Hyperparameterjustering av en modell med Azure Machine Learning (v1)
GÄLLER FÖR: Azure CLI ml-tillägg v1
Azure CLI ml-tillägg v1
Viktigt
Azure CLI-kommandona i den här artikeln kräverazure-cli-mltillägget , eller v1, för Azure Machine Learning. Stödet för v1-tillägget upphör den 30 september 2025. Du kommer att kunna installera och använda v1-tillägget fram till det datumet.
Vi rekommenderar att du övergår till mltillägget , eller v2, före den 30 september 2025. Mer information om v2-tillägget finns i Azure ML CLI-tillägget och Python SDK v2.
Automatisera effektiv hyperparameterjustering med hjälp av Azure Machine Learning (v1) HyperDrive-paket. Lär dig hur du utför de steg som krävs för att finjustera hyperparametrar med Azure Machine Learning SDK:
- Definiera parameterns sökutrymme
- Ange ett primärt mått för att optimera
- Ange en princip för tidig avslutning för lågpresterande körningar
- Skapa och tilldela resurser
- Starta ett experiment med den definierade konfigurationen
- Visualisera träningskörningarna
- Välj den bästa konfigurationen för din modell
Vad är justering av hyperparametrar?
Hyperparametrar är justerbara parametrar som gör att du kan styra modellträningsprocessen. Med neurala nätverk bestämmer du till exempel antalet dolda lager och antalet noder i varje lager. Modellprestanda är starkt beroende av hyperparametrar.
Justering av hyperparametrar, även kallat optimering av hyperparametrar, är en process för att hitta konfigurationen av hyperparametrar som ger bästa prestanda. Processen är vanligtvis beräkningsmässigt dyr och manuell.
Med Azure Machine Learning kan du automatisera justering av hyperparametrar och köra experiment parallellt för att effektivt optimera hyperparametrar.
Definiera sökutrymmet
Finjustera hyperparametrar genom att utforska intervallet med värden som definierats för varje hyperparameter.
Hyperparametrar kan vara diskreta eller kontinuerliga och har en fördelning av värden som beskrivs av ett parameteruttryck.
Diskreta hyperparametrar
Diskreta hyperparametrar anges som en choice bland diskreta värden. choice kan vara:
- ett eller flera kommaavgränsade värden
- ett
rangeobjekt - godtyckliga
listobjekt
{
"batch_size": choice(16, 32, 64, 128)
"number_of_hidden_layers": choice(range(1,5))
}
I det här fallet batch_size tar ett av värdena [16, 32, 64, 128] och number_of_hidden_layers ett av värdena [1, 2, 3, 4].
Följande avancerade diskreta hyperparametrar kan också anges med hjälp av en distribution:
quniform(low, high, q)- Returnerar ett värde som round(uniform(low, high) / q) * qqloguniform(low, high, q)- Returnerar ett värde som round(exp(uniform(low, high)) / q) * qqnormal(mu, sigma, q)- Returnerar ett värde som round(normal(mu, sigma) / q) * qqlognormal(mu, sigma, q)- Returnerar ett värde som round(exp(normal(mu, sigma)) / q) * q
Kontinuerliga hyperparametrar
Kontinuerliga hyperparametrar anges som en fördelning över ett kontinuerligt värdeintervall:
uniform(low, high)– Returnerar ett värde som är jämnt fördelat mellan låg och högloguniform(low, high)- Returnerar ett värde som ritats enligt exp(uniform(low, high)) så att logaritmen för returvärdet fördelas jämntnormal(mu, sigma)– Returnerar ett verkligt värde som normalt distribueras med medelvärdet mu och standardavvikelse sigmalognormal(mu, sigma)- Returnerar ett värde som ritats enligt exp(normal(mu, sigma)) så att logaritmen för returvärdet normalt distribueras
Ett exempel på en parameterutrymmesdefinition:
{
"learning_rate": normal(10, 3),
"keep_probability": uniform(0.05, 0.1)
}
Den här koden definierar ett sökutrymme med två parametrar – learning_rate och keep_probability. learning_rate har en normal fördelning med medelvärdet 10 och en standardavvikelse på 3. keep_probability har en enhetlig fördelning med ett minimivärde på 0,05 och ett maxvärde på 0,1.
Sampling av hyperparameterutrymmet
Ange den parametersamplingsmetod som ska användas över hyperparameterutrymmet. Azure Machine Learning stöder följande metoder:
- Stickprov
- Rutnätssampling
- Bayesiansk sampling
Stickprov
Slumpmässig sampling stöder diskreta och kontinuerliga hyperparametrar. Den stöder tidig avslutning av körningar med låga prestanda. Vissa användare gör en första sökning med slumpmässig sampling och förfinar sedan sökutrymmet för att förbättra resultaten.
I slumpmässig sampling väljs hyperparametervärden slumpmässigt från det definierade sökområdet.
from azureml.train.hyperdrive import RandomParameterSampling
from azureml.train.hyperdrive import normal, uniform, choice
param_sampling = RandomParameterSampling( {
"learning_rate": normal(10, 3),
"keep_probability": uniform(0.05, 0.1),
"batch_size": choice(16, 32, 64, 128)
}
)
Rutnätssampling
Rutnätssampling stöder diskreta hyperparametrar. Använd rutnätssampling om du kan budgeta för att fullständigt söka i sökutrymmet. Stöder tidig avslutning av körningar med låga prestanda.
Rutnätssampling gör en enkel rutnätssökning över alla möjliga värden. Rutnätssampling kan endast användas med choice hyperparametrar. Följande blanksteg innehåller till exempel sex exempel:
from azureml.train.hyperdrive import GridParameterSampling
from azureml.train.hyperdrive import choice
param_sampling = GridParameterSampling( {
"num_hidden_layers": choice(1, 2, 3),
"batch_size": choice(16, 32)
}
)
Bayesiansk sampling
Bayesiansk sampling baseras på Bayesian-optimeringsalgoritmen. Den väljer exempel baserat på hur tidigare exempel gjorde, så att nya exempel förbättrar det primära måttet.
Bayesiansk sampling rekommenderas om du har tillräckligt med budget för att utforska hyperparameterutrymmet. För bästa resultat rekommenderar vi ett maximalt antal körningar som är större än eller lika med 20 gånger antalet hyperparametrar som justeras.
Antalet samtidiga körningar påverkar justeringsprocessens effektivitet. Ett mindre antal samtidiga körningar kan leda till bättre samplingskonvergens, eftersom den mindre graden av parallellitet ökar antalet körningar som drar nytta av tidigare slutförda körningar.
Bayesiansk sampling stöder choiceendast , uniformoch quniform distributioner över sökutrymmet.
from azureml.train.hyperdrive import BayesianParameterSampling
from azureml.train.hyperdrive import uniform, choice
param_sampling = BayesianParameterSampling( {
"learning_rate": uniform(0.05, 0.1),
"batch_size": choice(16, 32, 64, 128)
}
)
Ange primärt mått
Ange det primära mått som du vill att hyperparameterjustering ska optimera. Varje träningskörning utvärderas för det primära måttet. Principen för tidig avslutning använder det primära måttet för att identifiera körningar med låga prestanda.
Ange följande attribut för ditt primära mått:
primary_metric_name: Namnet på det primära måttet måste exakt matcha namnet på måttet som loggas av träningsskriptetprimary_metric_goal: Det kan vara antingenPrimaryMetricGoal.MAXIMIZEellerPrimaryMetricGoal.MINIMIZEoch avgör om det primära måttet ska maximeras eller minimeras när körningarna utvärderas.
primary_metric_name="accuracy",
primary_metric_goal=PrimaryMetricGoal.MAXIMIZE
Det här exemplet maximerar "noggrannheten".
Loggmått för justering av hyperparametrar
Träningsskriptet för din modell måste logga det primära måttet under modellträningen så att HyperDrive kan komma åt det för justering av hyperparametrar.
Logga det primära måttet i träningsskriptet med följande exempelfragment:
from azureml.core.run import Run
run_logger = Run.get_context()
run_logger.log("accuracy", float(val_accuracy))
Träningsskriptet beräknar val_accuracy och loggar det som det primära måttet "noggrannhet". Varje gång måttet loggas tas det emot av tjänsten för hyperparameterjustering. Det är upp till dig att fastställa rapporteringsfrekvensen.
Mer information om loggningsvärden i modellträningskörningar finns i Aktivera loggning i Azure Machine Learning-träningskörningar.
Ange princip för tidig avslutning
Slutar automatiskt dåligt presterande körningar med en princip för tidig avslutning. Tidig avslutning förbättrar beräkningseffektiviteten.
Du kan konfigurera följande parametrar som styr när en princip tillämpas:
evaluation_interval: hur ofta principen tillämpas. Varje gång träningsskriptet loggar räknas det primära måttet som ett intervall. Enevaluation_intervalav 1 tillämpar principen varje gång träningsskriptet rapporterar det primära måttet. Enevaluation_intervalav 2 tillämpar principen varannan gång. Om det inte angesevaluation_intervalanges till 1 som standard.delay_evaluation: fördröjer den första principutvärderingen för ett angivet antal intervall. Det här är en valfri parameter som undviker för tidig avslutning av träningskörningar genom att tillåta att alla konfigurationer körs under ett minsta antal intervall. Om det anges tillämpar principen varje multipel av evaluation_interval som är större än eller lika med delay_evaluation.
Azure Machine Learning stöder följande principer för tidig avslutning:
Banditpolicy
Bandit-principen baseras på slackfaktor/slack-belopp och utvärderingsintervall. Banditen avslutas när det primära måttet inte är inom den angivna slackfaktorn/slack-mängden för den mest lyckade körningen.
Anteckning
Bayesiansk sampling stöder inte tidig avslutning. När du använder Bayesian-sampling anger du early_termination_policy = None.
Ange följande konfigurationsparametrar:
slack_factorellerslack_amount: det slack som tillåts med avseende på den bäst presterande träningskörningen.slack_factoranger det tillåtna slacket som ett förhållande.slack_amountanger det tillåtna slacket som ett absolut belopp i stället för ett förhållande.Anta till exempel att en Bandit-princip tillämpas med intervall 10. Anta att den bäst presterande körningen med intervall 10 rapporterade att ett primärt mått är 0,8 med målet att maximera det primära måttet. Om principen anger ett
slack_factorpå 0,2 avslutas alla träningskörningar vars bästa mått med intervall 10 är mindre än 0,66 (0,8/(1+slack_factor).).evaluation_interval: (valfritt) frekvensen för att tillämpa principendelay_evaluation: (valfritt) fördröjer den första principutvärderingen för ett angivet antal intervall
from azureml.train.hyperdrive import BanditPolicy
early_termination_policy = BanditPolicy(slack_factor = 0.1, evaluation_interval=1, delay_evaluation=5)
I det här exemplet tillämpas principen för tidig avslutning vid varje intervall när mått rapporteras, med början vid utvärderingsintervall 5. Alla körningar vars bästa mått är mindre än (1/(1+0.1) eller 91 % av den bästa körningen avslutas.
Princip för medianstopp
Medianstopp är en princip för tidig avslutning som baseras på löpande medelvärden för primära mått som rapporterats av körningarna. Den här principen beräknar löpande medelvärden för alla träningskörningar och stoppar körningar vars primära måttvärde är sämre än medelvärdenas median.
Den här principen tar följande konfigurationsparametrar:
evaluation_interval: frekvensen för att tillämpa principen (valfri parameter).delay_evaluation: fördröjer den första principutvärderingen för ett angivet antal intervall (valfri parameter).
from azureml.train.hyperdrive import MedianStoppingPolicy
early_termination_policy = MedianStoppingPolicy(evaluation_interval=1, delay_evaluation=5)
I det här exemplet tillämpas principen för tidig avslutning vid varje intervall som börjar med utvärderingsintervall 5. En körning stoppas med intervall 5 om dess bästa primära mått är sämre än medianvärdet för de löpande medelvärdena över intervall 1:5 för alla träningskörningar.
Princip för trunkeringsval
Trunkeringsmarkeringen avbryter en procentandel av de körningar som har lägst prestanda vid varje utvärderingsintervall. Körningar jämförs med det primära måttet.
Den här principen tar följande konfigurationsparametrar:
truncation_percentage: procentandelen med lägst presterande körningar som ska avslutas vid varje utvärderingsintervall. Ett heltalsvärde mellan 1 och 99.evaluation_interval: (valfritt) frekvensen för att tillämpa principendelay_evaluation: (valfritt) fördröjer den första principutvärderingen för ett angivet antal intervallexclude_finished_jobs: anger om slutförda jobb ska undantas när principen tillämpas
from azureml.train.hyperdrive import TruncationSelectionPolicy
early_termination_policy = TruncationSelectionPolicy(evaluation_interval=1, truncation_percentage=20, delay_evaluation=5, exclude_finished_jobs=true)
I det här exemplet tillämpas principen för tidig avslutning vid varje intervall som börjar med utvärderingsintervall 5. En körning avslutas med intervall 5 om dess prestanda vid intervall 5 har lägst 20 % av prestandan för alla körningar med intervall 5 och exkluderar slutförda jobb när principen tillämpas.
Ingen avslutningsprincip (standard)
Om ingen princip anges låter tjänsten för hyperparameterjustering alla träningskörningar köras för att slutföras.
policy=None
Välja en princip för tidig avslutning
- För en konservativ politik som ger besparingar utan att avsluta lovande jobb, överväg en medianstopppolicy med
evaluation_interval1 ochdelay_evaluation5. Det här är konservativa inställningar som kan ge ungefär 25–35 % besparingar utan förlust på primärmått (baserat på våra utvärderingsdata). - Om du vill ha mer aggressiva besparingar använder du Bandit Policy med en mindre tillåten slack- eller truncation-markeringsprincip med en större trunkeringsprocent.
Skapa och tilldela resurser
Kontrollera resursbudgeten genom att ange det maximala antalet träningskörningar.
max_total_runs: Maximalt antal träningskörningar. Måste vara ett heltal mellan 1 och 1 000.max_duration_minutes: (valfritt) Maximal varaktighet i minuter för hyperparameterjusteringsexperimentet. Körs efter att den här varaktigheten har avbrutits.
Anteckning
Om både max_total_runs och max_duration_minutes anges avslutas hyperparameterjusteringsexperimentet när det första av dessa två tröskelvärden nås.
Ange dessutom det maximala antalet träningskörningar som ska köras samtidigt under hyperparameterjusteringssökningen.
max_concurrent_runs: (valfritt) Maximalt antal körningar som kan köras samtidigt. Om inte anges startas alla körningar parallellt. Om det anges måste det vara ett heltal mellan 1 och 100.
Anteckning
Antalet samtidiga körningar är gated för de resurser som är tillgängliga i det angivna beräkningsmålet. Kontrollera att beräkningsmålet har tillgängliga resurser för önskad samtidighet.
max_total_runs=20,
max_concurrent_runs=4
Den här koden konfigurerar hyperparameterjusteringsexperimentet för att använda högst 20 totala körningar, som kör fyra konfigurationer åt gången.
Konfigurera hyperparameterjusteringsexperiment
Om du vill konfigurera hyperparameterjusteringsexperimentet anger du följande:
- Det definierade sökområdet för hyperparametrar
- Principen för tidig uppsägning
- Det primära måttet
- Resursallokeringsinställningar
- ScriptRunConfig
script_run_config
ScriptRunConfig är träningsskriptet som ska köras med de exempelbaserade hyperparametrarna. Den definierar de resurser per jobb (en eller flera noder) och beräkningsmålet som ska användas.
Anteckning
Beräkningsmålet som används i script_run_config måste ha tillräckligt med resurser för att uppfylla samtidighetsnivån. Mer information om ScriptRunConfig finns i Konfigurera träningskörningar.
Konfigurera hyperparameterjusteringsexperimentet:
from azureml.train.hyperdrive import HyperDriveConfig
from azureml.train.hyperdrive import RandomParameterSampling, BanditPolicy, uniform, PrimaryMetricGoal
param_sampling = RandomParameterSampling( {
'learning_rate': uniform(0.0005, 0.005),
'momentum': uniform(0.9, 0.99)
}
)
early_termination_policy = BanditPolicy(slack_factor=0.15, evaluation_interval=1, delay_evaluation=10)
hd_config = HyperDriveConfig(run_config=script_run_config,
hyperparameter_sampling=param_sampling,
policy=early_termination_policy,
primary_metric_name="accuracy",
primary_metric_goal=PrimaryMetricGoal.MAXIMIZE,
max_total_runs=100,
max_concurrent_runs=4)
Anger HyperDriveConfig parametrarna som skickas ScriptRunConfig script_run_configtill . I script_run_configsin tur skickar parametrarna till träningsskriptet. Kodfragmentet ovan hämtas från notebook-exemplet Train, hyperparameter tune och deploy with PyTorch. I det här exemplet justeras parametrarna learning_rate och momentum . Tidigt stopp av körningar bestäms av en BanditPolicy, som stoppar en körning vars primära mått faller utanför (se Referens för slack_factorBanditPolicy-klassen).
Följande kod från exemplet visar hur de justerade värdena tas emot, parsas och skickas till träningsskriptets fine_tune_model funktion:
# from pytorch_train.py
def main():
print("Torch version:", torch.__version__)
# get command-line arguments
parser = argparse.ArgumentParser()
parser.add_argument('--num_epochs', type=int, default=25,
help='number of epochs to train')
parser.add_argument('--output_dir', type=str, help='output directory')
parser.add_argument('--learning_rate', type=float,
default=0.001, help='learning rate')
parser.add_argument('--momentum', type=float, default=0.9, help='momentum')
args = parser.parse_args()
data_dir = download_data()
print("data directory is: " + data_dir)
model = fine_tune_model(args.num_epochs, data_dir,
args.learning_rate, args.momentum)
os.makedirs(args.output_dir, exist_ok=True)
torch.save(model, os.path.join(args.output_dir, 'model.pt'))
Viktigt
Varje hyperparameterkörning startar om träningen från grunden, inklusive återskapande av modellen och alla datainläsare. Du kan minimera den här kostnaden genom att använda en Azure Machine Learning-pipeline eller manuell process för att göra så mycket dataförberedelser som möjligt innan dina träningskörningar.
Skicka hyperparameterjusteringsexperiment
När du har definierat hyperparameterjusteringskonfigurationen skickar du experimentet:
from azureml.core.experiment import Experiment
experiment = Experiment(workspace, experiment_name)
hyperdrive_run = experiment.submit(hd_config)
Justering av hyperparameter för varmstart (valfritt)
Att hitta de bästa hyperparametervärdena för din modell kan vara en iterativ process. Du kan återanvända kunskap från de fem föregående körningarna för att påskynda justeringen av hyperparametrar.
Varm start hanteras på olika sätt beroende på samplingsmetoden:
- Bayesiansk sampling: Utvärderingsversioner från föregående körning används som förkunskaper för att välja nya exempel och för att förbättra det primära måttet.
- Slumpmässig sampling eller rutnätssampling: Tidig avslutning använder kunskap från tidigare körningar för att fastställa dåligt presterande körningar.
Ange listan över överordnade körningar som du vill värma start från.
from azureml.train.hyperdrive import HyperDriveRun
warmstart_parent_1 = HyperDriveRun(experiment, "warmstart_parent_run_ID_1")
warmstart_parent_2 = HyperDriveRun(experiment, "warmstart_parent_run_ID_2")
warmstart_parents_to_resume_from = [warmstart_parent_1, warmstart_parent_2]
Om ett hyperparameterjusteringsexperiment avbryts kan du återuppta träningskörningar från den senaste kontrollpunkten. Träningsskriptet måste dock hantera kontrollpunktslogik.
Träningskörningen måste använda samma hyperparameterkonfiguration och montera utdatamapparna. Träningsskriptet måste acceptera resume-from argumentet, som innehåller kontrollpunkten eller modellfilerna som träningskörningen ska återupptas från. Du kan återuppta enskilda träningskörningar med hjälp av följande kodfragment:
from azureml.core.run import Run
resume_child_run_1 = Run(experiment, "resume_child_run_ID_1")
resume_child_run_2 = Run(experiment, "resume_child_run_ID_2")
child_runs_to_resume = [resume_child_run_1, resume_child_run_2]
Du kan konfigurera hyperparameterjusteringsexperimentet till varm start från ett tidigare experiment eller återuppta enskilda träningskörningar med hjälp av de valfria parametrarna resume_from och resume_child_runs i konfigurationen:
from azureml.train.hyperdrive import HyperDriveConfig
hd_config = HyperDriveConfig(run_config=script_run_config,
hyperparameter_sampling=param_sampling,
policy=early_termination_policy,
resume_from=warmstart_parents_to_resume_from,
resume_child_runs=child_runs_to_resume,
primary_metric_name="accuracy",
primary_metric_goal=PrimaryMetricGoal.MAXIMIZE,
max_total_runs=100,
max_concurrent_runs=4)
Visualisera justeringskörningar för hyperparametrar
Du kan visualisera dina justeringskörningar för hyperparametrar i Azure Machine Learning-studio, eller så kan du använda en notebook-widget.
Studio
Du kan visualisera alla dina hyperparameterjusteringskörningar i Azure Machine Learning-studio. Mer information om hur du visar ett experiment i portalen finns i Visa körningsposter i studio.
Måttdiagram: Den här visualiseringen spårar de mått som loggas för varje underordnad hyperdrive-körning under varaktigheten för justering av hyperparametrar. Varje rad representerar en underordnad körning och varje punkt mäter det primära måttvärdet vid iterationen av körningen.
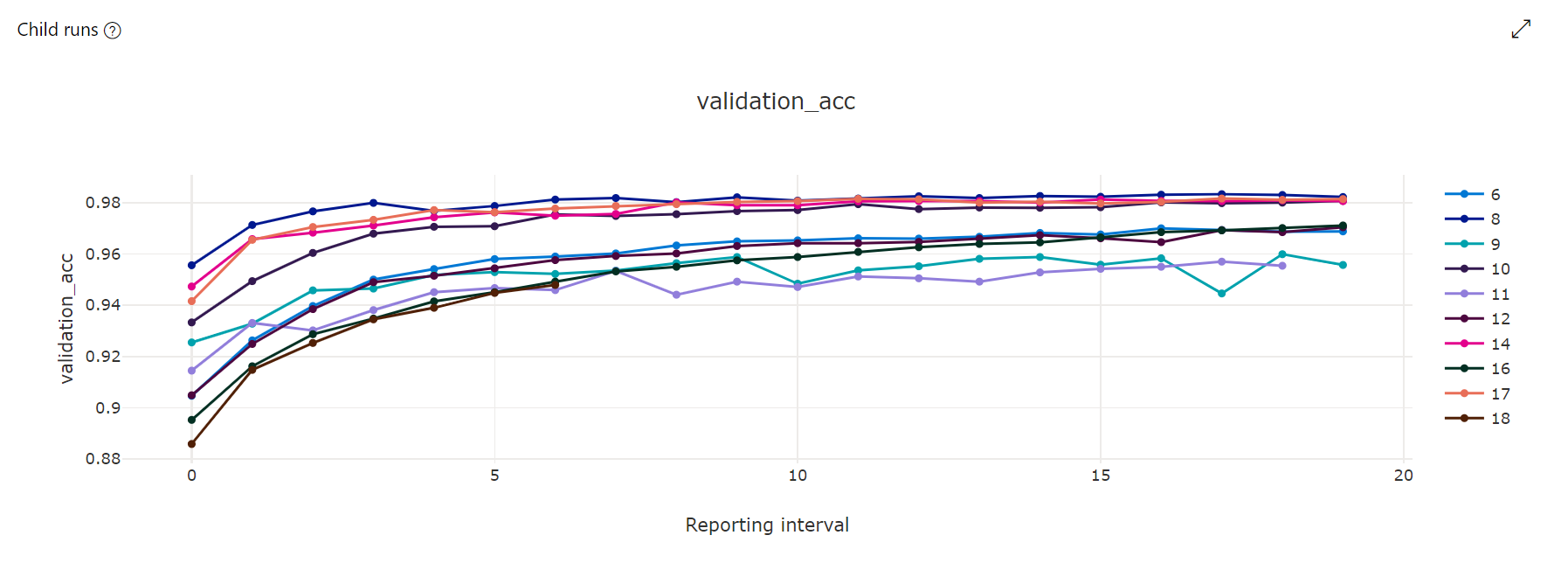
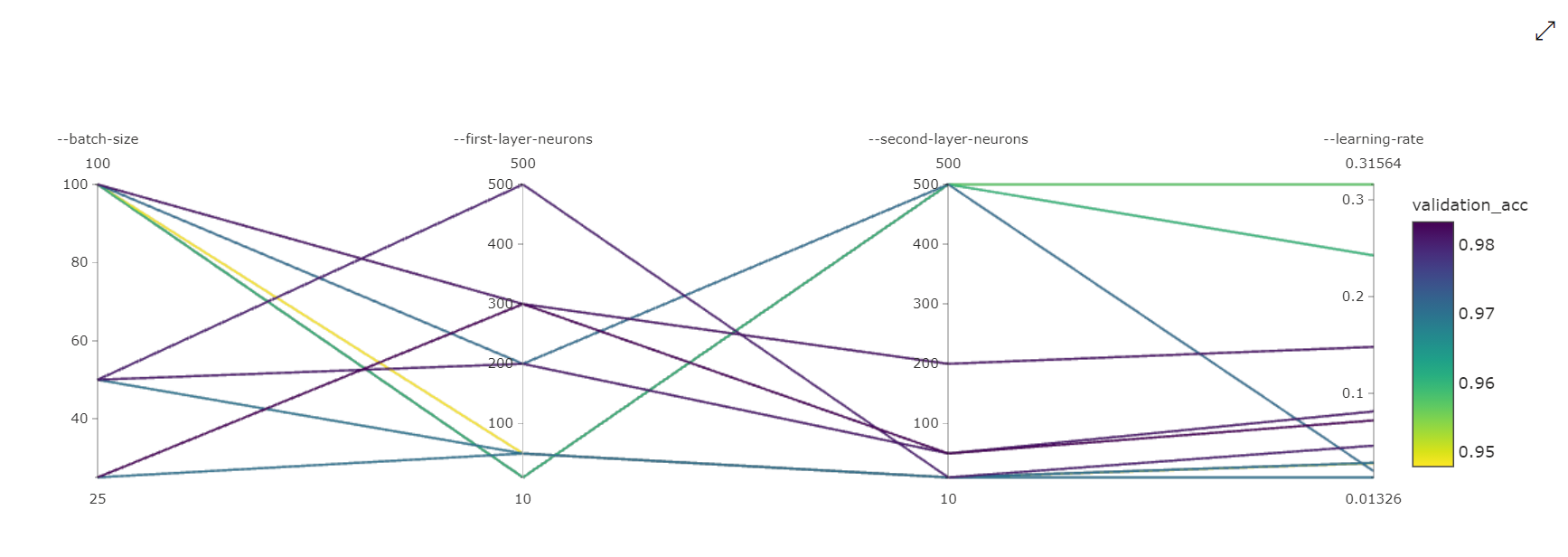
Diagram över parallella koordinater: Den här visualiseringen visar korrelationen mellan primära måttprestanda och enskilda hyperparametervärden. Diagrammet är interaktivt via förflyttning av axlar (klicka och dra med axeletiketten) och genom att markera värden över en enskild axel (klicka och dra lodrätt längs en enskild axel för att markera ett intervall med önskade värden). Diagrammet med parallella koordinater innehåller en axel på den högra delen av diagrammet som ritar det bästa måttvärdet som motsvarar de hyperparametrar som angetts för den körningsinstansen. Den här axeln tillhandahålls för att projicera diagramtoningsförklaringen till data på ett mer läsbart sätt.
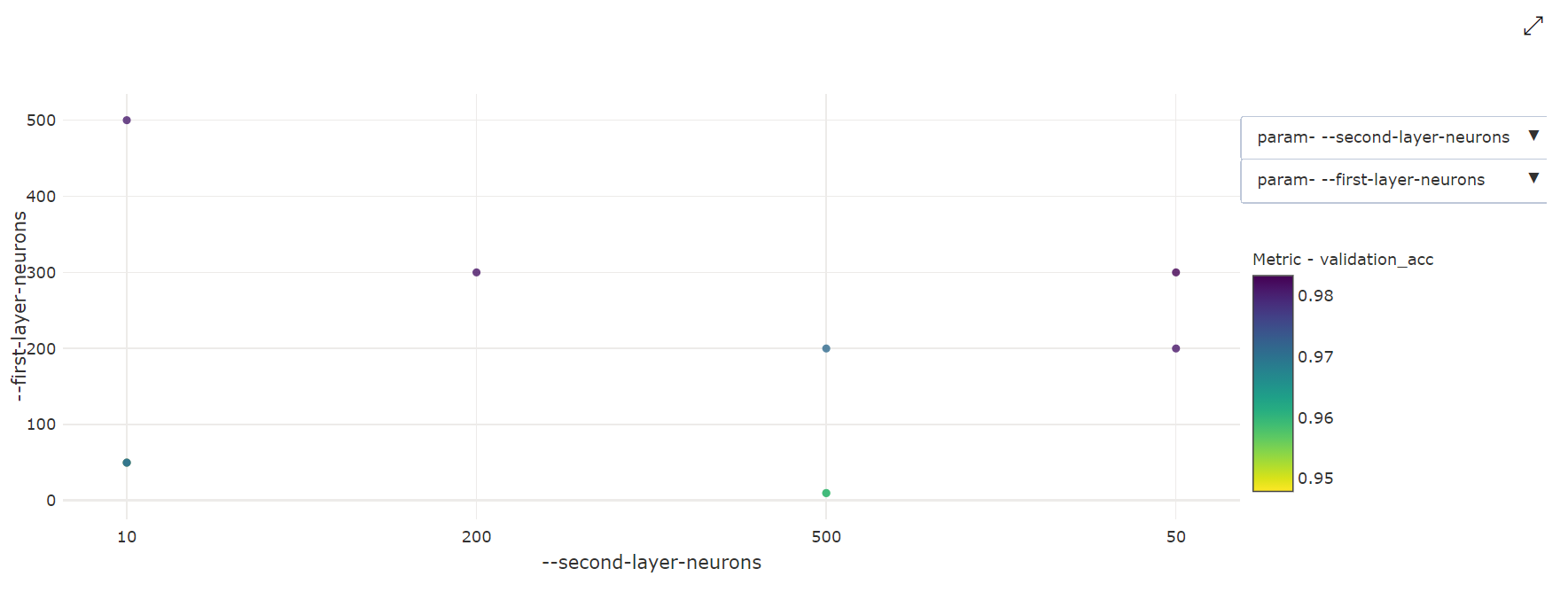
Tvådimensionellt punktdiagram: Den här visualiseringen visar korrelationen mellan två enskilda hyperparametrar tillsammans med deras associerade primära måttvärde.
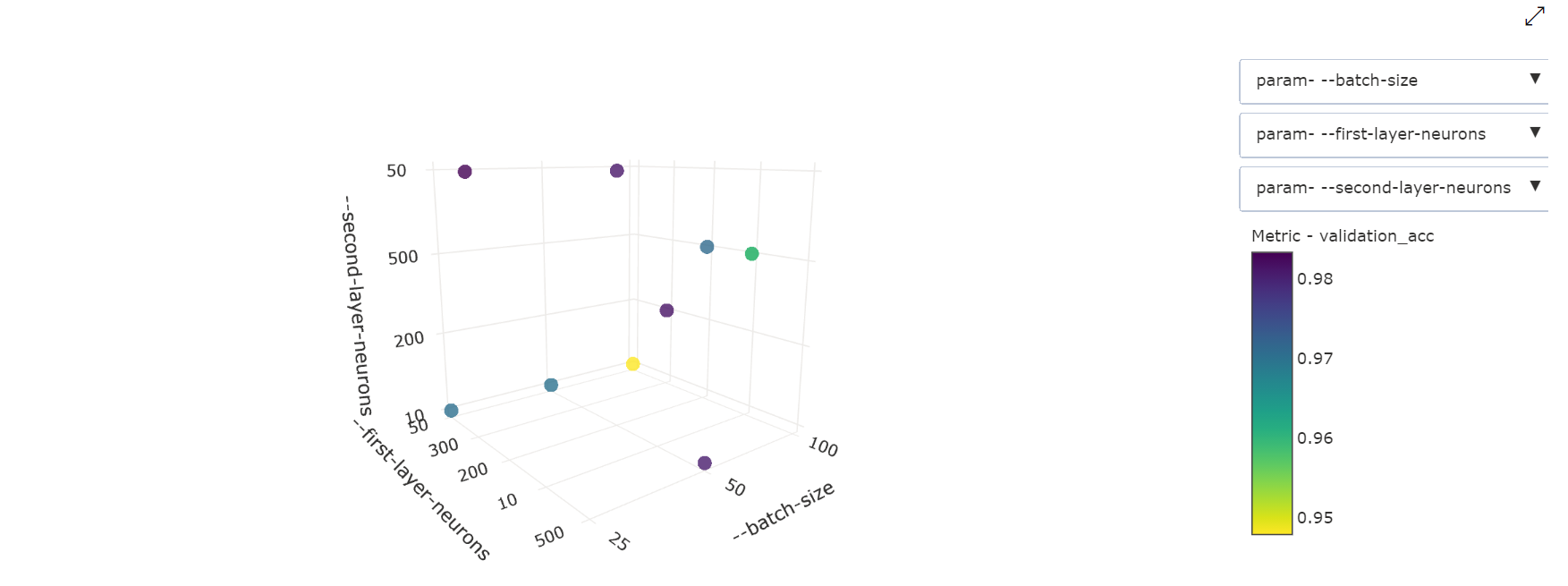
3-dimensionellt punktdiagram: Den här visualiseringen är samma som 2D men tillåter tre hyperparameterdimensioner av korrelation med det primära måttvärdet. Du kan också klicka och dra för att omorientera diagrammet för att visa olika korrelationer i 3D-utrymme.
Anteckningsbok-widget
Använd notebook-widgeten för att visualisera förloppet för dina träningskörningar. Följande kodfragment visualiserar alla dina justeringskörningar för hyperparametrar på ett ställe i en Jupyter Notebook:
from azureml.widgets import RunDetails
RunDetails(hyperdrive_run).show()
Den här koden visar en tabell med information om träningskörningarna för var och en av hyperparameterkonfigurationerna.
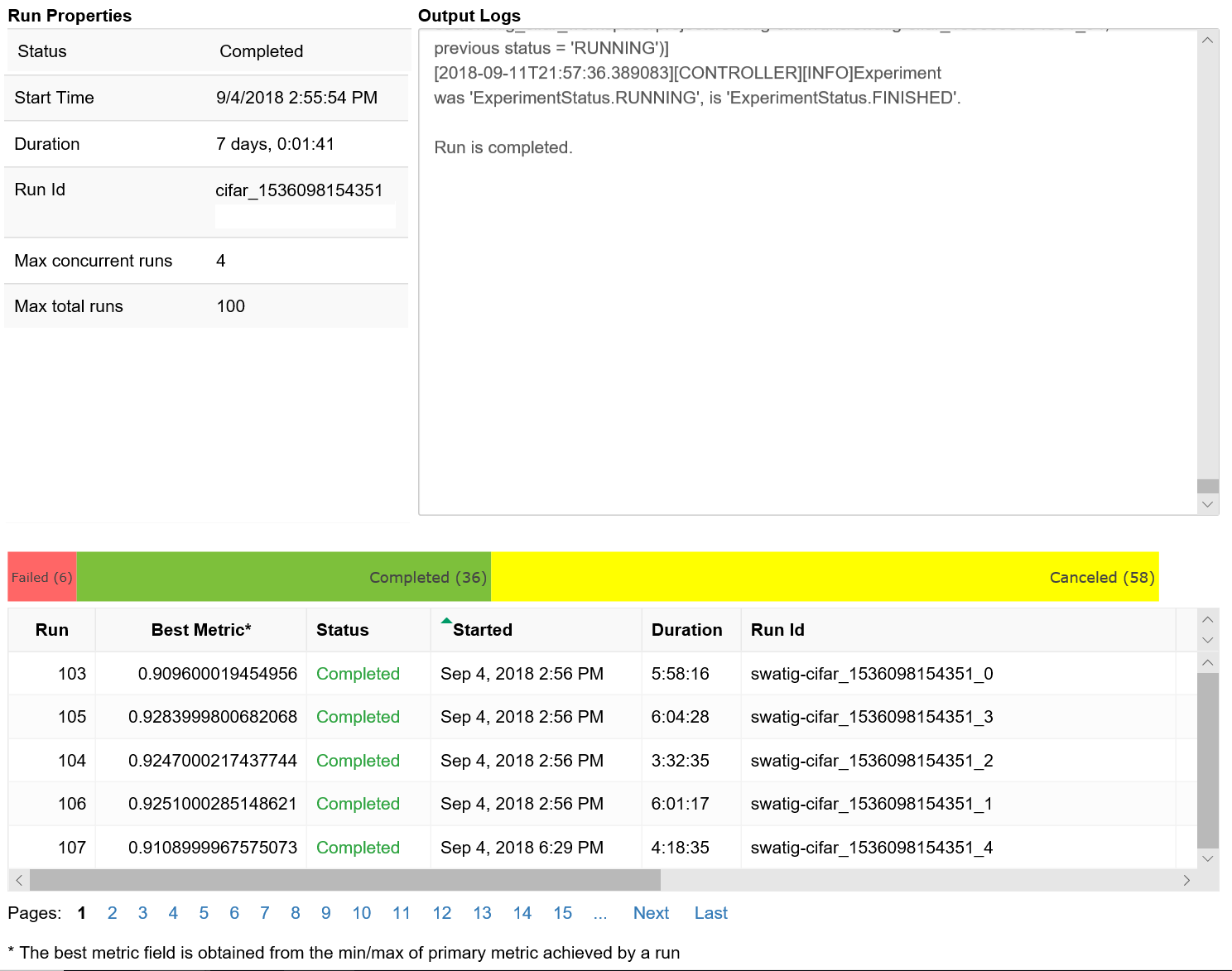
Du kan också visualisera prestanda för varje körning när träningen fortskrider.
Hitta den bästa modellen
När alla justeringskörningar för hyperparametrar har slutförts identifierar du de bästa konfigurations- och hyperparametervärdena:
best_run = hyperdrive_run.get_best_run_by_primary_metric()
best_run_metrics = best_run.get_metrics()
parameter_values = best_run.get_details()['runDefinition']['arguments']
print('Best Run Id: ', best_run.id)
print('\n Accuracy:', best_run_metrics['accuracy'])
print('\n learning rate:',parameter_values[3])
print('\n keep probability:',parameter_values[5])
print('\n batch size:',parameter_values[7])
Exempelanteckningsbok
Se notebook-filer för train-hyperparameter-* i den här mappen:
Lär dig att köra notebook-filer genom att följa artikeln Använda Jupyter-notebooks till att utforska tjänsten.