Konfigurera Pacemaker på Red Hat Enterprise Linux i Azure
I den här artikeln beskrivs hur du konfigurerar ett grundläggande Pacemaker-kluster på Red Hat Enterprise Server (RHEL). Anvisningarna omfattar RHEL 7, RHEL 8 och RHEL 9.
Förutsättningar
Läs följande SAP-anteckningar och artiklar först:
DOKUMENTATION om RHEL-hög tillgänglighet (HA)
- Konfigurera och hantera kluster med hög tillgänglighet.
- Supportprinciper för RHEL-kluster med hög tillgänglighet – sbd och fence_sbd.
- Supportprinciper för RHEL-kluster med hög tillgänglighet – fence_azure_arm.
- Kända begränsningar för programvaruemulerad vakthund.
- Utforska RHEL-komponenter med hög tillgänglighet – sbd och fence_sbd.
- Designvägledning för RHEL-kluster med hög tillgänglighet – sbd-överväganden.
- Överväganden vid införande av RHEL 8 – hög tillgänglighet och kluster
Azure-specifik RHEL-dokumentation
RHEL-dokumentation för SAP-erbjudanden
- Supportprinciper för RHEL-kluster med hög tillgänglighet – hantering av SAP S/4HANA i ett kluster.
- Konfigurera SAP S/4HANA ASCS/ERS med fristående Enqueue Server 2 (ENSA2) i Pacemaker.
- Konfigurera SAP HANA-systemreplikering i Pacemaker-kluster.
- Red Hat Enterprise Linux HA-lösning för SAP HANA-utskalning och systemreplikering.
Översikt
Viktigt!
Pacemakerkluster som sträcker sig över flera virtuella nätverk(VNet)/undernät omfattas inte av standardsupportprinciper.
Det finns två tillgängliga alternativ i Azure för att konfigurera fäktningen i ett pacemakerkluster för RHEL: Azure Fence Agent, som startar om en misslyckad nod via Azure-API:erna, eller så kan du använda SBD-enhet.
Viktigt!
I Azure använder RHEL-kluster med hög tillgänglighet med lagringsbaserad stängsel (fence_sbd) programvaruemulerad vakthund. Det är viktigt att granska kända begränsningar och supportprinciper för programvaruemulerade vakthundar för RHEL-kluster med hög tillgänglighet – sbd och fence_sbd när du väljer SBD som fäktningsmekanism.
Använda en SBD-enhet
Kommentar
Fäktningsmekanismen med SBD stöds på RHEL 8.8 och senare och RHEL 9.0 och senare.
Du kan konfigurera SBD-enheten med något av två alternativ:
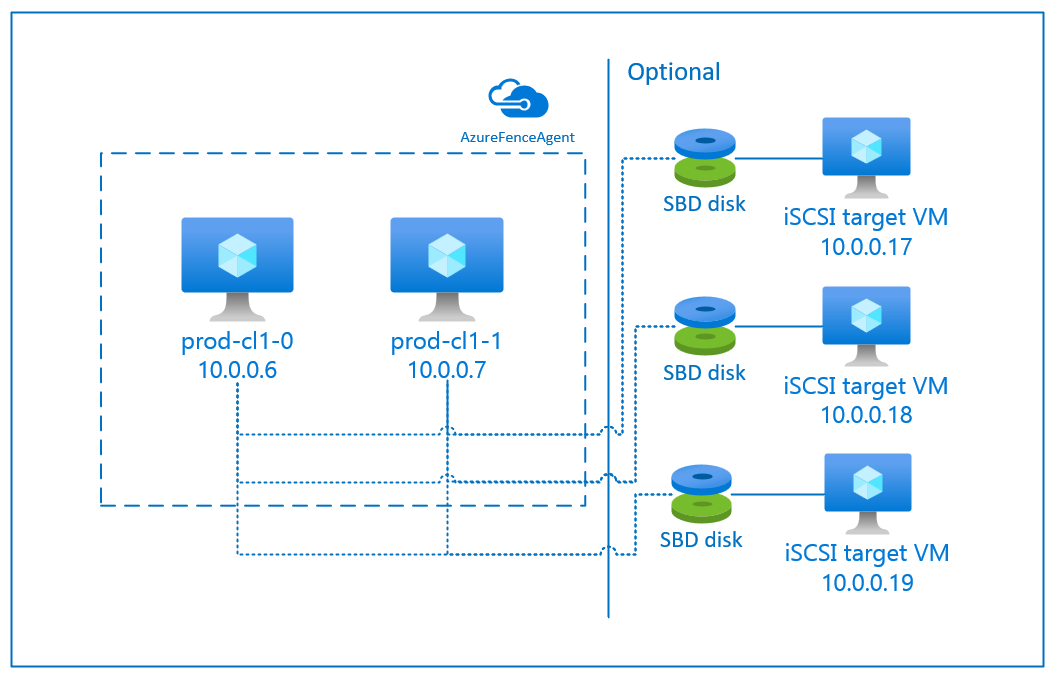
SBD med iSCSI-målserver
SBD-enheten kräver minst en ytterligare virtuell dator (VM) som fungerar som en iSCSI-målserver (Internet Small Compute System Interface) och tillhandahåller en SBD-enhet. Dessa iSCSI-målservrar kan dock delas med andra pacemakerkluster. Fördelen med att använda en SBD-enhet är att om du redan använder SBD-enheter lokalt behöver de inga ändringar i hur du använder pacemakerklustret.
Du kan använda upp till tre SBD-enheter för ett pacemakerkluster för att tillåta att en SBD-enhet blir otillgänglig (till exempel under os-korrigering av iSCSI-målservern). Om du vill använda mer än en SBD-enhet per pacemaker ska du distribuera flera iSCSI-målservrar och ansluta en SBD från varje iSCSI-målserver. Vi rekommenderar att du använder antingen en eller tre SBD-enheter. Pacemaker kan inte automatiskt avgränsa en klusternod om endast två SBD-enheter har konfigurerats och en av dem inte är tillgänglig. Om du vill kunna stänga när en iSCSI-målserver är nere måste du använda tre SBD-enheter och därför tre iSCSI-målservrar. Det är den mest motståndskraftiga konfigurationen när du använder SBD:er.
Viktigt!
När du planerar att distribuera och konfigurera Linux pacemaker-klusternoder och SBD-enheter ska du inte tillåta routning mellan dina virtuella datorer och de virtuella datorer som är värdar för SBD-enheterna att passera genom andra enheter, till exempel en virtuell nätverksinstallation (NVA).
Underhållshändelser och andra problem med NVA kan ha en negativ inverkan på stabiliteten och tillförlitligheten i den övergripande klusterkonfigurationen. Mer information finns i användardefinierade routningsregler.
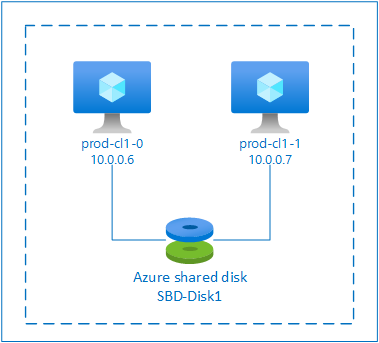
SBD med delad Azure-disk
För att konfigurera en SBD-enhet måste du koppla minst en Delad Azure-disk till alla virtuella datorer som ingår i pacemakerklustret. Fördelen med att SBD-enheten använder en delad Azure-disk är att du inte behöver distribuera och konfigurera ytterligare virtuella datorer.
Här följer några viktiga överväganden om SBD-enheter när du konfigurerar med azure shared disk:
- En Delad Azure-disk med Premium SSD stöds som en SBD-enhet.
- SBD-enheter som använder en delad Azure-disk stöds på RHEL 8.8 och senare.
- SBD-enheter som använder en Azure Premium-resursdisk stöds på lokalt redundant lagring (LRS) och zonredundant lagring (ZRS).
- Beroende på typen av distribution väljer du lämplig redundant lagring för en Delad Azure-disk som SBD-enhet.
- En SBD-enhet som använder LRS för en delad Azure Premium-disk (skuName – Premium_LRS) stöds endast med regional distribution som tillgänglighetsuppsättning.
- En SBD-enhet som använder ZRS för en delad Azure Premium-disk (skuName – Premium_ZRS) rekommenderas med zonindelad distribution som tillgänglighetszon eller skalningsuppsättning med FD=1.
- En ZRS för hanterad disk är för närvarande tillgänglig i de regioner som anges i dokumentet om regional tillgänglighet .
- Den Delade Azure-disk som du använder för SBD-enheter behöver inte vara stor. Värdet maxShares avgör hur många klusternoder som kan använda den delade disken. Du kan till exempel använda P1- eller P2-diskstorlekar för din SBD-enhet i kluster med två noder, till exempel SAP ASCS/ERS eller SAP HANA-uppskalning.
- För HANA-utskalning med HANA-systemreplikering (HSR) och pacemaker kan du använda en Delad Azure-disk för SBD-enheter i kluster med upp till fem noder per replikeringsplats på grund av den aktuella gränsen för maxShares.
- Vi rekommenderar inte att du ansluter en SBD-enhet med delad Azure-disk mellan pacemakerkluster.
- Om du använder flera SBD-enheter med delad Azure-disk kontrollerar du gränsen för ett maximalt antal datadiskar som kan anslutas till en virtuell dator.
- Mer information om begränsningar för delade Azure-diskar finns i avsnittet "Begränsningar" i dokumentationen om delade Azure-diskar.
Använda en Azure Fence-agent
Du kan konfigurera fäktning med hjälp av en Azure-stängselagent. Azure Fence-agenten kräver hanterade identiteter för de virtuella klusterdatorerna eller ett tjänsthuvudnamn eller en hanterad systemidentitet (MSI) som lyckas starta om misslyckade noder via Azure-API:er. Azure Fence-agenten kräver inte distribution av ytterligare virtuella datorer.
SBD med en iSCSI-målserver
Följ anvisningarna i nästa avsnitt om du vill använda en SBD-enhet som använder en iSCSI-målserver för stängsel.
Konfigurera iSCSI-målservern
Du måste först skapa virtuella iSCSI-måldatorer. Du kan dela iSCSI-målservrar med flera pacemakerkluster.
Distribuera virtuella datorer som körs på RHEL OS-version som stöds och anslut till dem via SSH. De virtuella datorerna behöver inte vara av stor storlek. Vm-storlekar som Standard_E2s_v3 eller Standard_D2s_v3 räcker. Se till att använda Premium Storage för OS-disken.
Det är inte nödvändigt att använda RHEL för SAP med HA och Update Services, eller RHEL för SAP Apps OS-avbildning för iSCSI-målservern. En STANDARD-RHEL OS-avbildning kan användas i stället. Tänk dock på att supportens livscykel varierar mellan olika os-produktversioner.
Kör följande kommandon på alla virtuella iSCSI-måldatorer.
Uppdatera RHEL.
sudo yum -y updateKommentar
Du kan behöva starta om noden när du har uppgraderat eller uppdaterat operativsystemet.
Installera iSCSI-målpaketet.
sudo yum install targetcliStarta och konfigurera målet så att det startar vid start.
sudo systemctl start target sudo systemctl enable targetÖppna porten
3260i brandväggensudo firewall-cmd --add-port=3260/tcp --permanent sudo firewall-cmd --add-port=3260/tcp
Skapa en iSCSI-enhet på iSCSI-målservern
Om du vill skapa iSCSI-diskarna för dina SAP-systemkluster kör du följande kommandon på varje virtuell iSCSI-måldator. Exemplet illustrerar skapandet av SBD-enheter för flera kluster, vilket visar användningen av en enda iSCSI-målserver för flera kluster. SBD-enheten är konfigurerad på OS-disken, så se till att det finns tillräckligt med utrymme.
- ascsnw1: Representerar ASCS/ERS-klustret i NW1.
- dbhn1: Representerar databasklustret för HN1.
- sap-cl1 och sap-cl2: Värdnamn för NW1 ASCS/ERS-klusternoderna.
- hn1-db-0 och hn1-db-1: Värdnamn för databasklusternoderna.
I följande instruktioner ändrar du kommandot med dina specifika värdnamn och SID:er efter behov.
Skapa rotmappen för alla SBD-enheter.
sudo mkdir /sbdSkapa SBD-enheten för ASCS/ERS-servrarna i systemet NW1.
sudo targetcli backstores/fileio create sbdascsnw1 /sbd/sbdascsnw1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.ascsnw1.local:ascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/luns/ create /backstores/fileio/sbdascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl1.local:sap-cl1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl2.local:sap-cl2Skapa SBD-enheten för databasklustret i systemet HN1.
sudo targetcli backstores/fileio create sbddbhn1 /sbd/sbddbhn1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.dbhn1.local:dbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/luns/ create /backstores/fileio/sbddbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-0.local:hn1-db-0 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-1.local:hn1-db-1Spara targetcli-konfigurationen.
sudo targetcli saveconfigKontrollera att allt har konfigurerats korrekt
sudo targetcli ls o- / ......................................................................................................................... [...] o- backstores .............................................................................................................. [...] | o- block .................................................................................................. [Storage Objects: 0] | o- fileio ................................................................................................. [Storage Objects: 2] | | o- sbdascsnw1 ............................................................... [/sbd/sbdascsnw1 (50.0MiB) write-thru activated] | | | o- alua ................................................................................................... [ALUA Groups: 1] | | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | | o- sbddbhn1 ................................................................... [/sbd/sbddbhn1 (50.0MiB) write-thru activated] | | o- alua ................................................................................................... [ALUA Groups: 1] | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | o- pscsi .................................................................................................. [Storage Objects: 0] | o- ramdisk ................................................................................................ [Storage Objects: 0] o- iscsi ............................................................................................................ [Targets: 2] | o- iqn.2006-04.dbhn1.local:dbhn1 ..................................................................................... [TPGs: 1] | | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | | o- acls .......................................................................................................... [ACLs: 2] | | | o- iqn.2006-04.hn1-db-0.local:hn1-db-0 .................................................................. [Mapped LUNs: 1] | | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | | o- iqn.2006-04.hn1-db-1.local:hn1-db-1 .................................................................. [Mapped LUNs: 1] | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | o- luns .......................................................................................................... [LUNs: 1] | | | o- lun0 ............................................................. [fileio/sbddbhn1 (/sbd/sbddbhn1) (default_tg_pt_gp)] | | o- portals .................................................................................................... [Portals: 1] | | o- 0.0.0.0:3260 ..................................................................................................... [OK] | o- iqn.2006-04.ascsnw1.local:ascsnw1 ................................................................................. [TPGs: 1] | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | o- acls .......................................................................................................... [ACLs: 2] | | o- iqn.2006-04.sap-cl1.local:sap-cl1 .................................................................... [Mapped LUNs: 1] | | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | | o- iqn.2006-04.sap-cl2.local:sap-cl2 .................................................................... [Mapped LUNs: 1] | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | o- luns .......................................................................................................... [LUNs: 1] | | o- lun0 ......................................................... [fileio/sbdascsnw1 (/sbd/sbdascsnw1) (default_tg_pt_gp)] | o- portals .................................................................................................... [Portals: 1] | o- 0.0.0.0:3260 ..................................................................................................... [OK] o- loopback ......................................................................................................... [Targets: 0]
Konfigurera ISCSI-målserverns SBD-enhet
[A]: Gäller för alla noder. [1]: Gäller endast för nod 1. [2]: Gäller endast för nod 2.
På klusternoderna ansluter och identifierar du iSCSI-enheten som skapades i det tidigare avsnittet. Kör följande kommandon på noderna i det nya kluster som du vill skapa.
[A] Installera eller uppdatera iSCSI-initierare på alla klusternoder.
sudo yum install -y iscsi-initiator-utils[A] Installera kluster- och SBD-paket på alla klusternoder.
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] Aktivera iSCSI-tjänsten.
sudo systemctl enable iscsid iscsi[1] Ändra initierarens namn på den första noden i klustret.
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl1.local:sap-cl1[2] Ändra initierarnamnet på den andra noden i klustret.
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl2.local:sap-cl2[A] Starta om iSCSI-tjänsten för att tillämpa ändringarna.
sudo systemctl restart iscsid sudo systemctl restart iscsi[A] Anslut iSCSI-enheterna. I följande exempel är 10.0.0.17 IP-adressen för iSCSI-målservern och 3260 är standardporten. Målnamnet
iqn.2006-04.ascsnw1.local:ascsnw1visas när du kör det första kommandotiscsiadm -m discovery.sudo iscsiadm -m discovery --type=st --portal=10.0.0.17:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.17:3260 sudo iscsiadm -m node -p 10.0.0.17:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Om du använder flera SBD-enheter ansluter du också till den andra iSCSI-målservern.
sudo iscsiadm -m discovery --type=st --portal=10.0.0.18:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.18:3260 sudo iscsiadm -m node -p 10.0.0.18:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Om du använder flera SBD-enheter ansluter du också till den tredje iSCSI-målservern.
sudo iscsiadm -m discovery --type=st --portal=10.0.0.19:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.19:3260 sudo iscsiadm -m node -p 10.0.0.19:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Kontrollera att iSCSI-enheterna är tillgängliga och anteckna enhetsnamnet. I följande exempel identifieras tre iSCSI-enheter genom att noden ansluts till tre iSCSI-målservrar.
lsscsi [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sde [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdb [1:0:0:2] disk Msft Virtual Disk 1.0 /dev/sdc [1:0:0:3] disk Msft Virtual Disk 1.0 /dev/sdd [2:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdf [3:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdh [4:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdg[A] Hämta ID:t för iSCSI-enheterna.
ls -l /dev/disk/by-id/scsi-* | grep -i sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf ls -l /dev/disk/by-id/scsi-* | grep -i sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh ls -l /dev/disk/by-id/scsi-* | grep -i sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdgKommandot visar tre enhets-ID:n för varje SBD-enhet. Vi rekommenderar att du använder det ID som börjar med scsi-3. I föregående exempel är ID:na:
- /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2
- /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d
- /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65
[1] Skapa SBD-enheten.
Använd enhets-ID:t för iSCSI-enheterna för att skapa de nya SBD-enheterna på den första klusternoden.
sudo sbd -d /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -1 60 -4 120 createSkapa även den andra och tredje SBD-enheten om du vill använda mer än en.
sudo sbd -d /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -1 60 -4 120 create sudo sbd -d /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -1 60 -4 120 create
[A] Anpassa SBD-konfigurationen
Öppna konfigurationsfilen för SBD.
sudo vi /etc/sysconfig/sbdÄndra egenskapen för SBD-enheten, aktivera pacemakerintegrering och ändra startläget för SBD.
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2;/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d;/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] SBD_DELAY_START=yes [...]
[A] Kör följande kommando för att läsa in modulen
softdog.modprobe softdog[A] Kör följande kommando för att säkerställa
softdogatt det läses in automatiskt efter en omstart av noden.echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-load[A] Tidsgränsvärdet för SBD-tjänsten är inställt på 90 s som standard. Men om värdet
SBD_DELAY_STARTär inställt påyeskommer SBD-tjänsten att fördröja starten till efter tidsgränsenmsgwait. Därför bör tidsgränsvärdet för SBD-tjänsten överskrida tidsgränsenmsgwaitnärSBD_DELAY_STARTär aktiverat.sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=144" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=2min 24s # TimeoutStopUSec=2min 24s
SBD med en delad Azure-disk
Det här avsnittet gäller endast om du vill använda en SBD-enhet med en delad Azure-disk.
Konfigurera en delad Azure-disk med PowerShell
Om du vill skapa och ansluta en delad Azure-disk med PowerShell kör du följande instruktion. Om du vill distribuera resurser med hjälp av Azure CLI eller Azure Portal kan du även läsa Distribuera en ZRS-disk.
$ResourceGroup = "MyResourceGroup"
$Location = "MyAzureRegion"
$DiskSizeInGB = 4
$DiskName = "SBD-disk1"
$ShareNodes = 2
$LRSSkuName = "Premium_LRS"
$ZRSSkuName = "Premium_ZRS"
$vmNames = @("prod-cl1-0", "prod-cl1-1") # VMs to attach the disk
# ZRS Azure shared disk: Configure an Azure shared disk with ZRS for a premium shared disk
$zrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $ZRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$zrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $zrsDiskConfig
# Attach ZRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $zrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
# LRS Azure shared disk: Configure an Azure shared disk with LRS for a premium shared disk
$lrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $LRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$lrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $lrsDiskConfig
# Attach LRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $lrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
Konfigurera en SBD-enhet med delad Azure-disk
[A] Installera kluster- och SBD-paket på alla klusternoder.
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] Kontrollera att den anslutna disken är tillgänglig.
lsblk # NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT # sda 8:0 0 4G 0 disk # sdb 8:16 0 64G 0 disk # ├─sdb1 8:17 0 500M 0 part /boot # ├─sdb2 8:18 0 63G 0 part # │ ├─rootvg-tmplv 253:0 0 2G 0 lvm /tmp # │ ├─rootvg-usrlv 253:1 0 10G 0 lvm /usr # │ ├─rootvg-homelv 253:2 0 1G 0 lvm /home # │ ├─rootvg-varlv 253:3 0 8G 0 lvm /var # │ └─rootvg-rootlv 253:4 0 2G 0 lvm / # ├─sdb14 8:30 0 4M 0 part # └─sdb15 8:31 0 495M 0 part /boot/efi # sr0 11:0 1 1024M 0 rom lsscsi # [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sdb # [0:0:0:2] cd/dvd Msft Virtual DVD-ROM 1.0 /dev/sr0 # [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda # [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdc[A] Hämta enhets-ID:t för den anslutna delade disken.
ls -l /dev/disk/by-id/scsi-* | grep -i sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-14d534654202020200792c2f5cc7ef14b8a7355cb3cef0107 -> ../../sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -> ../../sdaKommandolistans enhets-ID för den anslutna delade disken. Vi rekommenderar att du använder det ID som börjar med scsi-3. I det här exemplet är ID:t /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107.
[1] Skapa SBD-enheten
# Use the device ID from step 3 to create the new SBD device on the first cluster node sudo sbd -d /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -1 60 -4 120 create[A] Anpassa SBD-konfigurationen
Öppna konfigurationsfilen för SBD.
sudo vi /etc/sysconfig/sbdÄndra egenskapen för SBD-enheten, aktivera pacemakerintegrering och ändra startläget för SBD
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] SBD_DELAY_START=yes [...]
[A] Kör följande kommando för att läsa in modulen
softdog.modprobe softdog[A] Kör följande kommando för att säkerställa
softdogatt det läses in automatiskt efter en omstart av noden.echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-load[A] Tidsgränsvärdet för SBD-tjänsten är inställt på 90 sekunder som standard. Men om värdet
SBD_DELAY_STARTär inställt påyeskommer SBD-tjänsten att fördröja starten till efter tidsgränsenmsgwait. Därför bör tidsgränsvärdet för SBD-tjänsten överskrida tidsgränsenmsgwaitnärSBD_DELAY_STARTär aktiverat.sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=144" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=2min 24s # TimeoutStopUSec=2min 24s
Konfiguration av Azure Fence-agent
Fäktningsenheten använder antingen en hanterad identitet för Azure-resursen eller ett huvudnamn för tjänsten för att auktorisera mot Azure. Beroende på identitetshanteringsmetoden följer du lämpliga procedurer -
Konfigurera identitetshantering
Använd hanterad identitet eller tjänstens huvudnamn.
Skapa en hanterad identitet (MSI) genom att skapa en systemtilldelad hanterad identitet för varje virtuell dator i klustret. Om det redan finns en systemtilldelad hanterad identitet används den. Använd inte användartilldelade hanterade identiteter med Pacemaker just nu. En stängselenhet, baserad på hanterad identitet, stöds på RHEL 7.9 och RHEL 8.x/RHEL 9.x.
Skapa en anpassad roll för stängselagenten
Både den hanterade identiteten och tjänstens huvudnamn har inte behörighet att komma åt dina Azure-resurser som standard. Du måste ge den hanterade identiteten eller tjänstens huvudnamn behörighet att starta och stoppa (stänga av) alla virtuella datorer i klustret. Om du inte redan har skapat den anpassade rollen kan du skapa den med hjälp av PowerShell eller Azure CLI.
Använd följande innehåll för indatafilen. Du måste anpassa innehållet till dina prenumerationer, dvs. ersätt
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxochyyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyymed ID:t för din prenumeration. Om du bara har en prenumeration tar du bort den andra posten iAssignableScopes.{ "Name": "Linux Fence Agent Role", "description": "Allows to power-off and start virtual machines", "assignableScopes": [ "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "/subscriptions/yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy" ], "actions": [ "Microsoft.Compute/*/read", "Microsoft.Compute/virtualMachines/powerOff/action", "Microsoft.Compute/virtualMachines/start/action" ], "notActions": [], "dataActions": [], "notDataActions": [] }Tilldela den anpassade rollen
Använd hanterad identitet eller tjänstens huvudnamn.
Tilldela den anpassade roll
Linux Fence Agent Rolesom skapades i det senaste avsnittet till varje hanterad identitet för de virtuella klusterdatorerna. Varje systemtilldelad hanterad identitet för virtuella datorer behöver rollen tilldelad för varje kluster-VM:s resurs. Mer information finns i Tilldela en hanterad identitet åtkomst till en resurs med hjälp av Azure Portal. Kontrollera att varje virtuell dators rolltilldelning för hanterad identitet innehåller alla virtuella klusterdatorer.Viktigt!
Tänk på att tilldelning och borttagning av auktorisering med hanterade identiteter kan fördröjas tills det börjar gälla.
Klusterinstallation
Skillnader i kommandona eller konfigurationen mellan RHEL 7 och RHEL 8/RHEL 9 markeras i dokumentet.
[A] Installera RHEL HA-tillägget.
sudo yum install -y pcs pacemaker nmap-ncat[A] Installera resursagenterna för molndistribution på RHEL 9.x.
sudo yum install -y resource-agents-cloud[A] Installera paketet fence-agents om du använder en fäktningsenhet baserat på Azure-stängselagenten.
sudo yum install -y fence-agents-azure-armViktigt!
Vi rekommenderar följande versioner av Azure Fence-agenten (eller senare) för kunder som vill använda hanterade identiteter för Azure-resurser i stället för tjänstens huvudnamn för stängselagenten:
- RHEL 8.4: fence-agents-4.2.1-54.el8.
- RHEL 8.2: fence-agents-4.2.1-41.el8_2.4
- RHEL 8.1: fence-agents-4.2.1-30.el8_1.4
- RHEL 7.9: fence-agents-4.2.1-41.el7_9.4.
Viktigt!
På RHEL 9 rekommenderar vi följande paketversioner (eller senare) för att undvika problem med Azure Fence-agenten:
- fence-agents-4.10.0-20.el9_0.7
- fence-agents-common-4.10.0-20.el9_0.6
- ha-cloud-support-4.10.0-20.el9_0.6.x86_64.rpm
Kontrollera versionen av Azure Fence-agenten. Om det behövs uppdaterar du den till den lägsta version som krävs eller senare.
# Check the version of the Azure Fence Agent sudo yum info fence-agents-azure-armViktigt!
Om du behöver uppdatera Azure Fence-agenten, och om du använder en anpassad roll, måste du uppdatera den anpassade rollen så att den inkluderar åtgärden powerOff. Mer information finns i Skapa en anpassad roll för stängselagenten.
[A] Konfigurera värdnamnsmatchning.
Du kan antingen använda en DNS-server eller ändra
/etc/hostsfilen på alla noder. Det här exemplet visar hur du/etc/hostsanvänder filen. Ersätt IP-adressen och värdnamnet i följande kommandon.Viktigt!
Om du använder värdnamn i klusterkonfigurationen är det viktigt att ha tillförlitlig värdnamnsmatchning. Klusterkommunikationen misslyckas om namnen inte är tillgängliga, vilket kan leda till fördröjningar vid klusterredundans.
Fördelen med att använda
/etc/hostsär att klustret blir oberoende av DNS, vilket också kan vara en enskild felpunkt.sudo vi /etc/hostsInfoga följande rader i
/etc/hosts. Ändra IP-adressen och värdnamnet så att de matchar din miljö.# IP address of the first cluster node 10.0.0.6 prod-cl1-0 # IP address of the second cluster node 10.0.0.7 prod-cl1-1[A] Ändra
haclusterlösenordet till samma lösenord.sudo passwd hacluster[A] Lägg till brandväggsregler för Pacemaker.
Lägg till följande brandväggsregler för all klusterkommunikation mellan klusternoderna.
sudo firewall-cmd --add-service=high-availability --permanent sudo firewall-cmd --add-service=high-availability[A] Aktivera grundläggande klustertjänster.
Kör följande kommandon för att aktivera Pacemaker-tjänsten och starta den.
sudo systemctl start pcsd.service sudo systemctl enable pcsd.service[1] Skapa ett Pacemaker-kluster.
Kör följande kommandon för att autentisera noderna och skapa klustret. Ange token till 30000 för att tillåta minnesbevarande underhåll. Mer information finns i den här artikeln för Linux.
Om du skapar ett kluster på RHEL 7.x använder du följande kommandon:
sudo pcs cluster auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup --name nw1-azr prod-cl1-0 prod-cl1-1 --token 30000 sudo pcs cluster start --allOm du skapar ett kluster på RHEL 8.x/RHEL 9.x använder du följande kommandon:
sudo pcs host auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup nw1-azr prod-cl1-0 prod-cl1-1 totem token=30000 sudo pcs cluster start --allKontrollera klusterstatusen genom att köra följande kommando:
# Run the following command until the status of both nodes is online sudo pcs status # Cluster name: nw1-azr # WARNING: no stonith devices and stonith-enabled is not false # Stack: corosync # Current DC: prod-cl1-1 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum # Last updated: Fri Aug 17 09:18:24 2018 # Last change: Fri Aug 17 09:17:46 2018 by hacluster via crmd on prod-cl1-1 # # 2 nodes configured # 0 resources configured # # Online: [ prod-cl1-0 prod-cl1-1 ] # # No resources # # Daemon Status: # corosync: active/disabled # pacemaker: active/disabled # pcsd: active/enabled[A] Ange förväntade röster.
# Check the quorum votes pcs quorum status # If the quorum votes are not set to 2, execute the next command sudo pcs quorum expected-votes 2Dricks
Om du skapar ett kluster med flera noder, dvs. ett kluster med fler än två noder, anger du inte rösterna till 2.
[1] Tillåt samtidiga stängselåtgärder.
sudo pcs property set concurrent-fencing=true
Skapa en fäktningsenhet i Pacemaker-klustret
Dricks
- Om du vill undvika stängseltävlingar i ett pacemakerkluster med två noder kan du konfigurera klusteregenskapen
priority-fencing-delay. Den här egenskapen medför ytterligare fördröjning vid stängsel av en nod som har högre total resursprioritet när ett scenario med delad hjärna inträffar. Mer information finns i Can Pacemaker fence the cluster node with the fewest running resources?. - Egenskapen
priority-fencing-delaygäller för Pacemaker version 2.0.4-6.el8 eller senare och i ett kluster med två noder. Om du konfigurerar klusteregenskapenpriority-fencing-delaybehöver du inte ange egenskapenpcmk_delay_max. Men om pacemakerversionen är mindre än 2.0.4-6.el8 måste du angepcmk_delay_maxegenskapen. - Anvisningar om hur du anger klusteregenskapen
priority-fencing-delayfinns i respektive SAP ASCS/ERS- och SAP HANA-uppskalnings-HA-dokument.
Baserat på den valda fäktningsmekanismen följer du bara ett avsnitt för relevanta instruktioner: SBD som fäktningsenhet eller Azure-stängselagent som fäktningsenhet.
SBD som fäktningsenhet
[A] Aktivera SBD-tjänsten
sudo systemctl enable sbd[1] Kör följande kommandon för den SBD-enhet som konfigurerats med iSCSI-målservrar eller en delad Azure-disk.
sudo pcs property set stonith-timeout=144 sudo pcs property set stonith-enabled=true # Replace the device IDs with your device ID. pcs stonith create sbd fence_sbd \ devices=/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2,/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d,/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 \ op monitor interval=600 timeout=15[1] Starta om klustret
sudo pcs cluster stop --all # It would take time to start the cluster as "SBD_DELAY_START" is set to "yes" sudo pcs cluster start --allKommentar
Om du får följande fel när du startar pacemakerklustret kan du bortse från meddelandet. Du kan också starta klustret med kommandot
pcs cluster start --all --request-timeout 140.Fel: Det går inte att starta alla noder node1/node2: Det går inte att ansluta till node1/node2, kontrollera om pcsd körs där eller prova att ställa in högre timeout med
--request-timeoutalternativet (Tidsgränsen uppnåddes efter 6 000 millisekunder med 0 mottagna byte)
Azure Fence-agent som stängselenhet
[1] När du har tilldelat roller till båda klusternoderna kan du konfigurera fäktningsenheterna i klustret.
sudo pcs property set stonith-timeout=900 sudo pcs property set stonith-enabled=true[1] Kör lämpligt kommando beroende på om du använder en hanterad identitet eller ett huvudnamn för tjänsten för Azure Fence-agenten.
Kommentar
När du använder Azure Government-molnet måste du ange
cloud=ett alternativ när du konfigurerar stängselagenten. Till exempelcloud=usgovför Azure US Government-molnet. Mer information om RedHat-stöd i Azure Government-molnet finns i Supportprinciper för RHEL-kluster med hög tillgänglighet – Microsoft Azure Virtual Machines som klustermedlemmar.Dricks
Alternativet
pcmk_host_mapkrävs endast i kommandot om RHEL-värdnamnen och namnen på den virtuella Azure-datorn inte är identiska. Ange mappningen i formatet hostname:vm-name. Mer information finns i Vilket format ska jag använda för att ange nodmappningar till fäktningsenheter i pcmk_host_map?.För RHEL 7.x använder du följande kommando för att konfigurera stängselenheten:
sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ op monitor interval=3600För RHEL 8.x/9.x använder du följande kommando för att konfigurera stängselenheten:
# Run following command if you are setting up fence agent on (two-node cluster and pacemaker version greater than 2.0.4-6.el8) OR (HANA scale out) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 \ op monitor interval=3600 # Run following command if you are setting up fence agent on (two-node cluster and pacemaker version less than 2.0.4-6.el8) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ op monitor interval=3600
Om du använder en fäktningsenhet baserat på tjänstens huvudnamnskonfiguration läser du Ändra från SPN till MSI för Pacemaker-kluster med hjälp av Azure-stängsel och lär dig hur du konverterar till konfiguration av hanterad identitet.
Övervaknings- och fäktningsåtgärderna deserialiseras. Om det finns en övervakningsåtgärd som körs längre och samtidiga fäktningshändelser blir det därför ingen fördröjning i klusterredundansväxlingen eftersom övervakningsåtgärden redan körs.
Dricks
Azure Fence-agenten kräver utgående anslutning till offentliga slutpunkter. Mer information och möjliga lösningar finns i Offentlig slutpunktsanslutning för virtuella datorer med standard-ILB.
Konfigurera Pacemaker för schemalagda Händelser i Azure
Azure erbjuder schemalagda händelser. Schemalagda händelser skickas via metadatatjänsten och ger tid för programmet att förbereda sig för sådana händelser.
Pacemaker-resursagenten azure-events-az övervakar schemalagda Azure-händelser. Om händelser identifieras och resursagenten fastställer att en annan klusternod är tillgänglig, anger den ett klusterhälsoattribut.
När klustrets hälsoattribut har angetts för en nod, utlöses platsbegränsningen och alla resurser med namn som inte börjar med health- migreras bort från noden med den schemalagda händelsen. När den berörda klusternoden är fri från att köra klusterresurser bekräftas den schemalagda händelsen och kan utföra åtgärden, till exempel en omstart.
[A] Kontrollera att paketet för agenten
azure-events-azredan är installerat och uppdaterat.RHEL 8.x: sudo dnf info resource-agents RHEL 9.x: sudo dnf info resource-agents-cloudLägsta versionskrav:
- RHEL 8.4:
resource-agents-4.1.1-90.13 - RHEL 8.6:
resource-agents-4.9.0-16.9 - RHEL 8.8:
resource-agents-4.9.0-40.1 - RHEL 9.0:
resource-agents-cloud-4.10.0-9.6 - RHEL 9.2 och senare:
resource-agents-cloud-4.10.0-34.1
- RHEL 8.4:
[1] Konfigurera resurserna i Pacemaker.
#Place the cluster in maintenance mode sudo pcs property set maintenance-mode=true[1] Ange pacemakerklustrets hälsonodstrategi och villkor.
sudo pcs property set node-health-strategy=custom sudo pcs constraint location 'regexp%!health-.*' \ rule score-attribute='#health-azure' \ defined '#uname'Viktigt!
Definiera inte några andra resurser i klustret som börjar med
health-förutom de resurser som beskrivs i nästa steg.[1] Ange det initiala värdet för klusterattributen. Kör för varje klusternod och för utskalningsmiljöer, inklusive den virtuella majoritetstillverkarens virtuella dator.
sudo crm_attribute --node prod-cl1-0 --name '#health-azure' --update 0 sudo crm_attribute --node prod-cl1-1 --name '#health-azure' --update 0[1] Konfigurera resurserna i Pacemaker. Kontrollera att resurserna börjar med
health-azure.sudo pcs resource create health-azure-events \ ocf:heartbeat:azure-events-az \ op monitor interval=10s timeout=240s \ op start timeout=10s start-delay=90s sudo pcs resource clone health-azure-events allow-unhealthy-nodes=true failure-timeout=120sTa Pacemaker-klustret ur underhållsläge.
sudo pcs property set maintenance-mode=falseRensa eventuella fel under aktiveringen och kontrollera att
health-azure-eventsresurserna har startats på alla klusternoder.sudo pcs resource cleanupDet kan ta upp till två minuter att köra frågor för schemalagda händelser första gången. Pacemakertestning med schemalagda händelser kan använda omstarts- eller omdistribueringsåtgärder för de virtuella klusterdatorerna. Mer information finns i Schemalagda händelser.
Valfri fäktningskonfiguration
Dricks
Det här avsnittet gäller endast om du vill konfigurera den särskilda fäktningsenheten fence_kdump.
Om du behöver samla in diagnostikinformation på den virtuella datorn kan det vara bra att konfigurera en annan stängselenhet baserat på stängselagenten fence_kdump. Agenten fence_kdump kan identifiera att en nod har angett återställning av kdumpkrasch och kan tillåta att tjänsten för återställning av krascher slutförs innan andra stängselmetoder anropas. Observera att fence_kdump det inte är en ersättning för traditionella stängselmekanismer, som SBD eller Azure-stängselagenten, när du använder virtuella Azure-datorer.
Viktigt!
Tänk på att när fence_kdump har konfigurerats som en stängselenhet på första nivån medför det fördröjningar i fäktningsåtgärderna och fördröjningar i programresursernas redundansväxling.
Om en kraschdump har identifierats fördröjs fäktningen tills kraschåterställningstjänsten har slutförts. Om den misslyckade noden inte kan nås eller om den inte svarar fördröjs fäktningen med tiden, det konfigurerade antalet iterationer och tidsgränsen fence_kdump . Mer information finns i Hur gör jag för att konfigurera fence_kdump i ett Red Hat Pacemaker-kluster?.
Den föreslagna fence_kdump tidsgränsen kan behöva anpassas till den specifika miljön.
Vi rekommenderar att du konfigurerar fence_kdump fäktning endast när det behövs för att samla in diagnostik inom den virtuella datorn och alltid i kombination med traditionella stängselmetoder, till exempel SBD eller Azure Fence Agent.
Följande Artiklar om Red Hat KB innehåller viktig information om hur du konfigurerar fäktning fence_kdump :
- Se Hur gör jag för att konfigurera fence_kdump i ett Red Hat Pacemaker-kluster?.
- Se Konfigurera /hantera fäktningsnivåer i ett RHEL-kluster med Pacemaker.
- Se fence_kdump misslyckas med "timeout efter X sekunder" i ett RHEL 6- eller 7 HA-kluster med kexec-tools som är äldre än 2.0.14.
- Information om hur du ändrar standardtimeout finns i Hur gör jag för att konfigurera kdump för användning med RHEL 6, 7, 8 HA-tillägget?.
- Information om hur du minskar redundansfördröjningen när du använder
fence_kdumpfinns i Kan jag minska den förväntade redundansfördröjningen när du lägger till fence_kdump konfiguration?.
Kör följande valfria steg för att lägga till fence_kdump som en fäktningskonfiguration på första nivån, utöver azure fence agent-konfigurationen.
[A] Kontrollera att det
kdumpär aktivt och konfigurerat.systemctl is-active kdump # Expected result # active[A] Installera stängselagenten
fence_kdump.yum install fence-agents-kdump[1] Skapa en
fence_kdumpfäktningsenhet i klustret.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" timeout=30[1] Konfigurera fäktningsnivåer så att fäktningsmekanismen
fence_kdumpaktiveras först.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" pcs stonith level add 1 prod-cl1-0 rsc_st_kdump pcs stonith level add 1 prod-cl1-1 rsc_st_kdump # Replace <stonith-resource-name> to the resource name of the STONITH resource configured in your pacemaker cluster (example based on above configuration - sbd or rsc_st_azure) pcs stonith level add 2 prod-cl1-0 <stonith-resource-name> pcs stonith level add 2 prod-cl1-1 <stonith-resource-name> # Check the fencing level configuration pcs stonith level # Example output # Target: prod-cl1-0 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name> # Target: prod-cl1-1 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name>[A] Tillåt de portar som krävs för
fence_kdumpvia brandväggen.firewall-cmd --add-port=7410/udp firewall-cmd --add-port=7410/udp --permanent[A] Utför konfigurationen
fence_kdump_nodesi/etc/kdump.confför att undvikafence_kdumpatt misslyckas med en tidsgräns för vissakexec-toolsversioner. Mer information finns i fence_kdump tidsgräns när fence_kdump_nodes inte anges med kexec-tools version 2.0.15 eller senare och fence_kdump misslyckas med "timeout efter X sekunder" i ett RHEL 6- eller 7-kluster med kexec-tools-versioner som är äldre än 2.0.14. Exempelkonfigurationen för ett kluster med två noder visas här. När du har ändrat i/etc/kdump.confmåste kdumpavbildningen återskapas. Starta om tjänsten om du vill återskapa denkdump.vi /etc/kdump.conf # On node prod-cl1-0 make sure the following line is added fence_kdump_nodes prod-cl1-1 # On node prod-cl1-1 make sure the following line is added fence_kdump_nodes prod-cl1-0 # Restart the service on each node systemctl restart kdump[A] Kontrollera att
initramfsbildfilen innehållerfence_kdumpfilerna ochhosts. Mer information finns i Hur gör jag för att konfigurera fence_kdump i ett Red Hat Pacemaker-kluster?.lsinitrd /boot/initramfs-$(uname -r)kdump.img | egrep "fence|hosts" # Example output # -rw-r--r-- 1 root root 208 Jun 7 21:42 etc/hosts # -rwxr-xr-x 1 root root 15560 Jun 17 14:59 usr/libexec/fence_kdump_sendTesta konfigurationen genom att krascha en nod. Mer information finns i Hur gör jag för att konfigurera fence_kdump i ett Red Hat Pacemaker-kluster?.
Viktigt!
Om klustret redan används produktivt planerar du testet i enlighet med detta eftersom krasch av en nod påverkar programmet.
echo c > /proc/sysrq-trigger
Nästa steg
- Se Planering och implementering av Azure Virtual Machines för SAP.
- Se Azure Virtual Machines-distribution för SAP.
- Se Azure Virtual Machines DBMS-distribution för SAP.
- Information om hur du upprättar ha och planerar för haveriberedskap för SAP HANA på virtuella Azure-datorer finns i Hög tillgänglighet för SAP HANA på virtuella Azure-datorer.