Övervaka Azure Service Fabric
I den här artikeln beskrivs:
- De typer av övervakningsdata som du kan samla in för den här tjänsten.
- Sätt att analysera dessa data.
Kommentar
Om du redan är bekant med den här tjänsten och/eller Azure Monitor och bara vill veta hur du analyserar övervakningsdata kan du läsa avsnittet Analysera i slutet av den här artikeln.
När du har viktiga program och affärsprocesser som är beroende av Azure-resurser måste du övervaka och få aviseringar för systemet. Azure Monitor-tjänsten samlar in och aggregerar mått och loggar från varje komponent i systemet. Azure Monitor ger dig en översikt över tillgänglighet, prestanda och motståndskraft och meddelar dig om problem. Du kan använda Azure Portal, PowerShell, Azure CLI, REST API eller klientbibliotek för att konfigurera och visa övervakningsdata.
- Mer information om Azure Monitor finns i Översikt över Azure Monitor.
- Mer information om hur du övervakar Azure-resurser i allmänhet finns i Övervaka Azure-resurser med Azure Monitor.
Azure Service Fabric-övervakning
Azure Service Fabric har följande lager som du kan övervaka:
- Programövervakning: De program som körs på noderna. Du kan övervaka program med Application Insights-nyckel eller SDK, EventStore eller ASP.NET Core-loggning.
- Plattformsövervakning (kluster): Klientmått, loggar och händelser för plattforms - eller klusternoderna , inklusive containermått. Måtten och loggarna skiljer sig åt för Linux- eller Windows-noder.
- Övervakning av infrastruktur (prestanda): Tjänststatus och prestandaräknare för tjänstinfrastrukturen.
Du kan övervaka hur dina program används, vilka åtgärder som vidtas av Service Fabric-plattformen, resursanvändningen med prestandaräknare och klustrets övergripande hälsotillstånd. Azure Monitor-loggar och Application Insights erbjuder inbyggd integrering med Service Fabric.
- Mer information om metodtips finns i Metodtips för övervakning och diagnostik för Azure Service Fabric.
- En självstudiekurs som visar hur du visar Service Fabric-händelser och hälsorapporter, frågar EventStore-API:er och övervakar prestandaräknare finns i Självstudie: Övervaka ett Service Fabric-kluster i Azure.
- Mer information om hur du konfigurerar Azure Monitor-loggar för att övervaka dina Windows-containrar som är orkestrerade i Service Fabric finns i Självstudie: Övervaka Windows-containrar i Service Fabric med hjälp av Azure Monitor-loggar.
Service Fabric Explorer
Service Fabric Explorer, ett skrivbordsprogram för Windows, macOS och Linux, är ett verktyg med öppen källkod för att inspektera och hantera Azure Service Fabric-kluster. För att aktivera automatisering kan alla åtgärder som kan vidtas via Service Fabric Explorer också utföras via PowerShell eller ett REST-API.
Programövervakning
Programövervakning spårar hur funktioner och komponenter i ditt program används. Du vill övervaka dina program för att se till att problem som påverkar användarna fångas. Ansvaret för programövervakning ligger på användarna som utvecklar ett program och dess tjänster eftersom det är unikt för programmets affärslogik. Övervakning av dina program kan vara användbart i följande scenarier:
- Hur mycket trafik upplever mitt program? – Behöver du skala dina tjänster för att uppfylla användarnas krav eller åtgärda en potentiell flaskhals i ditt program?
- Lyckas och spåras mina tjänst-till-tjänst-anrop?
- Vilka åtgärder vidtas av användarna av mitt program? – Insamling av telemetri kan vägleda framtida funktionsutveckling och bättre diagnostik för programfel
- Utlöser mitt program ohanterade undantag?
- Vad händer inom de tjänster som körs i mina containrar?
Det fantastiska med programövervakning är att utvecklare kan använda vilka verktyg och ramverk de vill eftersom det finns inom ramen för ditt program! Du kan lära dig mer om Azure-lösningen för programövervakning med Azure Monitor Application Insights i händelseanalys med Application Insights.
Vi har också en självstudiekurs om hur du konfigurerar detta för .NET-program. Den här självstudien beskriver hur du installerar rätt verktyg, ett exempel för att skriva anpassad telemetri i ditt program och visa programdiagnostik och telemetri i Azure Portal.
Programloggning
Instrumentering av koden är inte bara ett sätt att få insikter om dina användare, utan också det enda sättet att veta om något är fel i ditt program och för att diagnostisera vad som behöver åtgärdas. Även om det tekniskt sett är möjligt att ansluta ett felsökningsprogram till en produktionstjänst är det inte vanligt. Det är därför viktigt att ha detaljerade instrumentationsdata.
Vissa produkter instrumenterar koden automatiskt. Även om de här lösningarna kan fungera bra måste manuell instrumentering nästan alltid vara specifik för din affärslogik. I slutändan måste du ha tillräckligt med information för att kunna felsöka programmet. Service Fabric-program kan instrumenteras med alla loggningsramverk. I det här avsnittet beskrivs några olika sätt att instrumentera koden och när du ska välja en metod framför en annan.
Application Insights SDK: Application Insights har en omfattande integrering med Service Fabric direkt. Användare kan lägga till AI Service Fabric-nuget-paketen och ta emot data och loggar som skapats och samlats in som kan visas i Azure Portal. Dessutom uppmanas användarna att lägga till sin egen telemetri för att diagnostisera och felsöka sina program och spåra vilka tjänster och delar av deras program som används mest. Klassen TelemetryClient i SDK innehåller många sätt att spåra telemetri i dina program. Mer information finns i Händelseanalys och visualisering med Application Insights.
Se ett exempel på hur du instrumenterar och lägger till application insights i ditt program i vår självstudiekurs för övervakning och diagnostisering av ett .NET-program.
EventSource: När du skapar en Service Fabric-lösning från en mall i Visual Studio genereras en EventSource-härledd klass (ServiceEventSource eller ActorEventSource). En mall skapas där du kan lägga till händelser för ditt program eller din tjänst. EventSource-namnet måste vara unikt och bör byta namn från standardmallsträngen MyCompany-solution-project><<>. Att ha flera EventSource-definitioner som använder samma namn orsakar ett problem vid körning. Varje definierad händelse måste ha en unik identifierare. Om en identifierare inte är unik uppstår ett körningsfel. Vissa organisationer förtilldelar värden för identifierare för att undvika konflikter mellan separata utvecklingsteam. Mer information finns i Vances blogg eller MSDN-dokumentationen.
ASP.NET Core-loggning: Det är viktigt att noggrant planera hur du ska instrumentera koden. Rätt instrumenteringsplan kan hjälpa dig att undvika att potentiellt destabilisera din kodbas och sedan behöva ominstrumentera koden. För att minska risken kan du välja ett instrumentationsbibliotek som Microsoft.Extensions.Logging, som är en del av Microsoft ASP.NET Core. ASP.NET Core har ett ILogger-gränssnitt som du kan använda med valfri leverantör, samtidigt som effekten på befintlig kod minimeras. Du kan använda koden i ASP.NET Core i Windows och Linux, och i hela .NET Framework, så att instrumentationskoden är standardiserad.
Exempel på hur du använder dessa förslag finns i Lägga till loggning i ditt Service Fabric-program.
Plattformsövervakning (kluster)
En användare har kontroll över vilken telemetri som kommer från deras program eftersom en användare skriver själva koden, men hur är det med diagnostiken från Service Fabric-plattformen? Ett av Service Fabrics mål är att hålla program motståndskraftiga mot maskinvarufel. Det här målet uppnås genom plattformens systemtjänsters förmåga att identifiera infrastrukturproblem och snabbt redundansväxla arbetsbelastningar till andra noder i klustret. Men i det här specifika fallet, vad händer om systemtjänsterna själva har problem? Eller om regler för placering av tjänster överträds vid försök att distribuera eller flytta en arbetsbelastning? Service Fabric tillhandahåller diagnostik för dessa och mer för att se till att du är informerad om aktivitet som äger rum i klustret. Några exempelscenarier för klusterövervakning är:
Mer information om plattformsövervakning (kluster) finns i Övervaka klustret.
Service Fabric-händelser
Service Fabric tillhandahåller en omfattande uppsättning diagnostikhändelser direkt, som du kan komma åt via EventStore eller den operativa händelsekanal som plattformen exponerar. Dessa Service Fabric-händelser illustrerar åtgärder som utförs av plattformen på olika entiteter, till exempel noder, program, tjänster och partitioner. Samma händelser är tillgängliga i både Windows- och Linux-kluster.
Service Fabric-händelsekanaler: I Windows är Service Fabric-händelser tillgängliga från en enda ETW-provider med en uppsättning relevanta
logLevelKeywordFilterssom används för att välja mellan kanaler för drift och data och meddelanden. Det här är det sätt på vilket vi separerar utgående Service Fabric-händelser som ska filtreras efter behov. I Linux kommer Service Fabric-händelser via LTTng och placeras i en Lagringstabell, varifrån de kan filtreras efter behov. Dessa kanaler innehåller utvalda, strukturerade händelser som kan användas för att bättre förstå klustrets tillstånd. Diagnostik aktiveras som standard när klustret skapas, vilket skapar en Azure Storage-tabell där händelserna från dessa kanaler skickas så att du kan fråga i framtiden.EventStore är en funktion som visar Service Fabric-plattformshändelser i Service Fabric Explorer och programmatiskt via REST-API:et för Service Fabric-klientbiblioteket . Du kan se en ögonblicksbildsvy över vad som händer i klustret för varje nod, tjänst och program och fråga baserat på tidpunkten för händelsen. EventStore-API:erna är endast tillgängliga för Windows-kluster som körs i Azure. På Windows-datorer matas dessa händelser in i händelseloggen, så du kan se Service Fabric-händelser i Loggboken.
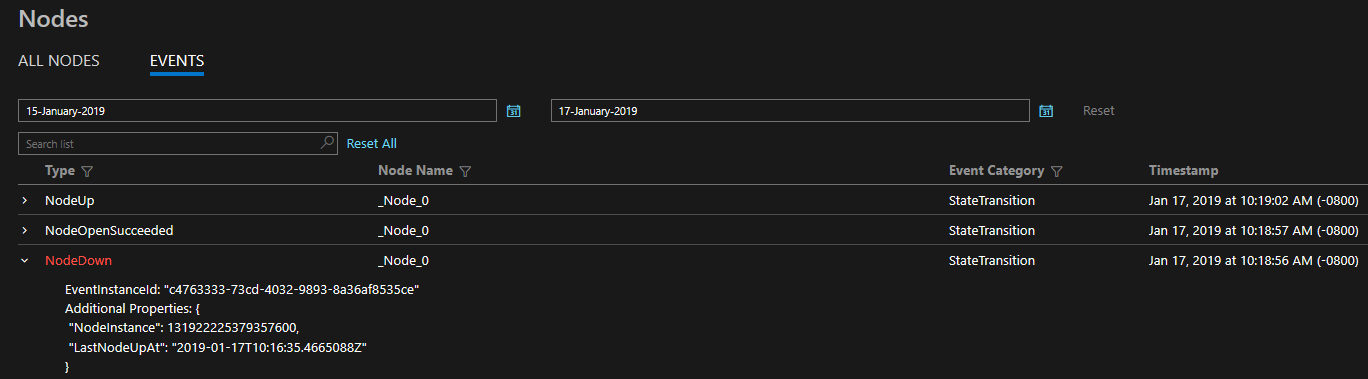
Diagnostiken som tillhandahålls är i form av en omfattande uppsättning händelser direkt. Dessa Service Fabric-händelser illustrerar åtgärder som utförs av plattformen på olika entiteter, till exempel noder, program, tjänster, partitioner osv. I det sista scenariot ovan, om en nod skulle gå ner, skulle plattformen generera en NodeDown händelse och du kan meddelas omedelbart av ditt valfritt övervakningsverktyg. Andra vanliga exempel är ApplicationUpgradeRollbackStarted eller PartitionReconfigured under en redundansväxling. Samma händelser är tillgängliga i både Windows- och Linux-kluster.
Händelserna skickas via standardkanaler i både Windows och Linux och kan läsas av alla övervakningsverktyg som stöder dessa. Azure Monitor-lösningen är Azure Monitor-loggar. Läs gärna mer om vår Integrering av Azure Monitor-loggar som innehåller en anpassad instrumentpanel för ditt kluster och några exempelfrågor som du kan skapa aviseringar från. Fler klusterövervakningskoncept finns tillgängliga på plattformsnivå för händelse- och logggenerering.
Hälsoövervakning
Service Fabric-plattformen innehåller en hälsomodell som tillhandahåller utökningsbar hälsorapportering för status för entiteter i ett kluster. Varje nod, program, tjänst, partition, replik eller instans har en ständigt uppdaterbar hälsostatus. Hälsostatusen kan antingen vara "OK", "Varning" eller "Fel". Tänk på Service Fabric-händelser som verb som görs av klustret till olika entiteter och hälsa som ett adjektiv för varje entitet. Varje gång hälsotillståndet för en viss entitet övergår genereras även en händelse. På så sätt kan du ställa in frågor och aviseringar för hälsohändelser i valfritt övervakningsverktyg, precis som andra händelser.
Dessutom låter vi även användare åsidosätta hälsotillståndet för entiteter. Om ditt program genomgår en uppgradering och verifieringstesterna misslyckas kan du skriva till Service Fabric Health med hjälp av hälso-API:et för att indikera att programmet inte längre är felfritt, och Service Fabric återställer uppgraderingen automatiskt! Mer information om hälsomodellen finns i introduktionen till Service Fabric-hälsoövervakning
Vakthundar
I allmänhet är en vakthund en separat tjänst som bevakar hälsa och belastning för tjänster, pingar slutpunkter och rapporterar oväntade hälsohändelser i klustret. Detta kan hjälpa till att förhindra fel som kanske inte identifieras enbart baserat på prestanda för en enda tjänst. Vakthundar är också en bra plats för att vara värd för kod som utför åtgärdsåtgärder som inte kräver användarinteraktion, till exempel att rensa loggfiler i lagring vid vissa tidsintervall. Om du vill ha en fullständigt implementerad öppen källkod SF-övervakningstjänst som innehåller en lätthanterlig utökningsmodell för vakthundar och som körs i både Windows- och Linux-kluster, se FabricObserver-projektet. FabricObserver är produktionsklar programvara. Vi rekommenderar att du distribuerar FabricObserver till dina test- och produktionskluster och utökar det för att uppfylla dina behov, antingen via dess plugin-modell eller genom att förgrena den och skriva egna inbyggda observatörer. Den tidigare metoden (plugin-program) är den rekommenderade metoden.
Övervakning av infrastruktur (prestanda)
Nu när vi har gått igenom diagnostiken i ditt program och plattformen, hur vet vi att maskinvaran fungerar som förväntat? Att övervaka din underliggande infrastruktur är en viktig del av att förstå tillståndet för klustret och resursutnyttjandet. Mätning av systemprestanda beror på många faktorer som kan vara subjektiva beroende på dina arbetsbelastningar. Dessa faktorer mäts vanligtvis via prestandaräknare. Dessa prestandaräknare kan komma från en mängd olika källor, inklusive operativsystemet, .NET-ramverket eller själva Service Fabric-plattformen. Vissa scenarier där de skulle vara användbara är
- Använder jag maskinvaran effektivt? Vill du använda maskinvaran med 90 % CPU eller 10 % CPU. Detta är praktiskt när du skalar klustret eller optimerar programmets processer.
- Kan jag förutsäga infrastrukturproblem proaktivt? – Många problem föregås av plötsliga ändringar (sänkningar) av prestanda, så du kan använda prestandaräknare som nätverks-I/O och CPU-användning för att förutsäga och diagnostisera problemen proaktivt.
En lista över prestandaräknare som ska samlas in på infrastrukturnivå finns i Prestandamått.
Azure Monitor-loggar rekommenderas för övervakning av händelser på klusternivå. När du har konfigurerat Log Analytics-agenten med din arbetsyta kan du samla in:
- Prestandamått som cpu-användning.
- .NET-prestandaräknare, till exempel processoranvändning på processnivå.
- Service Fabric-prestandaräknare, till exempel antal undantag från en tillförlitlig tjänst.
- Containermått, till exempel CPU-användning.
Resurstyper
Azure använder begreppet resurstyper och ID:t för att identifiera allt i en prenumeration. Resurstyper ingår också i resurs-ID:t för varje resurs som körs i Azure. En resurstyp för en virtuell dator är Microsoft.Compute/virtualMachinestill exempel . En lista över tjänster och deras associerade resurstyper finns i Resursprovidrar.
Azure Monitor organiserar på liknande sätt kärnövervakningsdata i mått och loggar baserat på resurstyper, även kallade namnområden. Olika mått och loggar är tillgängliga för olika resurstyper. Tjänsten kan vara associerad med mer än en resurstyp.
Mer information om resurstyperna för Azure Service Fabric finns i Referens för Service Fabric-övervakningsdata.
Datalagring
För Azure Monitor:
- Måttdata lagras i Azure Monitor-måttdatabasen.
- Loggdata lagras i Azure Monitor-loggarkivet. Log Analytics är ett verktyg i Azure Portal som kan köra frågor mot det här arkivet.
- Azure-aktivitetsloggen är ett separat arkiv med ett eget gränssnitt i Azure Portal.
Du kan också dirigera mått- och aktivitetsloggdata till Azure Monitor-loggarkivet. Du kan sedan använda Log Analytics för att fråga efter data och korrelera dem med andra loggdata.
Många tjänster kan använda diagnostikinställningar för att skicka mått- och loggdata till andra lagringsplatser utanför Azure Monitor. Exempel är Azure Storage, värdbaserade partnersystem och icke-Azure-partnersystem med hjälp av Event Hubs.
Detaljerad information om hur Azure Monitor lagrar data finns i Azure Monitor-dataplattformen.
Azure Monitor-plattformsmått
Azure Monitor tillhandahåller plattformsmått för många tjänster. En lista över alla mått som du kan samla in för alla resurser i Azure Monitor finns i Mått som stöds i Azure Monitor.
Den här tjänsten samlar inte in plattformsmått.
Icke-Azure Monitor-baserade mått
Den här tjänsten tillhandahåller andra mått som inte ingår i Azure Monitor-måttdatabasen.
Mått för gästoperativsystem
Mått för gästoperativsystemet (OS) som körs på Service Fabric-klusternoder måste samlas in via en eller flera agenter som körs på gästoperativsystemet. Mått för gästoperativsystem inkluderar prestandaräknare som spårar gäst-CPU-procent eller minnesanvändning, som båda används ofta för automatisk skalning eller aviseringar.
Bästa praxis är att använda och konfigurera Azure Monitor-agenten för att skicka prestandamått för gästoperativsystem via API:et för anpassade mått till Azure Monitor-måttdatabasen. Du kan skicka måtten för gästoperativsystem till Azure Monitor-loggar med hjälp av samma agent. Sedan kan du fråga efter dessa mått och loggar med hjälp av Log Analytics.
Kommentar
Azure Monitor-agenten ersätter Azure Diagnostics-tillägget och Log Analytics-agenten för routning av gästoperativsystem. Mer information finns i Översikt över Azure Monitor-agenter.
Azure Monitor-resursloggar
Resursloggar ger insikter om åtgärder som har utförts av en Azure-resurs. Loggar genereras automatiskt, men du måste dirigera dem till Azure Monitor-loggar för att spara eller köra frågor mot dem. Loggar är ordnade i kategorier. Ett angivet namnområde kan ha flera resursloggkategorier som du kan samla in.
Den här tjänsten samlar inte in resursloggar, men du kan hitta information om dem i Övervaka data från Azure-resurser.
Service Fabric-loggar och -händelser
Service Fabric kan samla in följande loggar:
- För Windows-kluster kan du konfigurera klusterövervakning med Diagnostikagent och Azure Monitor-loggar.
- För Linux-kluster är Azure Monitor-loggar också det rekommenderade verktyget för azure-plattforms- och infrastrukturövervakning. Linux-plattformsdiagnostik kräver olika konfigurationer. Mer information finns i Service Fabric Linux-klusterhändelser i Syslog.
- Du kan konfigurera Azure Monitor-agenten för att skicka gästoperativsystemloggar till Azure Monitor-loggar, där du kan fråga efter dem med hjälp av Log Analytics.
- Du kan skriva Service Fabric-containerloggar till stdout eller stderr så att de är tillgängliga i Azure Monitor-loggar.
- Du kan konfigurera containerövervakningslösningen för Azure Monitor-loggar för att visa containerhändelser.
Andra loggningslösningar
Även om de två lösningar som vi rekommenderade, Azure Monitor-loggar och Application Insights, har byggt in integrering med Service Fabric, skrivs många händelser ut via ETW-leverantörer och kan utökningsbara med andra loggningslösningar. Du bör också titta på Elastic Stack (särskilt om du överväger att köra ett kluster i en offlinemiljö), Dynatrace eller någon annan plattform som du föredrar. En lista över integrerade partner finns i Azure Service Fabric Monitoring Partners.
Viktiga punkter för alla plattformar som du väljer bör vara hur bekväm du är med användargränssnittet, frågefunktionerna, de anpassade visualiseringarna och instrumentpanelerna som är tillgängliga och de ytterligare verktyg som de tillhandahåller för att förbättra din övervakningsupplevelse.
Azure-aktivitetslogg
Aktivitetsloggen innehåller händelser på prenumerationsnivå som spårar åtgärder för varje Azure-resurs som visas utanför resursen. till exempel att skapa en ny resurs eller starta en virtuell dator.
Samling: Aktivitetslogghändelser genereras automatiskt och samlas in i ett separat arkiv för visning i Azure Portal.
Routning: Du kan skicka aktivitetsloggdata till Azure Monitor-loggar så att du kan analysera dem tillsammans med andra loggdata. Andra platser som Azure Storage, Azure Event Hubs och vissa Microsoft-övervakningspartner är också tillgängliga. Mer information om hur du dirigerar aktivitetsloggen finns i Översikt över Azure-aktivitetsloggen.
Analysera övervakningsdata
Det finns många verktyg för att analysera övervakningsdata.
Azure Monitor-verktyg
Azure Monitor har stöd för följande grundläggande verktyg:
Metrics Explorer, ett verktyg i Azure Portal som gör att du kan visa och analysera mått för Azure-resurser. Mer information finns i Analysera mått med Azure Monitor Metrics Explorer.
Log Analytics, ett verktyg i Azure Portal som gör att du kan köra frågor mot och analysera loggdata med hjälp av Kusto-frågespråket (KQL). Mer information finns i Kom igång med loggfrågor i Azure Monitor.
Aktivitetsloggen, som har ett användargränssnitt i Azure Portal för visning och grundläggande sökningar. Om du vill göra mer djupgående analys måste du dirigera data till Azure Monitor-loggar och köra mer komplexa frågor i Log Analytics.
Verktyg som möjliggör mer komplex visualisering är:
- Instrumentpaneler som gör att du kan kombinera olika typer av data i ett enda fönster i Azure Portal.
- Arbetsböcker, anpassningsbara rapporter som du kan skapa i Azure Portal. Arbetsböcker kan innehålla text-, mått- och loggfrågor.
- Grafana, ett öppet plattformsverktyg som utmärker sig i operativa instrumentpaneler. Du kan använda Grafana för att skapa instrumentpaneler som innehåller data från flera andra källor än Azure Monitor.
- Power BI, en tjänst för affärsanalys som tillhandahåller interaktiva visualiseringar mellan olika datakällor. Du kan konfigurera Power BI för att automatiskt importera loggdata från Azure Monitor för att dra nytta av dessa visualiseringar.
En översikt över vanliga scenarier för Service Fabric-övervakningsanalys finns i Diagnostisera vanliga scenarier med Service Fabric.
Exportverktyg för Azure Monitor
Du kan hämta data från Azure Monitor till andra verktyg med hjälp av följande metoder:
Mått: Använd REST-API:et för mått för att extrahera måttdata från Azure Monitor-måttdatabasen. API:et stöder filteruttryck för att förfina de data som hämtas. Mer information finns i Azure Monitor REST API-referens.
Loggar: Använd REST-API:et eller de associerade klientbiblioteken.
Ett annat alternativ är dataexporten för arbetsytan.
Information om hur du kommer igång med REST-API:et för Azure Monitor finns i Genomgång av REST API för Azure-övervakning.
Kusto-frågor
Du kan analysera övervakningsdata i Azure Monitor-loggar/Log Analytics-arkivet med hjälp av Kusto-frågespråket (KQL).
Viktigt!
När du väljer Loggar på tjänstens meny i portalen öppnas Log Analytics med frågeomfånget inställt på den aktuella tjänsten. Det här omfånget innebär att loggfrågor endast innehåller data från den typen av resurs. Om du vill köra en fråga som innehåller data från andra Azure-tjänster väljer du Loggar på Azure Monitor-menyn . Mer information finns i Log query scope and time range in Azure Monitor Log Analytics (Loggfrågeomfång och tidsintervall i Azure Monitor Log Analytics ).
En lista över vanliga frågor för alla tjänster finns i Log Analytics-frågegränssnittet.
Exempelfrågor
Följande frågor returnerar Service Fabric-händelser, inklusive åtgärder på noder. Andra användbara frågor finns i Service Fabric-händelser.
Returnera operativa händelser som registrerats under den senaste timmen:
ServiceFabricOperationalEvent
| where TimeGenerated > ago(1h)
| join kind=leftouter ServiceFabricEvent on EventId
| project EventId, EventName, TaskName, Computer, ApplicationName, EventMessage, TimeGenerated
| sort by TimeGenerated
Returnera hälsorapporter med HealthState == 3 (fel) och extrahera fler egenskaper från fältet EventMessage :
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| extend HealthStateId = extract(@"HealthState=(\S+) ", 1, EventMessage, typeof(int))
| where TaskName == 'HM' and HealthStateId == 3
| extend SourceId = extract(@"SourceId=(\S+) ", 1, EventMessage, typeof(string)),
Property = extract(@"Property=(\S+) ", 1, EventMessage, typeof(string)),
HealthState = case(HealthStateId == 0, 'Invalid', HealthStateId == 1, 'Ok', HealthStateId == 2, 'Warning', HealthStateId == 3, 'Error', 'Unknown'),
TTL = extract(@"TTL=(\S+) ", 1, EventMessage, typeof(string)),
SequenceNumber = extract(@"SequenceNumber=(\S+) ", 1, EventMessage, typeof(string)),
Description = extract(@"Description='([\S\s, ^']+)' ", 1, EventMessage, typeof(string)),
RemoveWhenExpired = extract(@"RemoveWhenExpired=(\S+) ", 1, EventMessage, typeof(bool)),
SourceUTCTimestamp = extract(@"SourceUTCTimestamp=(\S+)", 1, EventMessage, typeof(datetime)),
ApplicationName = extract(@"ApplicationName=(\S+) ", 1, EventMessage, typeof(string)),
ServiceManifest = extract(@"ServiceManifest=(\S+) ", 1, EventMessage, typeof(string)),
InstanceId = extract(@"InstanceId=(\S+) ", 1, EventMessage, typeof(string)),
ServicePackageActivationId = extract(@"ServicePackageActivationId=(\S+) ", 1, EventMessage, typeof(string)),
NodeName = extract(@"NodeName=(\S+) ", 1, EventMessage, typeof(string)),
Partition = extract(@"Partition=(\S+) ", 1, EventMessage, typeof(string)),
StatelessInstance = extract(@"StatelessInstance=(\S+) ", 1, EventMessage, typeof(string)),
StatefulReplica = extract(@"StatefulReplica=(\S+) ", 1, EventMessage, typeof(string))
Hämta service fabric-drifthändelser aggregerade med den specifika tjänsten och noden:
ServiceFabricOperationalEvent
| where ApplicationName != "" and ServiceName != ""
| summarize AggregatedValue = count() by ApplicationName, ServiceName, Computer
Aviseringar
Azure Monitor-aviseringar meddelar dig proaktivt när specifika villkor finns i dina övervakningsdata. Med aviseringar kan du identifiera och åtgärda problem i systemet innan kunderna märker dem. Mer information finns i Azure Monitor-aviseringar.
Det finns många källor till vanliga aviseringar för Azure-resurser. Exempel på vanliga aviseringar för Azure-resurser finns i Exempelloggaviseringsfrågor. Webbplatsen Azure Monitor Baseline Alerts (AMBA) innehåller en halvautomatiserad metod för att implementera viktiga plattformsmåttaviseringar, instrumentpaneler och riktlinjer. Webbplatsen gäller för en kontinuerligt expanderande delmängd av Azure-tjänster, inklusive alla tjänster som ingår i Azure Landing Zone (ALZ).
Det gemensamma aviseringsschemat standardiserar förbrukningen av Azure Monitor-aviseringsmeddelanden. Mer information finns i Vanliga aviseringsscheman.
Typer av aviseringar
Du kan avisera om valfritt mått eller loggdatakälla på Azure Monitor-dataplattformen. Det finns många olika typer av aviseringar beroende på vilka tjänster du övervakar och de övervakningsdata som du samlar in. Olika typer av aviseringar har olika fördelar och nackdelar. Mer information finns i Välj rätt övervakningsaviseringstyp.
I följande lista beskrivs de typer av Azure Monitor-aviseringar som du kan skapa:
- Måttaviseringar utvärderar resursmått med jämna mellanrum. Mått kan vara plattformsmått, anpassade mått, loggar från Azure Monitor som konverterats till mått eller Application Insights-mått. Måttaviseringar kan också tillämpa flera villkor och dynamiska tröskelvärden.
- Med loggaviseringar kan användare använda en Log Analytics-fråga för att utvärdera resursloggar med en fördefinierad frekvens.
- Aktivitetsloggaviseringar utlöses när en ny aktivitetslogghändelse inträffar som matchar definierade villkor. Resource Health-aviseringar och Service Health-aviseringar är aktivitetsloggaviseringar som rapporterar om tjänstens och resurshälsan.
Vissa Azure-tjänster stöder även aviseringar om smart identifiering, Prometheus-aviseringar eller rekommenderade aviseringsregler.
För vissa tjänster kan du övervaka i stor skala genom att tillämpa samma måttaviseringsregel på flera resurser av samma typ som finns i samma Azure-region. Enskilda meddelanden skickas för varje övervakad resurs. Information om Azure-tjänster och moln som stöds finns i Övervaka flera resurser med en aviseringsregel.
Service Fabric-aviseringsregler
I följande tabell visas några aviseringsregler för Service Fabric. Dessa aviseringar är bara exempel. Du kan ange aviseringar för alla mått, loggposter eller aktivitetsloggposter som anges i referensen för Service Fabric-övervakningsdata eller listan över Service Fabric-händelser.
| Aviseringstyp | Villkor | beskrivning |
|---|---|---|
| Nodhändelse | Noden går ned | ServiceFabricOperationalEvent där EventID >= 25622 och EventID <= 25626. Dessa händelse-ID:er finns i referensen för Node-händelser. |
| Programhändelse | Återställning av programuppgradering | ServiceFabricOperationalEvent där EventID == 29623 eller EventID == 29624. Dessa händelse-ID:er finns i referensen programhändelser. |
| Resurshälsa | Uppgraderingstjänsten kan inte nås/är inte tillgänglig | Klustret går till UpgradeServiceUnreachable-tillstånd. |
Advisor-rekommendationer
För vissa tjänster, om kritiska villkor eller överhängande ändringar inträffar under resursåtgärder, visas en avisering på sidan Tjänstöversikt i portalen. Du hittar mer information och rekommenderade korrigeringar för aviseringen i Advisor-rekommendationer under Övervakning i den vänstra menyn. Under normal drift visas inga advisor-rekommendationer.
Mer information om Azure Advisor finns i Översikt över Azure Advisor.
Rekommenderad installation
Nu när vi har gått igenom varje område med övervaknings- och exempelscenarier, här är en sammanfattning av Azure-övervakningsverktygen och konfigureras som behövs för att övervaka alla områden ovan.
- Programövervakning med Application Insights
- Klusterövervakning med Diagnostikagent och Azure Monitor-loggar
- Infrastrukturövervakning med Azure Monitor-loggar
Du kan också använda och ändra ARM-exempelmallen för att automatisera distributionen av alla nödvändiga resurser och agenter.
Relaterat innehåll
- Se Referens för Service Fabric-övervakningsdata för en referens till mått, loggar och andra viktiga värden som skapats för Service Fabric.
- Mer information om övervakning av Azure-resurser finns i Övervaka Azure-resurser med Azure Monitor .
- Se listan över Service Fabric-händelser.