Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
Azure AI Search stöder import, analys och indexering av data från flera datakällor till ett enda konsoliderat sökindex.
I den här C#-självstudien används klientbiblioteket Azure.Search.Documents i Azure SDK för .NET för att indexering av exempel på hotelldata från en Azure Cosmos DB-instans. Sedan sammanfogar du data med information om hotellrum som hämtats från Azure Blob Storage-dokument. Resultatet är ett kombinerat hotellsökningsindex som innehåller hotelldokument, med rum som komplexa datatyper.
I den här handledningen kommer du att:
- Ladda upp exempeldata till datakällor
- Identifiera dokumentnyckeln
- Definiera och skapa indexet
- Indexering av hotelldata från Azure Cosmos DB
- Slå samman hotellrumsdata från Blob Storage
Översikt
I den här självstudien används Azure.Search.Documents för att skapa och köra flera indexerare. Du laddar upp exempeldata till två Azure-datakällor och konfigurerar en indexerare som hämtar från båda källorna för att fylla i ett enda sökindex. De två datauppsättningarna måste ha ett gemensamt värde för att stödja sammanfogningen. I den här handledningen är fältet ett ID. Så länge det finns ett gemensamt fält som stöder mappningen kan en indexerare slå samman data från olika resurser: strukturerade data från Azure SQL, ostrukturerade data från Blob Storage eller valfri kombination av datakällor som stöds i Azure.
En färdig version av koden i den här självstudien finns i följande projekt:
Förutsättningar
- Ett Azure-konto med en aktiv prenumeration. Skapa ett konto utan kostnad.
- Ett Azure Cosmos DB för NoSQL-konto.
- Ett Azure Storage-konto.
- En Azure AI Search-tjänst.
- Visual Studio.
Kommentar
Du kan använda en kostnadsfri sökfunktion till den här guiden. Den kostnadsfria nivån begränsar dig till tre index, tre indexerare och tre datakällor. I den här kursen skapar du en av varje. Innan du börjar måste du se till att du har plats för din tjänst för att acceptera de nya resurserna.
Förbereda tjänster
I den här självstudien används Azure AI Search för indexering och frågor, Azure Cosmos DB för den första datauppsättningen och Azure Blob Storage för den andra datauppsättningen.
Om möjligt skapar du alla tjänster i samma region och resursgrupp för närhet och hanterbarhet. I praktiken kan dina tjänster finnas i valfri region.
Det här exemplet använder två små datamängder som beskriver sju fiktiva hotell. En uppsättning beskriver själva hotellen och läses in i en Azure Cosmos DB-databas. Den andra uppsättningen innehåller information om hotellrum och tillhandahålls som sju separata JSON-filer som ska laddas upp till Azure Blob Storage.
Börja med Azure Cosmos DB
Logga in på Azure-portalen och välj ditt Azure Cosmos DB-konto.
Välj Datautforskaren i den vänstra rutan.
Välj Ny container>Ny databas.
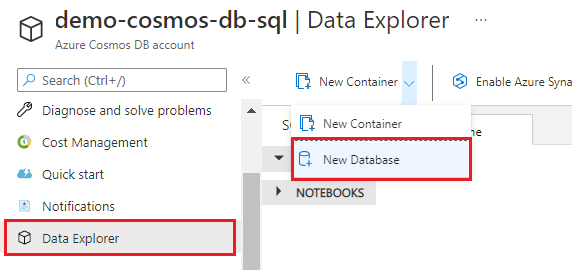
Ange hotel-rooms-db som namn. Acceptera standardvärdena för de återstående inställningarna.
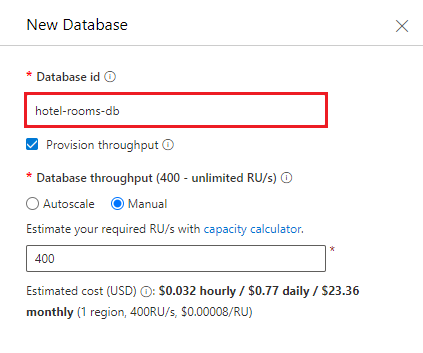
Skapa en container som riktar sig till den databas som du skapade tidigare. Ange hotell för containernamnet och /HotelId för partitionsnyckeln.
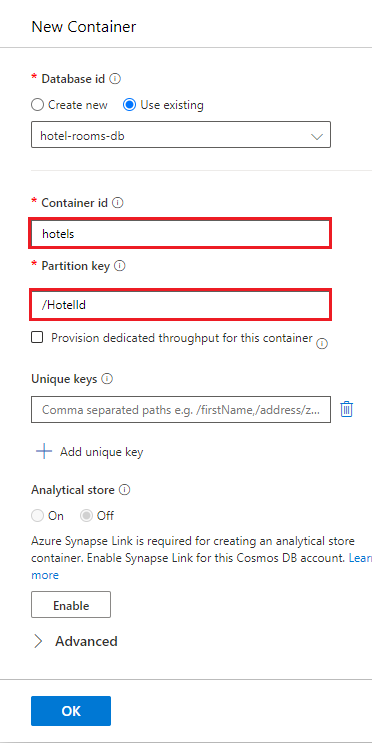
Välj hotell> och sedan Objekt, och välj sedan Ladda upp objekt på kommandofältet.
Ladda upp JSON-filen från
cosmosdbmappen i multiple-data-sources/v11.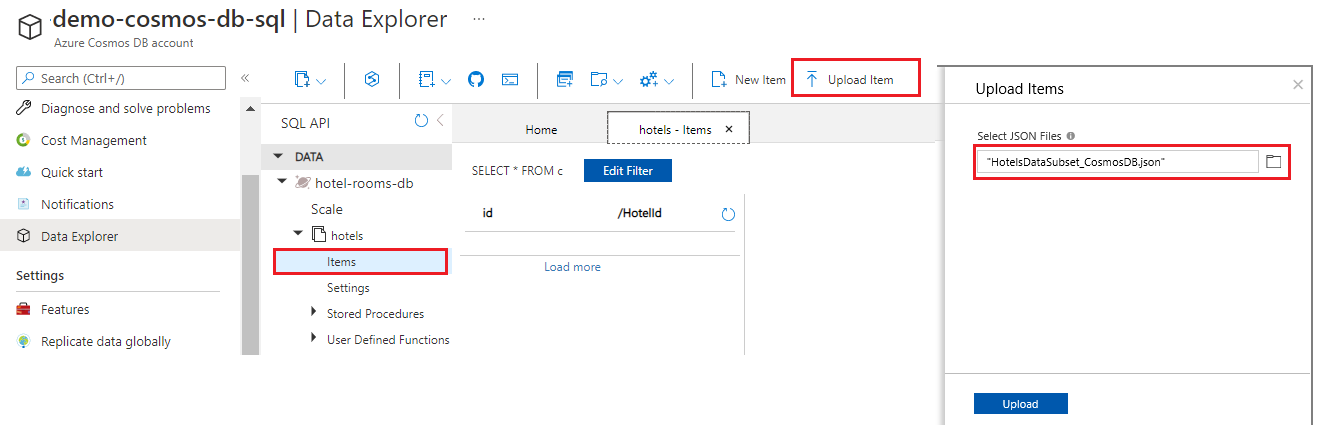
Använd uppdateringsknappen för att uppdatera vyn över objekten i hotellsamlingen. Du bör se sju nya databasdokument i listan.
Välj Inställningar>Nycklar i den vänstra rutan.
Anteckna en anslutningssträng. Du behöver det här värdet för appsettings.json i ett senare steg. Om du inte använde det föreslagna databasnamnet hotel-rooms-db kopierar du även databasnamnet.
Azure Blob Storage
Logga in på Azure-portalen och välj ditt Azure Storage-konto.
I den vänstra rutan väljer duDatalagringscontainrar>.
Skapa en blobcontainer med namnet hotel-rooms för att lagra exempelfilerna för hotellrums-JSON. Du kan ange åtkomstnivån till valfritt giltigt värde.
Öppna containern och välj sedan Ladda upp i kommandofältet.
Ladda upp de sju JSON-filerna från
blobmappen i multiple-data-sources/v11.
I den vänstra rutan väljer du Åtkomstnycklar för säkerhet + nätverk>.
Anteckna kontonamnet och en anslutningssträng. Du behöver båda värdena för appsettings.json i ett senare steg.
Azure AI-sökning
Den tredje komponenten är Azure AI Search, som du kan skapa i Azure Portal eller hitta en befintlig söktjänst i dina Azure-resurser.
Kopiera en administratörsnyckel och URL för Azure AI Search
Om du vill autentisera till söktjänsten behöver du tjänst-URL:en och en åtkomstnyckel. Att ha en giltig nyckel upprättar förtroende per begäran mellan programmet som skickar begäran och tjänsten som hanterar den.
Logga in på Azure-portalen och välj din söktjänst.
Välj Översikt i den vänstra rutan.
Anteckna URL:en, som bör se ut som
https://my-service.search.windows.net.Välj Inställningar>Nycklar i den vänstra rutan.
Anteckna en administratörsnyckel för att få full behörighet inom tjänsten. Det finns två utbytbara administratörsnycklar som tillhandahålls för affärskontinuitet om du behöver rulla över en. Du kan använda någon av nycklarna på begäranden för att lägga till, ändra och ta bort objekt.
Konfigurera din miljö
AzureSearchMultipleDataSources.slnÖppna filen från multiple-data-sources/v11 i Visual Studio.Högerklicka på projektet i Solution Explorer och välj Hantera NuGet-paket för lösning....
På fliken Bläddra letar du upp och installerar följande paket:
Azure.Search.Documents (version 11.0 eller senare)
Microsoft.Extensions.Configuration
Microsoft.Extensions.Configuration.Json
I Solution Explorer redigerar
appsettings.jsondu filen med den anslutningsinformation som du samlade in i föregående steg.{ "SearchServiceUri": "<YourSearchServiceURL>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "BlobStorageAccountName": "<YourBlobStorageAccountName>", "BlobStorageConnectionString": "<YourBlobStorageConnectionString>", "CosmosDBConnectionString": "<YourCosmosDBConnectionString>", "CosmosDBDatabaseName": "hotel-rooms-db" }
Kartlägg nyckelfält
Sammanslagning av innehåll kräver att båda dataströmmarna riktar in sig på samma dokument i sökindexet.
I Azure AI Search identifierar nyckelfältet varje dokument unikt. Varje sökindex måste ha exakt ett nyckelfält av typen Edm.String. Nyckelfältet måste finnas för varje dokument i en datakälla som läggs till i indexet. (Det är faktiskt det enda obligatoriska fältet.)
När du indexerar data från flera datakällor kontrollerar du att varje inkommande rad eller dokument innehåller en gemensam dokumentnyckel. På så sätt kan du sammanfoga data från två fysiskt distinkta källdokument till ett nytt sökdokument i det kombinerade indexet.
Det kräver ofta viss planering i förväg för att identifiera en meningsfull dokumentnyckel för ditt index och för att se till att den finns i båda datakällorna. I den här demonstrationen finns också nyckeln för varje hotell i Azure Cosmos DB i JSON-blobbarna för rummen i Blob Storage.
Azure AI Search-indexerare kan använda fältmappningar för att byta namn på och till och med formatera om datafält under indexeringsprocessen, så att källdata kan dirigeras till rätt indexfält. I Azure Cosmos DB kallas HotelIdtill exempel hotellidentifieraren , men i JSON-blobfilerna för hotellrummen heter Idhotellidentifieraren . Programmet hanterar den här avvikelsen Id genom att mappa fältet från blobarna till HotelId nyckelfältet i indexeraren.
Kommentar
I de flesta fall gör inte automatiskt genererade dokumentnycklar, till exempel de som skapats som standard av vissa indexerare, bra dokumentnycklar för kombinerade index. I allmänhet använder du ett meningsfullt, unikt nyckelvärde som redan finns i dina datakällor eller som enkelt kan läggas till.
Utforska koden
När data- och konfigurationsinställningarna är på plats bör exempelprogrammet i AzureSearchMultipleDataSources.sln vara redo att bygga och köra.
Den här enkla C#/.NET-konsolappen utför följande uppgifter:
- Skapar ett nytt index baserat på datastrukturen för klassen C# Hotel, som även refererar till klasserna Adress och Rum.
- Skapar en ny datakälla och en indexerare som mappar Azure Cosmos DB-data till indexfält. Det här är båda objekten i Azure AI Search.
- Kör indexeraren för att läsa in hotelldata från Azure Cosmos DB.
- Skapar en andra datakälla och en indexerare som mappar JSON-blobdata till indexfält.
- Kör den andra indexeraren för att läsa in hotellrumsdata från Blob Storage.
Innan du kör programmet tar det en minut att studera koden, indexdefinitionen och indexerarens definition. Den relevanta koden finns i två filer:
-
Hotel.csinnehåller schemat som definierar indexet. -
Program.csinnehåller funktioner som skapar Azure AI Search-index, datakällor och indexerare och läser in de kombinerade resultaten i indexet.
Skapa ett index
Det här exempelprogrammet använder CreateIndexAsync för att definiera och skapa ett Azure AI Search-index. Den använder klassen FieldBuilder för att generera en indexstruktur från en C#-datamodellklass.
Datamodellen definieras av klassen Hotell, som även innehåller referenser till klasserna Adress och Rum. FieldBuilder ökar detaljnivån genom flera klassdefinitioner för att generera en komplex datastruktur för indexet. Metadatataggar används för att definiera attributen för varje fält, till exempel om det är sökbart eller sorterbart.
Programmet tar bort ett befintligt index med samma namn innan det nya skapas, om du vill köra det här exemplet mer än en gång.
Följande kodfragment från Hotel.cs filen visar enkla fält följt av en referens till en annan datamodellklass, Room[], som i sin tur definieras i Room.cs filen (visas inte).
. . .
[SimpleField(IsFilterable = true, IsKey = true)]
public string HotelId { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true)]
public string HotelName { get; set; }
. . .
public Room[] Rooms { get; set; }
. . .
Program.cs I filen definieras ett SearchIndex med ett namn och en fältsamling som genereras av FieldBuilder.Build metoden och skapas sedan på följande sätt:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address and Room classes are referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
Skapa Azure Cosmos DB-datakälla och indexerare
Huvudprogrammet innehåller logik för att skapa Azure Cosmos DB-datakällan för hotelldata.
Först sammanfogar den Azure Cosmos DB-databasnamnet till anslutningssträngen. Sedan definieras ett SearchIndexerDataSourceConnection-objekt .
private static async Task CreateAndRunCosmosDbIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
// Append the database name to the connection string
string cosmosConnectString =
configuration["CosmosDBConnectionString"]
+ ";Database="
+ configuration["CosmosDBDatabaseName"];
SearchIndexerDataSourceConnection cosmosDbDataSource = new SearchIndexerDataSourceConnection(
name: configuration["CosmosDBDatabaseName"],
type: SearchIndexerDataSourceType.CosmosDb,
connectionString: cosmosConnectString,
container: new SearchIndexerDataContainer("hotels"));
// The Azure Cosmos DB data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(cosmosDbDataSource);
När datakällan har skapats konfigurerar programmet en Azure Cosmos DB-indexerare med namnet hotel-rooms-cosmos-indexer.
Programmet uppdaterar alla befintliga indexerare med samma namn och skriver över den befintliga indexeraren med innehållet i den tidigare koden. Den innehåller även återställnings- och körningsåtgärder, om du vill köra det här exemplet mer än en gång.
I följande exempel definieras ett schema för indexeraren så att det körs en gång per dag. Du kan ta bort schemaegenskapen från det här anropet om du inte vill att indexeraren ska köras automatiskt igen i framtiden.
SearchIndexer cosmosDbIndexer = new SearchIndexer(
name: "hotel-rooms-cosmos-indexer",
dataSourceName: cosmosDbDataSource.Name,
targetIndexName: indexName)
{
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Indexers keep metadata about how much they have already indexed.
// If we already ran the indexer, it "remembers" and does not run again.
// To avoid this, reset the indexer if it exists.
try
{
await indexerClient.GetIndexerAsync(cosmosDbIndexer.Name);
// Reset the indexer if it exists.
await indexerClient.ResetIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
// If the indexer does not exist, 404 will be thrown.
}
await indexerClient.CreateOrUpdateIndexerAsync(cosmosDbIndexer);
Console.WriteLine("Running Azure Cosmos DB indexer...\n");
try
{
// Run the indexer.
await indexerClient.RunIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 429)
{
Console.WriteLine("Failed to run indexer: {0}", ex.Message);
}
Det här exemplet innehåller ett enkelt try-catch-block för att rapportera eventuella fel som kan inträffa under körningen.
När Azure Cosmos DB-indexeraren har körts innehåller sökindexet en fullständig uppsättning exempel på hotelldokument. Rumsfältet för varje hotell är dock en tom matris, eftersom Azure Cosmos DB-datakällan utelämnar rumsinformation. Därefter hämtas programmet från Blob Storage för att läsa in och sammanfoga rumsdata.
Skapa Blob Storage-datakälla och indexerare
För att få rumsinformation konfigurerar programmet först en Blob Storage-datakälla för att referera till en uppsättning enskilda JSON-blobfiler.
private static async Task CreateAndRunBlobIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
SearchIndexerDataSourceConnection blobDataSource = new SearchIndexerDataSourceConnection(
name: configuration["BlobStorageAccountName"],
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["BlobStorageConnectionString"],
container: new SearchIndexerDataContainer("hotel-rooms"));
// The blob data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(blobDataSource);
När datakällan har skapats konfigurerar programmet en blobindexerare med namnet hotel-rooms-blob-indexer, enligt nedan.
JSON-blobarna innehåller ett nyckelfält med namnet Id i stället för HotelId. Koden använder FieldMapping klassen för att instruera indexeraren att dirigera Id fältvärdet till HotelId dokumentnyckeln i indexet.
Blob Storage-indexerare kan använda IndexingParametrar för att ange ett parsningsläge. Du bör ange olika parsningslägen beroende på om blobar representerar ett enda dokument eller flera dokument i samma blob. I det här exemplet representerar varje blob ett enda JSON-dokument, så koden använder json parsningsläget. Mer information om indexerarens parsningsparametrar för JSON-blobar finns i Index JSON-blobar.
Det här exemplet definierar ett schema för indexeraren, så att det körs en gång per dag. Du kan ta bort schemaegenskapen från det här anropet om du inte vill att indexeraren ska köras automatiskt igen i framtiden.
IndexingParameters parameters = new IndexingParameters();
parameters.Configuration.Add("parsingMode", "json");
SearchIndexer blobIndexer = new SearchIndexer(
name: "hotel-rooms-blob-indexer",
dataSourceName: blobDataSource.Name,
targetIndexName: indexName)
{
Parameters = parameters,
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Map the Id field in the Room documents to the HotelId key field in the index
blobIndexer.FieldMappings.Add(new FieldMapping("Id") { TargetFieldName = "HotelId" });
// Reset the indexer if it already exists
try
{
await indexerClient.GetIndexerAsync(blobIndexer.Name);
await indexerClient.ResetIndexerAsync(blobIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404) { }
await indexerClient.CreateOrUpdateIndexerAsync(blobIndexer);
try
{
// Run the indexer.
await searchService.Indexers.RunAsync(blobIndexer.Name);
}
catch (CloudException e) when (e.Response.StatusCode == (HttpStatusCode)429)
{
Console.WriteLine("Failed to run indexer: {0}", e.Response.Content);
}
Eftersom indexet redan är fyllt med hotelldata från Azure Cosmos DB-databasen uppdaterar blobindexeraren de befintliga dokumenten i indexet och lägger till rumsinformationen.
Kommentar
Om du har samma icke-nyckelfält i båda datakällorna och data i dessa fält inte matchar, innehåller indexet värdena från den indexerare som kördes senast. I vårt exempel innehåller båda datakällorna ett HotelName fält. Om data i det här fältet av någon anledning skiljer sig åt för dokument med samma nyckelvärde är HotelName data från den senast indexerade datakällan det värde som lagras i indexet.
Sökning
När du har kört programmet kan du utforska det ifyllda sökindexet med hjälp av Sökutforskaren i Azure-portalen.
Logga in på Azure-portalen och välj din söktjänst.
I den vänstra rutan väljer du Sökhanteringsindex>.
Välj hotel-rooms-sample i listan med index.
På fliken Sökutforskaren anger du en fråga för en term som
Luxury.Du bör se minst ett dokument i resultatet. Det här dokumentet bör innehålla en lista över rumsobjekt i matrisen
Rooms.
Återställa och köra igen
I de tidiga experimentella utvecklingsfaserna är det mest praktiska sättet att utforma iteration att ta bort objekten från Azure AI Search och låta koden återskapa dem. Resursnamn är unika. Om du tar bort ett objekt kan du återskapa det med samma namn.
Exempelkoden söker efter befintliga objekt och tar bort eller uppdaterar dem så att du kan köra programmet igen. Du kan också använda Azure Portal för att ta bort index, indexerare och datakällor.
Rensa resurser
När du arbetar i en egen prenumeration i slutet av ett projekt är det en bra idé att ta bort de resurser som du inte längre behöver. Resurser som fortsätter att köras kan kosta dig pengar. Du kan ta bort enstaka resurser eller hela resursgruppen om du vill ta bort alla resurser.
Du kan hitta och hantera resurser i Azure-portalen med hjälp av länken Alla resurser eller Resursgrupper i den vänstra rutan.
Nästa steg
Nu när du är bekant med att mata in data från flera källor kan du titta närmare på indexerarkonfigurationen, med början i Azure Cosmos DB: