Köra batchslutpunkter från Azure Data Factory
GÄLLER FÖR: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Stordata kräver en tjänst som kan samordna och operationalisera processer för att förfina dessa enorma lager av rådata till användbara affärsinsikter. Den hanterade Molntjänsten i Azure Data Factory hanterar dessa komplexa hybridprojekt för ETL (extract-transform-load), extraheringsbelastningstransformering (ELT) och dataintegreringsprojekt.
Med Azure Data Factory kan du skapa pipelines som kan samordna flera datatransformeringar och hantera dem som en enda enhet. Batchslutpunkter är en utmärkt kandidat för att bli ett steg i ett sådant bearbetningsarbetsflöde.
I den här artikeln får du lära dig hur du använder batchslutpunkter i Azure Data Factory-aktiviteter genom att förlita dig på webbanropsaktiviteten och REST-API:et.
Dricks
När du använder datapipelines i Fabric kan du anropa batchslutpunkten direkt med hjälp av Azure Mašinsko učenje-aktiviteten. Vi rekommenderar att du använder Infrastruktur för dataorkestrering när det är möjligt för att dra nytta av de senaste funktionerna. Azure Mašinsko učenje-aktiviteten i Azure Data Factory kan bara fungera med tillgångar från Azure Mašinsko učenje V1. Mer information finns i Köra Azure Mašinsko učenje-modeller från Fabric med batchslutpunkter (förhandsversion).
Förutsättningar
En modell som distribueras som en batchslutpunkt. Använd hjärttillståndsklassificeraren som skapats i Använda MLflow-modeller i batchdistributioner.
En Azure Data Factory-resurs. Om du vill skapa en datafabrik följer du stegen i Snabbstart: Skapa en datafabrik med hjälp av Azure-portalen.
När du har skapat datafabriken bläddrar du till den i Azure-portalen och väljer Starta studio:


Autentisera mot batchslutpunkter
Azure Data Factory kan anropa REST-API:er för batchslutpunkter med hjälp av aktiviteten Webbanrop . Batch-slutpunkter stöder Microsoft Entra-ID för auktorisering och begäran till API:erna kräver en korrekt autentiseringshantering. Mer information finns i Webbaktivitet i Azure Data Factory och Azure Synapse Analytics.
Du kan använda tjänstens huvudnamn eller en hanterad identitet för att autentisera mot batchslutpunkter. Vi rekommenderar att du använder en hanterad identitet eftersom det förenklar användningen av hemligheter.
Du kan använda Azure Data Factory-hanterad identitet för att kommunicera med batchslutpunkter. I det här fallet behöver du bara se till att din Azure Data Factory-resurs har distribuerats med en hanterad identitet.
Om du inte har någon Azure Data Factory-resurs eller om den redan har distribuerats utan en hanterad identitet följer du den här proceduren för att skapa den: Systemtilldelad hanterad identitet.
Varning
Det går inte att ändra resursidentiteten i Azure Data Factory efter distributionen. Om du behöver ändra identiteten för en resurs när du har skapat den måste du återskapa resursen.
Efter distributionen beviljar du åtkomst för den hanterade identiteten för den resurs som du skapade till din Azure Mašinsko učenje-arbetsyta. Se Bevilja åtkomst. I det här exemplet kräver tjänstens huvudnamn:
- Behörighet på arbetsytan att läsa batchdistributioner och utföra åtgärder över dem.
- Behörighet att läsa/skriva i datalager.
- Behörigheter att läsa på valfri molnplats (lagringskonto) som anges som indata.
Om pipelinen
I det här exemplet skapar du en pipeline i Azure Data Factory som kan anropa en viss batchslutpunkt över vissa data. Pipelinen kommunicerar med Azure Mašinsko učenje batchslutpunkter med hjälp av REST. Mer information om hur du använder REST-API:et för batchslutpunkter finns i Skapa jobb och indata för batchslutpunkter.
Pipelinen ser ut så här:

Pipelinen innehåller följande aktiviteter:
Kör Batch-Endpoint: En webbaktivitet som använder batchslutpunkts-URI:n för att anropa den. Den skickar indata-URI:n där data finns och den förväntade utdatafilen.
Vänta på jobbet: Det är en loopaktivitet som kontrollerar statusen för det skapade jobbet och väntar på att det ska slutföras, antingen som Slutfört eller Misslyckat. Den här aktiviteten använder i sin tur följande aktiviteter:
- Kontrollera status: En webbaktivitet som frågar efter statusen för jobbresursen som returnerades som ett svar på aktiviteten Kör Batch-slutpunkt .
- Vänta: En vänteaktivitet som styr avsökningsfrekvensen för jobbets status. Vi anger ett standardvärde på 120 (2 minuter).
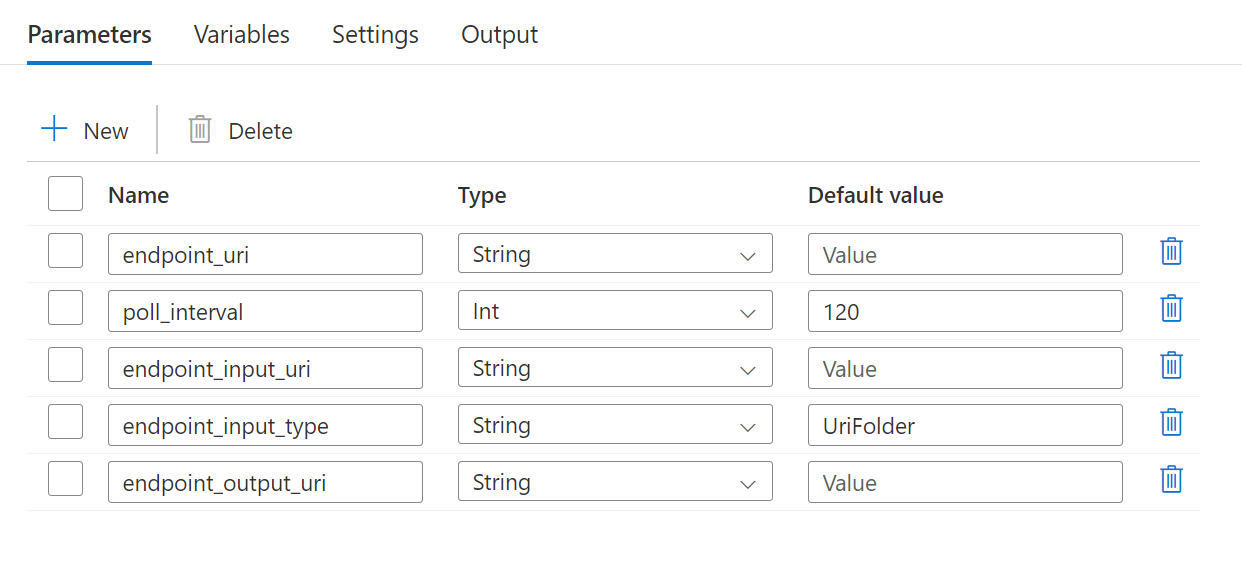
Pipelinen kräver att du konfigurerar följande parametrar:
| Parameter | Description | Exempelvärde |
|---|---|---|
endpoint_uri |
Slutpunktsbedömnings-URI | https://<endpoint_name>.<region>.inference.ml.azure.com/jobs |
poll_interval |
Antalet sekunder att vänta innan du kontrollerar jobbstatusen för slutförande. Standardvärdet är 120. |
120 |
endpoint_input_uri |
Slutpunktens indata. Flera typer av dataindata stöds. Kontrollera att den hanterade identitet som du använder för att köra jobbet har åtkomst till den underliggande platsen. Om du använder datalager kan du också se till att autentiseringsuppgifterna anges där. | azureml://datastores/.../paths/.../data/ |
endpoint_input_type |
Typen av indata som du anger. Batch-slutpunkter stöder för närvarande mappar (UriFolder) och Fil (UriFile). Standardvärdet är UriFolder. |
UriFolder |
endpoint_output_uri |
Slutpunktens utdatafil. Det måste vara en sökväg till en utdatafil i ett datalager som är kopplat till Mašinsko učenje arbetsytan. Ingen annan typ av URI:er stöds. Du kan använda standarddatalagret för Azure Mašinsko učenje med namnet workspaceblobstore. |
azureml://datastores/workspaceblobstore/paths/batch/predictions.csv |

Varning
Kom ihåg att endpoint_output_uri bör vara sökvägen till en fil som inte finns ännu. Annars misslyckas jobbet med felet att sökvägen redan finns.
Skapa pipelinen
Följ dessa steg för att skapa den här pipelinen i din befintliga Azure Data Factory och anropa batchslutpunkter:
Se till att den beräkning där batchslutpunkten körs har behörighet att montera de data som Azure Data Factory tillhandahåller som indata. Entiteten som anropar slutpunkten ger fortfarande åtkomst.
I det här fallet är det Azure Data Factory. Den beräkning där batchslutpunkten körs måste dock ha behörighet att montera lagringskontot som Azure Data Factory tillhandahåller. Mer information finns i Åtkomst till lagringstjänster .
Öppna Azure Data Factory Studio. Välj pennikonen för att öppna fönstret Författare och under Fabriksresurser väljer du plustecknet.
Välj Pipelineimport>från pipelinemall.
Välj en .zip fil.
- Om du vill använda hanterade identiteter väljer du den här filen.
- Välj den här filen om du vill använda en tjänstprincip.
En förhandsgranskning av pipelinen visas i portalen. Välj Använd denna mall.
Pipelinen skapas åt dig med namnet Run-BatchEndpoint.
Konfigurera parametrarna för batchdistributionen:
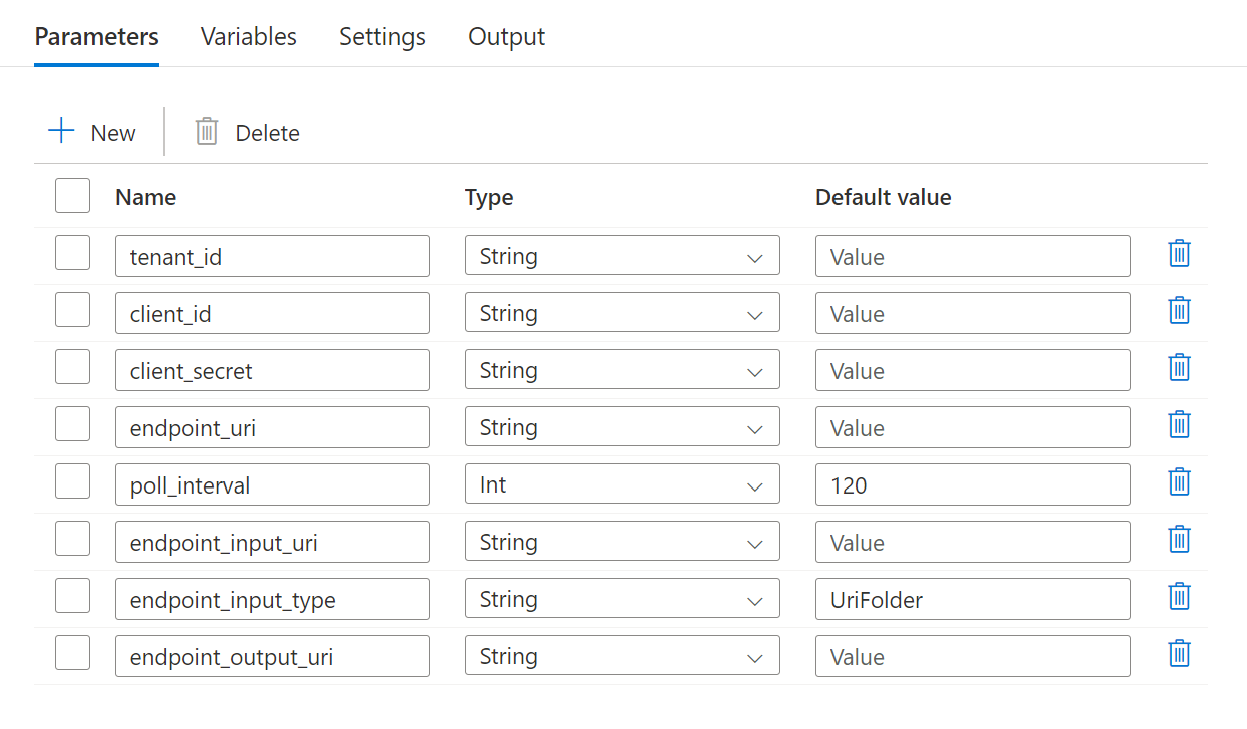
Varning
Kontrollera att batchslutpunkten har en standarddistribution konfigurerad innan du skickar ett jobb till den. Den skapade pipelinen anropar slutpunkten. En standarddistribution måste skapas och konfigureras.
Dricks
För bästa återanvändning använder du den skapade pipelinen som en mall och anropar den inifrån andra Azure Data Factory-pipelines med hjälp av aktiviteten Kör pipeline. I så fall ska du inte konfigurera parametrarna i den inre pipelinen utan skicka dem som parametrar från den yttre pipelinen enligt följande bild:
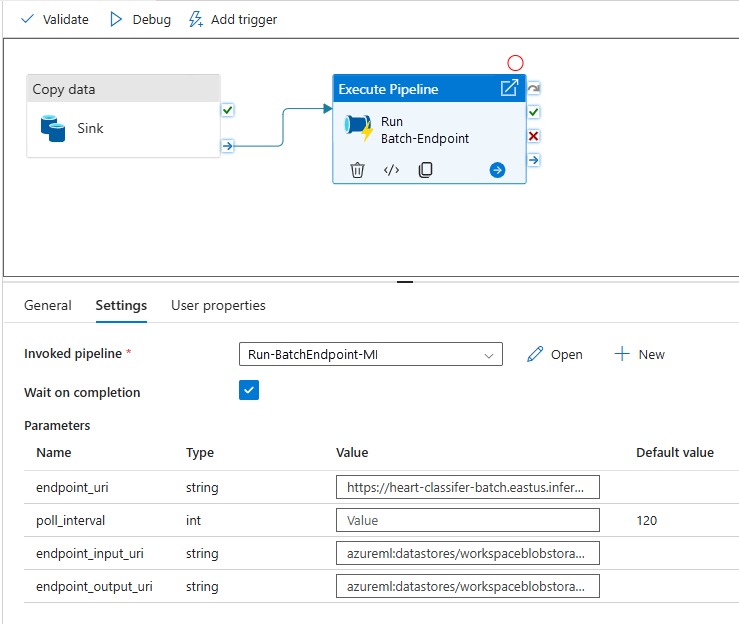
Din pipeline är redo att användas.
Begränsningar
Tänk på följande begränsningar när du använder Azure Mašinsko učenje batchdistributioner:
Dataindata
- Endast Azure Mašinsko učenje datalager eller Azure Storage-konton (Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2) stöds som indata. Om dina indata finns i en annan källa använder du Azure Data Factory-kopieringsaktiviteten innan batchjobbet körs för att skicka data till ett kompatibelt lager.
- Batch-slutpunktsjobb utforskar inte kapslade mappar. De kan inte fungera med kapslade mappstrukturer. Om dina data distribueras i flera mappar måste du platta ut strukturen.
- Kontrollera att ditt bedömningsskript som tillhandahålls i distributionen kan hantera data eftersom de förväntas matas in i jobbet. Om modellen är MLflow, för begränsningarna för filtyper som stöds, se Distribuera MLflow-modeller i batchdistributioner.
Datautdata
- Endast registrerade Azure Mašinsko učenje-datalager stöds. Vi rekommenderar att du registrerar lagringskontot som Azure Data Factory använder som ett datalager i Azure Mašinsko učenje. På så sätt kan du skriva tillbaka till samma lagringskonto som du läser.
- Endast Azure Blob Storage-konton stöds för utdata. Azure Data Lake Storage Gen2 stöds till exempel inte som utdata i batchdistributionsjobb. Om du behöver mata ut data till en annan plats eller mottagare använder du Azure Data Factory Copy-aktiviteten när du har kört batchjobbet.