Azure Machine Learning-slutsatsdragningen. |
| mlflow/multideployment-scikit | deploy-custom-container-mlflow-multideployment-scikit | Distribuerar två MLFlow-modeller med olika Python-krav till två separata distributioner bakom en enda slutpunkt. Använder den minimala avbilden för Azure Machine Learning-inferens. |
| r/multimodel-plumber | deploy-custom-container-r-multimodel-plumber | Distribuerar tre regressionsmodeller till en slutpunkt. Använder Plumber R-paketet. |
| tfserving/half-plus-two | deploy-custom-container-tfserving-half-plus-two | Distribuerar en Half Plus Two-modell med hjälp av en anpassad TF Serving-container. Använder standardmodellens registreringsprocess. |
| tfserving/half-plus-two-integrated | deploy-custom-container-tfserving-half-plus-two-integrated | Distribuerar en Half Plus Two-modell med hjälp av en anpassad TF-servercontainer med modellen integrerad i avbildningen. |
| torchserve/densenet | deploy-custom-container-torchserve-densenet | Distribuerar en enskild modell med hjälp av en anpassad TorchServe-container. |
| triton/single-model | deploy-custom-container-triton-single-model | Distribuerar en Triton-modell med hjälp av en anpassad container. |
Den här artikeln visar hur du använder exemplet tfserving/half-plus-two.
Warning
Microsofts supportteam kanske inte kan hjälpa till att felsöka problem som orsakas av en anpassad avbildning. Om du får problem kan du bli ombedd att använda standardbilden eller någon av de bilder som Microsoft tillhandahåller för att se om problemet är specifikt för din bild.
Ladda ned källkoden
The steps in this article use code samples from the azureml-examples repository. Använd följande kommandon för att klona lagringsplatsen:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
Initiera miljövariabler
Om du vill använda en TensorFlow-modell behöver du flera miljövariabler. Kör följande kommandon för att definiera dessa variabler:
BASE_PATH=endpoints/online/custom-container/tfserving/half-plus-two
AML_MODEL_NAME=tfserving-mounted
MODEL_NAME=half_plus_two
MODEL_BASE_PATH=/var/azureml-app/azureml-models/$AML_MODEL_NAME/1
Ladda ned en TensorFlow-modell
Ladda ned och packa upp en modell som delar ett indatavärde med två och lägger till två i resultatet:
wget https://aka.ms/half_plus_two-model -O $BASE_PATH/half_plus_two.tar.gz
tar -xvf $BASE_PATH/half_plus_two.tar.gz -C $BASE_PATH
Testa en TF-serveringsbild lokalt
Använd Docker för att köra avbildningen lokalt för testning:
docker run --rm -d -v $PWD/$BASE_PATH:$MODEL_BASE_PATH -p 8501:8501 \
-e MODEL_BASE_PATH=$MODEL_BASE_PATH -e MODEL_NAME=$MODEL_NAME \
--name="tfserving-test" docker.io/tensorflow/serving:latest
sleep 10
Skicka liveness- och bedömningsbegäranden till avbildningen
Skicka en liveness-begäran för att kontrollera att processen i containern körs. Du bör få en svarsstatuskod på 200 OK.
curl -v http://localhost:8501/v1/models/$MODEL_NAME
Skicka en bedömningsbegäran för att kontrollera att du kan få förutsägelser om omärkta data:
curl --header "Content-Type: application/json" \
--request POST \
--data @$BASE_PATH/sample_request.json \
http://localhost:8501/v1/models/$MODEL_NAME:predict
Stoppa avbildningen
När du är klar med testningen lokalt stoppar du avbildningen:
docker stop tfserving-test
Distribuera din onlineslutpunkt till Azure
Utför stegen i följande avsnitt för att distribuera din onlineslutpunkt till Azure.
Skapa YAML-filer för slutpunkten och distributionen
Du kan konfigurera molndistributionen med hjälp av YAML. Om du till exempel vill konfigurera slutpunkten kan du skapa en YAML-fil med namnet tfserving-endpoint.yml som innehåller följande rader:
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: tfserving-endpoint
auth_mode: aml_token
För att konfigurera distributionen kan du skapa en YAML-fil med namnet tfserving-deployment.yml som innehåller följande rader:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: <model-version>
path: ./half_plus_two
environment_variables:
MODEL_BASE_PATH: /var/azureml-app/azureml-models/tfserving-mounted/<model-version>
MODEL_NAME: half_plus_two
environment:
#name: tfserving
#version: 1
image: docker.io/tensorflow/serving:latest
inference_config:
liveness_route:
port: 8501
path: /v1/models/half_plus_two
readiness_route:
port: 8501
path: /v1/models/half_plus_two
scoring_route:
port: 8501
path: /v1/models/half_plus_two:predict
instance_type: Standard_DS3_v2
instance_count: 1
I följande avsnitt beskrivs viktiga begrepp om YAML- och Python-parametrarna.
Base image
I avsnittet environment i YAML, eller Environment konstruktorn i Python, anger du basavbildningen som en parameter. Det här exemplet används docker.io/tensorflow/serving:latest som image värde.
Om du inspekterar containern kan du se att den här servern använder ENTRYPOINT kommandon för att starta ett startpunktsskript. Det skriptet tar miljövariabler som MODEL_BASE_PATH och MODEL_NAMEoch exponerar portar som 8501. Den här informationen gäller för den här servern och du kan använda den här informationen för att avgöra hur du definierar distributionen. Om du till exempel anger MODEL_BASE_PATH miljövariablerna och MODEL_NAME i distributionsdefinitionen använder TF Serving dessa värden för att initiera servern. Om du anger porten för varje väg till 8501 i distributionsdefinitionen dirigeras användarbegäranden till dessa vägar korrekt till TF-serverservern.
Det här exemplet baseras på TF Serving-fallet. Men du kan använda alla containrar som håller sig uppe och svarar på begäranden som går till liveness, beredskap och bedömningsvägar. Om du vill se hur du skapar en Dockerfile för att skapa en container kan du läsa andra exempel. Vissa servrar använder CMD instruktioner i stället för ENTRYPOINT instruktioner.
Parametern "inference_config"
I avsnittet environment eller Environment klassen inference_config är en parameter. Den anger porten och sökvägen för tre typer av rutter: livkraftsrutter, beredskapsrutter och bedömningsrutter. Parametern inference_config krävs om du vill köra en egen container med en hanterad onlineslutpunkt.
Beredskapsvägar jämfört med liveness-vägar
Vissa API-servrar är ett sätt att kontrollera serverns status. Det finns två typer av vägar som du kan ange för att kontrollera statusen:
- Liveness routes: To check whether a server is running, you use a liveness route.
- Readiness routes: To check whether a server is ready to do work, you use a readiness route.
När det gäller maskininlärningsinferens kan en server svara med statuskoden 200 OK på en liveness-begäran innan en modell läses in. Servern kan svara med statuskoden 200 OK på en beredskapsbegäran först när modellen har lästs in i minnet.
Mer information om live- och beredskapsavsökningar finns i Konfigurera liveness, beredskap och startavsökningar.
Den API-server som du väljer avgör tillgänglighets- och beredskapspunkterna. Du identifierar servern i ett tidigare steg när du testar containern lokalt. I den här artikeln används samma rutt för både liveness- och beredskapsvägarna i exempeldistributionen, eftersom TF Serving endast definierar en livenessväg. Andra sätt att definiera vägarna finns i andra exempel.
Scoring routes
Den API-server som du använder tillhandahåller ett sätt att ta emot databördan för att arbeta med. I samband med maskininlärningsinferens tar en server emot indata via en specifik väg. Identifiera den vägen för DIN API-server när du testar containern lokalt i ett tidigare steg. Ange den vägen som bedömningsväg när du definierar distributionen som ska skapas.
När distributionen har skapats uppdateras även parametern scoring_uri för slutpunkten. Du kan kontrollera detta genom att köra följande kommando: az ml online-endpoint show -n <endpoint-name> --query scoring_uri.
Lokalisera den monterade modellen
When you deploy a model as an online endpoint, Azure Machine Learning mounts your model to your endpoint. När modellen monteras kan du distribuera nya versioner av modellen utan att behöva skapa en ny Docker-avbildning. By default, a model registered with the name my-model and version 1 is located on the following path inside your deployed container: /var/azureml-app/azureml-models/my-model/1.
Tänk till exempel på följande konfiguration:
- En katalogstruktur på din lokala dator med /azureml-examples/cli/endpoints/online/custom-container
- Ett modellnamn för
half_plus_two
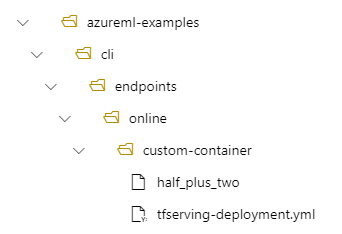
Anta att din tfserving-deployment.yml-fil innehåller följande rader i avsnittet model . I det här avsnittet name refererar värdet till det namn som du använder för att registrera modellen i Azure Machine Learning.
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
I det här fallet finns din modell under följande mapp när du skapar en distribution: /var/azureml-app/azureml-models/tfserving-mounted/1.
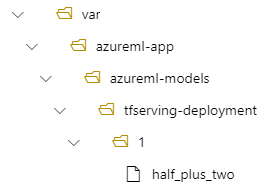
Du kan också konfigurera ditt model_mount_path värde. Genom att justera den här inställningen kan du ändra sökvägen där modellen monteras.
Important
Värdet model_mount_path måste vara en giltig absolut sökväg i Linux (i gästoperativsystemet för containeravbildningen).
Important
model_mount_path kan endast användas i BYOC-scenariot (Bring your own container). I BYOC-scenariot måste den miljö som onlinedistributionen använder ha inference_config parametern konfigurerad. Du kan använda Azure ML CLI eller Python SDK för att ange inference_config parametern när du skapar miljön. Studio-användargränssnittet stöder för närvarande inte att ange den här parametern.
När du ändrar värdet model_mount_pathför måste du också uppdatera MODEL_BASE_PATH miljövariabeln. Ange MODEL_BASE_PATH till samma värde som model_mount_path för att undvika en felaktig distribution med ett felmeddelande om att basvägen inte hittades.
Du kan till exempel lägga till parametern i model_mount_path din tfserving-deployment.yml-fil. Du kan också uppdatera MODEL_BASE_PATH värdet i filen:
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
model_mount_path: /var/tfserving-model-mount
environment_variables:
MODEL_BASE_PATH: /var/tfserving-model-mount
...
I distributionen finns din modell sedan på /var/tfserving-model-mount/tfserving-mounted/1. Den finns inte längre under azureml-app/azureml-models, utan under den monteringsväg som du anger.
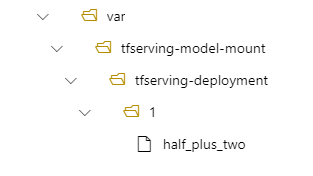
Skapa slutpunkten och distributionen
När du har skapat YAML-filen använder du följande kommando för att skapa slutpunkten:
az ml online-endpoint create --name tfserving-endpoint -f endpoints/online/custom-container/tfserving/half-plus-two/tfserving-endpoint.yml
Använd följande kommando för att skapa distributionen. Det här steget kan köras i några minuter.
az ml online-deployment create --name tfserving-deployment -f endpoints/online/custom-container/tfserving/half-plus-two/tfserving-deployment.yml --all-traffic
Anropa slutpunkten
När distributionen är klar gör du en bedömningsbegäran till den distribuerade slutpunkten.
RESPONSE=$(az ml online-endpoint invoke -n $ENDPOINT_NAME --request-file $BASE_PATH/sample_request.json)
Ta bort slutpunkten
Om du inte längre behöver slutpunkten kör du följande kommando för att ta bort den:
az ml online-endpoint delete --name tfserving-endpoint