Självstudie: Övervaka ett Service Fabric-kluster i Azure
Övervakning och diagnostik är avgörande för att utveckla, testa och distribuera arbetsbelastningar i alla molnmiljöer. Den här självstudien är del två i en serie och visar hur du övervakar och diagnostiserar ett Service Fabric-kluster med hjälp av händelser, prestandaräknare och hälsorapporter. Mer information finns i översikten över klusterövervakning och infrastrukturövervakning.
I den här självstudien lär du dig att:
- Visa Service Fabric-händelser
- Fråga EventStore-API:er för klusterhändelser
- Övervaka infrastruktur/samla in perf-räknare
- Visa hälsorapporter för kluster
I den här självstudieserien får du lära du dig att:
- Skapa ett säkert Windows-kluster på Azure med hjälp av en mall
- Övervaka ett kluster
- skala upp eller ned ett kluster
- uppgradera körningen för ett kluster
- Ta bort ett kluster
Kommentar
Vi rekommenderar att du använder Azure Az PowerShell-modulen för att interagera med Azure. Information om hur du kommer igång finns i Installera Azure PowerShell. Information om hur du migrerar till Az PowerShell-modulen finns i artikeln om att migrera Azure PowerShell från AzureRM till Az.
Förutsättningar
Innan du börjar den här självstudien:
- Om du inte har någon Azure-prenumeration kan du skapa ett kostnadsfritt konto
- Installera Azure PowerShell eller Azure CLI.
- Skapa ett säkert Windows-kluster
- Konfigurera diagnostiksamling för klustret
- Aktivera EventStore-tjänsten i klustret
- Konfigurera Azure Monitor-loggar och Log Analytics-agenten för klustret
Visa Service Fabric-händelser med hjälp av Azure Monitor-loggar
Azure Monitor-loggar samlar in och analyserar telemetri från program och tjänster som finns i molnet och tillhandahåller analysverktyg som hjälper dig att maximera deras tillgänglighet och prestanda. Du kan köra frågor i Azure Monitor-loggar för att få insikter och felsöka vad som händer i klustret.
Om du vill komma åt Service Fabric Analytics-lösningen går du till Azure-portalen och väljer den resursgrupp där du skapade Service Fabric Analytics-lösningen.
Välj resursen ServiceFabric(mysfomsworkspace).
I Översikt visas paneler i form av ett diagram för var och en av de aktiverade lösningarna, inklusive en för Service Fabric. Välj diagrammet Service Fabric för att fortsätta till Service Fabric Analytics-lösningen.
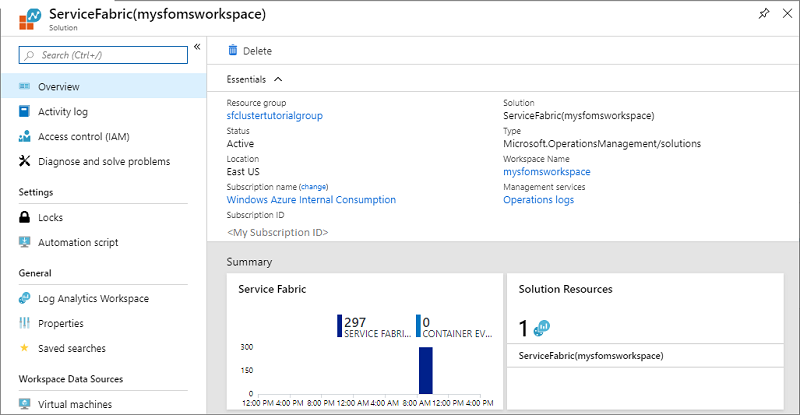
Följande bild visar startsidan för Service Fabric Analytics-lösningen. Den här startsidan innehåller en ögonblicksbild av vad som händer i klustret.
Om du aktiverade diagnostik när klustret skapades kan du se händelser för
- Service Fabric-klusterhändelser
- Reliable Actors programmeringsmodellhändelser
- Reliable Services-programmeringsmodellhändelser
Kommentar
Utöver Service Fabric-händelserna kan du samla in mer detaljerade systemhändelser genom att uppdatera konfigurationen för diagnostiktillägget.
Visa Service Fabric-händelser, inklusive åtgärder på noder
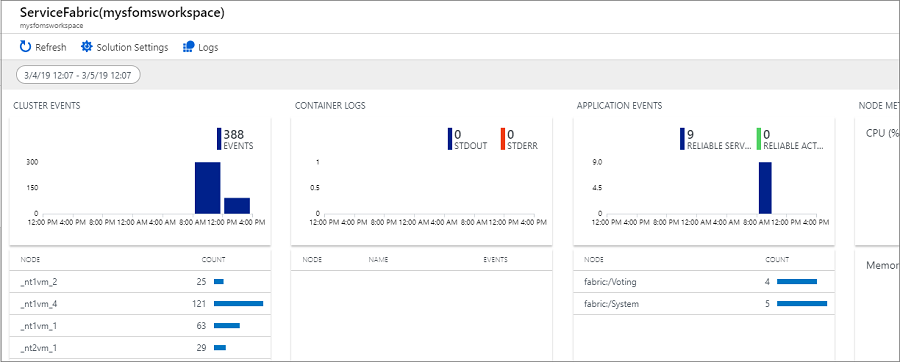
På sidan Service Fabric Analytics klickar du på diagrammet för Klusterhändelser. Loggarna för alla systemhändelser som har samlats in visas. Som referens kommer dessa från WADServiceFabricSystemEventsTable i Azure Storage-kontot, och på samma sätt kommer de tillförlitliga tjänste- och aktörshändelser som du ser härnäst från respektive tabeller.
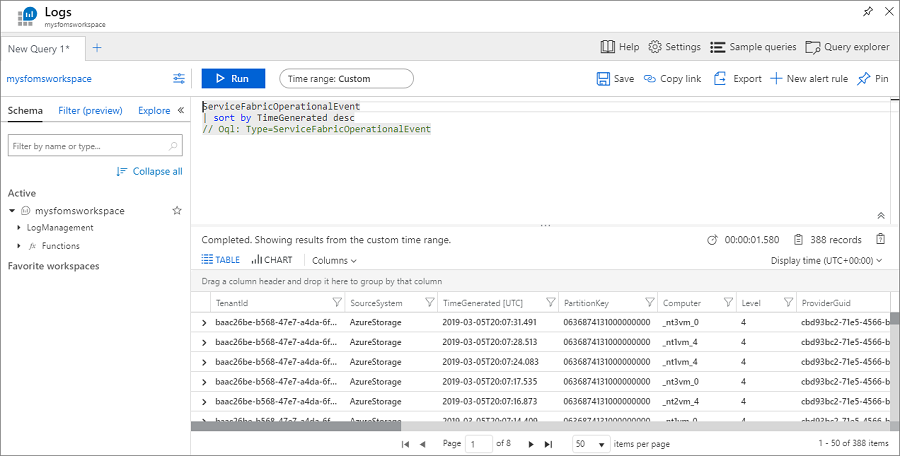
Frågan använder Kusto-frågespråket, som du kan ändra för att förfina det du letar efter. Om du till exempel vill hitta alla åtgärder som vidtas på noder i klustret kan du använda följande fråga. Händelse-ID:t som används nedan finns i händelsereferensen för den operativa kanalen.
ServiceFabricOperationalEvent
| where EventId < 25627 and EventId > 25619
Kusto-frågespråket är kraftfullt. Här är några andra användbara frågor.
Skapa en ServiceFabricEvent-uppslagstabell som användardefinierad funktion genom att spara frågan som en funktion med aliaset ServiceFabricEvent:
let ServiceFabricEvent = datatable(EventId: int, EventName: string)
[
...
18603, 'NodeUpOperational',
18604, 'NodeDownOperational',
...
];
ServiceFabricEvent
Returnera operativa händelser som registrerats under den senaste timmen:
ServiceFabricOperationalEvent
| where TimeGenerated > ago(1h)
| join kind=leftouter ServiceFabricEvent on EventId
| project EventId, EventName, TaskName, Computer, ApplicationName, EventMessage, TimeGenerated
| sort by TimeGenerated
Returnera operativa händelser med EventId == 18604 och EventName == 'NodeDownOperational':
ServiceFabricOperationalEvent
| where EventId == 18604
| project EventId, EventName = 'NodeDownOperational', TaskName, Computer, EventMessage, TimeGenerated
| sort by TimeGenerated
Returnera operativa händelser med EventId == 18604 och EventName == 'NodeUpOperational':
ServiceFabricOperationalEvent
| where EventId == 18603
| project EventId, EventName = 'NodeUpOperational', TaskName, Computer, EventMessage, TimeGenerated
| sort by TimeGenerated
Returnerar hälsorapporter med HealthState == 3 (fel) och extraherar fler egenskaper från fältet EventMessage:
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| extend HealthStateId = extract(@"HealthState=(\S+) ", 1, EventMessage, typeof(int))
| where TaskName == 'HM' and HealthStateId == 3
| extend SourceId = extract(@"SourceId=(\S+) ", 1, EventMessage, typeof(string)),
Property = extract(@"Property=(\S+) ", 1, EventMessage, typeof(string)),
HealthState = case(HealthStateId == 0, 'Invalid', HealthStateId == 1, 'Ok', HealthStateId == 2, 'Warning', HealthStateId == 3, 'Error', 'Unknown'),
TTL = extract(@"TTL=(\S+) ", 1, EventMessage, typeof(string)),
SequenceNumber = extract(@"SequenceNumber=(\S+) ", 1, EventMessage, typeof(string)),
Description = extract(@"Description='([\S\s, ^']+)' ", 1, EventMessage, typeof(string)),
RemoveWhenExpired = extract(@"RemoveWhenExpired=(\S+) ", 1, EventMessage, typeof(bool)),
SourceUTCTimestamp = extract(@"SourceUTCTimestamp=(\S+)", 1, EventMessage, typeof(datetime)),
ApplicationName = extract(@"ApplicationName=(\S+) ", 1, EventMessage, typeof(string)),
ServiceManifest = extract(@"ServiceManifest=(\S+) ", 1, EventMessage, typeof(string)),
InstanceId = extract(@"InstanceId=(\S+) ", 1, EventMessage, typeof(string)),
ServicePackageActivationId = extract(@"ServicePackageActivationId=(\S+) ", 1, EventMessage, typeof(string)),
NodeName = extract(@"NodeName=(\S+) ", 1, EventMessage, typeof(string)),
Partition = extract(@"Partition=(\S+) ", 1, EventMessage, typeof(string)),
StatelessInstance = extract(@"StatelessInstance=(\S+) ", 1, EventMessage, typeof(string)),
StatefulReplica = extract(@"StatefulReplica=(\S+) ", 1, EventMessage, typeof(string))
Returnera ett tidsdiagram över händelser med EventId != 17523:
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| where EventId != 17523
| summarize Count = count() by Timestamp = bin(TimeGenerated, 1h), strcat(tostring(EventId), " - ", case(EventName != "", EventName, "Unknown"))
| render timechart
Hämta service fabric-drifthändelser aggregerade med den specifika tjänsten och noden:
ServiceFabricOperationalEvent
| where ApplicationName != "" and ServiceName != ""
| summarize AggregatedValue = count() by ApplicationName, ServiceName, Computer
Rendera antalet Service Fabric-händelser efter EventId/EventName med hjälp av en fråga mellan resurser:
app('PlunkoServiceFabricCluster').traces
| where customDimensions.ProviderName == 'Microsoft-ServiceFabric'
| extend EventId = toint(customDimensions.EventId), TaskName = tostring(customDimensions.TaskName)
| where EventId != 17523
| join kind=leftouter ServiceFabricEvent on EventId
| extend EventName = case(EventName != '', EventName, 'Undocumented')
| summarize ["Event Count"]= count() by bin(timestamp, 30m), EventName = strcat(tostring(EventId), " - ", EventName)
| render timechart
Visa Service Fabric-programhändelser
Du kan visa händelser för tillförlitliga tjänster och tillförlitliga aktörsprogram som distribueras i klustret. På sidan Service Fabric Analytics väljer du grafen för Programhändelser.
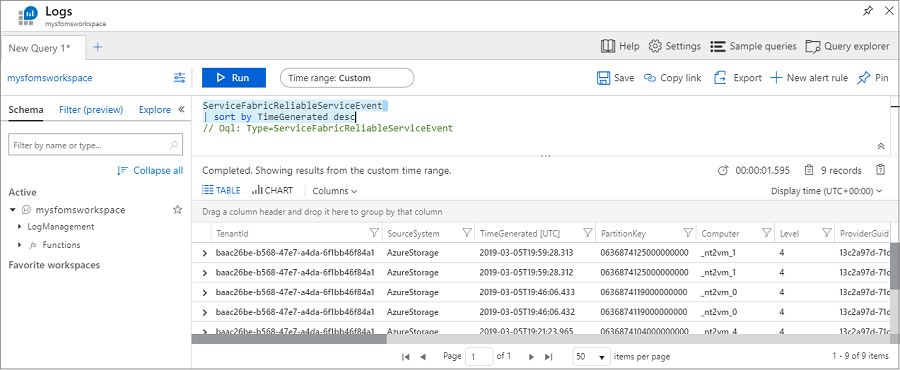
Kör följande fråga för att visa händelser från dina tillförlitliga tjänstprogram:
ServiceFabricReliableServiceEvent
| sort by TimeGenerated desc
Du kan se olika händelser för när tjänsten runasync startas och slutförs, vilket vanligtvis sker vid distributioner och uppgraderingar.
Du kan också hitta händelser för den tillförlitliga tjänsten med ServiceName == "fabric:/Watchdog/WatchdogService":
ServiceFabricReliableServiceEvent
| where ServiceName == "fabric:/Watchdog/WatchdogService"
| project TimeGenerated, EventMessage
| order by TimeGenerated desc
Tillförlitliga aktörshändelser kan visas på ett liknande sätt:
ServiceFabricReliableActorEvent
| sort by TimeGenerated desc
Om du vill konfigurera mer detaljerade händelser för tillförlitliga aktörer kan du ändra scheduledTransferKeywordFilter i konfigurationen för diagnostiktillägget i klustermallen. Information om värdena för dessa finns i referensen för tillförlitliga aktörers händelser.
"EtwEventSourceProviderConfiguration": [
{
"provider": "Microsoft-ServiceFabric-Actors",
"scheduledTransferKeywordFilter": "1",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableActorEventTable"
}
},
Visa prestandaräknare med Azure Monitor-loggar
Om du vill visa prestandaräknare går du till Azure-portalen och resursgruppen där du skapade Service Fabric Analytics-lösningen.
Välj resursen ServiceFabric(mysfomsworkspace), sedan Log Analytics-arbetsyta och sedan Avancerade inställningar.
Välj Data och välj sedan Prestandaräknare för Windows. Det finns en lista över standardräknare som du kan välja att aktivera och du kan också ange intervallet för samlingen. Du kan också lägga till ytterligare prestandaräknare att samla in. Rätt format refereras till i den här artikeln. Klicka på Spara och välj sedan OK.
Stäng bladet Avancerade inställningar och välj Sammanfattning av arbetsyta under rubriken Allmänt . För var och en av de lösningar som är aktiverade finns det en grafisk panel, inklusive en för Service Fabric. Välj diagrammet Service Fabric för att fortsätta till Service Fabric Analytics-lösningen.
Det finns grafiska paneler för driftkanal och tillförlitliga tjänstehändelser. Den grafiska representationen av data som flödar in för de räknare som du har valt visas under Nodmått.
Välj diagrammet Container metric (Container Metric) om du vill visa mer information. Du kan också köra frågor mot prestandaräknare på liknande sätt som klusterhändelser och filtrera på noderna, perf-räknarens namn och värden med hjälp av Kusto-frågespråket.
Fråga EventStore-tjänsten
EventStore-tjänsten är ett sätt att förstå tillståndet för klustret eller arbetsbelastningarna vid en viss tidpunkt. EventStore är en tillståndskänslig Service Fabric-tjänst som underhåller händelser från klustret. Händelserna exponeras via Service Fabric Explorer, REST och API:er. EventStore frågar klustret direkt för att hämta diagnostikdata på en entitet i klustret Om du vill se en fullständig lista över händelser som är tillgängliga i EventStore läser du Service Fabric-händelser.
EventStore-API:erna kan frågas programmatiskt med hjälp av Service Fabric-klientbiblioteket.
Här är en exempelbegäran för alla klusterhändelser mellan 2018-04-03T18:00:00Z och 2018-04-04T18:00:00Z via funktionen GetClusterEventListAsync.
var sfhttpClient = ServiceFabricClientFactory.Create(clusterUrl, settings);
var clstrEvents = sfhttpClient.EventsStore.GetClusterEventListAsync(
"2018-04-03T18:00:00Z",
"2018-04-04T18:00:00Z")
.GetAwaiter()
.GetResult()
.ToList();
Här är ett annat exempel som frågar efter klusterhälsan och alla nodhändelser i september 2018 och skriver ut dem.
const int timeoutSecs = 60;
var clusterUrl = new Uri(@"http://localhost:19080"); // This example is for a Local cluster
var sfhttpClient = ServiceFabricClientFactory.Create(clusterUrl);
var clusterHealth = sfhttpClient.Cluster.GetClusterHealthAsync().GetAwaiter().GetResult();
Console.WriteLine("Cluster Health: {0}", clusterHealth.AggregatedHealthState.Value.ToString());
Console.WriteLine("Querying for node events...");
var nodesEvents = sfhttpClient.EventsStore.GetNodesEventListAsync(
"2018-09-01T00:00:00Z",
"2018-09-30T23:59:59Z",
timeoutSecs,
"NodeDown,NodeUp")
.GetAwaiter()
.GetResult()
.ToList();
Console.WriteLine("Result Count: {0}", nodesEvents.Count());
foreach (var nodeEvent in nodesEvents)
{
Console.Write("Node event happened at {0}, Node name: {1} ", nodeEvent.TimeStamp, nodeEvent.NodeName);
if (nodeEvent is NodeDownEvent)
{
var nodeDownEvent = nodeEvent as NodeDownEvent;
Console.WriteLine("(Node is down, and it was last up at {0})", nodeDownEvent.LastNodeUpAt);
}
else if (nodeEvent is NodeUpEvent)
{
var nodeUpEvent = nodeEvent as NodeUpEvent;
Console.WriteLine("(Node is up, and it was last down at {0})", nodeUpEvent.LastNodeDownAt);
}
}
Övervaka hälsotillstånd hos kluster
Service Fabric introducerar en hälsomodell med hälsoentiteter där systemkomponenter och vakthundar kan rapportera lokala förhållanden som de övervakar. Hälsolagret aggregerar alla hälsodata för att avgöra om entiteter är felfria.
Klustret fylls automatiskt i med hälsorapporter som skickas av systemkomponenterna. Läs mer i Använda systemhälsorapporter för att felsöka.
Service Fabric exponerar hälsofrågor för var och en av de entitetstyper som stöds. De kan nås via API:et med hjälp av metoder på FabricClient.HealthManager, PowerShell-cmdletar och REST. Dessa frågor returnerar fullständig hälsoinformation om entiteten: aggregerat hälsotillstånd, händelser för entitetshälsa, underordnade hälsotillstånd (i förekommande fall), felaktiga utvärderingar (när entiteten inte är felfri) och hälsostatistik för underordnade (i förekommande fall).
Hämta klusterhälsa
Cmdleten Get-ServiceFabricClusterHealth returnerar hälsotillståndet för klusterentiteten och innehåller hälsotillståndet för program och noder (underordnade i klustret). Anslut först till klustret med hjälp av cmdleten Connect-ServiceFabricCluster.
Klustrets tillstånd är 11 noder, systemprogrammet och infrastrukturresurser:/Röstning konfigurerat enligt beskrivningen.
I följande exempel hämtas klusterhälsa med hjälp av standardhälsoprinciper. De 11 noderna är felfria, men klustrets aggregerade hälsotillstånd är Fel eftersom programmet fabric:/Voting är i Fel. Observera hur de felaktiga utvärderingarna ger information om de villkor som utlöste den aggregerade hälsan.
Get-ServiceFabricClusterHealth
AggregatedHealthState : Error
UnhealthyEvaluations :
100% (1/1) applications are unhealthy. The evaluation tolerates 0% unhealthy applications.
Application 'fabric:/Voting' is in Error.
33% (1/3) deployed applications are unhealthy. The evaluation tolerates 0% unhealthy deployed applications.
Deployed application on node '_nt2vm_3' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '8723eb73-9b83-406b-9de3-172142ba15f3' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376195593305'.
There was an error during CodePackage activation.The service host terminated with exit code:1
NodeHealthStates :
NodeName : _nt2vm_3
AggregatedHealthState : Ok
NodeName : _nt1vm_4
AggregatedHealthState : Ok
NodeName : _nt2vm_2
AggregatedHealthState : Ok
NodeName : _nt1vm_3
AggregatedHealthState : Ok
NodeName : _nt2vm_1
AggregatedHealthState : Ok
NodeName : _nt1vm_2
AggregatedHealthState : Ok
NodeName : _nt2vm_0
AggregatedHealthState : Ok
NodeName : _nt1vm_1
AggregatedHealthState : Ok
NodeName : _nt1vm_0
AggregatedHealthState : Ok
NodeName : _nt3vm_0
AggregatedHealthState : Ok
NodeName : _nt2vm_4
AggregatedHealthState : Ok
ApplicationHealthStates :
ApplicationName : fabric:/System
AggregatedHealthState : Ok
ApplicationName : fabric:/Voting
AggregatedHealthState : Error
HealthEvents : None
HealthStatistics :
Node : 11 Ok, 0 Warning, 0 Error
Replica : 4 Ok, 0 Warning, 0 Error
Partition : 2 Ok, 0 Warning, 0 Error
Service : 2 Ok, 0 Warning, 0 Error
DeployedServicePackage : 3 Ok, 1 Warning, 1 Error
DeployedApplication : 1 Ok, 1 Warning, 1 Error
Application : 0 Ok, 0 Warning, 1 Error
I följande exempel hämtas hälsotillståndet för klustret med hjälp av en anpassad programprincip. Det filtrerar resultat för att endast hämta program och noder i fel eller varning. I det här exemplet returneras inga noder eftersom alla är felfria. Endast programmet fabric:/Voting respekterar programfiltret. Eftersom den anpassade principen anger att varningar ska betraktas som fel för infrastrukturresursen:/röstningsprogrammet utvärderas programmet som ett fel och det är även klustret.
$appHealthPolicy = New-Object -TypeName System.Fabric.Health.ApplicationHealthPolicy
$appHealthPolicy.ConsiderWarningAsError = $true
$appHealthPolicyMap = New-Object -TypeName System.Fabric.Health.ApplicationHealthPolicyMap
$appUri1 = New-Object -TypeName System.Uri -ArgumentList "fabric:/Voting"
$appHealthPolicyMap.Add($appUri1, $appHealthPolicy)
Get-ServiceFabricClusterHealth -ApplicationHealthPolicyMap $appHealthPolicyMap -ApplicationsFilter "Warning,Error" -NodesFilter "Warning,Error" -ExcludeHealthStatistics
AggregatedHealthState : Error
UnhealthyEvaluations :
100% (1/1) applications are unhealthy. The evaluation tolerates 0% unhealthy applications.
Application 'fabric:/Voting' is in Error.
100% (5/5) deployed applications are unhealthy. The evaluation tolerates 0% unhealthy deployed applications.
Deployed application on node '_nt2vm_3' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '8723eb73-9b83-406b-9de3-172142ba15f3' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376195593305'.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt2vm_2' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '2466f2f9-d5fd-410c-a6a4-5b1e00630cca' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376486201388'.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt2vm_4' is in Error.
100% (1/1) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '5faa5201-eede-400a-865f-07f7f886aa32' is in Error.
'System.Hosting' reported Warning for property 'CodePackageActivation:Code:SetupEntryPoint:131959376207396204'. The evaluation treats
Warning as Error.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt2vm_0' is in Error.
100% (1/1) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '204f1783-f774-4f3a-b371-d9983afaf059' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959375885791093'.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt3vm_0' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '2533ae95-2d2a-4f8b-beef-41e13e4c0081' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376108346272'.
There was an error during CodePackage activation.The service host terminated with exit code:1
NodeHealthStates : None
ApplicationHealthStates :
ApplicationName : fabric:/Voting
AggregatedHealthState : Error
HealthEvents : None
Hämta nodhälsa
Cmdleten Get-ServiceFabricNodeHealth returnerar hälsotillståndet för en nodentitet och innehåller hälsohändelserna som rapporteras på noden. Anslut först till klustret med hjälp av cmdleten Connect-ServiceFabricCluster. I följande exempel hämtas hälsotillståndet för en specifik nod med hjälp av standardhälsoprinciper:
Get-ServiceFabricNodeHealth _nt1vm_3
I följande exempel hämtas hälsotillståndet för alla noder i klustret:
Get-ServiceFabricNode | Get-ServiceFabricNodeHealth | select NodeName, AggregatedHealthState | ft -AutoSize
Hämta systemtjänsthälsa
Hämta den aggregerade hälsan för systemtjänsterna:
Get-ServiceFabricService -ApplicationName fabric:/System | Get-ServiceFabricServiceHealth | select ServiceName, AggregatedHealthState | ft -AutoSize
Nästa steg
I den här självstudiekursen lärde du dig att:
- Visa Service Fabric-händelser
- Fråga EventStore-API:er för klusterhändelser
- Övervaka infrastruktur/samla in perf-räknare
- Visa hälsorapporter för kluster
Gå sedan vidare till följande självstudie för att lära dig hur du skalar ett kluster.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för