Spåra ML-experiment i Azure Synapse Analytics med MLflow och Azure Mašinsko učenje
I den här artikeln får du lära dig hur du aktiverar MLflow för att ansluta till Azure Mašinsko učenje när du arbetar på en Azure Synapse Analytics-arbetsyta. Du kan använda den här konfigurationen för spårning, modellhantering och modelldistribution.
MLflow är ett bibliotek med öppen källkod för att hantera livscykeln för dina maskininlärningsexperiment. MLFlow Tracking är en komponent i MLflow som loggar och spårar dina träningskörningsmått och modellartefakter. Läs mer om MLflow.
Om du har ett MLflow-projekt att träna med Azure Mašinsko učenje läser du Träna ML-modeller med MLflow Projects och Azure Mašinsko učenje (förhandsversion).
Förutsättningar
Installera bibliotek
Så här installerar du bibliotek i ditt dedikerade kluster i Azure Synapse Analytics:
Skapa en
requirements.txtfil med de paket som experimenten kräver, men se till att den även innehåller följande paket:requirements.txt
mlflow azureml-mlflow azure-ai-mlGå till Azure Analytics-arbetsyteportalen.
Gå till fliken Hantera och välj Apache Spark-pooler.
Klicka på de tre punkterna bredvid klusternamnet och välj Paket.
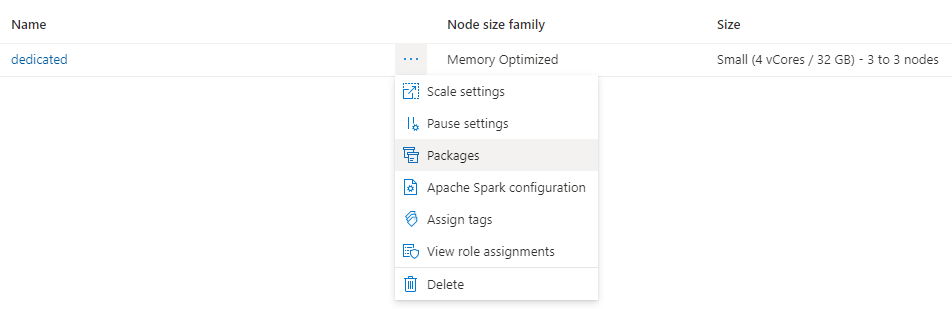
I avsnittet Kravfiler klickar du på Ladda upp.
Ladda upp
requirements.txt-filen.Vänta tills klustret startas om.
Spåra experiment med MLflow
Azure Synapse Analytics kan konfigureras för att spåra experiment med MLflow till Azure Mašinsko učenje arbetsyta. Azure Mašinsko učenje tillhandahåller en central lagringsplats för att hantera hela livscykeln för experiment, modeller och distributioner. Det har också fördelen att aktivera enklare sökväg till distribution med hjälp av Azure Mašinsko učenje distributionsalternativ.
Konfigurera dina notebook-filer så att de använder MLflow som är anslutet till Azure Mašinsko učenje
Om du vill använda Azure Mašinsko učenje som centraliserad lagringsplats för experiment kan du använda MLflow. I varje notebook-fil där du arbetar med måste du konfigurera spårnings-URI:n så att den pekar på den arbetsyta som du ska använda. I följande exempel visas hur det kan göras:
Konfigurera spårnings-URI
Hämta spårnings-URI:n för din arbetsyta:
GÄLLER FÖR:
 Azure CLI ml-tillägget v2 (aktuellt)
Azure CLI ml-tillägget v2 (aktuellt)Logga in och konfigurera din arbetsyta:
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>Du kan hämta spårnings-URI:n med kommandot
az ml workspace:az ml workspace show --query mlflow_tracking_uri
Konfigurera spårnings-URI:n:
Sedan pekar metoden
set_tracking_uri()MLflow-spårnings-URI:n till den URI:n.import mlflow mlflow.set_tracking_uri(mlflow_tracking_uri)Dricks
När du arbetar med delade miljöer, till exempel ett Azure Databricks-kluster, Azure Synapse Analytics-kluster eller liknande, är det användbart att ange miljövariabeln
MLFLOW_TRACKING_URIpå klusternivå för att automatiskt konfigurera MLflow-spårnings-URI:n så att den pekar på Azure Mašinsko učenje för alla sessioner som körs i klustret i stället för att göra det per session.
Konfigurera autentisering
När spårningen har konfigurerats måste du också konfigurera hur autentiseringen ska ske på den associerade arbetsytan. Som standard utför Azure Mašinsko učenje plugin-programmet för MLflow interaktiv autentisering genom att öppna standardwebbläsaren för att fråga efter autentiseringsuppgifter. Se Konfigurera MLflow för Azure Mašinsko učenje: Konfigurera autentisering på ytterligare sätt för att konfigurera autentisering för MLflow i Azure Mašinsko učenje arbetsytor.
För interaktiva jobb där en användare är ansluten till sessionen kan du förlita dig på interaktiv autentisering och därför krävs ingen ytterligare åtgärd.
Varning
Interaktiv webbläsarautentisering blockerar kodkörning när den frågar efter autentiseringsuppgifter. Den här metoden är inte lämplig för autentisering i obevakade miljöer som träningsjobb. Vi rekommenderar att du konfigurerar ett annat autentiseringsläge.
För de scenarier där obevakad körning krävs måste du konfigurera ett huvudnamn för tjänsten för att kommunicera med Azure Mašinsko učenje.
import os
os.environ["AZURE_TENANT_ID"] = "<AZURE_TENANT_ID>"
os.environ["AZURE_CLIENT_ID"] = "<AZURE_CLIENT_ID>"
os.environ["AZURE_CLIENT_SECRET"] = "<AZURE_CLIENT_SECRET>"
Dricks
När du arbetar med delade miljöer rekommenderar vi att du konfigurerar dessa miljövariabler vid beräkningen. Vi rekommenderar att du hanterar dem som hemligheter i en instans av Azure Key Vault.
I Azure Databricks kan du till exempel använda hemligheter i miljövariabler enligt följande i klusterkonfigurationen: AZURE_CLIENT_SECRET={{secrets/<scope-name>/<secret-name>}}. Mer information om hur du implementerar den här metoden i Azure Databricks finns i Referens till en hemlighet i en miljövariabel eller i dokumentationen för din plattform.
Experimentets namn i Azure Mašinsko učenje
Som standard spårar Azure Mašinsko učenje körningar i ett standardexperiment med namnet Default. Det är vanligtvis en bra idé att ställa in experimentet som du kommer att arbeta med. Använd följande syntax för att ange experimentets namn:
mlflow.set_experiment(experiment_name="experiment-name")
Spåra parametrar, mått och artefakter
Du kan använda MLflow i Azure Synapse Analytics på samma sätt som du är van vid. Mer information finns i Logga och visa mått och loggfiler.
Registrera modeller i registret med MLflow
Modeller kan registreras i Azure Mašinsko učenje arbetsyta, som erbjuder en central lagringsplats för att hantera livscykeln. I följande exempel loggas en modell som tränats med Spark MLLib och registrerar den även i registret.
mlflow.spark.log_model(model,
artifact_path = "model",
registered_model_name = "model_name")
Om det inte finns någon registrerad modell med namnet registrerar metoden en ny modell, skapar version 1 och returnerar ett ModelVersion MLflow-objekt.
Om det redan finns en registrerad modell med namnet skapar metoden en ny modellversion och returnerar versionsobjektet.
Du kan hantera modeller som registrerats i Azure Mašinsko učenje med MLflow. Mer information finns i Hantera modellregister i Azure Mašinsko učenje med MLflow.
Distribuera och använda modeller som registrerats i Azure Mašinsko učenje
Modeller som registrerats i Azure Mašinsko učenje Service med MLflow kan användas som:
En Azure Mašinsko učenje-slutpunkt (realtid och batch): Med den här distributionen kan du använda Azure Mašinsko učenje distributionsfunktioner för både realtids- och batchinferens i Azure Container Instances (ACI), Azure Kubernetes (AKS) eller våra hanterade slutpunkter.
MLFlow-modellobjekt eller Pandas UDF:er, som kan användas i Azure Synapse Analytics-notebook-filer i strömnings- eller batchpipelines.
Distribuera modeller till Azure Mašinsko učenje-slutpunkter
Du kan använda plugin-programmet azureml-mlflow för att distribuera en modell till din Azure Mašinsko učenje-arbetsyta. Kontrollera hur du distribuerar MLflow-modeller för en fullständig information om hur du distribuerar modeller till de olika målen.
Viktigt!
Modeller måste registreras i Azure Mašinsko učenje-registret för att kunna distribuera dem. Distribution av oregistrerade modeller stöds inte i Azure Mašinsko učenje.
Distribuera modeller för batchbedömning med hjälp av UDF:er
Du kan välja Azure Synapse Analytics-kluster för batchbedömning. MLFlow-modellen läses in och används som Spark Pandas UDF för att poängsätta nya data.
from pyspark.sql.types import ArrayType, FloatType
model_uri = "runs:/"+last_run_id+ {model_path}
#Create a Spark UDF for the MLFlow model
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
#Load Scoring Data into Spark Dataframe
scoreDf = spark.table({table_name}).where({required_conditions})
#Make Prediction
preds = (scoreDf
.withColumn('target_column_name', pyfunc_udf('Input_column1', 'Input_column2', ' Input_column3', …))
)
display(preds)
Rensa resurser
Om du vill behålla din Azure Synapse Analytics-arbetsyta, men inte längre behöver Azure Mašinsko učenje-arbetsytan, kan du ta bort Azure Mašinsko učenje-arbetsytan. Om du inte planerar att använda de loggade måtten och artefakterna på din arbetsyta är möjligheten att ta bort dem individuellt inte tillgänglig just nu. Ta i stället bort resursgruppen som innehåller lagringskontot och arbetsytan, så att du inte debiteras några avgifter:
I Azure-portalen väljer du Resursgrupper längst till vänster.
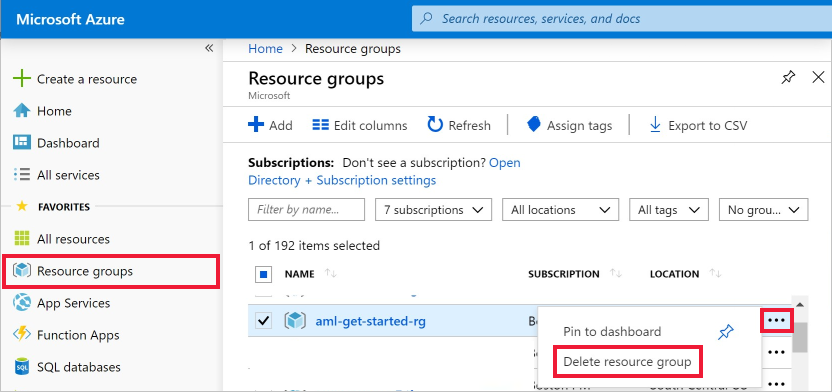
Välj den resursgrupp i listan som du har skapat.
Välj Ta bort resursgrupp.
Ange resursgruppsnamnet. Välj sedan ta bort.