Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Med Azure Synapse Analytics-arbetsytan kan du skapa två typer av databaser ovanpå en Spark-datasjö:
- Lake-databaser där du kan definiera tabeller ovanpå lakedata med apache Spark-notebook-filer, databasmallar eller Microsoft Dataverse (tidigare Common Data Service). Dessa tabeller kan frågas med T-SQL-språk (Transact-SQL) med hjälp av den serverlösa SQL-poolen.
- SQL-databaser där du kan definiera dina egna databaser och tabeller direkt med hjälp av den serverlösa SQL-poolen. Du kan använda T-SQL CREATE DATABASE, CREATE EXTERNAL TABLE för att definiera objekten och lägga till ytterligare SQL-vyer, procedurer och inline-table-value-funktioner ovanpå tabellerna.
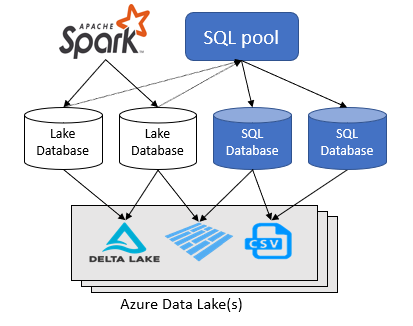
Den här artikeln fokuserar på sjödatabaser i en serverlös SQL-pool i Azure Synapse Analytics.
Med Azure Synapse Analytics kan du skapa lakedatabaser och tabeller med Spark eller databasdesignern och sedan analysera data i sjödatabaserna med hjälp av den serverlösa SQL-poolen. Sjödatabaserna och tabellerna (parquet eller CSV-backade) som skapas i Apache Spark-poolerna, lakedatabasmallarna eller Dataverse är automatiskt tillgängliga för frågor med den serverlösa SQL-poolmotorn. Sjödatabaserna och tabellerna som ändras är tillgängliga i en serverlös SQL-pool efter en stund. Det finns en fördröjning tills ändringarna som görs i Spark eller databasdesignern syns i serverless.
Hantera sjödatabas
Om du vill hantera Spark-skapade lakedatabaser kan du använda Apache Spark-pooler eller databasdesigner. Du kan till exempel skapa eller ta bort en sjödatabas via ett Spark-pooljobb. Du kan inte skapa en sjödatabas eller objekten i sjödatabaserna med hjälp av den serverlösa SQL-poolen.
Spark-databasen default är tillgänglig i den serverlösa SQL-poolkontexten som en lakedatabas med namnet default.
Anteckning
Du kan inte skapa en sjö och en SQL-databas i den serverlösa SQL-poolen med samma namn.
Tabeller i lakedatabaserna kan inte ändras från en serverlös SQL-pool. Använd databasdesignern eller Apache Spark-poolerna för att ändra en lake-databas. Med den serverlösa SQL-poolen kan du göra följande ändringar i en lake-databas med hjälp av T-SQL-kommandon:
- Lägg till, ändra och släppa vyer, procedurer, infogade tabellvärdefunktioner i en sjödatabas.
- Lägg till och ta bort Microsoft Entra-användare som är begränsade till databasen.
- Lägg till eller ta bort Microsoft Entra-databasanvändare i den db_datareader rollen. Microsoft Entra-databasanvändare i rollen db_datareader har behörighet att läsa alla tabeller i lake-databasen, men kan inte läsa data från andra databaser.
Säkerhetsmodell
Sjödatabaserna och tabellerna skyddas på två nivåer:
- Det underliggande lagringsskiktet genom att tilldela Microsoft Entra-användare något av följande:
- Rollbaserad åtkomstkontroll i Azure (Azure RBAC)
- Azure-attributbaserad åtkomstkontrollroll (Azure ABAC)
- Behörigheter för åtkomstkontrollistor (ACL)
- SQL-lagret där du kan definiera en Microsoft Entra-användare och ge SQL-behörigheter till data från tabeller som refererar till
SELECTlake-data.
Sjösäkerhetsmodell
Åtkomst till lake-databasfiler styrs med hjälp av lake-behörigheter på lagringsskiktet. Endast Microsoft Entra-användare kan använda tabeller i lakedatabaserna och de kan komma åt data i sjön med sina egna identiteter.
Du kan bevilja åtkomst till underliggande data som används för externa tabeller till ett säkerhetsobjekt, till exempel: en användare, ett Microsoft Entra-program med tilldelat tjänsthuvudnamn eller en säkerhetsgrupp. Bevilja båda följande behörigheter för dataåtkomst:
- Bevilja
read (R)behörighet för filer (till exempel tabellens underliggande datafiler). - Bevilja
execute (X)behörighet för mappen där filerna lagras och på varje överordnad mapp upp till roten. Du kan läsa mer om dessa behörigheter i åtkomstkontrollistor (ACL:er).
Till exempel behöver säkerhetsprinciper i https://<storage-name>.dfs.core.windows.net/<fs>/synapse/workspaces/<synapse_ws>/warehouse/mytestdb.db/myparquettable/:
-
execute (X)behörigheter för alla mappar som börjar på<fs>tillmyparquettable. -
read (R)behörigheter förmyparquettableoch filer i mappen för att kunna läsa en tabell i en databas (synkroniserad eller ursprunglig).
Om en säkerhetsprincip kräver förmågan att skapa eller ta bort objekt i en databas krävs ytterligare write (W) behörigheter för mapparna och filerna i lagermappen . Det går inte att ändra objekt i en databas från en serverlös SQL-pool, bara från Spark-pooler eller databasdesignern.
SQL-säkerhetsmodell
Azure Synapse-arbetsytan tillhandahåller en T-SQL-slutpunkt som gör att du kan köra frågor mot lakedatabasen med hjälp av den serverlösa SQL-poolen. Förutom dataåtkomsten kan du med SQL-gränssnittet styra vem som kan komma åt tabellerna. Du måste göra det möjligt för en användare att komma åt de delade lakedatabaserna med hjälp av den serverlösa SQL-poolen. Det finns tre typer av användare som kan komma åt sjödatabaserna:
- Administratörer: Tilldela rollen Synapse SQL-administratör eller sysadmin-roll på servernivå i den serverlösa SQL-poolen. Den här rollen har fullständig kontroll över alla databaser. Rollerna Synapse-administratör och Synapse SQL-administratör har också alla behörigheter för alla objekt i en serverlös SQL-pool som standard.
- Arbetsyteläsare: Bevilja behörigheter på servernivå BEVILJA CONNECT ANY DATABASE och BEVILJA ALLA ANVÄNDAR-SÄKERHETER på serverlös SQL-pool till ett inloggningskonto som gör det möjligt för kontot att få tillgång till och läsa alla databaser. Det här kan vara ett bra alternativ för att tilldela läsare/icke-administratörsåtkomst till en användare.
- Databasläsare: Skapa databasanvändare från Microsoft Entra ID i din sjödatanbas och lägg till dem i db_datareader-rollen, vilket gör att de kan läsa data i sjödatanbasen.
Läs mer om hur du ställer in åtkomstkontroll för delade databaser.
Anpassade SQL-objekt i lakedatabaser
Med lakedatabaser kan du skapa anpassade T-SQL-objekt, till exempel scheman, procedurer, vyer och inline table-value functions (iTVFs). För att kunna skapa anpassade SQL-objekt måste du skapa ett schema där du placerar objekten. Det går inte att placera anpassade SQL-objekt i dbo schemat eftersom de är reserverade för de lake-tabeller som definieras i Spark, databasdesignern eller Dataverse.
Viktigt!
Du måste skapa ett anpassat SQL-schema där du ska placera dina SQL-objekt. Det går inte att placera anpassade SQL-objekt i dbo schemat. Schemat dbo är reserverat för de sjötabeller som ursprungligen skapades i Spark eller databasdesignern.
Exempel
Skapa SQL-databasläsare i Lake Database
I det här exemplet lägger vi till en Microsoft Entra-användare i lake-databasen som kan läsa data via delade tabeller. Användarna läggs till i lake-databasen via den serverlösa SQL-poolen. Tilldela sedan användaren till rollen db_datareader så att de kan läsa data.
CREATE USER [customuser@contoso.com] FROM EXTERNAL PROVIDER;
GO
ALTER ROLE db_datareader
ADD MEMBER [customuser@contoso.com];
Skapa dataläsare på arbetsytenivå
En inloggning med GRANT CONNECT ANY DATABASE och GRANT SELECT ALL USER SECURABLES behörigheter kan läsa alla tabeller med hjälp av den serverlösa SQL-poolen, men det går inte att skapa SQL-databaser eller ändra objekten i dem.
CREATE LOGIN [wsdatareader@contoso.com] FROM EXTERNAL PROVIDER
GRANT CONNECT ANY DATABASE TO [wsdatareader@contoso.com]
GRANT SELECT ALL USER SECURABLES TO [wsdatareader@contoso.com]
Med det här skriptet kan du skapa användare utan administratörsbehörighet som kan läsa valfri tabell i Lake-databaser.
Skapa och ansluta till Spark-databasen med en serverlös SQL-pool
Skapa först en ny Spark-databas med namnet mytestlakedb med ett Spark-kluster som du redan har skapat på din arbetsyta. Du kan till exempel uppnå detta med hjälp av en Spark C#-notebook-fil med följande .NET för Spark-instruktion:
spark.sql("CREATE DATABASE mytestlakedb")
Efter en kort fördröjning kan du se lakedatabasen från en serverlös SQL-pool. Kör till exempel följande instruktion från en serverlös SQL-pool.
SELECT * FROM sys.databases;
Kontrollera att mytestlakedb ingår i resultatet.
Skapa anpassade SQL-objekt i lake-databasen
I följande exempel visas hur du skapar en anpassad vy, procedur och infogad tabellvärdefunktion (iTVF) i reports schemat:
CREATE SCHEMA reports
GO
CREATE OR ALTER VIEW reports.GreenReport
AS SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
GROUP BY puYear, puMonth
GO
CREATE OR ALTER PROCEDURE reports.GreenReportSummary
AS BEGIN
SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
GROUP BY puYear, puMonth
END
GO
CREATE OR ALTER FUNCTION reports.GreenDataReportMonthly(@year int)
RETURNS TABLE
RETURN ( SELECT puYear = @year, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
WHERE puYear = @year
GROUP BY puMonth )
GO
Relaterat innehåll
- Delade metadata för Azure Synapse Analytics
- Delade metadatatabeller i Azure Synapse Analytics
- Snabbstart: Skapa en ny lake-databas med hjälp av databasmallar
- Självstudie: Använda serverlös SQL-pool med Power BI Desktop och skapa en rapport
- Synkronisera Apache Spark för externa Azure Synapse-tabelldefinitioner i en serverlös SQL-pool
- Självstudie: Utforska och analysera datasjöar med en serverlös SQL-pool