Design och prestanda för Netezza-migreringar
Den här artikeln är del ett i en serie i sju delar som ger vägledning om hur du migrerar från Netezza till Azure Synapse Analytics. Fokus i den här artikeln är metodtips för design och prestanda.
Översikt
På grund av att supporten från IBM upphör vill många befintliga användare av Netezzas informationslagersystem dra nytta av de innovationer som tillhandahålls av moderna molnmiljöer. Med molnmiljöerna Infrastruktur som en tjänst (IaaS) och PaaS (plattform som en tjänst) kan du delegera uppgifter som infrastrukturunderhåll och plattformsutveckling till molnleverantören.
Dricks
Mer än bara en databas – Azure-miljön innehåller en omfattande uppsättning funktioner och verktyg.
Även om Netezza och Azure Synapse Analytics båda är SQL-databaser som använder MPP-tekniker (massively parallel processing) för att uppnå höga frågeprestanda på exceptionellt stora datavolymer finns det några grundläggande skillnader i metoden:
Äldre Netezza-system installeras ofta lokalt och använder egen maskinvara, medan Azure Synapse är molnbaserat och använder Azure-lagrings- och beräkningsresurser.
Att uppgradera en Netezza-konfiguration är en viktig uppgift med extra fysisk maskinvara och potentiellt lång databasomkonfiguration, eller dumpning och omläsning. Eftersom lagrings- och beräkningsresurser är separata i Azure-miljön och har elastisk skalningskapacitet kan dessa resurser skalas uppåt eller nedåt oberoende av varandra.
Du kan pausa eller ändra storlek på Azure Synapse efter behov för att minska resursanvändningen och kostnaderna.
Microsoft Azure är en globalt tillgänglig, mycket säker och skalbar molnmiljö som innehåller Azure Synapse och ett ekosystem med stödverktyg och funktioner. Nästa diagram sammanfattar Azure Synapse-ekosystemet.
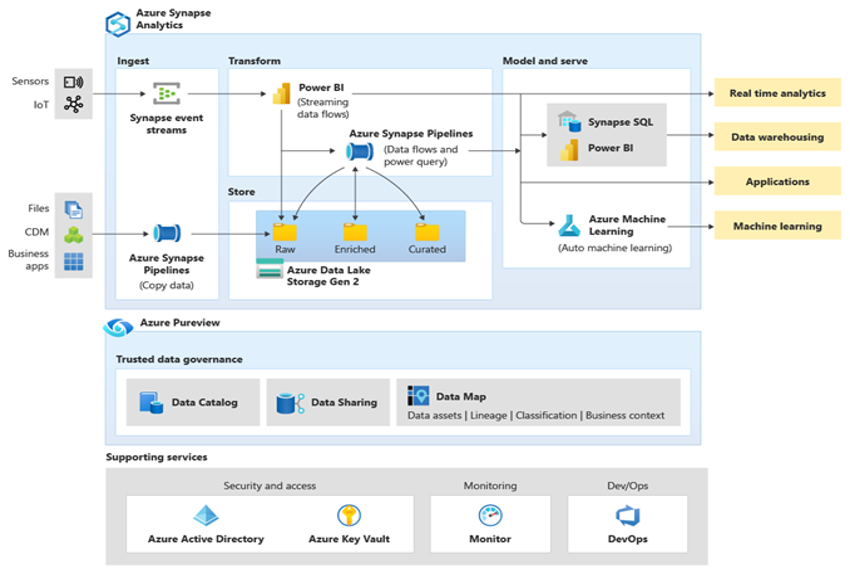
Azure Synapse ger bästa möjliga relationsdatabasprestanda med hjälp av tekniker som MPP och flera nivåer av automatiserad cachelagring för data som används ofta. Du kan se resultatet av dessa tekniker i oberoende benchmarks, till exempel den som nyligen kördes av GigaOm, som jämför Azure Synapse med andra populära molndatalagererbjudanden. Kunder som migrerar till Azure Synapse-miljön ser många fördelar, bland annat:
Förbättrad prestanda och pris/prestanda.
Ökad flexibilitet och kortare tid till värde.
Snabbare serverdistribution och programutveckling.
Elastisk skalbarhet – betala endast för faktisk användning.
Förbättrad säkerhet/efterlevnad.
Minskade kostnader för lagring och haveriberedskap.
Lägre total TCO, bättre kostnadskontroll och effektivare driftsutgifter (OPEX).
För att maximera dessa fördelar migrerar du nya eller befintliga data och program till Azure Synapse-plattformen. I många organisationer omfattar migrering att flytta ett befintligt informationslager från en äldre lokal plattform, till exempel Netezza, till Azure Synapse. På hög nivå omfattar migreringsprocessen följande steg:
Förberedelse 🡆
Definiera omfång – vad som ska migreras.
Skapa en inventering av data och processer för migrering.
Definiera ändringar i datamodellen (om det finns några).
Definiera mekanismen för källdataextrakt.
Identifiera lämpliga Verktyg och funktioner från Azure och tredje part som ska användas.
Utbilda personalen tidigt på den nya plattformen.
Konfigurera Azure-målplattformen.
Migrering 🡆
Börja litet och enkelt.
Automatisera när det är möjligt.
Använd inbyggda Azure-verktyg och funktioner för att minska migreringsarbetet.
Migrera metadata för tabeller och vyer.
Migrera historiska data som ska underhållas.
Migrera eller omstrukturera lagrade procedurer och affärsprocesser.
Migrera eller omstrukturera inkrementella inläsningsprocesser för ETL/ELT.
Efter migreringen
Övervaka och dokumentera alla faser i processen.
Använd upplevelsen för att skapa en mall för framtida migreringar.
Återskapa datamodellen om det behövs (med nya plattformsprestanda och skalbarhet).
Testa program och frågeverktyg.
Prestandatesta och optimera frågeprestanda.
Den här artikeln innehåller allmän information och riktlinjer för prestandaoptimering när du migrerar ett informationslager från en befintlig Netezza-miljö till Azure Synapse. Målet med prestandaoptimering är att uppnå samma eller bättre informationslagerprestanda i Azure Synapse efter schemamigrering.
Utformningsbeaktanden
Migreringsomfång
När du förbereder migreringen från en Netezza-miljö bör du överväga följande migreringsalternativ.
Välj arbetsbelastningen för den första migreringen
Vanligtvis har äldre Netezza-miljöer utvecklats över tid för att omfatta flera ämnesområden och blandade arbetsbelastningar. När du bestämmer var du ska börja med ett migreringsprojekt väljer du ett område där du kan:
Bevisa hur bra det är att migrera till Azure Synapse genom att snabbt leverera fördelarna med den nya miljön.
Låt din interna tekniska personal få relevant erfarenhet av de processer och verktyg som de kommer att använda när de migrerar andra områden.
Skapa en mall för ytterligare migreringar som är specifika för Netezza-källmiljön och de aktuella verktygen och processerna som redan finns.
En bra kandidat för en inledande migrering från en Netezza-miljö stöder föregående objekt och:
Implementerar en BI/Analytics-arbetsbelastning i stället för en arbetsbelastning för onlinetransaktionsbearbetning (OLTP).
Har en datamodell, till exempel ett star- eller snowflake-schema, som kan migreras med minimal ändring.
Dricks
Skapa en inventering av objekt som behöver migreras och dokumentera migreringsprocessen.
Mängden migrerade data i en inledande migrering bör vara tillräckligt stor för att demonstrera funktionerna och fördelarna med Azure Synapse-miljön, men inte för stor för att snabbt kunna visa värde. En storlek på 1–10 terabyte är typisk.
För det första migreringsprojektet minimerar du risken, ansträngningen och migreringstiden så att du snabbt kan se fördelarna med Azure-molnmiljön. Både lift-and-shift och stegvisa migreringsmetoder begränsar omfattningen för den inledande migreringen till bara data marts och tar inte upp bredare migreringsaspekter som ETL-migrering och historisk datamigrering. Du kan dock hantera dessa aspekter i senare faser av projektet när det migrerade data mart-lagret fylls på med data och de nödvändiga byggprocesserna.
Lift and shift-migrering jämfört med stegvis metod
I allmänhet finns det två typer av migrering oavsett syftet med och omfattningen av den planerade migreringen: lift and shift as-is och en stegvis metod som innehåller ändringar.
Lift and Shift
Vid en lift and shift-migrering migreras en befintlig datamodell, till exempel ett star-schema, oförändrad till den nya Azure Synapse-plattformen. Den här metoden minimerar risken och migreringstiden genom att minska det arbete som krävs för att utnyttja fördelarna med att flytta till Azure-molnmiljön. Lift and Shift-migrering passar bra för följande scenarier:
- Du har en befintlig Netezza-miljö med en enda data mart att migrera, eller
- Du har en befintlig Netezza-miljö med data som redan finns i ett väldesignade star- eller snowflake-schema, eller
- Du är under tids- och kostnadsbelastning för att övergå till en modern molnmiljö.
Dricks
Lift and shift är en bra utgångspunkt, även om efterföljande faser implementerar ändringar i datamodellen.
Stegvis metod som innehåller ändringar
Om ett äldre informationslager har utvecklats under en lång tidsperiod kan du behöva återskapa det för att upprätthålla de prestandanivåer som krävs. Du kan också behöva omkonstruera för att stödja nya data som IoT-strömmar (Internet of Things). Som en del av ombyggnadsprocessen migrerar du till Azure Synapse för att få fördelarna med en skalbar molnmiljö. Migrering kan också innehålla en ändring i den underliggande datamodellen, till exempel en flytt från en Inmon-modell till ett datavalv.
Microsoft rekommenderar att du flyttar din befintliga datamodell som den är till Azure och använder prestanda och flexibilitet i Azure-miljön för att tillämpa de omdefinierade ändringarna. På så sätt kan du använda Azures funktioner för att göra ändringarna utan att påverka det befintliga källsystemet.
Använda Azure Data Factory för att implementera en metadatadriven migrering
Du kan automatisera och samordna migreringsprocessen med hjälp av funktionerna i Azure-miljön. Den här metoden minimerar prestandan i den befintliga Netezza-miljön, som kanske redan körs nära kapaciteten.
Azure Data Factory är en molnbaserad dataintegreringstjänst som har stöd för att skapa datadrivna arbetsflöden i molnet som samordnar och automatiserar dataflytt och datatransformering. Du kan använda Data Factory för att skapa och schemalägga datadrivna arbetsflöden (pipelines) som matar in data från olika datalager. Data Factory kan bearbeta och transformera data med hjälp av beräkningstjänster som Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics och Azure Mašinsko učenje.
När du planerar att använda Data Factory-anläggningar för att hantera migreringsprocessen skapar du metadata som visar alla datatabeller som ska migreras och deras plats.
Designskillnader mellan Netezza och Azure Synapse
Som tidigare nämnts finns det några grundläggande skillnader i metod mellan Netezza- och Azure Synapse Analytics-databaser och dessa skillnader diskuteras härnäst.
Flera databaser jämfört med en enskild databas och scheman
Netezza-miljön innehåller ofta flera separata databaser. Det kan till exempel finnas separata databaser för: datainmatning och mellanlagringstabeller, kärnlagertabeller och data marts (kallas ibland semantiska lager). ETL- eller ELT-pipelineprocesser kan implementera kopplingar mellan databaser och flytta data mellan de separata databaserna.
Azure Synapse-miljön innehåller däremot en enkel databas och använder scheman för att dela upp tabeller i logiskt separata grupper. Vi rekommenderar att du använder en serie scheman i Azure Synapse-måldatabasen för att efterlikna de separata databaser som migrerats från Netezza-miljön. Om Netezza-miljön redan använder scheman kan du behöva använda en ny namngivningskonvention när du flyttar de befintliga Netezza-tabellerna och vyerna till den nya miljön. Du kan till exempel sammanfoga det befintliga Netezza-schemat och tabellnamnen till det nya Azure Synapse-tabellnamnet och använda schemanamn i den nya miljön för att underhålla de ursprungliga separata databasnamnen. Om namngivning av schemakonsolidering har punkter kan Azure Synapse Spark ha problem. Även om du kan använda SQL-vyer ovanpå de underliggande tabellerna för att underhålla de logiska strukturerna finns det potentiella nackdelar med den metoden:
Vyer i Azure Synapse är skrivskyddade, så alla uppdateringar av data måste ske i de underliggande bastabellerna.
Det kan redan finnas ett eller flera skikt av vyer och att lägga till ett extra lager vyer kan påverka prestanda och support eftersom kapslade vyer är svåra att felsöka.
Dricks
Kombinera flera databaser till en enskild databas i Azure Synapse och använd schemanamn för att logiskt separera tabellerna.
Tabellöverväganden
När du migrerar tabeller mellan olika miljöer är det vanligtvis bara rådata och metadata som beskriver dem fysiskt migrera. Andra databaselement från källsystemet, till exempel index, migreras vanligtvis inte eftersom de kan vara onödiga eller implementerade på olika sätt i den nya miljön.
Prestandaoptimeringar i källmiljön, till exempel index, anger var du kan lägga till prestandaoptimering i den nya miljön. Om till exempel frågor i Netezza-källmiljön ofta använder zonkartor, föreslår det att ett icke-grupperat index ska skapas i Azure Synapse. Andra inbyggda tekniker för prestandaoptimering som tabelreplikering kan vara mer tillämpliga än att skapa ett direkt index som liknar varandra.
Dricks
Befintliga index anger kandidater för indexering i det migrerade lagret.
Netezza-databasobjekttyper som inte stöds
Netezza-specifika funktioner kan ofta ersättas av Azure Synapse-funktioner. Vissa Netezza-databasobjekt stöds dock inte direkt i Azure Synapse. Följande lista över Netezza-databasobjekt som inte stöds beskriver hur du kan uppnå motsvarande funktioner i Azure Synapse.
Zonkartor: i Netezza skapas och underhålls zonkartor automatiskt för följande kolumntyper och används vid frågetillfället för att begränsa mängden data som ska genomsökas:
INTEGERkolumner med längd 8 byte eller mindre.- Temporala kolumner, till exempel
DATE,TIMEochTIMESTAMP. CHARkolumner om de ingår i en materialiserad vy och nämns iORDER BY-satsen.
Du kan ta reda på vilka kolumner som har zonkartor med hjälp
nz_zonemapav verktyget, som är en del av NZ Toolkit. Azure Synapse inkluderar inte zonkartor, men du kan uppnå liknande resultat med hjälp av andra användardefinierade indextyper och/eller partitionering.Klustrade bastabeller (CBT): I Netezza används KBT ofta för faktatabeller, som kan ha miljarder poster. Genomsökning av en sådan enorm tabell kräver lång bearbetningstid eftersom en fullständig tabellgenomsökning kan behövas för att hämta relevanta poster. Genom att ordna poster på restriktiva KBT:er kan Netezza gruppera poster i samma eller närliggande utsträckning. Den här processen skapar även zonkartor som förbättrar prestandan genom att minska mängden data som behöver genomsökas.
I Azure Synapse kan du uppnå en liknande effekt genom att partitionera och/eller använda andra index.
Materialiserade vyer: Netezza stöder materialiserade vyer och rekommenderar att du använder en eller flera materialiserade vyer för stora tabeller med många kolumner om bara några få kolumner används regelbundet i frågor. Materialiserade vyer uppdateras automatiskt av systemet när data i bastabellen uppdateras.
Azure Synapse stöder materialiserade vyer med samma funktioner som Netezza.
Netezza-datatypsmappning
De flesta Netezza-datatyper har en direkt motsvarighet i Azure Synapse. I följande tabell visas den rekommenderade metoden för att mappa Netezza-datatyper till Azure Synapse.
| Netezza-datatyp | Azure Synapse-datatyp |
|---|---|
| BIGINT | BIGINT |
| BINÄR VARIERANDE(n) | VARBINARY(n) |
| BOOLESK | BIT |
| BYTEINT | TINYINT |
| CHARACTER VARYING(n) | VARCHAR(n) |
| CHARACTER(n) | CHAR(n) |
| DATUM | DATUM(datum) |
| DECIMAL(p,s) | DECIMAL(p,s) |
| DUBBEL PRECISION | FLYTA |
| FLOAT(n) | FLOAT(n) |
| INTEGER | INT |
| INTERVALL | INTERVAL-datatyper stöds för närvarande inte direkt i Azure Synapse, men kan beräknas med hjälp av temporala funktioner som DATEDIFF. |
| PENGAR | PENGAR |
| NATIONELLA TECKEN VARIERANDE(n) | NVARCHAR(n) |
| NATIONELLA TECKEN(n) | NCHAR(n) |
| NUMERIC(p,s) | NUMERIC(p,s) |
| REAL | REAL |
| SMALLINT | SMALLINT |
| ST_GEOMETRY(n) | Rumsliga datatyper som ST_GEOMETRY stöds för närvarande inte i Azure Synapse, men data kan lagras som VARCHAR eller VARBINARY. |
| TID | TID |
| TID MED TIDSZON | DATETIMEOFFSET |
| TIMESTAMP | DATETIME |
Dricks
Utvärdera antalet och typen av datatyper som inte stöds under migreringsförberedelsefasen.
Tredjepartsleverantörer erbjuder verktyg och tjänster för att automatisera migreringen, inklusive mappning av datatyper. Om ett ETL-verktyg från tredje part redan används i Netezza-miljön använder du verktyget för att implementera nödvändiga datatransformeringar.
Skillnader i SQL DML-syntax
SQL DML-syntaxskillnader finns mellan Netezza SQL och Azure Synapse T-SQL. Dessa skillnader beskrivs i detalj i Minimera SQL-problem för Netezza-migreringar.
STRPOS: i NetezzaSTRPOSreturnerar funktionen positionen för en delsträng i en sträng. Motsvarande funktion i Azure Synapse ärCHARINDEXmed omvänd ordning på argumenten. Till exempelSELECT STRPOS('abcdef','def')...i Netezza motsvararSELECT CHARINDEX('def','abcdef')...i Azure Synapse.AGE: Netezza stöder operatornAGEför att ge intervallet mellan två temporala värden, till exempel tidsstämplar eller datum, till exempel:SELECT AGE('23-03-1956','01-01-2019') FROM.... I Azure Synapse använder duDATEDIFFför att hämta intervallet, till exempel:SELECT DATEDIFF(day, '1956-03-26','2019-01-01') FROM.... Observera datumrepresentationssekvensen.NOW(): Netezza använderNOW()för att representeraCURRENT_TIMESTAMPi Azure Synapse.
Funktioner, lagrade procedurer och sekvenser
När du migrerar ett informationslager från en mogen miljö som Netezza måste du förmodligen migrera andra element än enkla tabeller och vyer. Kontrollera om verktyg i Azure-miljön kan ersätta funktionerna i funktioner, lagrade procedurer och sekvenser eftersom det vanligtvis är mer effektivt att använda inbyggda Azure-verktyg än att koda om dessa element för Azure Synapse.
Som en del av förberedelsefasen skapar du en inventering av objekt som behöver migreras, definierar en metod för att hantera dem och allokerar lämpliga resurser i migreringsplanen.
Dataintegreringspartner erbjuder verktyg och tjänster som kan automatisera migreringen av funktioner, lagrade procedurer och sekvenser.
I följande avsnitt beskrivs vidare migrering av funktioner, lagrade procedurer och sekvenser.
Functions
Precis som med de flesta databasprodukter har Netezza stöd för system- och användardefinierade funktioner i en SQL-implementering. När du migrerar en äldre databasplattform till Azure Synapse kan vanliga systemfunktioner vanligtvis migreras utan ändringar. Vissa systemfunktioner kan ha en något annorlunda syntax, men alla nödvändiga ändringar kan automatiseras.
För Netezza-systemfunktioner eller godtyckliga användardefinierade funktioner som inte har någon motsvarighet i Azure Synapse ska du koda om dessa funktioner med hjälp av ett målmiljöspråk. Användardefinierade netezza-funktioner kodas på nzlua- eller C++-språk. Azure Synapse använder transact-SQL-språket för att implementera användardefinierade funktioner.
Lagrade procedurer
De flesta moderna databasprodukter stöder lagring av procedurer i databasen. Netezza tillhandahåller NZPLSQL-språket, som är baserat på Postgres PL/pgSQL, för detta ändamål. En lagrad procedur innehåller vanligtvis både SQL-instruktioner och procedurlogik och returnerar data eller status.
Azure Synapse stöder lagrade procedurer med T-SQL, så du måste koda om alla migrerade lagrade procedurer på det språket.
Sekvenser
I Netezza är en sekvens ett namngivet databasobjekt som skapats med hjälp av CREATE SEQUENCE. En sekvens ger unika numeriska värden via NEXT VALUE FOR metoden. Du kan använda de genererade unika talen som surrogatnyckelvärden för primära nycklar.
Azure Synapse implementerar CREATE SEQUENCEinte , men du kan implementera sekvenser med IDENTITY-kolumner eller SQL-kod som genererar nästa sekvensnummer i en serie.
Extrahera metadata och data från en Netezza-miljö
Generering av datadefinitionsspråk (DDL)
ANSI SQL-standarden definierar den grundläggande syntaxen för DDL-kommandon (Data Definition Language). Vissa DDL-kommandon, till exempel CREATE TABLE och CREATE VIEW, är gemensamma för både Netezza och Azure Synapse men har utökats för att tillhandahålla implementeringsspecifika funktioner.
Du kan redigera befintliga Netezza CREATE TABLE och CREATE VIEW skript för att uppnå motsvarande definitioner i Azure Synapse. För att göra det kan du behöva använda ändrade datatyper och ta bort eller ändra Netezza-specifika satser som ORGANIZE ON.
I Netezza-miljön anger systemkatalogtabeller den aktuella tabellen och vydefinitionen. Till skillnad från användarunderhållen dokumentation är systemkataloginformationen alltid fullständig och synkroniserad med aktuella tabelldefinitioner. Genom att använda verktyg som nz_ddl_tablekan du komma åt systemkataloginformation för att generera CREATE TABLE DDL-instruktioner som skapar motsvarande tabeller i Azure Synapse.
Du kan också använda migrering från tredje part och ETL-verktyg som bearbetar systemkataloginformation för att uppnå liknande resultat.
Extrahering av data från Netezza
Du kan extrahera rådata från Netezza-tabeller till platta avgränsade filer, till exempel CSV-filer, med hjälp av netezza-standardverktyg som nzsql och nzunload eller via externa tabeller. Sedan kan du komprimera de platta avgränsade filerna med hjälp av gzip och ladda upp de komprimerade filerna till Azure Blob Storage med azcopy- eller Azure-datatransportverktyg som Azure Data Box.
Extrahera tabelldata så effektivt som möjligt. Använd metoden för externa tabeller eftersom det är den snabbaste extraheringsmetoden. Utför flera extraheringar parallellt för att maximera dataextraheringsdataflödet. Följande SQL-instruktion utför ett externt tabellextrakt:
CREATE EXTERNAL TABLE '/tmp/export_tab1.csv' USING (DELIM ',') AS SELECT * from <TABLENAME>;
Om det finns tillräckligt med nätverksbandbredd kan du extrahera data från ett lokalt Netezza-system direkt till Azure Synapse-tabeller eller Azure Blob Data Storage. Det gör du genom att använda Data Factory-processer eller datamigrering från tredje part eller ETL-produkter.
Dricks
Använd externa Netezza-tabeller för den mest effektiva dataextraheringen.
Extraherade datafiler ska innehålla avgränsad text i CSV-, Optimerad radkolumn (ORC) eller Parquet-format.
Mer information om hur du migrerar data och ETL från en Netezza-miljö finns i Datamigrering, ETL och inläsning för Netezza-migreringar.
Prestandarekommendationer för Netezza-migreringar
Målet med prestandaoptimering är samma eller bättre prestanda för informationslagret efter migreringen till Azure Synapse.
Likheter i begrepp för prestandajusteringsmetoden
Många prestandajusteringsbegrepp för Netezza-databaser gäller för Azure Synapse-databaser. Till exempel:
Använd datadistribution för att samla in data som ska kopplas till samma bearbetningsnod.
Använd den minsta datatypen för en viss kolumn för att spara lagringsutrymme och påskynda frågebearbetningen.
Se till att kolumner som ska kopplas har samma datatyp för att optimera kopplingsbearbetningen och minska behovet av datatransformering.
Se till att statistiken är uppdaterad för att optimeraren ska kunna skapa den bästa körningsplanen.
Övervaka prestanda med hjälp av inbyggda databasfunktioner för att säkerställa att resurserna används effektivt.
Dricks
Prioritera kunskaper om justeringsalternativen i Azure Synapse i början av en migrering.
Skillnader i prestandajusteringsmetod
Det här avsnittet belyser skillnader i implementering av prestandajustering på låg nivå mellan Netezza och Azure Synapse.
Alternativ för datadistribution
För prestanda har Azure Synapse utformats med arkitektur med flera noder och använder parallell bearbetning. För att optimera tabellprestanda kan du definiera ett alternativ för datadistribution i CREATE TABLE instruktioner med hjälp av DISTRIBUTION i Azure Synapse och DISTRIBUTE ON i Netezza.
Till skillnad från Netezza stöder Azure Synapse lokala kopplingar mellan en liten tabell och en stor tabell via liten tabellreplikering. Tänk dig till exempel en liten dimensionstabell och en stor faktatabell i en star-schemamodell. Azure Synapse kan replikera den mindre dimensionstabellen över alla noder för att säkerställa att värdet för en kopplingsnyckel för den stora tabellen har en matchande, lokalt tillgänglig dimensionsrad. Omkostnaderna för replikering av dimensionstabeller är relativt låga för en liten dimensionstabell. För stora dimensionstabeller är en hashdistributionsmetod mer lämplig. Mer information om alternativ för datadistribution finns i Designvägledning för att använda replikerade tabeller och vägledning för att utforma distribuerade tabeller.
Dataindexering
Azure Synapse stöder flera användardefinierbara indexeringsalternativ som har en annan åtgärd och användning jämfört med systemhanterade zonkartor i Netezza. Mer information om de olika indexeringsalternativen i Azure Synapse finns i Index för dedikerade SQL-pooltabeller.
De befintliga systemhanterade zonkartorna i en Netezza-källmiljö ger en användbar indikation på dataanvändning och kandidatkolumnerna för indexering i Azure Synapse-miljön.
Datapartitionering
I ett informationslager för företag kan faktatabeller innehålla miljarder rader. Partitionering optimerar underhåll och frågeprestanda för dessa tabeller genom att dela upp dem i separata delar för att minska mängden data som bearbetas. I Azure Synapse definierar -instruktionen CREATE TABLE partitioneringsspecifikationen för en tabell.
Du kan bara använda ett fält per tabell för partitionering. Det fältet är ofta ett datumfält eftersom många frågor filtreras efter datum eller datumintervall. Det går att ändra partitioneringen av en tabell efter den första inläsningen med hjälp av CTAS-instruktionen CREATE TABLE AS för att återskapa tabellen med en ny distribution. En detaljerad beskrivning av partitionering i Azure Synapse finns i Partitionering av tabeller i en dedikerad SQL-pool.
Statistik för datatabeller
Du bör se till att statistiken för datatabeller är uppdaterad genom att skapa ett statistiksteg till ETL/ELT-jobb.
PolyBase eller COPY INTO för datainläsning
PolyBase stöder effektiv inläsning av stora mängder data till ett informationslager med hjälp av parallella inläsningsströmmar. Mer information finns i PolyBase-datainläsningsstrategi.
COPY INTO stöder också datainmatning med högt dataflöde och:
Datahämtning från alla filer i en mapp och undermappar.
Datahämtning från flera platser i samma lagringskonto. Du kan ange flera platser med hjälp av kommaavgränsade sökvägar.
Azure Data Lake Storage (ADLS) och Azure Blob Storage.
CSV-, PARQUET- och ORC-filformat.
Arbetsbelastningshantering
Att köra blandade arbetsbelastningar kan innebära resursutmaningar i upptagna system. Ett lyckat arbetsbelastningshanteringsschema hanterar effektivt resurser, säkerställer högeffektiv resursanvändning och maximerar avkastningen på investeringen (ROI). Arbetsbelastningsklassificering, arbetsbelastningsbetydelse och arbetsbelastningsisolering ger mer kontroll över hur arbetsbelastningen använder systemresurser.
Guiden för arbetsbelastningshantering beskriver de tekniker som används för att analysera arbetsbelastningen, hantera och övervaka arbetsbelastningens betydelse samt stegen för att konvertera en resursklass till en arbetsbelastningsgrupp. Använd Azure-portalen och T-SQL-frågor på DMV:er för att övervaka arbetsbelastningen för att säkerställa att tillämpliga resurser används effektivt.
Nästa steg
Mer information om ETL och inläsning för Netezza-migrering finns i nästa artikel i den här serien: Datamigrering, ETL och inläsning för Netezza-migreringar.