Kunskapsuppsättningsbegrepp i Azure AI Search
Den här artikeln är avsedd för utvecklare som behöver en djupare förståelse för begrepp och sammansättning för kompetensuppsättningar och som förutsätter att de är bekanta med de övergripande begreppen för tillämpad AI i Azure AI Search.
En kompetensuppsättning är ett återanvändbart objekt i Azure AI Search som är kopplat till en indexerare. Den innehåller en eller flera kunskaper som anropar inbyggd AI eller extern anpassad bearbetning över dokument som hämtats från en extern datakälla.
Följande diagram illustrerar det grundläggande dataflödet för körning av kompetensuppsättningar.
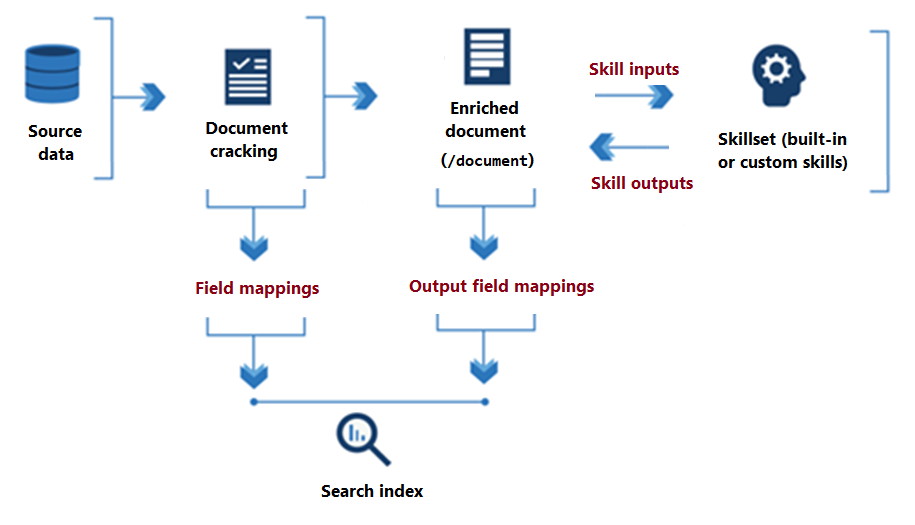
Från början av kompetensuppsättningen bearbetning till dess slutsats, färdigheter läsa från och skriva till ett berikat dokument som finns i minnet. Inledningsvis är ett berikat dokument bara det råa innehållet som extraheras från en datakälla (artikulerat som rotnoden "/document" ). Med varje färdighetskörning får det berikade dokumentet struktur och substans när varje färdighet skriver ut sina utdata som noder i diagrammet.
När körningen av kunskapsuppsättningen är klar hittar utdata från ett berikat dokument sin väg in i ett index via användardefinierade mappningar av utdatafält. Allt råinnehåll som du vill överföra intakt, från källa till index, definieras via fältmappningar.
Om du vill konfigurera tillämpad AI anger du inställningar i en kompetensuppsättning och indexerare.
Definition av kunskaper
En kompetensuppsättning är en matris med en eller flera färdigheter som utför en berikning, till exempel översättning av text eller optisk teckenigenkänning (OCR) på en bildfil. Kunskaper kan vara inbyggda kunskaper från Microsoft eller anpassade kunskaper för bearbetning av logik som du är värd för externt. En kunskapsuppsättning skapar berikade dokument som antingen används under indexering eller projiceras till ett kunskapslager.
Färdigheter har en kontext, indata och utdata:
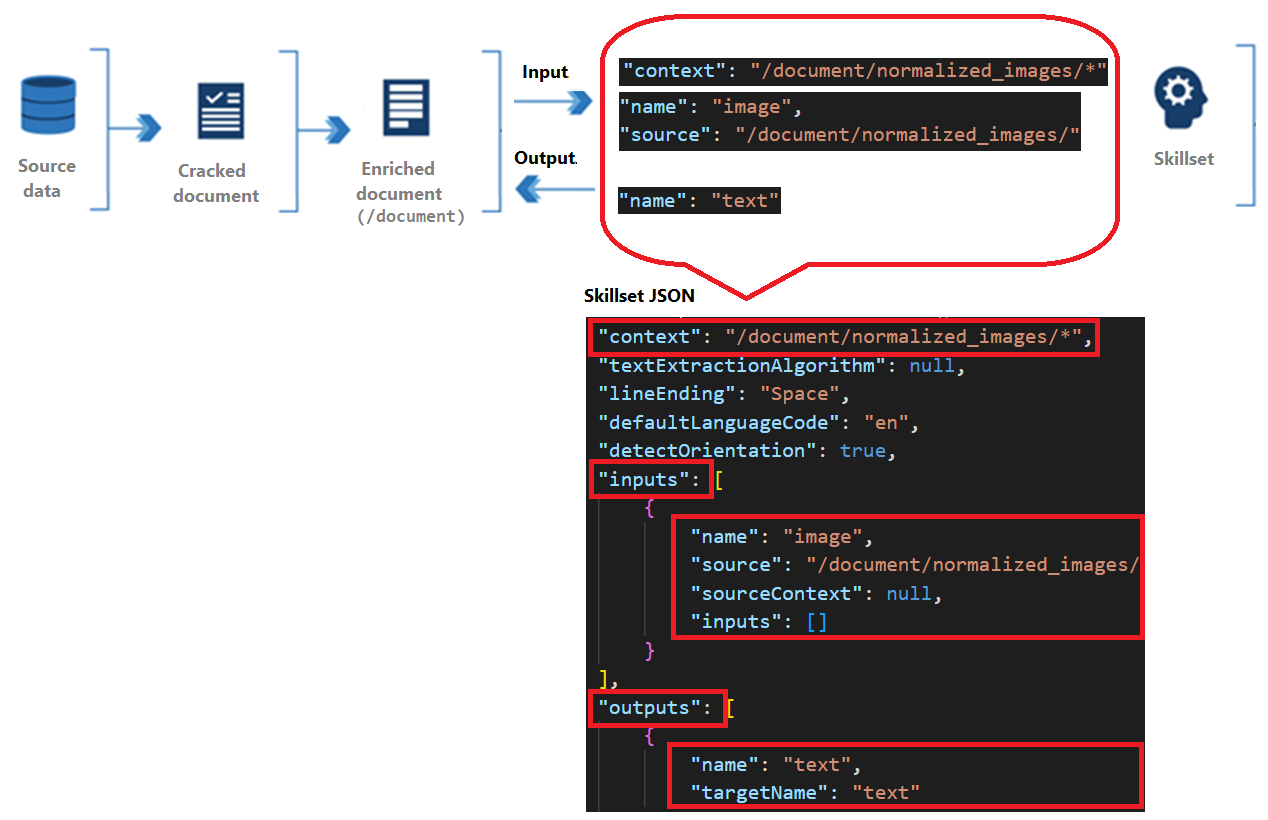
Kontext refererar till åtgärdens omfattning, som kan vara en gång per dokument eller en gång för varje objekt i en samling.
Indata kommer från noder i ett berikat dokument, där en "källa" och "namn" identifierar en viss nod.
Utdata skickas tillbaka till det berikade dokumentet som en ny nod. Värden är nodens "namn" och nodinnehåll. Om ett nodnamn dupliceras kan du ange ett målnamn för disambiguation.
Kompetenskontext
Varje färdighet har en kontext, som kan vara hela dokumentet (/document) eller en nod längre ned i trädet (/document/countries/*).
En kontext avgör:
Antalet gånger färdigheten körs, över ett enda värde (en gång per fält, per dokument) eller för en samling, där du lägger till ett
/*resultat i kompetensanrop för varje instans i samlingen.Utdatadeklaration eller var i berikningsträdet som kunskapsutdata läggs till. Utdata läggs alltid till i trädet som underordnade kontextnoder.
Form på indata. För samlingar på flera nivåer påverkar inställningen av kontexten till den överordnade samlingen formen på indata för färdigheten. Om du till exempel har ett berikningsträd med en lista över länder/regioner, var och en berikad med en lista över tillstånd som innehåller en lista med postnummer, avgör hur du anger kontexten hur indata tolkas.
Kontext Indata Form på indata Kompetensanrop /document/countries/*/document/countries/*/states/*/zipcodes/*En lista över alla postnummer i landet/regionen En gång per land/region /document/countries/*/states/*/document/countries/*/states/*/zipcodes/*En lista över postnummer i tillståndet En gång per kombination av land/region och stat
Kunskapsberoenden
Färdigheter kan köras oberoende och parallellt eller sekventiellt om du matar ut utdata från en färdighet till en annan färdighet. I följande exempel visas två inbyggda färdigheter som körs i följd:
Kunskap nr 1 är en färdighet för textdelning som accepterar innehållet i källfältet "reviews_text" som indata och delar upp innehållet i "sidor" på 5 000 tecken som utdata. Att dela upp stor text i mindre segment kan ge bättre resultat för färdigheter som sentimentidentifiering.
Kunskap nr 2 är en attitydidentifieringsfärdighet som accepterar "sidor" som indata och skapar ett nytt fält med namnet "Sentiment" som utdata som innehåller resultatet av attitydanalys.
Observera hur utdata från den första färdigheten ("sidor") används i attitydanalys, där "/document/reviews_text/pages/*" är både kontext och indata. Mer information om sökvägsformulering finns i Så här refererar du till berikningar.
{
"skills": [
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SentimentSkill",
"name": "#2",
"description": null,
"context": "/document/reviews_text/pages/*",
"defaultLanguageCode": "en",
"inputs": [
{
"name": "text",
"source": "/document/reviews_text/pages/*",
}
],
"outputs": [
{
"name": "sentiment",
"targetName": "sentiment"
},
{
"name": "confidenceScores",
"targetName": "confidenceScores"
},
{
"name": "sentences",
"targetName": "sentences"
}
]
}
. . .
]
}
Berikande träd
Ett berikat dokument är en tillfällig, trädliknande datastruktur som skapas under körningen av kompetensuppsättningen och som samlar in alla ändringar som introduceras genom färdigheter. Tillsammans representeras berikningar som en hierarki med adresserbara noder. Noder innehåller även alla oenrichade fält som skickas ordagrant från den externa datakällan.
Det finns ett utökat dokument under hela körningen av kunskapsuppsättningen, men kan cachelagras eller skickas till ett kunskapslager.
Inledningsvis är ett berikat dokument helt enkelt det innehåll som extraheras från en datakälla under dokumentsprickor, där text och bilder extraheras från källan och görs tillgängliga för språk- eller bildanalys.
Det första innehållet är metadata och rotnoden (document/content). Rotnoden är vanligtvis ett helt dokument eller en normaliserad bild som extraheras från en datakälla när dokumentet spricker. Hur det artikuleras i ett berikande träd varierar för varje typ av datakälla. I följande tabell visas tillståndet för ett dokument som kommer in i berikande pipelinen för flera datakällor som stöds:
| Datakälla\Parsningsläge | Standardvärde | JSON, JSON-rader och CSV |
|---|---|---|
| Blob Storage | /document/content /document/normalized_images/* … |
/document/{key1} /document/{key2} … |
| Azure SQL | /document/{column1} /document/{column2} … |
Ej tillämpligt |
| Azure Cosmos DB | /document/{key1} /document/{key2} … |
Ej tillämpligt |
När färdigheter körs läggs utdata till i berikningsträdet som nya noder. Om kunskapskörningen är över hela dokumentet läggs noder till på den första nivån under roten.
Noder kan användas som indata för underordnade kunskaper. Kunskaper som skapar innehåll, till exempel översatta strängar, kan till exempel bli indata för färdigheter som känner igen entiteter eller extraherar nyckelfraser.
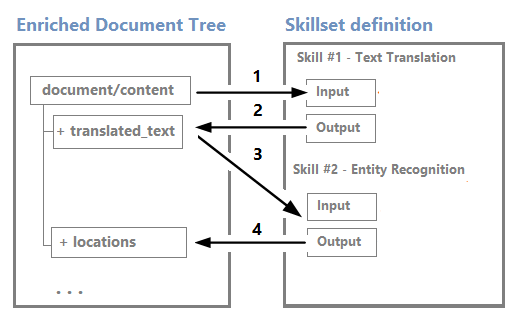
Även om du kan visualisera och arbeta med ett berikande träd via redigeraren för visuella felsökningssessioner är det främst en intern struktur.
Berikningar är oföränderliga: när de har skapats kan noder inte redigeras. När dina kunskapsuppsättningar blir mer komplexa kommer även ditt berikande träd, men inte alla noder i berikningsträdet att behöva göra det till indexet eller kunskapsarkivet.
Du kan selektivt bevara bara en delmängd av berikningsutdata så att du bara behåller det du tänker använda. Mappningar av utdatafält i indexerarens definition avgör vilket innehåll som faktiskt matas in i sökindexet. På samma sätt kan du mappa utdata till former som har tilldelats projektioner om du skapar ett kunskapslager.
Kommentar
Berikande trädformat gör det möjligt för berikningspipelinen att bifoga metadata till även primitiva datatyper. Metadata är inte ett giltigt JSON-objekt, men kan projiceras till ett giltigt JSON-format i projektionsdefinitioner i ett kunskapslager. Mer information finns i Formningsfärdighet.
Definition av indexerare
En indexerare har egenskaper och parametrar som används för att konfigurera indexerarens körning. Bland dessa egenskaper finns mappningar som anger datasökvägen till fält i ett sökindex.

Det finns två uppsättningar mappningar:
"fieldMappings" mappar ett källfält till ett sökfält.
"outputFieldMappings" mappar en nod i ett berikat dokument till ett sökfält.
Egenskapen "sourceFieldName" anger antingen ett fält i datakällan eller en nod i ett berikande träd. Egenskapen "targetFieldName" anger sökfältet i ett index som tar emot innehållet.
Berikningsexempel
Med hjälp av kompetensuppsättningen för hotellrecensioner som referenspunkt förklarar det här exemplet hur ett berikande träd utvecklas genom färdighetskörning med hjälp av konceptuella diagram.
Det här exemplet visar också:
- Hur en färdighets kontext och indata fungerar för att avgöra hur många gånger en färdighet körs
- Vilken form indata är baserad på kontexten
I det här exemplet innehåller källfält från en CSV-fil kundrecensioner om hotell ("reviews_text") och klassificeringar ("reviews_rating"). Indexeraren lägger till metadatafält från Blob Storage och färdigheter lägger till översatt text, attitydpoäng och identifiering av nyckelfraser.
I exemplet med hotellgranskningar representerar ett "dokument" i berikningsprocessen en enda hotellgranskning.
Dricks
Du kan skapa ett sökindex och kunskapslager för dessa data i Azure-portalen eller REST-API:er. Du kan också använda Felsökningssessioner för insikter om sammansättning, beroenden och effekter på ett berikande träd. Bilder i den här artikeln hämtas från felsökningssessioner.
Konceptuellt ser det första berikningsträdet ut så här:

Rotnoden för alla berikanden är "/document". När du arbetar med blobindexerare "/document" har noden underordnade noder till "/document/content" och "/document/normalized_images". När data är CSV, som i det här exemplet, mappas kolumnnamnen till noder under "/document".
Skicklighet nr 1: Dela kompetens
När källinnehållet består av stora textsegment är det bra att dela upp det i mindre komponenter för att få bättre precision i språk, sentiment och identifiering av nyckelfraser. Det finns två tillgängliga korn: sidor och meningar. En sida består av cirka 5 000 tecken.
En kunskap om textdelning är vanligtvis först i en kompetensuppsättning.
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
Med kunskapskontexten "/document/reviews_text"körs den delade färdigheten en gång för reviews_text. Kunskapsutdata är en lista där segmenten reviews_text är segmenterade i 5 000 tecken. Utdata från den delade färdigheten namnges pages och läggs till i berikningsträdet. Med targetName funktionen kan du byta namn på en kunskapsutdata innan du läggs till i berikningsträdet.
Berikningsträdet har nu en ny nod som placeras under kompetensens kontext. Den här noden är tillgänglig för alla kunskaps-, projektions- eller utdatafältmappningar.

För att få åtkomst till någon av de berikanden som läggs till i en nod av en färdighet krävs den fullständiga sökvägen för berikningen. Om du till exempel vill använda texten från pages noden som indata till en annan färdighet anger du den som "/document/reviews_text/pages/*". Mer information om sökvägar finns i Referensberikningar.
Kunskap nr 2 Språkidentifiering
Dokument för hotellgranskning innehåller feedback från kunder som uttrycks på flera språk. Språkidentifieringsfärdigheten avgör vilket språk som används. Resultatet skickas sedan till extrahering av nyckelfraser och sentimentidentifiering (visas inte), med språket i åtanke när du identifierar sentiment och fraser.
Även om språkidentifieringsfärdigheten är den tredje (färdighet nr 3) som definierats i kompetensuppsättningen är det nästa färdighet att utföra. Det kräver inga indata så det körs parallellt med den tidigare kunskapen. Precis som den delade färdighet som föregick den anropas även språkidentifieringsfärdigheten en gång för varje dokument. Berikningsträdet har nu en ny nod för språk.

Kunskaper nr 3 och 4 (attitydanalys och identifiering av nyckelfraser)
Kundfeedback återspeglar en rad positiva och negativa upplevelser. Kunskapen för attitydanalys analyserar feedbacken och tilldelar en poäng längs ett kontinuum av negativa till positiva tal eller neutral om sentimentet är obestämt. Parallellt med attitydanalys identifierar och extraherar nyckelfrasidentifiering ord och korta fraser som visas som följdfraser.
Med tanke på kontexten /document/reviews_text/pages/*för anropas både attitydanalys och nyckelfrasfärdigheter en gång för vart och ett av objekten pages i samlingen. Utdata från färdigheten blir en nod under det associerade sidelementet.
Nu bör du kunna titta på resten av färdigheterna i kunskapsuppsättningen och visualisera hur berikande träd fortsätter att växa med utförandet av varje färdighet. Vissa kunskaper, till exempel sammanslagningsfärdigheten och formningsfärdigheten, skapar också nya noder men använder bara data från befintliga noder och skapar inte nya net-berikanden.

Färgerna på anslutningsapparna i trädet ovan anger att berikningarna har skapats med olika kunskaper och att noderna måste åtgärdas individuellt och inte ingår i objektet som returneras när den överordnade noden väljs.
Skicklighet nr 5 Formningsfärdighet
Om utdata innehåller ett kunskapslager lägger du till en Shaper-färdighet som ett sista steg. Shaper-färdigheten skapar dataformer från noder i ett berikande träd. Du kanske till exempel vill konsolidera flera noder till en enda form. Du kan sedan projicera den här formen som en tabell (noder blir kolumnerna i en tabell) och skicka formen efter namn till en tabellprojektion.
Shaper-färdigheten är lätt att arbeta med eftersom den fokuserar på att forma under en färdighet. Du kan också välja infogad formning i enskilda projektioner. Shaper Skill lägger inte till eller förringar inte ett berikande träd, så det visualiseras inte. I stället kan du tänka dig en Shaper-färdighet som det sätt på vilket du omformulerar berikandeträdet som du redan har. Konceptuellt liknar detta att skapa vyer ur tabeller i en databas.
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "#5",
"description": null,
"context": "/document",
"inputs": [
{
"name": "name",
"source": "/document/name"
},
{
"name": "reviews_date",
"source": "/document/reviews_date"
},
{
"name": "reviews_rating",
"source": "/document/reviews_rating"
},
{
"name": "reviews_text",
"source": "/document/reviews_text"
},
{
"name": "reviews_title",
"source": "/document/reviews_title"
},
{
"name": "AzureSearch_DocumentKey",
"source": "/document/AzureSearch_DocumentKey"
},
{
"name": "pages",
"sourceContext": "/document/reviews_text/pages/*",
"inputs": [
{
"name": "Sentiment",
"source": "/document/reviews_text/pages/*/Sentiment"
},
{
"name": "LanguageCode",
"source": "/document/Language"
},
{
"name": "Page",
"source": "/document/reviews_text/pages/*"
},
{
"name": "keyphrase",
"sourceContext": "/document/reviews_text/pages/*/Keyphrases/*",
"inputs": [
{
"name": "Keyphrases",
"source": "/document/reviews_text/pages/*/Keyphrases/*"
}
]
}
]
}
],
"outputs": [
{
"name": "output",
"targetName": "tableprojection"
}
]
}
Nästa steg
Med en introduktion och ett exempel bakom dig kan du prova att skapa din första kompetensuppsättning med hjälp av inbyggda färdigheter.