Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
Azure CLI ml-tillägget v2 (aktuellt)
I den här artikeln ser du hur du distribuerar din MLflow-modell till en onlineslutpunkt för realtidsinferens. När du distribuerar MLflow-modellen till en onlineslutpunkt behöver du inte ange ett bedömningsskript eller en miljö – den här funktionen kallas ingen koddistribution.
Azure Machine Learning för distribution utan kod:
- Installerar Python-paket som du listar dynamiskt i en conda.yaml-fil. Därför installeras beroenden under containerkörningen.
- Tillhandahåller en MLflow-basavbildning eller en kuraterad miljö som innehåller följande objekt:
- Paketet
azureml-inference-server-http - Paketet
mlflow-skinny - Ett poängsättningsskript för inferens
- Paketet
Prerequisites
En Azure-prenumeration. Om du inte har en Azure-prenumeration, skapa ett gratis konto innan du börjar.
Ett användarkonto som har minst en av följande rollbaserade åtkomstkontrollroller i Azure (Azure RBAC):
- En ägarroll för Azure Machine Learning-arbetsytan
- En deltagarroll för Azure Machine Learning-arbetsytan
- En anpassad roll som har
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*behörigheter
Mer information finns i Hantera åtkomst till Azure Machine Learning-arbetsytor.
Åtkomst till Azure Machine Learning:
Installera Azure CLI och
mltillägget till Azure CLI. Installationssteg finns i Installera och konfigurera CLI (v2).
Om exemplet
Exemplet i den här artikeln visar hur du distribuerar en MLflow-modell till en onlineslutpunkt för att utföra förutsägelser. I exemplet används en MLflow-modell som baseras på datauppsättningen Diabetes. Denna datamängd innehåller 10 baslinjevariabler: ålder, kön, kroppsmasseindex, genomsnittligt blodtryck och 6 blodserummätningar från 442 diabetespatienter. Den innehåller också det svar vi är intresserade av, ett kvantitativt mått på sjukdomsprogression ett år efter datumet för baslinjedata.
Modellen tränades med hjälp av en scikit-learn regressor. All nödvändig förbearbetning är paketerad som en pipeline, så den här modellen är en helhetslösning som går från rådata till förutsägelser.
Informationen i den här artikeln baseras på kodexempel från lagringsplatsen azureml-examples . Om du klonar lagringsplatsen kan du köra kommandona i den här artikeln lokalt utan att behöva kopiera eller klistra in YAML-filer och andra filer. Använd följande kommandon för att klona lagringsplatsen och gå till mappen för ditt kodningsspråk:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
Följ med i Jupyter Notebook
Om du vill följa stegen i den här artikeln, läs Distribuera MLflow-modell till onlineslutpunkter notebook-filen i exempelsamlingen.
Anslut till din arbetsyta
Anslut till din Azure Machine Learning-arbetsyta:
az account set --subscription <subscription-ID>
az configure --defaults workspace=<workspace-name> group=<resource-group-name> location=<location>
Registrera modellen
Du kan bara distribuera registrerade modeller till onlineslutpunkter. Stegen i den här artikeln använder en modell som tränas för datauppsättningen Diabetes. I det här fallet har du redan en lokal kopia av modellen i den klonade lagringsplatsen, så du behöver bara publicera modellen i registret på arbetsytan. Du kan hoppa över det här steget om den modell som du vill distribuera redan är registrerad.
MODEL_NAME='sklearn-diabetes'
az ml model create --name $MODEL_NAME --type "mlflow_model" --path "endpoints/online/ncd/sklearn-diabetes/model"

Vad händer om din modell loggades under ett körningspass?
Om din modell loggades i en körning kan du registrera den direkt.
Om du vill registrera modellen måste du känna till dess lagringsplats:
- Om du använder MLflow-funktionen
autologberor sökvägen till modellen på modelltypen och ramverket. Kontrollera jobbutdata för att identifiera namnet på modellmappen. Den här mappen innehåller en fil med namnet MLModel. - Om du använder
log_modelmetoden för att manuellt logga dina modeller skickar du sökvägen till modellen som ett argument till den metoden. Om du till exempel användermlflow.sklearn.log_model(my_model, "classifier")för att logga modellenclassifierär den sökväg som modellen lagras på.
Du kan använda Azure Machine Learning CLI v2 för att skapa en modell från träningsjobbets utdata. Följande kod använder artefakterna för ett jobb med ID $RUN_ID för att registrera en modell med namnet $MODEL_NAME.
$MODEL_PATH är den sökväg som jobbet använder för att lagra modellen.
az ml model create --name $MODEL_NAME --path azureml://jobs/$RUN_ID/outputs/artifacts/$MODEL_PATH

Distribuera en MLflow-modell till en onlineslutpunkt
Använd följande kod för att konfigurera namn och autentiseringsläge för slutpunkten som du vill distribuera modellen till:
Ange ett slutpunktsnamn genom att köra följande kommando. Ersätt
YOUR_ENDPOINT_NAMEförst med ett unikt namn.export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"Om du vill konfigurera slutpunkten skapar du en YAML-fil med namnet create-endpoint.yaml som innehåller följande rader:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json name: my-endpoint auth_mode: keySkapa slutpunkten:
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/ncd/create-endpoint.yamlKonfigurera distributionen. En distribution är en uppsättning resurser som krävs för att vara värd för den modell som utför den faktiska inferensen.
Skapa en YAML-fil med namnet sklearn-deployment.yaml som innehåller följande rader:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json name: sklearn-deployment endpoint_name: my-endpoint model: name: mir-sample-sklearn-ncd-model version: 2 path: sklearn-diabetes/model type: mlflow_model instance_type: Standard_DS3_v2 instance_count: 1Note
Automatisk generering av
scoring_scriptochenvironmentstöds endast för modellsmakenPyFunc. Om du vill använda en annan modellsmak kan du läsa Anpassa MLflow-modelldistributioner.Skapa distributionen:
az ml online-deployment create --name sklearn-deployment --endpoint $ENDPOINT_NAME -f endpoints/online/ncd/sklearn-deployment.yaml --all-trafficaz ml online-deployment create --name sklearn-deployment --endpoint $ENDPOINT_NAME -f endpoints/online/ncd/sklearn-deployment.yaml --all-trafficTilldela all trafik till distribueringen. Än så länge har slutpunkten en distribution, men den har ingen tilldelad trafik.
Det här steget krävs inte i Azure CLI om du använder
--all-trafficflaggan när du skapar den. Om du behöver ändra trafiken kan du användaaz ml online-endpoint update --traffickommandot . Mer information om hur du uppdaterar trafik finns i Progressiv uppdatering av trafiken.Uppdatera slutpunktskonfigurationen:
Det här steget krävs inte i Azure CLI om du använder
--all-trafficflaggan när du skapar den. Om du behöver ändra trafik kan du använda kommandotaz ml online-endpoint update --traffic. Mer information om hur du uppdaterar trafik finns i Progressiv uppdatering av trafiken.


Anropa slutpunkten
När distributionen är klar kan du använda den för att hantera begäranden. Ett sätt att testa distributionen är att använda den inbyggda anropsfunktionen i distributionsklienten. I exempellagringsplatsen innehåller filen sample-request-sklearn.json följande JSON-kod. Du kan använda den som en exempelbegäransfil för distributionen.
{"input_data": {
"columns": [
"age",
"sex",
"bmi",
"bp",
"s1",
"s2",
"s3",
"s4",
"s5",
"s6"
],
"data": [
[ 1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0 ],
[ 10.0,2.0,9.0,8.0,7.0,6.0,5.0,4.0,3.0,2.0]
],
"index": [0,1]
}}
Note
Den här filen använder input_data nyckeln i stället för inputs, som MLflow-servering använder. Azure Machine Learning kräver ett annat indataformat för att automatiskt kunna generera Swagger-kontrakten för slutpunkterna. Mer information om förväntade indataformat finns i Distribution i den inbyggda MLflow-servern jämfört med distribution i Azure Machine Learning-inferensservern.
Skicka en begäran till slutpunkten:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/ncd/sample-request-sklearn.json
Svaret bör likna följande text:
[
11633.100167144921,
8522.117402884991
]
Important
För MLflow no-code-deployment stöds för närvarande inte testning via lokala slutpunkter .
Anpassa distributionen av MLflow-modeller
Du behöver inte ange ett bedömningsskript i distributionsdefinitionen för en MLflow-modell till en onlineslutpunkt. Men du kan ange ett bedömningsskript om du vill anpassa din slutsatsdragningsprocess.
Du vill vanligtvis anpassa MLflow-modelldistributionen i följande fall:
- Modellen har ingen
PyFunc-smak. - Du måste anpassa hur du kör modellen. Du måste till exempel använda
mlflow.<flavor>.load_model()för att använda en specifik variant för att ladda in modellen. - Du måste utföra förbearbetning eller efterbearbetning i din bedömningsrutin, eftersom modellen inte utför den här bearbetningen.
- Modellens utdata kan inte representeras på ett bra sätt i tabelldata. Till exempel är utdata en tensor som representerar en bild.
Important
Om du anger ett bedömningsskript för en MLflow-modelldistribution måste du också ange den miljö som distributionen körs i.
Distribuera ett anpassat bedömningsskript
Utför stegen i följande avsnitt för att distribuera en MLflow-modell som använder ett anpassat bedömningsskript.
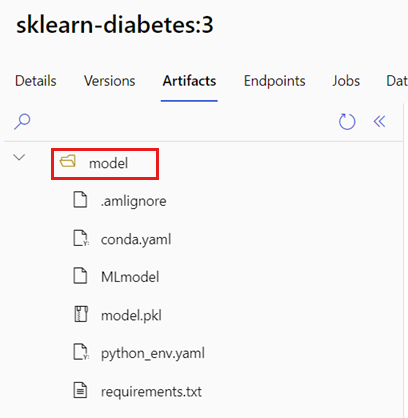
Identifiera modellmappen
Identifiera mappen som innehåller din MLflow-modell genom att utföra följande steg:
Gå till Azure Machine Learning-studio.
Gå till avsnittet Modeller .
Välj den modell som du vill distribuera och gå till fliken Artefakter .
Anteckna mappen som visas. När du registrerar en modell anger du den här mappen.

Skapa ett bedömningsskript
Följande bedömningsskript, score.py, innehåller ett exempel på hur du utför slutsatsdragning med en MLflow-modell. Du kan anpassa det här skriptet efter dina behov eller ändra någon av dess delar så att det återspeglar ditt scenario. Observera att mappnamnet som du tidigare identifierade, model, ingår i init() funktionen.
import logging
import os
import json
import mlflow
from io import StringIO
from mlflow.pyfunc.scoring_server import infer_and_parse_json_input, predictions_to_json
def init():
global model
global input_schema
# "model" is the path of the mlflow artifacts when the model was registered. For automl
# models, this is generally "mlflow-model".
model_path = os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model")
model = mlflow.pyfunc.load_model(model_path)
input_schema = model.metadata.get_input_schema()
def run(raw_data):
json_data = json.loads(raw_data)
if "input_data" not in json_data.keys():
raise Exception("Request must contain a top level key named 'input_data'")
serving_input = json.dumps(json_data["input_data"])
data = infer_and_parse_json_input(serving_input, input_schema)
predictions = model.predict(data)
result = StringIO()
predictions_to_json(predictions, result)
return result.getvalue()
Warning
MLflow 2.0-rådgivning: Exempelbedömningsskriptet fungerar med MLflow 1.X och MLflow 2.X. De förväntade in- och utdataformaten för dessa versioner kan dock variera. Kontrollera din miljödefinition för att se vilken MLflow-version du använder. MLflow 2.0 stöds endast i Python 3.8 och senare versioner.
Skapa en miljö
Nästa steg är att skapa en miljö som du kan köra bedömningsskriptet i. Eftersom modellen är en MLflow-modell anges även conda-kraven i modellpaketet. Mer information om de filer som ingår i en MLflow-modell finns i MLmodel-formatet. Du skapar miljön med hjälp av conda-beroendena från filen. Du måste dock även inkludera azureml-inference-server-http paketet, som krävs för onlinedistributioner i Azure Machine Learning.
Du kan skapa en conda-definitionsfil med namnet conda.yaml som innehåller följande rader:
channels:
- conda-forge
dependencies:
- python=3.12
- pip
- pip:
- mlflow
- scikit-learn==1.7.0
- cloudpickle==3.1.1
- psutil==7.0.0
- pandas==2.3.0
- azureml-inference-server-http
name: mlflow-env
Note
Avsnittet dependencies i den här conda-filen innehåller azureml-inference-server-http paketet.
Använd den här conda-beroendefilen för att skapa miljön:
Miljön skapas direkt i distributionskonfigurationen.
Skapa distributionen
I mappen endpoints/online/ncd skapar du en distributionskonfigurationsfil, deployment.yml, som innehåller följande rader:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: sklearn-diabetes-custom
endpoint_name: my-endpoint
model: azureml:sklearn-diabetes@latest
environment:
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04
conda_file: sklearn-diabetes/environment/conda.yaml
code_configuration:
code: sklearn-diabetes/src
scoring_script: score.py
instance_type: Standard_F2s_v2
instance_count: 1
Skapa distributionen:
az ml online-deployment create -f endpoints/online/ncd/deployment.yml


Hantera begäranden
När distributionen är klar är den redo att hantera begäranden. Ett sätt att testa distributionen är att använda invoke metoden med en exempelbegäransfil, till exempel följande fil, sample-request-sklearn.json:
{"input_data": {
"columns": [
"age",
"sex",
"bmi",
"bp",
"s1",
"s2",
"s3",
"s4",
"s5",
"s6"
],
"data": [
[ 1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0 ],
[ 10.0,2.0,9.0,8.0,7.0,6.0,5.0,4.0,3.0,2.0]
],
"index": [0,1]
}}
Skicka en begäran till slutpunkten:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/ncd/sample-request-sklearn.json
Svaret bör likna följande text:
{
"predictions": [
1095.2797413413252,
1134.585328803727
]
}
Warning
MLflow 2.0-rekommendation: I MLflow 1.X innehåller predictions svaret inte nyckeln.
Rensa resurser
Om du inte längre behöver slutpunkten tar du bort dess associerade resurser:
az ml online-endpoint delete --name $ENDPOINT_NAME --yes