Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Tip
Microsoft Fabric Data Warehouse är ett relationslager i företagsskala på en datasjögrund med en framtidsklar arkitektur, inbyggd AI och nya funktioner. Om du är nybörjare på datalager börjar du med Fabric Data Warehouse. Befintliga dedicerade SQL-poolarbetsbelastningar kan uppgraderas till Fabric för att få åtkomst till nya funktioner inom datavetenskap, realtidsanalys och rapportering.
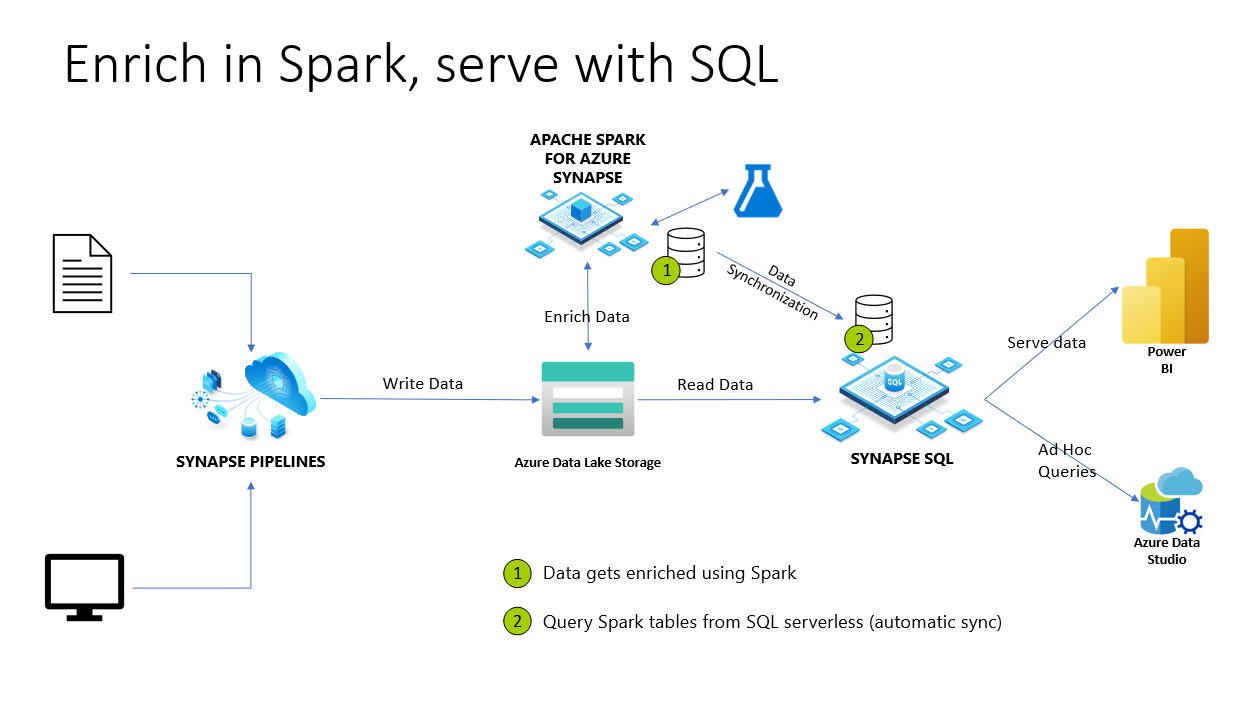
I Azure Synapse Analytics delas Spark-databaser och tabeller med en serverlös SQL-pool. Lake-databaser, Parquet- och CSV-säkerhetskopierade tabeller som skapats med Spark är automatiskt tillgängliga i en serverlös SQL-pool. Med den här funktionen kan du använda en serverlös SQL-pool för att utforska och fråga efter data som förberetts med hjälp av Spark-pooler. I diagrammet nedan kan du se en översikt över arkitektur på hög nivå för att använda den här funktionen. Först flyttar Azure Synapse Pipelines data från lokal (eller annan) lagring till Azure Data Lake Storage. Spark kan nu utöka data och skapa databaser och tabeller som synkroniseras till serverlös Synapse SQL. Senare kan användaren köra ad hoc-frågor ovanpå berikade data eller hantera dem till exempel i Power BI.
Fullständig administratörsåtkomst(sysadmin)
När dessa databaser och tabeller har synkroniserats från Spark till en serverlös SQL-pool kan dessa externa tabeller i en serverlös SQL-pool användas för att komma åt samma data. Objekt i en serverlös SQL-pool är dock endast läsbar för att upprätthålla konsekvens med Spark-poolobjekten. Begränsningen gör att endast användare med Synapse SQL-administratörs- eller Synapse-administratörsroller kan komma åt dessa objekt i en serverlös SQL-pool. Om en icke-administratörsanvändare försöker köra en fråga i den synkroniserade databasen/tabellen får de ett felmeddelande som:
External table '<table>' is not accessible because content of directory cannot be listed. trots att de har åtkomst till data på de underliggande lagringskontona.
Eftersom synkroniserade databaser i en serverlös SQL-pool är skrivskyddade kan de inte ändras. Det går inte att skapa en användare eller ge andra behörigheter om det görs ett försök. För att kunna läsa synkroniserade databaser måste man ha behörigheter på servernivå (till exempel sysadmin). Den här begränsningen finns också i externa tabeller i en serverlös SQL-pool när du använder Tabellerna Azure Synapse Link for Dataverse och Lake Databases.
Icke-administratörsåtkomst till synkroniserade databaser
En användare som behöver läsa data och skapa rapporter har vanligtvis inte fullständig administratörsåtkomst (sysadmin). Den här användaren är vanligtvis dataanalytiker som bara behöver läsa och analysera data med hjälp av befintliga tabeller. De behöver inte skapa nya objekt.
En användare med minimal behörighet bör kunna:
- Ansluta till en databas som replikeras från Spark
- Välj data via externa tabeller och få åtkomst till underliggande ADLS-data.
När du har kört kodskriptet nedan kan användare som inte är administratörer ha behörighet på servernivå att ansluta till valfri databas. Det gör det också möjligt för användare att visa data från alla objekt på schemanivå, till exempel tabeller eller vyer. Dataåtkomstsäkerhet kan hanteras på lagringslagret.
-- Creating Azure AD login (same can be achieved for Azure AD app)
CREATE LOGIN [login@contoso.com] FROM EXTERNAL PROVIDER;
go;
GRANT CONNECT ANY DATABASE to [login@contoso.com];
GRANT SELECT ALL USER SECURABLES to [login@contoso.com];
GO;
Anmärkning
Dessa instruktioner ska köras på huvuddatabasen, eftersom dessa är alla behörigheter på servernivå.
När du har skapat en inloggning och beviljat behörigheter kan användarna köra frågor ovanpå de synkroniserade externa tabellerna. Denna mildring kan också tillämpas på Microsoft Entra-säkerhetsgrupper.
Mer säkerhet för objekten kan hanteras via specifika scheman och låsa åtkomsten till ett specifikt schema. Lösningen kräver extra DDL. I det här scenariot kan du skapa en ny serverlös databas, scheman och vyer som pekar på Spark-tabelldata i ADLS.
Åtkomst till data på lagringskontot kan hanteras via ACL eller vanliga roller för lagringsblobdataägare/läsare/deltagare för Microsoft Entra-användare/-grupper. För tjänstprincipaler (Microsoft Entra-appar) kontrollera att du använder ACL-konfiguration.
Anmärkning
- Om du vill förbjuda användning av OPENROWSET ovanpå data kan du använda
DENY ADMINISTER BULK OPERATIONS to [login@contoso.com];Mer information finns i NEKA Server-behörigheter. - Om du vill förbjuda användning av specifika scheman kan du använda
DENY SELECT ON SCHEMA::[schema_name] TO [login@contoso.com];. Mer information finns i Neka schemabehörigheter.
Nästa steg
Mer information finns i SQL-autentisering.