Ta bort dubbletter i varje tabell för dataidentifiering
Steget Dedupliceringsregler av sammanslagningen hittar och tar bort dubblettposter för en kund från en källtabell så att varje kund representeras av en enda rad i varje tabell. Varje tabell avgränsas separat med hjälp av regler för att identifiera posterna för en viss kund.
Regler bearbetas i ordning. När alla regler har körts på alla poster i en tabell kombineras matchningsgrupper som delar en gemensam rad till en enskild matchningsgrupp.
Definiera regler för deduplicering
En bra regel identifierar en unik kund. Tänk på dina uppgifter. Det kan räcka att identifiera kunder baserat på ett fält som e-post. Om du vill särskilja kunder som delar ett e-postmeddelande kan du välja att ha en regel med två villkor som matchar i E-post + FirstName. Mer information finns i Metodtips för deduplicering.
På sidan Dedupliceringsregler markerar du en tabell och väljer Lägg till regel för att definiera dubblettreglerna.
Dricks
Om du har förädlat tabeller på datakälla nivå för att förbättra resultaten markerar du Använd berikade tabeller längst upp på sidan. Mer information: Berikande för datakällor.
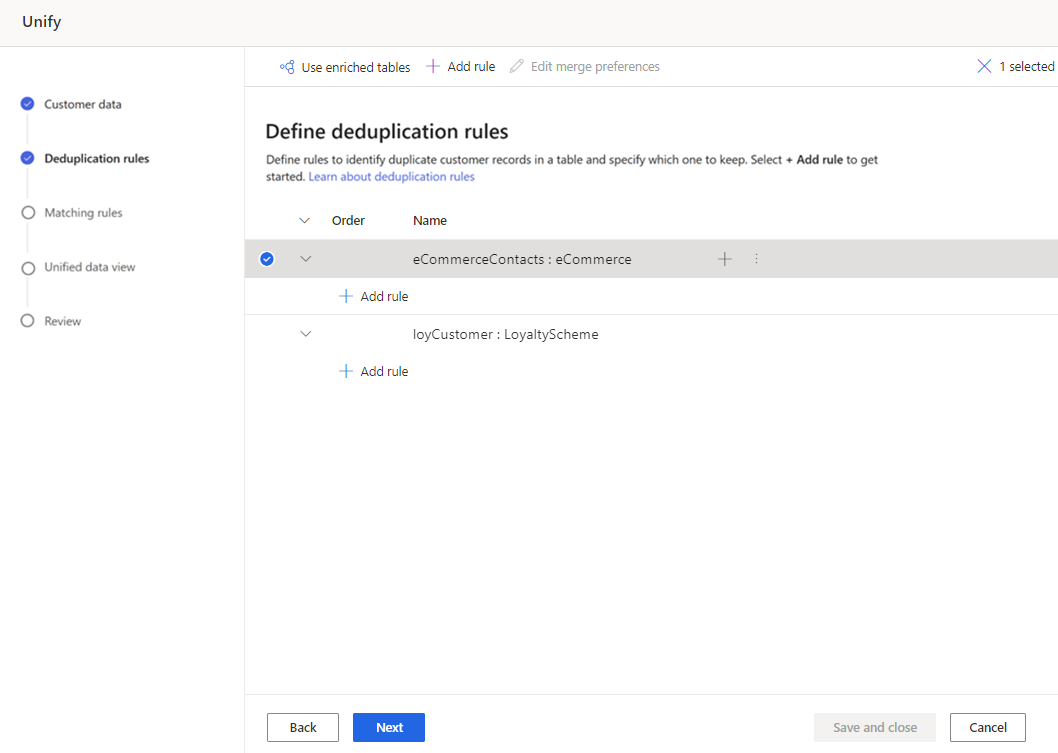
I fönstret Lägg till regel, ange följande information:
Välj fält: Välj i listan över tillgängliga fält från den tabell som du vill söka efter dubbletter i. Välj fält som troligen är unika för varje enskild kund. Till exempel en e-postadress eller kombinationen av namn, ort och telefonnummer.
Normalisera: Väljnormaliseringsalternativ för kolumnen. Normaliseringen påverkar endast det matchande steget och data ändras inte.
- Siffror: Konverterar Unicode-symboler som representerar tal till enkla tal.
- Symboler: Tar bort symboler och specialtecken som !" #$%&'()*+,-./:;<=>?@[]^_'{|}~. Till exempel, Head&Shoulder blir HeadShoulder.
- Text till gemener: Konverterar versaler till gemener. "ALLA VERSALER och rubriker" blir "alla versaler och rubriker."
- Typ (Telefon, Namn, Adress, Organisation): Standardiserar namn, titlar, telefonnummer och adresser.
- Unicode till ASCII: Konverterar Unicode-tecken till deras motsvarighet till ASCII-bokstaven. Exempelvis konverteras ề till e-tecknet.
- Tomt utrymme: Tar bort alla blanksteg. Hello World blir HelloWorld.
- Alias mappning: Gör att du kan ladda upp en anpassad lista med strängpar för att ange strängar som alltid ska betraktas som en exakt matchning.
- Anpassad kringkoppling: Gör att du kan ladda upp en anpassad lista med strängar för att ange strängar som aldrig ska matchas.
Precision: Ställ in precisionsnivån. Precision används för exakt matchning och fuzzy-matchning och avgör hur nära två strängar måste vara för att betraktas som en matchning.
- Grundläggande: Välj mellan Låg (30 %), Medel (60 %), Hög (80 %) och Exakt (100 %). Välj Exakt om du endast vill matcha poster som matchar 100 procent.
- Anpassad: Ange en procentandel som posterna måste matcha. Systemet matchar endast poster som passerar tröskelvärdet.
Namn: Namn för regeln.
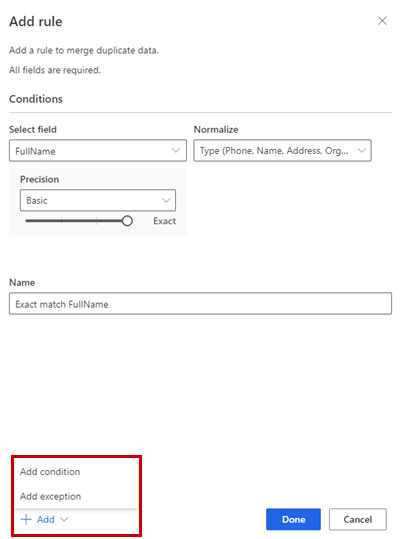
Alternativt väljer du Lägg till>Lägg till villkor om du vill lägga till fler villkor i regeln. Villkoren är kopplade till en logisk OCH-operator och körs därför endast om alla villkor uppfylls.
Alternativt Lägg till>Lägg till undantag till lägga till undantag till regeln. Undantag används för att hantera få fall av falskt positiva och falskt negativa.
Välj Klar för att skapa regeln.
Alternativt kan du lägga till fler regler.
Välj en tabellen och redigera inställningarna för kopplade dokument.
I rutan Kopplingsinställningar:
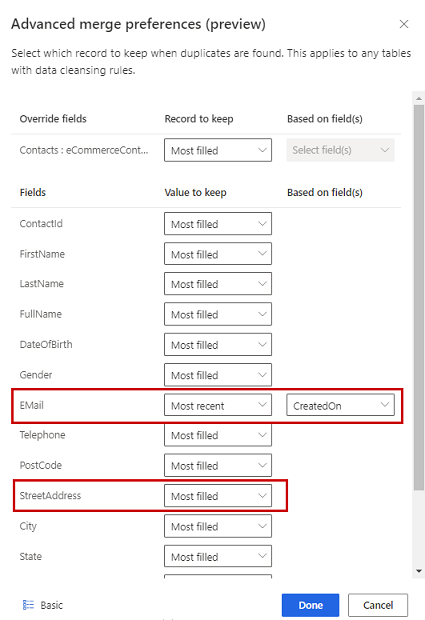
Välj ett av tre alternativ för att avgöra vilken post som ska behållas om en dubblett påträffas:
- Mest ifylld: Identifierar posten med flest befolkade kolumner som vinnarpost. Det här är standardalternativet för sammanfogning.
- Senaste: Identifierar vinnarpost baserat på aktualitet. Kräver ett datum eller ett numeriskt fält för att definiera aktualitet.
- Minst aktuell: Identifierar vinnarpost baserat på lägsta aktualitet. Kräver ett datum eller ett numeriskt fält för att definiera aktualitet.
Vid händelse av en händelse är posten den med MAX(PK) eller det större primärnyckelns värde.
Om du vill definiera kopplingsinställningar för enskilda kolumner för en tabell väljer du Avancerat längst ned i fönstret. Du kan till exempel välja att behålla den senaste e-postadressen OCH den mest fullständiga adressen från olika poster. Expandera tabellen för att se alla dess kolumner och definiera vilket alternativ som ska användas för enskilda kolumner. Om du väljer ett recency-baserat alternativ måste du också ange ett datum- och tidsfält som definierar recency.
Välj Klart för att tillämpa kopplingsinställningar.
När du har definierat dedupliceringsreglerna och sammanslagningsinställningarna väljer du Nästa.
