Konfigurationer och åtgärder för SAP HANA i Azure-infrastrukturer
Det här dokumentet innehåller vägledning för att konfigurera Azure-infrastruktur och använda SAP HANA-system som distribueras på virtuella Azure-datorer (VM). Dokumentet innehåller även konfigurationsinformation för SAP HANA-utskalning för den virtuella M128-datorns SKU. Det här dokumentet är inte avsett att ersätta SAP-standarddokumentationen, som innehåller följande innehåll:
Förutsättningar
Om du vill använda den här guiden behöver du grundläggande kunskaper om följande Azure-komponenter:
Mer information om SAP NetWeaver och andra SAP-komponenter i Azure finns i avsnittet SAP on Azure i Azure-dokumentationen.
Grundläggande konfigurationsöverväganden
I följande avsnitt beskrivs grundläggande konfigurationsöverväganden för distribution av SAP HANA-system på virtuella Azure-datorer.
Ansluta till virtuella Azure-datorer
Som beskrivs i planeringsguiden för virtuella Azure-datorer finns det två grundläggande metoder för att ansluta till virtuella Azure-datorer:
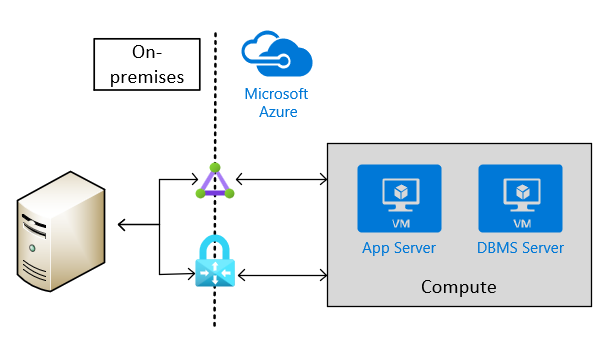
- Anslut via Internet och offentliga slutpunkter på en virtuell jump-dator eller på den virtuella dator som kör SAP HANA.
- Anslut via ett VPN eller Azure ExpressRoute.
Plats-till-plats-anslutning via VPN eller ExpressRoute krävs för produktionsscenarier. Den här typen av anslutning behövs också för scenarier som inte är produktionsscenarier där SAP-programvara används. Följande bild visar ett exempel på anslutning mellan platser:
Välj typer av virtuella Azure-datorer
SAP listar vilka typer av virtuella Azure-datorer som du kan använda för produktionsscenarier. För scenarier som inte är produktionsbaserade är en bredare mängd olika typer av interna virtuella Azure-datorer tillgängliga.
Kommentar
För scenarier som inte är produktionsbaserade använder du de VM-typer som visas i SAP-anteckningen #1928533. Om du vill använda virtuella Azure-datorer för produktionsscenarier kan du söka efter SAP HANA-certifierade virtuella datorer i listan SAP-publicerade certifierade IaaS-plattformar.
Distribuera de virtuella datorerna i Azure med hjälp av:
- Azure-portalen.
- Azure PowerShell-cmdletar.
- Azure CLI.
Viktigt!
För att kunna använda M208xx_v2 virtuella datorer måste du vara försiktig med att välja din Linux-avbildning. Mer information finns i Storlekar på minnesoptimerade virtuella datorer.
Lagringskonfiguration för SAP HANA
För lagringskonfigurationer och lagringstyper som ska användas med SAP HANA i Azure läser du dokumentet sap hana azure virtual machine storage configurations
Konfigurera virtuella Azure-nätverk
När du har plats-till-plats-anslutning till Azure via VPN eller ExpressRoute måste du ha minst ett virtuellt Azure-nätverk som är anslutet via en virtuell gateway till VPN- eller ExpressRoute-kretsen. I enkla distributioner kan den virtuella gatewayen distribueras i ett undernät i det virtuella Azure-nätverket (VNet) som också är värd för SAP HANA-instanserna. Om du vill installera SAP HANA skapar du ytterligare två undernät i det virtuella Azure-nätverket. Ett undernät är värd för de virtuella datorerna för att köra SAP HANA-instanserna. Det andra undernätet kör jumpbox- eller hanteringsdatorer för att vara värd för SAP HANA Studio, annan hanteringsprogramvara eller programprogramvara.
Viktigt!
Av funktioner, men ännu viktigare av prestandaskäl, stöds det inte att konfigurera virtuella Azure-nätverksinstallationer i kommunikationssökvägen mellan SAP-programmet och DBMS-lagret i ett SAP NetWeaver-, Hybris- eller S/4HANA-baserat SAP-system. Kommunikationen mellan SAP-programlagret och DBMS-lagret måste vara direkt. Begränsningen omfattar inte Azure ASG- och NSG-regler så länge dessa ASG- och NSG-regler tillåter direkt kommunikation. Ytterligare scenarier där NVA:er inte stöds finns i kommunikationsvägar mellan virtuella Azure-datorer som representerar Linux Pacemaker-klusternoder och SBD-enheter enligt beskrivningen i Hög tillgänglighet för SAP NetWeaver på virtuella Azure-datorer på SUSE Linux Enterprise Server för SAP-program. Eller i kommunikationsvägar mellan virtuella Azure-datorer och Windows Server SOFS som konfigurerats enligt beskrivningen i Klustra en SAP ASCS/SCS-instans i ett Windows-redundanskluster med hjälp av en filresurs i Azure. NVA:er i kommunikationsvägar kan enkelt fördubbla nätverksfördröjningen mellan två kommunikationspartner, kan begränsa dataflödet i kritiska sökvägar mellan SAP-programlagret och DBMS-lagret. I vissa scenarier som observeras med kunder kan NVA:er orsaka att Pacemaker Linux-kluster misslyckas i fall där kommunikationen mellan Linux Pacemaker-klusternoderna behöver kommunicera med sin SBD-enhet via en NVA.
Viktigt!
En annan design som INTE stöds är uppdelningen av SAP-programskiktet och DBMS-lagret i olika virtuella Azure-nätverk som inte är peer-kopplade till varandra. Vi rekommenderar att du separerar SAP-programskiktet och DBMS-lagret med hjälp av undernät i ett virtuellt Azure-nätverk i stället för att använda olika virtuella Azure-nätverk. Om du bestämmer dig för att inte följa rekommendationen och i stället separerar de två lagren i olika virtuella nätverk måste de två virtuella nätverken vara peer-kopplade. Tänk på att nätverkstrafik mellan två peerkopplade virtuella Azure-nätverk är föremål för överföringskostnader. Med den enorma datavolymen i många Terabyte som utbyts mellan SAP-programskiktet och DBMS-lagret kan betydande kostnader ackumuleras om SAP-programskiktet och DBMS-lagret är åtskilda mellan två peerkopplade virtuella Azure-nätverk.
Om du har distribuerat jumpbox- eller hanteringsdatorer i ett separat undernät kan du definiera flera virtuella nätverkskort (vNIC) för den virtuella HANA-datorn, där varje virtuellt nätverkskort har tilldelats till olika undernät. Med möjligheten att ha flera virtuella nätverkskort kan du konfigurera nätverkstrafikavgränsning om det behövs. Till exempel kan klienttrafik dirigeras via det primära virtuella nätverkskortet och administratörstrafiken dirigeras via ett andra virtuellt nätverkskort.
Du tilldelar också statiska privata IP-adresser som distribueras för båda virtuella nätverkskorten.
Kommentar
Du bör tilldela statiska IP-adresser via Azure till enskilda virtuella nätverkskort. Du bör inte tilldela statiska IP-adresser i gästoperativsystemet till ett virtuellt nätverkskort. Vissa Azure-tjänster som Azure Backup Service förlitar sig på att minst det primära virtuella nätverkskortet är inställt på DHCP och inte på statiska IP-adresser. Se även dokumentet Felsöka säkerhetskopiering av virtuella Azure-datorer. Om du behöver tilldela flera statiska IP-adresser till en virtuell dator måste du tilldela flera virtuella nätverkskort till en virtuell dator.
För distributioner som är varaktiga måste du dock skapa en nätverksarkitektur för virtuella datacenter i Azure. Den här arkitekturen rekommenderar att du separerar den Virtuella Azure-gatewayen som ansluter till en lokal plats i ett separat virtuellt Azure-nätverk. Det här separata virtuella nätverket ska vara värd för all trafik som lämnar antingen till lokalt eller till Internet. Med den här metoden kan du distribuera programvara för granskning och loggning av trafik som kommer in i det virtuella datacentret i Azure i det här separata virtuella hubbnätverket. Så du har ett virtuellt nätverk som är värd för alla program och konfigurationer som är relaterade till in- och utgående trafik till din Azure-distribution.
Artiklarna Azure Virtual Datacenter: A Network Perspective och Azure Virtual Datacenter och Enterprise Control Plane ger mer information om den virtuella datacentermetoden och relaterad Azure VNet-design.
Kommentar
Trafik som flödar mellan ett virtuellt hubbnätverk och eker-VNet med Azure VNet-peering medför ytterligare kostnader. Baserat på dessa kostnader kan du behöva överväga att göra kompromisser mellan att köra en strikt hubb- och ekernätverksdesign och köra flera Azure ExpressRoute-gatewayer som du ansluter till "ekrar" för att kringgå VNet-peering. Azure ExpressRoute-gatewayer medför dock även ytterligare kostnader . Du kan också stöta på ytterligare kostnader för programvara från tredje part som du använder för loggning, granskning och övervakning av nätverkstrafik. Beroende på kostnaderna för datautbyte via VNet-peering på ena sidan och kostnader som skapas av ytterligare Azure ExpressRoute-gatewayer och ytterligare programvarulicenser, kan du besluta om mikrosegmentering inom ett VNet genom att använda undernät som isoleringsenhet i stället för virtuella nätverk.
En översikt över de olika metoderna för att tilldela IP-adresser finns i IP-adresstyper och allokeringsmetoder i Azure.
För virtuella datorer som kör SAP HANA bör du arbeta med statiska IP-adresser tilldelade. Orsaken är att vissa konfigurationsattribut för HANA-referens-IP-adresser.
Azure Network Security Groups (NSG:er) används för att dirigera trafik som dirigeras till SAP HANA-instansen eller jumpboxen. NSG:er och slutligen programsäkerhetsgrupper är associerade med SAP HANA-undernätet och undernätet Hantering.
Om du vill distribuera SAP HANA i Azure utan plats-till-plats-anslutning vill du fortfarande skydda SAP HANA-instansen från det offentliga Internet och dölja den bakom en framåtriktad proxy. I det här grundläggande scenariot förlitar sig distributionen på Inbyggda DNS-tjänster i Azure för att matcha värdnamn. I en mer komplex distribution där offentliga IP-adresser används är inbyggda DNS-tjänster i Azure särskilt viktiga. Använd Azure NSG:er och Azure NVA:er för att styra, övervaka routningen från Internet till din Azure VNet-arkitektur i Azure. Följande bild visar ett grovt schema för att distribuera SAP HANA utan en plats-till-plats-anslutning i en hubb- och eker-VNet-arkitektur:
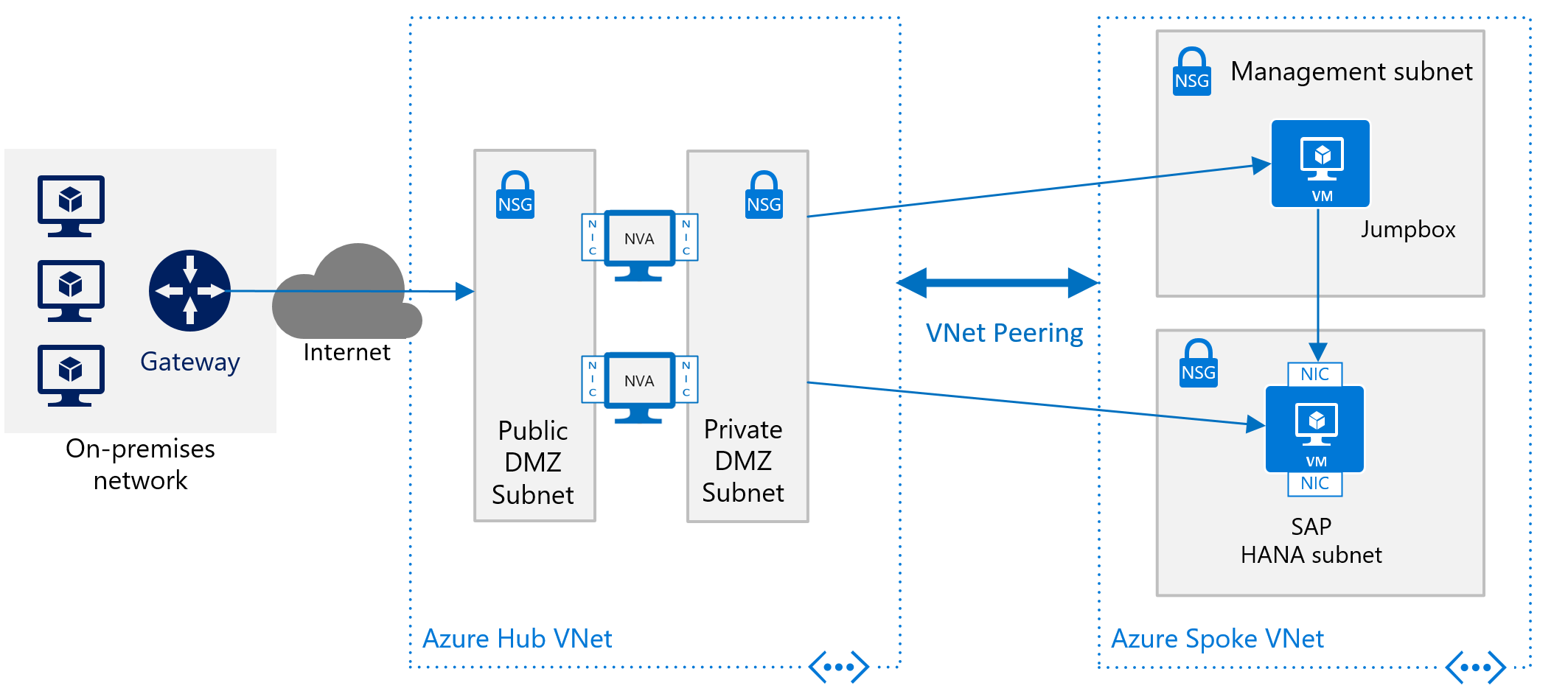
En annan beskrivning av hur du använder Azure NVA:er för att styra och övervaka åtkomst från Internet utan hubb- och eker-VNet-arkitektur finns i artikeln Distribuera virtuella nätverksinstallationer med hög tillgänglighet.
Alternativ för klockkälla på virtuella Azure-datorer
SAP HANA kräver tillförlitlig och korrekt tidsinformation för att prestera optimalt. Traditionellt använde virtuella Azure-datorer som körs på Azure hypervisor endast Hyper-V TSC-sidan som standardklockakälla. Tekniska framsteg inom maskinvara, värdoperativsystem och Linux-gästoperativsystemkärnor gjorde det möjligt att tillhandahålla "Invariant TSC" som ett klockkällalternativ på vissa SKU:er för virtuella Azure-datorer.
Hyper-V TSC-sidan (hyperv_clocksource_tsc_page) stöds på alla virtuella Azure-datorer som en klockkälla.
Om den underliggande maskinvaran, hypervisor- och gästoperativsystemets linux-kernel stöder Invariant TSC erbjuds tsc som tillgänglig och stöds klockkälla i gästoperativsystemet på virtuella Azure-datorer.
Konfigurera Azure-infrastruktur för SAP HANA-utskalning
Om du vill ta reda på vilka typer av virtuella Azure-datorer som är certifierade för antingen OLAP-utskalning eller S/4HANA-utskalning kan du läsa katalogen för SAP HANA-maskinvara. En bockmarkering i kolumnen "Klustring" anger utskalningsstöd. Programtyp anger om OLAP-utskalning eller S/4HANA-utskalning stöds. Mer information om noder som certifierats i utskalning finns i posten för en specifik VM SKU som anges i sap hana-maskinvarukatalogen.
De lägsta versionerna av operativsystemet för distribution av utskalningskonfigurationer på virtuella Azure-datorer kontrollerar du informationen om posterna i den specifika VM SKU som anges i SAP HANA-maskinvarukatalogen. En nod fungerar som huvudnod för en OLAP-utskalningskonfiguration med n-nod. De andra noderna upp till gränsen för certifieringen fungerar som arbetsnod. Fler väntelägesnoder räknas inte in i antalet certifierade noder
Kommentar
Utskalningsdistributioner av SAP HANA med väntelägesnoder för virtuella Azure-datorer är endast möjliga med hjälp av Azure NetApp Files-lagringen. Ingen annan SAP HANA-certifierad Azure Storage tillåter konfiguration av SAP HANA-väntelägesnoder
För /hana/shared rekommenderar vi användning av Azure NetApp Files eller Azure Files.
En typisk grundläggande design för en enskild nod i en utskalningskonfiguration, med /hana/shared distribuerad i Azure NetApp Files, ser ut så här:
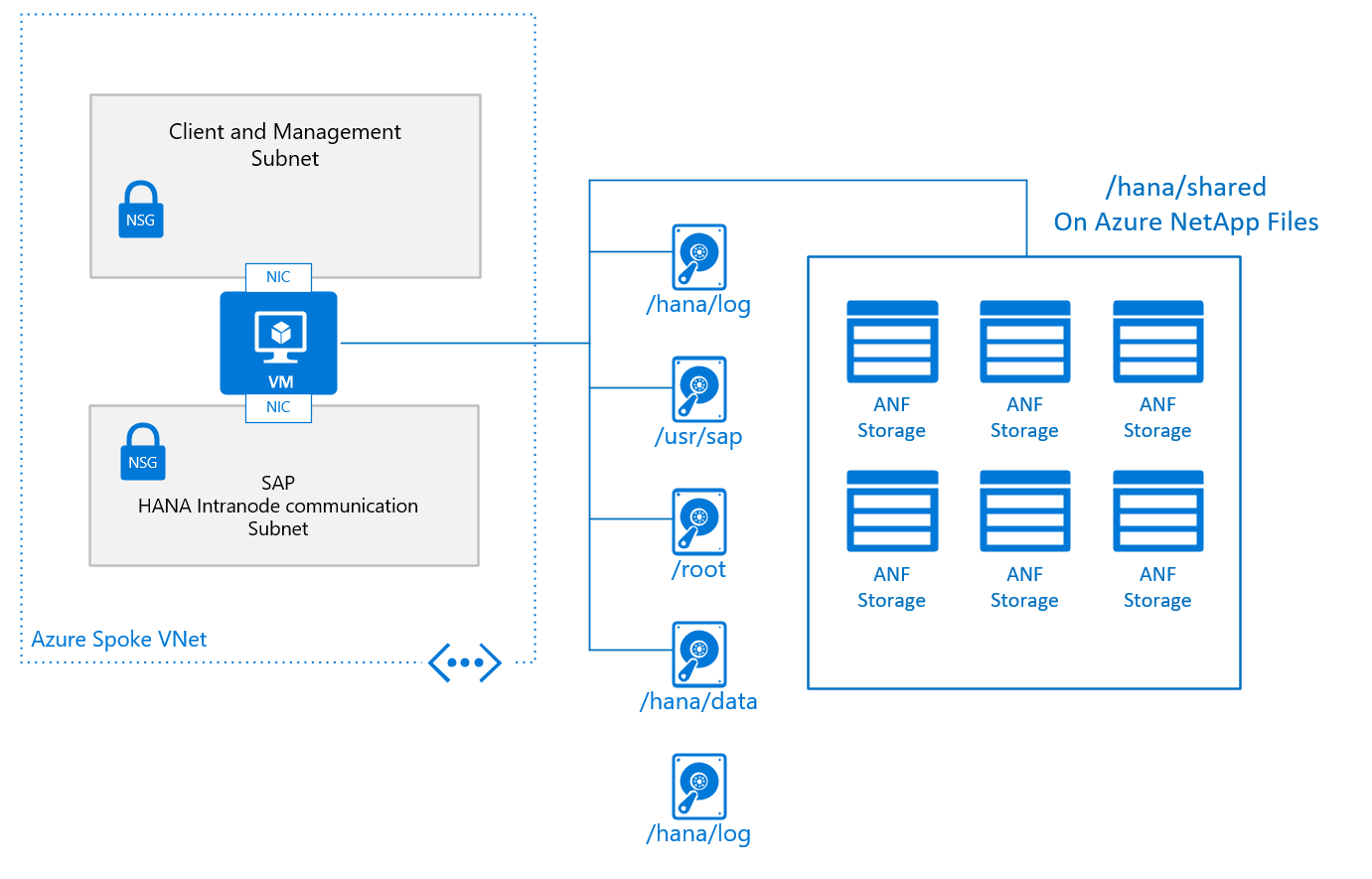
Den grundläggande konfigurationen av en VM-nod för SAP HANA-utskalning ser ut så här:
- För /hana/shared använder du den interna NFS-tjänsten som tillhandahålls via Azure NetApp Files eller Azure Files.
- Alla andra diskvolymer delas inte mellan de olika noderna och baseras inte på NFS. Installationskonfigurationer och steg för utskalning av HANA-installationer med icke-delade /hana/data och /hana/log tillhandahålls längre fram i det här dokumentet. För HANA-certifierad lagring som kan användas kan du läsa artikeln sap hana azure virtual machine storage configurations.
När du ändrar storlek på volymer eller diskar måste du kontrollera dokumentet SAP HANA TDI-lagringskrav för den storlek som krävs beroende på antalet arbetsnoder. Dokumentet släpper en formel som du måste tillämpa för att få den kapacitet som krävs för volymen
De andra designkriterierna som visas i grafiken för konfigurationen av en enskild nod för en skalbar virtuell SAP HANA-dator är det virtuella nätverket, eller bättre konfiguration av undernätet. SAP rekommenderar starkt en separation av klient-/programriktad trafik från kommunikationen mellan HANA-noderna. Som du ser i grafiken uppnås det här målet genom att ha två olika virtuella nätverkskort kopplade till den virtuella datorn. Båda virtuella nätverkskorten finns i olika undernät och har två olika IP-adresser. Sedan styr du trafikflödet med routningsregler med hjälp av NSG:er eller användardefinierade vägar.
Särskilt i Azure finns det inga metoder för att framtvinga tjänstkvalitet och kvoter på specifika virtuella nätverkskort. Därför öppnar inte separationen av klient-/programriktad och intranodkommunikation några möjligheter att prioritera en trafikström framför den andra. I stället förblir separationen ett säkerhetsmått för att avskärma kommunikationen mellan noder i utskalningskonfigurationerna.
Kommentar
SAP rekommenderar att du separerar nätverkstrafik till klient-/programsidan och intranodtrafik enligt beskrivningen i det här dokumentet. Därför rekommenderas att du placerar en arkitektur på plats, vilket visas i den senaste grafiken. Kontakta även säkerhets- och efterlevnadsteamet för krav som avviker från rekommendationen
Från nätverkssynpunkt skulle den minsta nödvändiga nätverksarkitekturen se ut så här:

Installera SAP HANA scale-out n Azure
När du installerar en skalbar SAP-konfiguration måste du utföra grova steg i:
- Distribuera ny eller anpassa en befintlig Azure VNet-infrastruktur
- Distribuera de nya virtuella datorerna med Azure Managed Premium Storage, Ultra-diskvolymer och/eller NFS-volymer baserat på ANF
-
- Anpassa nätverksroutning för att se till att till exempel kommunikation mellan noder mellan virtuella datorer inte dirigeras via en NVA.
- Installera SAP HANA-huvudnoden.
- Anpassa konfigurationsparametrarna för SAP HANA-huvudnoden
- Fortsätt med installationen av SAP HANA-arbetsnoderna
Installation av SAP HANA i utskalningskonfiguration
När infrastrukturen för den virtuella Azure-datorn distribueras och alla andra förberedelser är klara måste du installera SAP HANA-utskalningskonfigurationerna i följande steg:
- Installera SAP HANA-huvudnoden enligt SAP:s dokumentation
- När du använder Azure Premium Storage eller Ultra-disklagring med icke-delade diskar av
/hana/dataoch/hana/loglägger du till parameternbasepath_shared = noiglobal.inifilen. Med den här parametern kan SAP HANA köras i utskalning utan delade/hana/datavolymer och/hana/logvolymer mellan noderna. Information dokumenteras i SAP Note #2080991. Om du använder NFS-volymer baserat på ANF för /hana/data och /hana/log behöver du inte göra den här ändringen - Starta om SAP HANA-instansen efter den slutliga ändringen i parametern global.ini
- Lägg till fler arbetsnoder. Mer information finns i Lägga till värdar med kommandoradsgränssnittet. Ange det interna nätverket för SAP HANA-kommunikation mellan noder under installationen eller därefter med hjälp av till exempel den lokala hdblcmen. Mer detaljerad dokumentation finns i SAP Note #2183363.
Information om hur du konfigurerar ett SAP HANA-skalningssystem med en väntelägesnod finns i SUSE Linux-distributionsinstruktionerna eller Red Hat-distributionsinstruktionerna.
SAP HANA Dynamic Tiering 2.0 för virtuella Azure-datorer
Förutom SAP HANA-certifieringar på virtuella Datorer i Azure M-serien stöds även SAP HANA Dynamic Tiering 2.0 på Microsoft Azure. Mer information finns i Länkar till DT 2.0-dokumentation. Det finns ingen skillnad när det gäller att installera eller använda produkten. Du kan till exempel installera SAP HANA Cockpit på en virtuell Azure-dator. Det finns dock vissa obligatoriska krav, som beskrivs i följande avsnitt, för officiell support i Azure. I artikeln kommer förkortningen "DT 2.0" att användas i stället för det fullständiga namnet Dynamisk nivåindelning 2.0.
SAP HANA Dynamic Tiering 2.0 stöds inte av SAP BW eller S4HANA. Huvudsakliga användningsfall just nu är interna HANA-program.
Översikt
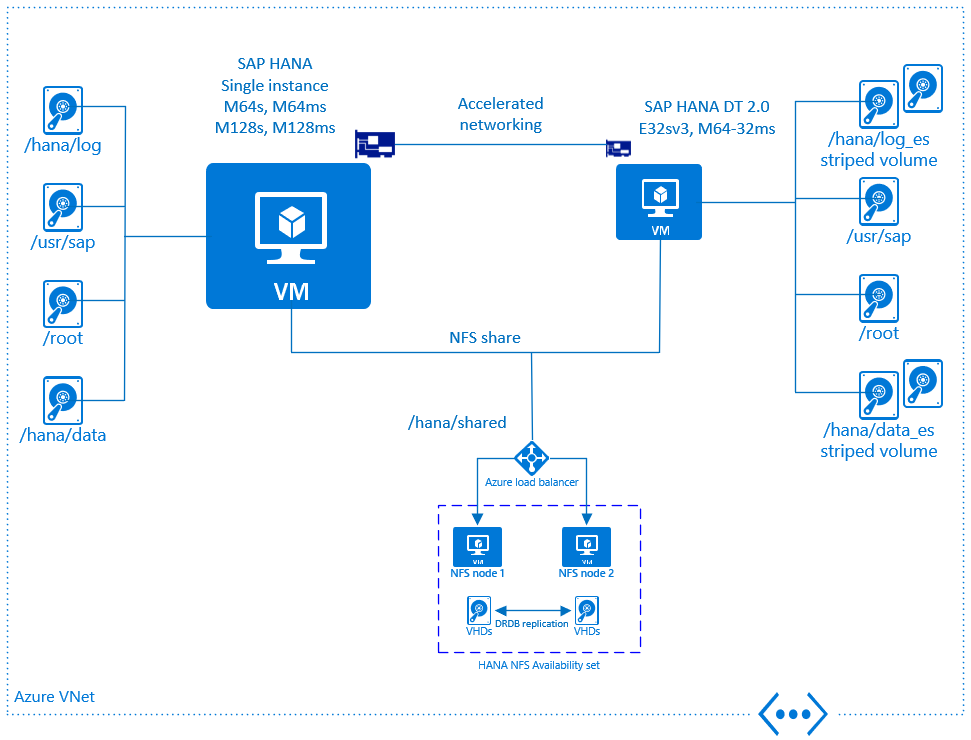
Bilden nedan ger en översikt över DT 2.0-support på Microsoft Azure. Det finns en uppsättning obligatoriska krav som måste följas för att uppfylla den officiella certifieringen:
- DT 2.0 måste installeras på en dedikerad virtuell Azure-dator. Den kanske inte körs på samma virtuella dator där SAP HANA körs
- Virtuella SAP HANA- och DT 2.0-datorer måste distribueras i samma virtuella Azure-nätverk
- De virtuella SAP HANA- och DT 2.0-datorerna måste distribueras med Azure-accelererat nätverk aktiverat
- Lagringstyp för de virtuella DT 2.0-datorerna måste vara Azure Premium Storage
- Flera Azure-diskar måste vara anslutna till den virtuella DT 2.0-datorn
- Det krävs för att skapa en programräd/randig volym (antingen via lvm eller mdadm) med striping över Azure-diskarna
Mer information kommer att förklaras i följande avsnitt.
Dedikerad virtuell Azure-dator för SAP HANA DT 2.0
På Azure IaaS stöds DT 2.0 endast på en dedikerad virtuell dator. Det är inte tillåtet att köra DT 2.0 på samma virtuella Azure-dator där HANA-instansen körs. Inledningsvis kan två typer av virtuella datorer användas för att köra SAP HANA DT 2.0:
- M64-32ms
- E32sv3
Mer information om beskrivningen av VM-typ finns i Storlekar på virtuella Azure-datorer – Minne
Med tanke på den grundläggande idén med DT 2.0, som handlar om att avlasta "varma" data för att spara kostnader, är det vettigt att använda motsvarande VM-storlekar. Det finns dock ingen strikt regel för möjliga kombinationer. Det beror på den specifika kundarbetsbelastningen.
Rekommenderade konfigurationer är:
| SAP HANA VM-typ | DT 2.0 VM-typ |
|---|---|
| M128ms | M64-32ms |
| M128s | M64-32ms |
| M64ms | E32sv3 |
| M64s | E32sv3 |
Alla kombinationer av SAP HANA-certifierade virtuella datorer i M-serien med DT 2.0-datorer som stöds (M64-32ms och E32sv3) är möjliga.
Azure-nätverk och SAP HANA DT 2.0
För att installera DT 2.0 på en dedikerad virtuell dator krävs nätverksdataflöde mellan den virtuella DT 2.0-datorn och den virtuella SAP HANA-datorn på minst 10 Gb. Därför är det obligatoriskt att placera alla virtuella datorer i samma virtuella Azure-nätverk och aktivera Azure-accelererat nätverk.
Se ytterligare information om Azure-accelererat nätverk Skapa en virtuell Azure-dator med accelererat nätverk med Azure CLI
VM Storage för SAP HANA DT 2.0
Enligt bästa praxis för DT 2.0 bör diskens I/O-dataflöde vara minst 50 MB/s per fysisk kärna.
Enligt specifikationerna för de två typerna av virtuella Azure-datorer, som stöds för DT 2.0, ser den maximala disk-I/O-dataflödesgränsen för den virtuella datorn ut så här:
- E32sv3: 768 MB/s (ej åtskilt) vilket innebär ett förhållande på 48 MB/sek per fysisk kärna
- M64-32ms: 1 000 MB/s (ej åtskilt) vilket innebär ett förhållande på 62,5 MB/sek per fysisk kärna
Du måste ansluta flera Azure-diskar till den virtuella DT 2.0-datorn och skapa en programräd (striping) på OS-nivå för att uppnå den maximala gränsen för diskdataflöde per virtuell dator. En enskild Azure-disk kan inte ange dataflödet för att nå den maximala VM-gränsen i det här avseendet. Azure Premium Storage är obligatoriskt för att köra DT 2.0.
- Information om tillgängliga Azure-disktyper finns på sidan Välj en disktyp för virtuella Azure IaaS-datorer – hanterade diskar
- Information om hur du skapar en programräd via mdadm finns på sidan Konfigurera programvaru-RAID på en virtuell Linux-dator
- Information om hur du konfigurerar LVM för att skapa en randig volym för maximalt dataflöde finns på sidan Konfigurera LVM på en virtuell dator som kör Linux
Beroende på storlekskrav finns det olika alternativ för att nå det maximala dataflödet för en virtuell dator. Här är möjliga diskkonfigurationer för datavolymer för varje typ av virtuell DT 2.0-dator för att uppnå den övre dataflödesgränsen för virtuella datorer. Den virtuella E32sv3-datorn bör betraktas som en startnivå för mindre arbetsbelastningar. Om det skulle visa sig att det inte är tillräckligt snabbt kan det vara nödvändigt att ändra storlek på den virtuella datorn till M64-32ms. Eftersom den virtuella M64-32ms-datorn har mycket minne kanske I/O-belastningen inte når gränsen, särskilt för läsintensiva arbetsbelastningar. Därför kan färre diskar i stripe-uppsättningen vara tillräckliga beroende på kundens specifika arbetsbelastning. Men för att vara på den säkra sidan valdes diskkonfigurationerna nedan för att garantera maximalt dataflöde:
| VM-SKU | Diskkonfiguration 1 | Diskkonfiguration 2 | Diskkonfiguration 3 | Diskkonfiguration 4 | Diskkonfiguration 5 |
|---|---|---|---|---|---|
| M64-32ms | 4 x P50 –> 16 TB | 4 x P40 –> 8 TB | 5 x P30 –> 5 TB | 7 x P20 –> 3,5 TB | 8 x P15 –> 2 TB |
| E32sv3 | 3 x P50 –> 12 TB | 3 x P40 –> 6 TB | 4 x P30 –> 4 TB | 5 x P20 –> 2,5 TB | 6 x P15 –> 1,5 TB |
Särskilt om arbetsbelastningen är läsintensiv kan det öka I/O-prestanda för att aktivera Azure-värdcachen "skrivskyddad" enligt rekommendationerna för datavolymerna i databasprogramvaran. För transaktionsloggen måste Azure-värddiskcachen vara "ingen".
När det gäller storleken på loggvolymen är en rekommenderad startpunkt en heuristik på 15 % av datastorleken. Du kan skapa loggvolymen genom att använda olika Typer av Azure-diskar beroende på kostnader och dataflödeskrav. För loggvolymen krävs ett högt I/O-dataflöde.
När du använder vm-typen M64-32ms är det obligatoriskt att aktivera skrivaccelerator. Azure Write Accelerator ger optimal svarstid för diskskrivning för transaktionsloggen (endast tillgänglig för M-serien). Det finns vissa objekt att tänka på, till exempel det maximala antalet diskar per vm-typ. Information om skrivningsaccelerator finns på sidan Med Azure Write Accelerator
Här följer några exempel på hur du ändrar storlek på loggvolymen:
| datavolymstorlek och disktyp | loggvolym och disktyp config 1 | loggvolym och disktyp config 2 |
|---|---|---|
| 4 x P50 –> 16 TB | 5 x P20 –> 2,5 TB | 3 x P30 –> 3 TB |
| 6 x P15 –> 1,5 TB | 4 x P6 –> 256 GB | 1 x P15 –> 256 GB |
Precis som för SAP HANA-utskalning måste katalogen /hana/shared delas mellan den virtuella SAP HANA-datorn och den virtuella DT 2.0-datorn. Samma arkitektur som för SAP HANA-utskalning med dedikerade virtuella datorer, som fungerar som en NFS-server med hög tillgänglighet rekommenderas. För att tillhandahålla en delad säkerhetskopieringsvolym kan den identiska designen användas. Men det är upp till kunden om ha skulle vara nödvändigt eller om det räcker att bara använda en dedikerad virtuell dator med tillräckligt med lagringskapacitet för att fungera som en säkerhetskopieringsserver.
Länkar till DT 2.0-dokumentation
- Installations- och uppdateringsguide för SAP HANA Dynamic Tiering
- Självstudier och resurser för dynamisk nivåindelning i SAP HANA
- SAP HANA Dynamic Tiering PoC
- Förbättringar av dynamisk nivåindelning för SAP HANA 2.0 SPS 02
Åtgärder för att distribuera SAP HANA på virtuella Azure-datorer
I följande avsnitt beskrivs några av de åtgärder som rör distribution av SAP HANA-system på virtuella Azure-datorer.
Säkerhetskopierings- och återställningsåtgärder på virtuella Azure-datorer
Följande dokument beskriver hur du säkerhetskopierar och återställer din SAP HANA-distribution:
- Översikt över SAP HANA-säkerhetskopiering
- SAP HANA-säkerhetskopiering på filnivå
- SAP HANA-lagringsögonblickstest
Starta och starta om virtuella datorer som innehåller SAP HANA
En framträdande funktion i det offentliga Azure-molnet är att du bara debiteras för dina databehandlingsminuter. När du till exempel stänger av en virtuell dator som kör SAP HANA debiteras du endast för lagringskostnaderna under den tiden. En annan funktion är tillgänglig när du anger statiska IP-adresser för dina virtuella datorer i den första distributionen. När du startar om en virtuell dator som har SAP HANA startas den virtuella datorn om med sina tidigare IP-adresser.
Använda SAProuter för SAP-fjärrsupport
Om du har en plats-till-plats-anslutning mellan dina lokala platser och Azure, och du kör SAP-komponenter, kör du förmodligen redan SAProuter. I det här fallet slutför du följande objekt för fjärrsupport:
- Underhålla den privata och statiska IP-adressen för den virtuella dator som är värd för SAP HANA i SAProuter-konfigurationen.
- Konfigurera NSG för det undernät som är värd för den virtuella HANA-datorn för att tillåta trafik via TCP/IP-port 3299.
Om du ansluter till Azure via Internet och du inte har någon SAP-router för den virtuella datorn med SAP HANA måste du installera komponenten. Installera SAProuter på en separat virtuell dator i undernätet Hantering. Följande bild visar ett grovt schema för distribution av SAP HANA utan plats-till-plats-anslutning och med SAProuter:
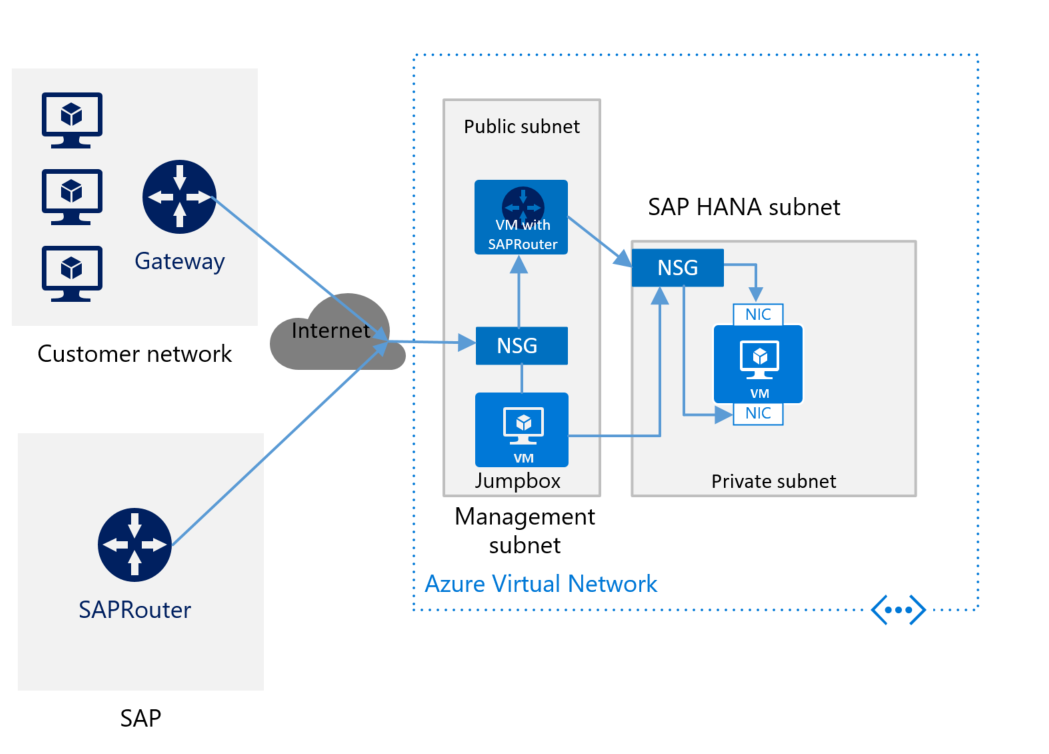
Se till att installera SAProuter på en separat virtuell dator och inte i den virtuella Jumpbox-datorn. Den separata virtuella datorn måste ha en statisk IP-adress. Om du vill ansluta DIN SAProuter till DEN SAProuter som hanteras av SAP kontaktar du SAP för en IP-adress. (SAProuter som hanteras av SAP är motsvarigheten till den SAProuter-instans som du installerar på den virtuella datorn.) Använd IP-adressen från SAP för att konfigurera din SAProuter-instans. I konfigurationsinställningarna är den enda nödvändiga porten TCP-port 3299.
Mer information om hur du konfigurerar och underhåller fjärrsupportanslutningar via SAProuter finns i SAP-dokumentationen.
Hög tillgänglighet med SAP HANA på inbyggda virtuella Azure-datorer
Om du kör SUSE Linux Enterprise Server eller Red Hat kan du upprätta ett Pacemaker-kluster med fäktningsenheter. Du kan använda enheterna för att konfigurera en SAP HANA-konfiguration som använder synkron replikering med HANA-systemreplikering och automatisk redundans. Mer information finns i avsnittet "nästa steg".
Nästa steg
Bekanta dig med artiklarna enligt listan
- Lagringskonfigurationer för virtuella SAP HANA Azure-datorer
- Distribuera ett SAP HANA-utskalningssystem med väntelägesnod på virtuella Azure-datorer med hjälp av Azure NetApp Files på SUSE Linux Enterprise Server
- Distribuera ett SAP HANA-utskalningssystem med väntelägesnod på virtuella Azure-datorer med hjälp av Azure NetApp Files på Red Hat Enterprise Linux
- Distribuera ett SAP HANA-utskalningssystem med HSR och Pacemaker på virtuella Azure-datorer på SUSE Linux Enterprise Server
- Distribuera ett SAP HANA-utskalningssystem med HSR och PAcemaker på virtuella Azure-datorer i Red Hat Enterprise Linux
- Hög tillgänglighet för SAP HANA på virtuella Azure-datorer på SUSE Linux Enterprise Server
- Hög tillgänglighet för SAP HANA på virtuella Azure-datorer på Red Hat Enterprise Linux