Slutpunkter för slutsatsdragning i produktion
GÄLLER FÖR: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
När du har tränat maskininlärningsmodeller eller pipelines, eller om du har hittat modeller från modellkatalogen som passar dina behov, måste du distribuera dem till produktion så att andra kan använda dem för slutsatsdragning. Slutsatsdragning är processen att tillämpa nya indata på en maskininlärningsmodell eller pipeline för att generera utdata. Även om dessa utdata vanligtvis kallas "förutsägelser" kan slutsatsdragning användas för att generera utdata för andra maskininlärningsuppgifter, till exempel klassificering och klustring. I Azure Mašinsko učenje utför du slutsatsdragning med hjälp av slutpunkter.
Slutpunkter och distributioner
En slutpunkt är en stabil och varaktig URL som kan användas för att begära eller anropa en modell. Du anger nödvändiga indata till slutpunkten och får tillbaka utdata. Med Azure Mašinsko učenje kan du implementera serverlösa API-slutpunkter, onlineslutpunkter och batchslutpunkter. En slutpunkt innehåller:
- en stabil och hållbar URL (till exempel endpoint-name.region.inference.ml.azure.com),
- en autentiseringsmekanism och
- en auktoriseringsmekanism.
En distribution är en uppsättning resurser och beräkningar som krävs för att vara värd för modellen eller komponenten som utför den faktiska inferensen. En slutpunkt innehåller en distribution och för online- och batchslutpunkter kan en slutpunkt innehålla flera distributioner. Distributionerna kan vara värdar för oberoende tillgångar och använda olika resurser baserat på tillgångarnas behov. Dessutom har en slutpunkt en routningsmekanism som kan dirigera begäranden till någon av dess distributioner.
Å ena sidan Mašinsko učenje vissa typer av slutpunkter i Azure använda dedikerade resurser i sina distributioner. För att dessa slutpunkter ska kunna köras måste du ha beräkningskvot för din Azure-prenumeration. Å andra sidan stöder vissa modeller en serverlös distribution, vilket gör att de inte kan använda någon kvot från din prenumeration. För serverlös distribution debiteras du baserat på användning.
Intuition
Anta att du arbetar med ett program som förutsäger typen och färgen på en bil, med tanke på dess foto. För det här programmet gör en användare med vissa autentiseringsuppgifter en HTTP-begäran till en URL och ger en bild av en bil som en del av begäran. I gengäld får användaren ett svar som innehåller bilens typ och färg som strängvärden. I det här scenariot fungerar URL:en som en slutpunkt.
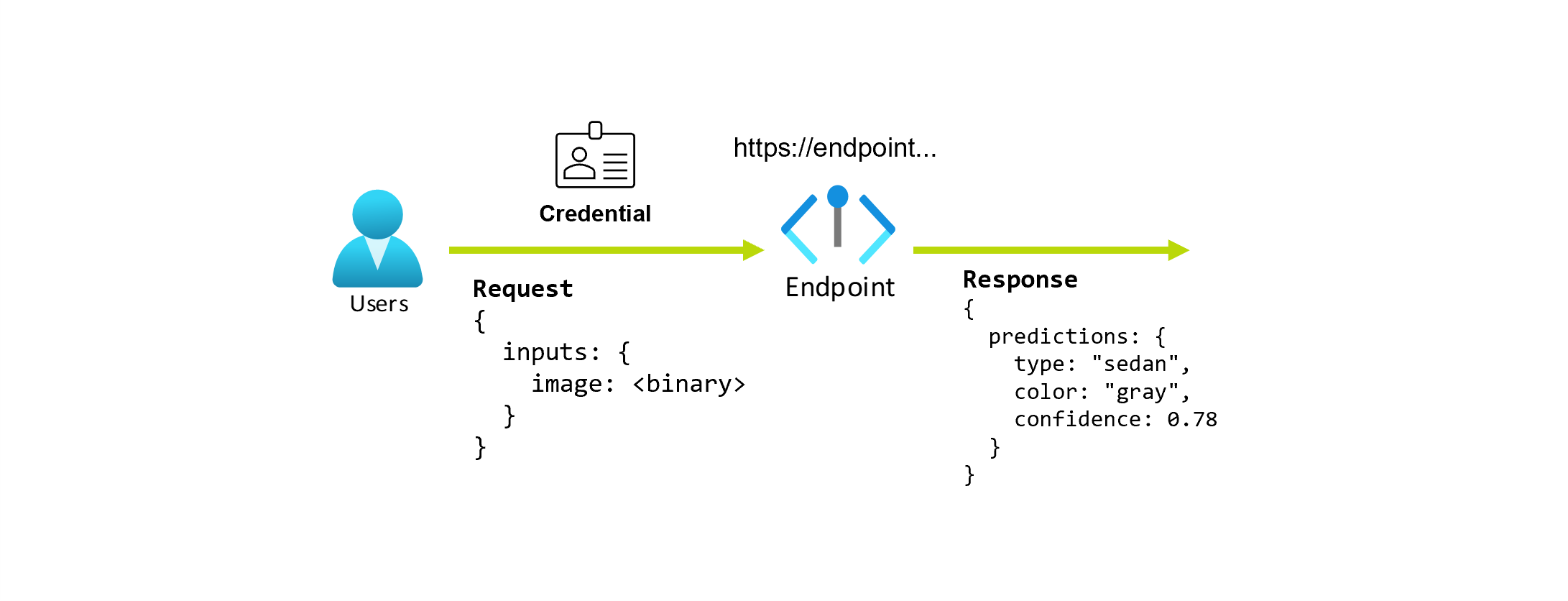
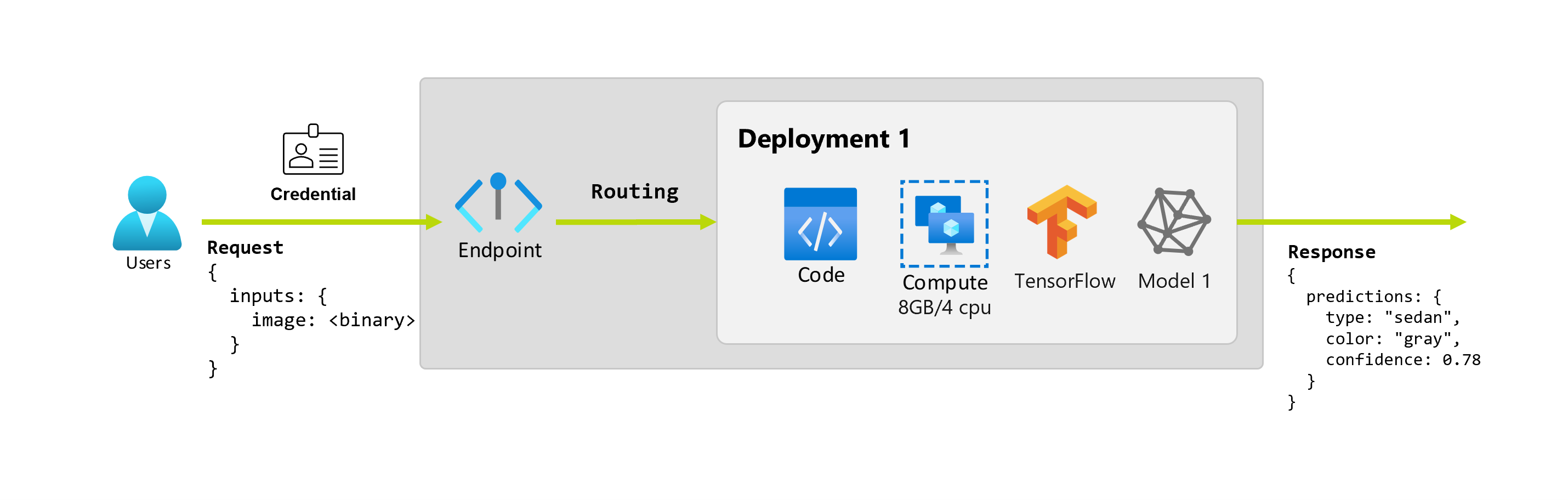
Anta dessutom att en dataexpert, Alice, arbetar med att implementera programmet. Alice vet mycket om TensorFlow och bestämmer sig för att implementera modellen med hjälp av en sekventiell Keras-klassificerare med en RestNet-arkitektur från TensorFlow Hub. Efter att ha testat modellen är Alice nöjd med sina resultat och bestämmer sig för att använda modellen för att lösa problemet med bilförutsägelse. Modellen är stor och kräver 8 GB minne med 4 kärnor att köra. I det här scenariot utgör Alices modell och resurserna, till exempel koden och beräkningen, som krävs för att köra modellen en distribution under slutpunkten.
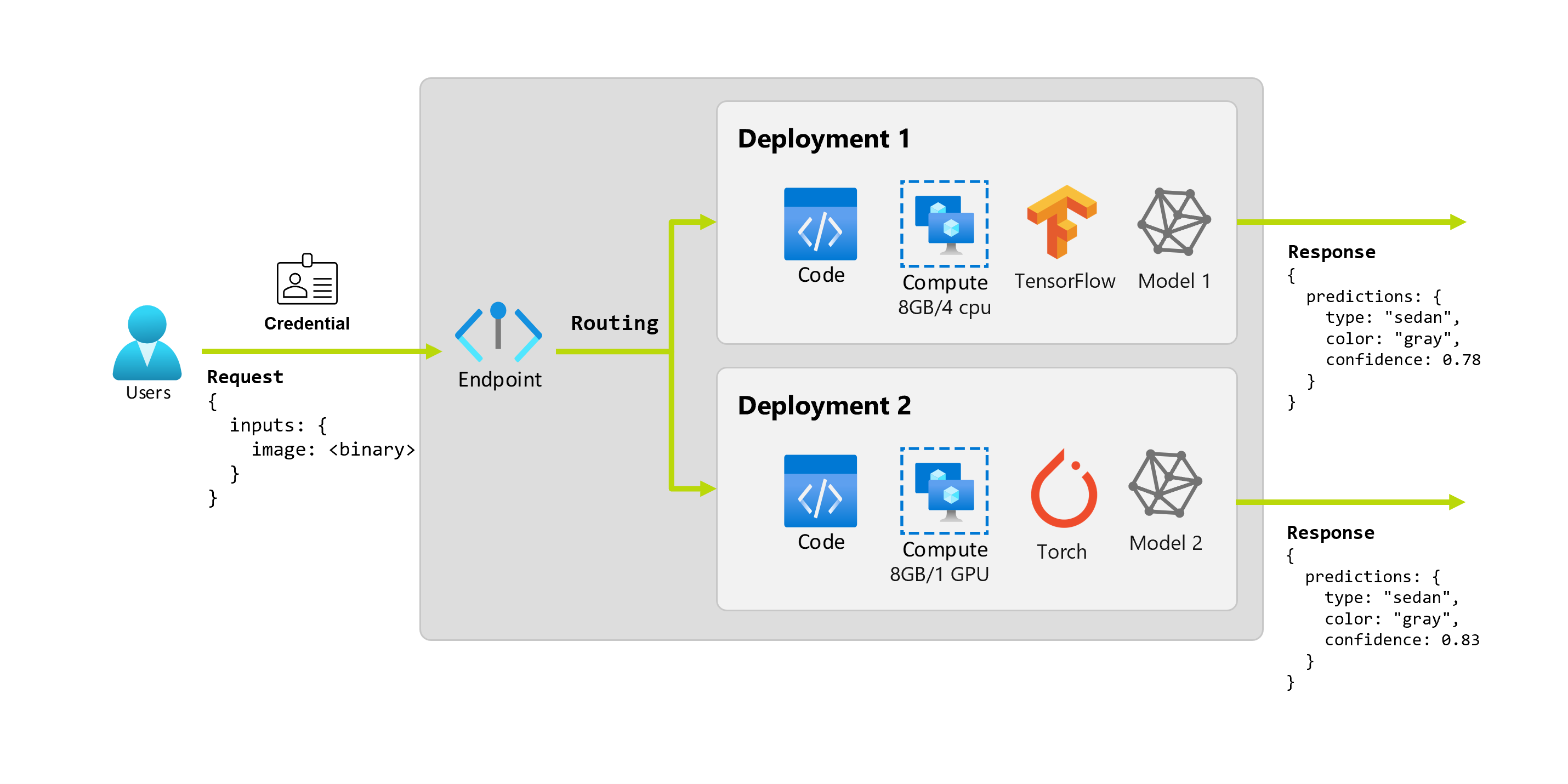
Anta att organisationen efter ett par månader upptäcker att programmet presterar dåligt på bilder med mindre än idealiska belysningsförhållanden. Bob, en annan dataexpert, vet mycket om dataförstoringstekniker som hjälper en modell att bygga robusthet på den faktorn. Bob känner sig dock mer bekväm med torch för att implementera modellen och träna en ny modell med Torch. Bob vill prova den här modellen i produktion gradvis tills organisationen är redo att dra tillbaka den gamla modellen. Den nya modellen visar också bättre prestanda när den distribueras till GPU, så distributionen måste innehålla en GPU. I det här scenariot utgör Bobs modell och resurser, till exempel koden och beräkningen, som krävs för att köra modellen en annan distribution under samma slutpunkt.
Slutpunkter: serverlöst API, online och batch
Med Azure Mašinsko učenje kan du implementera serverlösa API-slutpunkter, onlineslutpunkter och batchslutpunkter.
Serverlösa API-slutpunkter och onlineslutpunkter är utformade för slutsatsdragning i realtid. När du anropar slutpunkten returneras resultaten i slutpunktens svar. Serverlösa API-slutpunkter förbrukar inte kvoter från din prenumeration. I stället debiteras de med betala per användning-fakturering.
Batchslutpunkter är utformade för långvarig batchinferens. När du anropar en batchslutpunkt genererar du ett batchjobb som utför det faktiska arbetet.
När du ska använda serverlöst API, online och batchslutpunkter
Serverlösa API-slutpunkter:
Använd serverlösa API-slutpunkter för att använda stora grundläggande modeller för slutsatsdragning i realtid utanför hyllan eller för finjustering av sådana modeller. Alla modeller är inte tillgängliga för distribution till serverlösa API-slutpunkter. Vi rekommenderar att du använder det här distributionsläget när:
- Din modell är en grundläggande modell eller en finjusterad version av en grundläggande modell som är tillgänglig för serverlösa API-distributioner.
- Du kan dra nytta av en distribution utan kvot.
- Du behöver inte anpassa den slutsatsdragningsstack som används för att köra modellen.
Onlineslutpunkter:
Använd onlineslutpunkter för att operationalisera modeller för realtidsinferens i synkrona begäranden med låg svarstid. Vi rekommenderar att du använder dem när:
- Din modell är en grundläggande modell eller en finjusterad version av en grundläggande modell, men den stöds inte i serverlösa API-slutpunkter.
- Du har krav på låg latens.
- Din modell kan besvara begäran på relativt kort tid.
- Modellens indata får plats på HTTP-nyttolasten för begäran.
- Du måste skala upp när det gäller antalet begäranden.
Batch-slutpunkter:
Använd batchslutpunkter för att operationalisera modeller eller pipelines för långvarig asynkron slutsatsdragning. Vi rekommenderar att du använder dem när:
- Du har dyra modeller eller pipelines som kräver längre tid att köra.
- Du vill operationalisera maskininlärningspipelines och återanvända komponenter.
- Du måste utföra slutsatsdragning för stora mängder data som distribueras i flera filer.
- Du har inte krav på låg svarstid.
- Modellens indata lagras i ett lagringskonto eller i en Azure-Mašinsko učenje datatillgång.
- Du kan dra nytta av parallellisering.
Jämförelse av serverlösa API-, online- och batchslutpunkter
Alla serverlösa API:er, online- och batchslutpunkter baseras på idén om slutpunkter. Därför kan du enkelt övergå från en till en annan. Online- och batchslutpunkter kan också hantera flera distributioner för samma slutpunkt.
Slutpunkter
I följande tabell visas en sammanfattning av de olika funktioner som är tillgängliga för serverlösa API-, online- och batchslutpunkter på slutpunktsnivå.
| Funktion | Serverlösa API-slutpunkter | Onlineslutpunkter | Batch-slutpunkter |
|---|---|---|---|
| Stabil anrops-URL | Ja | Ja | Ja |
| Stöd för flera distributioner | Nej | Ja | Ja |
| Distributionens routning | Ingen | Trafikdelning | Växla till standard |
| Speglingstrafik för säker distribution | Nej | Ja | Nej |
| Swagger-stöd | Ja | Ja | Nej |
| Autentisering | Nyckel | Key och Microsoft Entra ID (förhandsversion) | Microsoft Entra ID |
| Stöd för privat nätverk (äldre) | Nej | Ja | Ja |
| Hanterad nätverksisolering | Ja | Ja | Ja (se nödvändig ytterligare konfiguration) |
| Kundhanterade nycklar | Saknas | Ja | Ja |
| Kostnadsbas | Per slutpunkt, per minut1 | Ingen | Ingen |
1En liten fraktion debiteras för serverlösa API-slutpunkter per minut. Se avsnittet distributioner för de avgifter som är relaterade till förbrukning, som faktureras per token.
Distributioner
I följande tabell visas en sammanfattning av de olika funktioner som är tillgängliga för serverlösa API-, online- och batchslutpunkter på distributionsnivå. De här begreppen gäller för varje distribution under slutpunkten (för online- och batchslutpunkter) och gäller för serverlösa API-slutpunkter (där distributionsbegreppet är inbyggt i slutpunkten).
| Funktion | Serverlösa API-slutpunkter | Onlineslutpunkter | Batch-slutpunkter |
|---|---|---|---|
| Distributionstyper | Modeller | Modeller | Modeller och pipelinekomponenter |
| MLflow-modelldistribution | Nej, endast specifika modeller i katalogen | Ja | Ja |
| Distribution av anpassad modell | Nej, endast specifika modeller i katalogen | Ja, med bedömningsskript | Ja, med bedömningsskript |
| Distribution av modellpaket 2 | Inbyggd | Ja (förhandsversion) | Nej |
| Slutsatsdragningsserver 3 | API:et för Azure AI-modellslutsatsdragning | – Azure Mašinsko učenje Inferencing Server -Triton – Anpassad (med BYOC) |
Batch-slutsatsdragning |
| Förbrukad beräkningsresurs | Ingen (serverlös) | Instanser eller detaljerade resurser | Klusterinstanser |
| Typ av beräkning | Ingen (serverlös) | Hanterad beräkning och Kubernetes | Hanterad beräkning och Kubernetes |
| Beräkning med låg prioritet | NA | Nej | Ja |
| Skala beräkning till noll | Inbyggd | Nej | Ja |
| Beräkning av automatisk skalning4 | Inbyggd | Ja, baserat på resursanvändning | Ja, baserat på antal jobb |
| Hantering av överkapacitet | Begränsning | Begränsning | Queuing |
| Kostnadsbas5 | Per token | Per distribution: beräkningsinstanser som körs | Per jobb: beräkningsinstanser som förbrukas i jobbet (begränsas till det maximala antalet instanser av klustret) |
| Lokal testning av distributioner | Nej | Ja | Nej |
2 Distribution av MLflow-modeller till slutpunkter utan utgående internetanslutning eller privata nätverk kräver att modellen först paketeras.
3 Slutsatsdragningsservern refererar till den serveringsteknik som tar begäranden, bearbetar dem och skapar svar. Slutsatsdragningsservern avgör också formatet på indata och förväntade utdata.
4 Autoskalning är möjligheten att dynamiskt skala upp eller skala ned distributionens allokerade resurser baserat på belastningen. Online- och batchdistributioner använder olika strategier för automatisk skalning. Medan onlinedistributioner skalas upp och ned baserat på resursanvändningen (t.ex. PROCESSOR, minne, begäranden osv.), skalas batchslutpunkter upp eller ned baserat på antalet jobb som skapats.
5 Både online- och batchdistributioner debiteras av de resurser som förbrukas. I onlinedistributioner etableras resurser vid distributionstillfället. I batchdistributionen förbrukas inte resurser vid distributionstillfället, men vid den tidpunkt då jobbet körs. Därför finns det ingen kostnad som är associerad med själva batchdistributionen. På samma sätt förbrukar inte köade jobb resurser heller.
Utvecklargränssnitt
Slutpunkter är utformade för att hjälpa organisationer att operationalisera arbetsbelastningar på produktionsnivå i Azure Mašinsko učenje. Slutpunkter är robusta och skalbara resurser och de ger de bästa funktionerna för att implementera MLOps-arbetsflöden.
Du kan skapa och hantera batch- och onlineslutpunkter med flera utvecklarverktyg:
- Azure CLI och Python SDK
- Azure Resource Manager/REST API
- Azure Mašinsko učenje Studio-webbportalen
- Azure-portalen (IT/administratör)
- Stöd för CI/CD MLOps-pipelines med hjälp av Azure CLI-gränssnittet och REST/ARM-gränssnitt