Spåra experiment och modeller med MLflow
Spårning är processen för att spara relevant information om experiment. I den här artikeln får du lära dig hur du använder MLflow för att spåra experiment och körningar på Azure Machine Learning-arbetsytor.
Vissa metoder som är tillgängliga i MLflow-API:et kanske inte är tillgängliga när de är anslutna till Azure Machine Learning. Mer information om åtgärder som stöds och som inte stöds finns i Supportmatris för frågekörningar och experiment. Du kan också lära dig mer om de MLflow-funktioner som stöds i Azure Machine Learning i artikeln MLflow och Azure Machine Learning.
Kommentar
- Information om hur du spårar experiment som körs på Azure Databricks finns i Spåra Azure Databricks ML-experiment med MLflow och Azure Machine Learning.
- Information om hur du spårar experiment som körs i Azure Synapse Analytics finns i Spåra ML-experiment för Azure Synapse Analytics med MLflow och Azure Machine Learning.
Förutsättningar
Ha en Azure-prenumeration med den kostnadsfria eller betalda versionen av Azure Machine Learning.
Om du vill köra Azure CLI- och Python-kommandon installerar du Azure CLI v2 och Azure Machine Learning SDK v2 för Python. Tillägget
mlför Azure CLI installeras automatiskt första gången du kör ett Azure Machine Learning CLI-kommando.
Installera MLflow SDK-paketet
mlflowoch Azure Machine Learning-plugin-programmetazureml-mlflowför MLflow på följande sätt:pip install mlflow azureml-mlflowDricks
Du kan använda
mlflow-skinnypaketet, som är ett enkelt MLflow-paket utan SQL-lagring, server, användargränssnitt eller datavetenskapsberoenden. Det här paketet rekommenderas för användare som främst behöver MLflow-spårnings- och loggningsfunktionerna utan att importera hela sviten med funktioner, inklusive distributioner.Skapa en Azure Machine Learning-arbetsyta. Information om hur du skapar en arbetsyta finns i Skapa resurser som du behöver för att komma igång. Granska de åtkomstbehörigheter du behöver för att utföra dina MLflow-åtgärder på din arbetsyta.
Om du vill utföra fjärrspårning eller spåra experiment som körs utanför Azure Machine Learning konfigurerar du MLflow så att det pekar på spårnings-URI:n för din Azure Machine Learning-arbetsyta. Mer information om hur du ansluter MLflow till din arbetsyta finns i Konfigurera MLflow för Azure Machine Learning.
Konfigurera experimentet
MLflow organiserar information i experiment och körningar. Körningar kallas jobb i Azure Machine Learning. Som standard kör loggen till ett automatiskt skapat experiment med namnet Standard, men du kan konfigurera vilket experiment som ska spåras.
För interaktiv träning, till exempel i en Jupyter-anteckningsbok, använder du MLflow-kommandot mlflow.set_experiment(). Följande kodfragment konfigurerar till exempel ett experiment:
experiment_name = 'hello-world-example'
mlflow.set_experiment(experiment_name)
Konfigurera körningen
Azure Machine Learning spårar träningsjobb i vad MLflow-anrop körs. Använd körningar för att samla in all bearbetning som jobbet utför.
När du arbetar interaktivt börjar MLflow spåra din träningsrutin så snart du loggar information som kräver en aktiv körning. Om mlflows autologgningsfunktion till exempel är aktiverad startar MLflow-spårning när du loggar ett mått eller en parameter eller startar en träningscykel.
Det är dock vanligtvis bra att starta körningen explicit, särskilt om du vill samla in den totala tiden för experimentet i fältet Varaktighet . Om du vill starta körningen explicit använder du mlflow.start_run().
Oavsett om du startar körningen manuellt eller inte måste du stoppa körningen så att MLflow vet att experimentkörningen är klar och kan markera körningens status som Slutförd. Om du vill stoppa en körning använder du mlflow.end_run().
Följande kod startar en körning manuellt och avslutar den i slutet av notebook-filen:
mlflow.start_run()
# Your code
mlflow.end_run()
Det är bäst att starta körningar manuellt så att du inte glömmer att avsluta dem. Du kan använda paradigmet context manager för att komma ihåg att avsluta körningen.
with mlflow.start_run() as run:
# Your code
När du startar en ny körning med mlflow.start_run()kan det vara användbart att ange parametern run_name som senare översätts till namnet på körningen i Azure Machine Learning-användargränssnittet. Den här metoden hjälper dig att identifiera körningen snabbare.
with mlflow.start_run(run_name="hello-world-example") as run:
# Your code
Aktivera automatisk MLflow-loggning
Du kan logga mått, parametrar och filer med MLflow manuellt, och du kan också förlita dig på MLflows automatiska loggningsfunktion. Varje maskininlärningsramverk som stöds av MLflow avgör vad du ska spåra automatiskt åt dig.
Om du vill aktivera automatisk loggning infogar du följande kod före träningskoden:
mlflow.autolog()
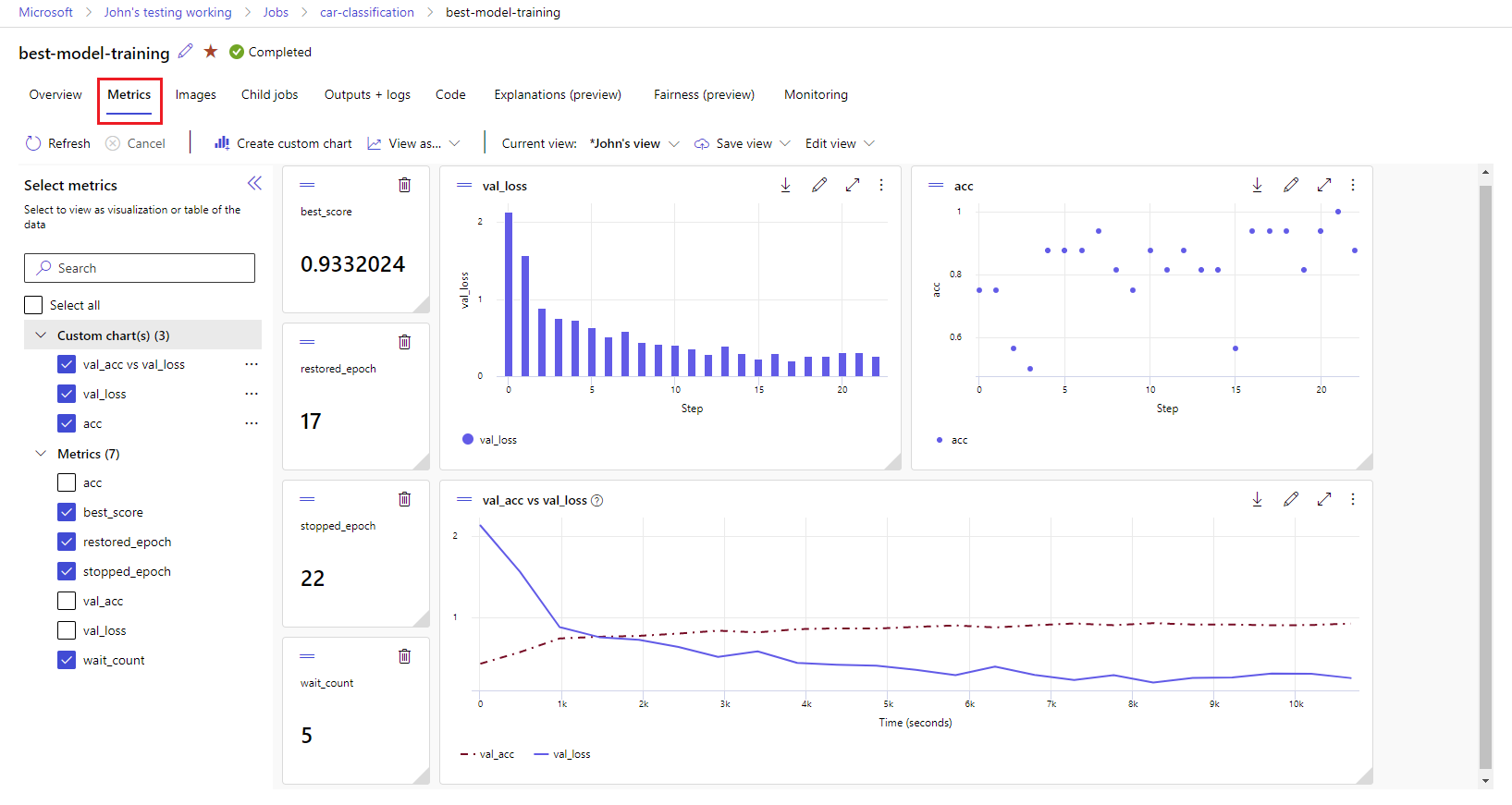
Visa mått och artefakter på din arbetsyta
Mått och artefakter från MLflow-loggning spåras på din arbetsyta. Du kan visa och komma åt dem i Azure Machine Learning-studio eller komma åt dem programmässigt via MLflow SDK.
Så här visar du mått och artefakter i studion:
På sidan Jobb på arbetsytan väljer du experimentnamnet.
På sidan med experimentinformation väljer du fliken Mått .
Välj loggade mått för att återge diagram till höger. Du kan anpassa diagrammen genom att använda utjämning, ändra färg eller rita flera mått i en enda graf. Du kan också ändra storlek på och ordna om layouten.
När du har skapat önskad vy sparar du den för framtida användning och delar den med dina teammedlemmar med hjälp av en direktlänk.

Om du vill komma åt eller fråga efter mått, parametrar och artefakter programmässigt via MLflow SDK använder du mlflow.get_run().
import mlflow
run = mlflow.get_run("<RUN_ID>")
metrics = run.data.metrics
params = run.data.params
tags = run.data.tags
print(metrics, params, tags)
Dricks
Föregående exempel returnerar endast det sista värdet för ett visst mått. Om du vill hämta alla värden för ett visst mått använder du mlflow.get_metric_history metoden. Mer information om hur du hämtar måttvärden finns i Hämta params och mått från en körning.
Om du vill ladda ned artefakter som du loggade, till exempel filer och modeller, använder du mlflow.artifacts.download_artifacts().
mlflow.artifacts.download_artifacts(run_id="<RUN_ID>", artifact_path="helloworld.txt")
Mer information om hur du hämtar eller jämför information från experiment och körs i Azure Machine Learning med hjälp av MLflow finns i Fråga och jämföra experiment och körningar med MLflow.