Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Viktigt!
Den här funktionen är i förhandsversion.
Fabric Runtime levererar sömlös integrering i Microsoft Fabric-ekosystemet och erbjuder en robust miljö för datateknik och datavetenskapsprojekt som drivs av Apache Spark.
Den här artikeln introducerar offentlig förhandsversion av Fabric Runtime 2.0, den senaste körmiljön som är utformad för stordataberäkningar för Microsoft Fabric. Den belyser de viktigaste funktionerna och komponenterna som gör den här versionen till ett viktigt steg framåt för skalbar analys och avancerade arbetsbelastningar.
Fabric Runtime 2.0 innehåller följande komponenter och uppgraderingar som är utformade för att förbättra dina databehandlingsfunktioner:
- Apache Spark 4.1
- Operativsystem: Azure Linux 3.0 (Mariner 3.0)
- Java: 21
- Scala: 2.13
- Python: 3.13
- Delta Lake: 4,2
- R: 4.5.2
Viktigt!
Microsoft Fabric-teamet rullar ut en uppdatering till Microsoft Fabric Runtime 2.0. Som en del av denna uppdatering introducerar Python-uppgraderingen en avgörande förändring för kunder som använder miljöartefakter med python och hjulbibliotek. Kunder ser ett av de två felmeddelandena vid Notebook- eller Spark Job Definition (SJD)-exekvering:
- Fel: varning: 1 inaktuell funktion (sedan 2.13.0); för mer information, aktivera
:setting -deprecationeller:replay -deprecationKälla: SparkCoreService. - "LibraryManagementError": "En uppgradering av basmiljön Spark Python har upptäckts. Vänligen publicera miljön igen.|UserError"
Nödvändiga åtgärder
Publicera din miljö på nytt (inklusive biblioteken). För att göra detta, ta bort alla bibliotek, publicera miljön, lägg till alla bibliotek igen och publicera igen. Denna process återskapar miljön genom att använda den uppdaterade Python-runtimen och löser problemet.
Tips/Råd
Fabric Runtime 2.0 har stöd för den interna körningsmotorn, vilket avsevärt kan förbättra prestandan utan mer kostnader. Du kan aktivera den inbyggda exekveringsmotorn på miljönivå så att alla jobb och notebook-filer automatiskt ärver de förbättrade prestandaförmågorna.
Aktivera Runtime 2.0
Du kan aktivera Runtime 2.0 på antingen arbetsytenivå eller miljöobjektnivå. Använd arbetsyteinställningen för att tillämpa Runtime 2.0 som standard för alla Spark-arbetsbelastningar på din arbetsyta. Du kan också skapa ett miljöobjekt med Runtime 2.0 som ska användas med specifika notebook-filer eller Spark-jobbdefinitioner, vilket åsidosätter standardinställningen för arbetsytan.
Aktivera Runtime 2.0 i arbetsyteinställningar
Så här anger du Runtime 2.0 som standard för hela arbetsytan:
Gå till sidan Inställningar för arbetsyta i din Fabric-arbetsyta.
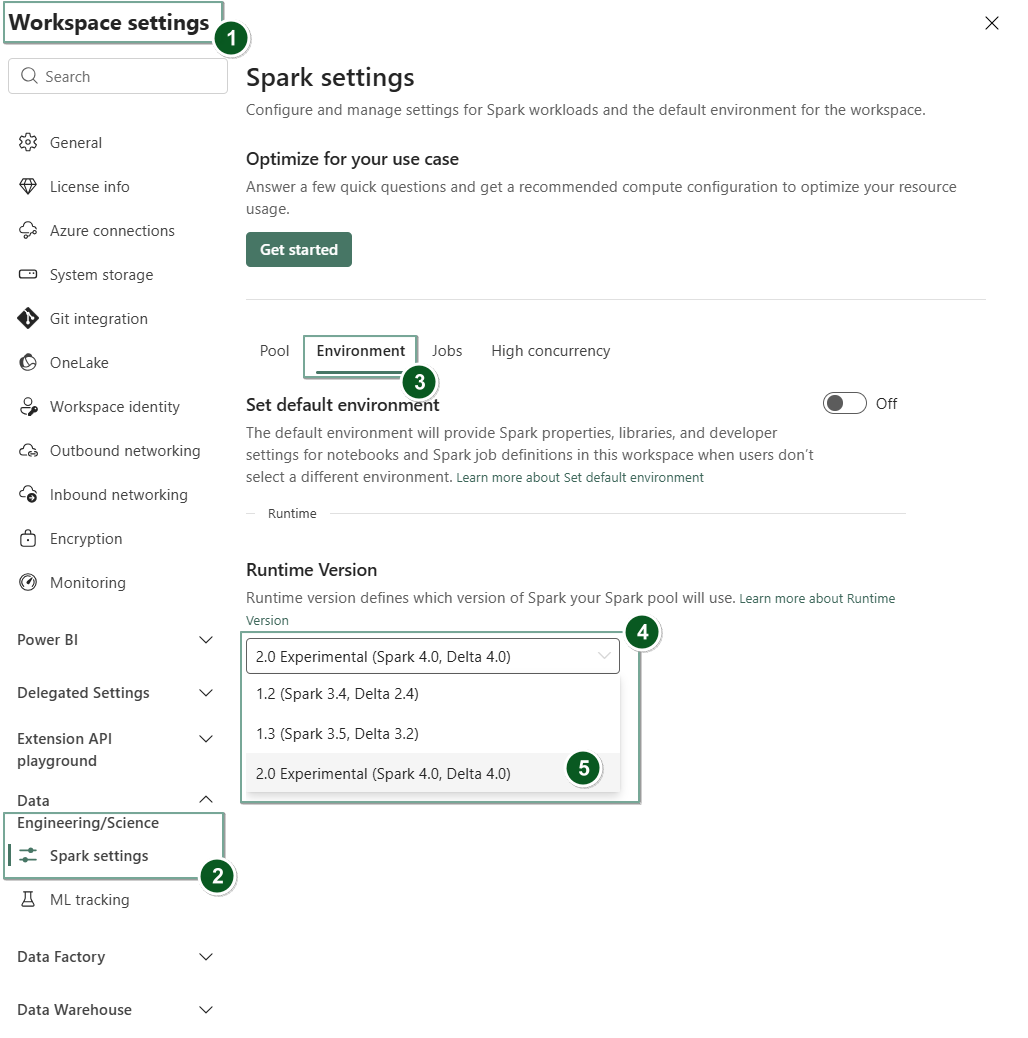
Välj fliken Datateknik/vetenskap och välj sedan Spark-inställningar.
Välj fliken Miljö.
Under rullgardinsmenyn för runtime-versionen väljer du 2.0 Public Preview (Spark 4.1, Delta 4.2) och sparar dina ändringar.
Runtime 2.0 har ställts in som standardkörning för din arbetsyta.

Aktivera Runtime 2.0 i ett miljöobjekt
För att använda Runtime 2.0 med specifika anteckningsböcker eller Spark-jobbdefinitioner:
Skapa ett nytt miljöobjekt eller öppna ett befintligt objekt.
Under rullgardinsmenyn Runtime , välj 2.0 Public Preview (Spark 4.1, Delta 4.2),Spara och publicera dina ändringar.
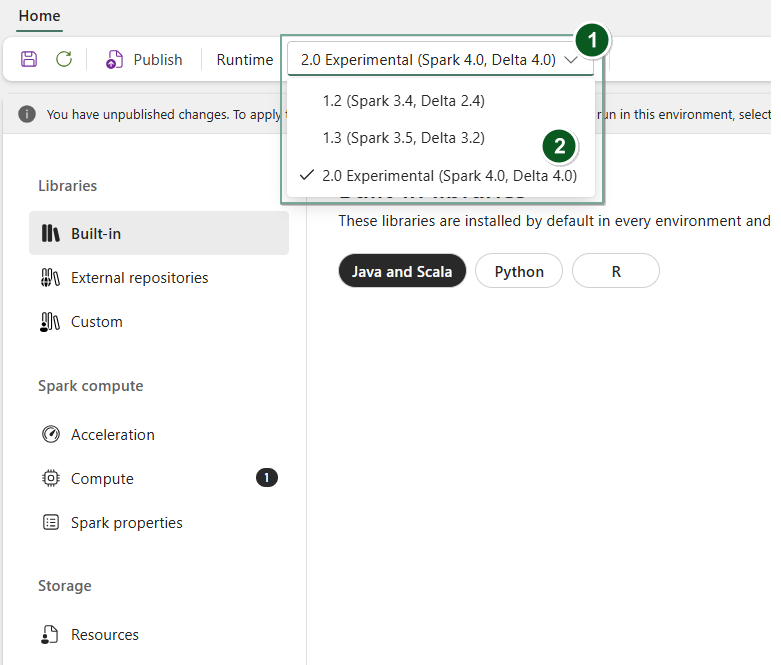
Sedan kan du använda det här miljöobjektet med notebook-filen eller Spark-jobbdefinitionen.

Du kan nu börja experimentera med de senaste förbättringarna och funktionerna som introducerats i Fabric Runtime 2.0 (Spark 4.1 och Delta Lake 4.2).
Offentlig förhandsversion
Fabric Runtime 2.0 publika förhandsvisningsfasen ger dig tillgång till nya funktioner och API:er från både Spark 4.1 och Delta Lake 4.2. Med förhandsversionen kan du använda de senaste Spark- och Delta-baserade förbättringarna direkt samt säkerställa en smidig beredskap och övergång för förbättrade och förbättrade ändringar som nyare Java-, Scala- och Python-versioner.
Tips/Råd
För uppdaterad information, en detaljerad lista över ändringar och specifika versionsanteckningar för Fabric-körtider, kontrollera och prenumerera på utgåvor och uppdateringar av Spark-körtider.
Viktiga höjdpunkter
Förbättringar av prestanda- och exekveringsmotorn.
Fabric Runtime 2.0 innehåller den inbyggda körningsmotorn, som ger betydande prestandaförbättringar jämfört med Spark med öppen källkod. Motorn använder vektoriserad bearbetning för att påskynda Spark-frågor på lakehouse-infrastrukturen utan att kräva kodändringar.
Viktiga prestandafunktioner i Runtime 2.0:
- Upp till sex gånger snabbare: Prestandamått visar upp till sex gånger snabbare prestanda jämfört med Spark med öppen källkod för TPC-DS arbetsbelastningar.
- Vektoriserad CSV-parsning: Den inbyggda körningsmotorn innehåller en vektoriserad CSV-parser som påskyndar CSV-inmatning och frågearbetsbelastningar. Stöd för vektoriserad JSON-parsning och Spark Structured Streaming planeras för framtida uppdateringar.
Information om hur du aktiverar den inbyggda körmotorn finns i Inbyggd körmotor för Fabric Datateknik.
Apache Spark 4.1
Apache Spark 4.0 markerade en viktig milstolpe som den första versionen i 4.x-serien, som förkroppsligar den samlade ansträngningen i den livliga communityn med öppen källkod. Fabric Runtime 2.0 körs nu på Apache Spark 4.1, som bygger på den grunden med ytterligare förbättringar.
I den här versionen är Spark SQL avsevärt berikat med kraftfulla nya funktioner som är utformade för att öka uttryckskraften och mångsidigheten för SQL-arbetsbelastningar, till exempel stöd för VARIANT-datatyp, användardefinierade SQL-funktioner, sessionsvariabler, pipe-syntax och strängsortering. PySpark ser ett kontinuerligt engagemang för både dess funktionella bredd och den övergripande utvecklarupplevelsen, vilket ger ett inbyggt api för plottning, ett nytt API för Python-datakälla, stöd för Python-UDF:er och enhetlig profilering för PySpark-UDF:er, tillsammans med många andra förbättringar. Strukturerad strömning utvecklas med viktiga tilläggsfunktioner som ger bättre kontroll och enklare felsökning, särskilt införandet av det godtyckliga tillstånds-API v2 för mer flexibel tillståndshantering och State Data Source för enklare felsökning.
Du kan kontrollera hela listan och detaljerade ändringar här:
Anmärkning
I Spark 4.x är SparkR inaktuellt och kan tas bort i en framtida version.
Delta Lake 4.2
Delta Lake 4.2 bygger vidare på tidigare Delta Lake-utgåvor och fortsätter sitt engagemang för att göra Delta Lake interoperabelt över format, lättare att arbeta med och mer prestandaeffektivt. Den innehåller kraftfulla nya funktioner, prestandaoptimeringar och grundläggande förbättringar för framtiden för öppna datasjöhus.
För hela listan och detaljerade förändringar som infördes med Delta Lake 3.3, 4.0, 4.1 och 4.2, se:
Datalayout och optimering
Runtime 2.0 stöder funktioner för datalayout och optimering för Delta-tabeller:
- Z-ordning: Organisera data i Delta-tabellfiler efter angivna kolumner för att förbättra frågeprestanda för filtrerade förfrågningar.
- Liquid Clustering: En flexibel klustringsmetod som automatiskt optimerar datalayouten utan manuellt underhåll.
- Parallell inläsning av Delta-ögonblicksbilder: Den inbyggda körningsmotorn läser in Delta-ögonblicksbilder parallellt, vilket minskar uppstartstiden för frågor för stora tabeller.
Viktigt!
Delta Lake 4.2-specifika funktioner är experimentella och fungerar endast på Spark-upplevelser, såsom anteckningsböcker och Spark Job Definitions. Om du behöver använda samma Delta Lake-tabeller i flera Microsoft Fabric-arbetsbelastningar ska du inte aktivera dessa funktioner. För att lära dig mer om vilka protokollversioner och funktioner som är kompatibla över alla Microsoft Fabric-upplevelser, se Delta Lake-tabellformatinteroperabilitet.
Beräkningshantering i Runtime 2.0
Runtime 2.0 stöder följande funktioner för beräkningshantering:
- Resursprofiler: Konfigurera fördefinierade resursallokeringar för Spark-sessioner för att matcha arbetsbelastningskrav och kontrollera kostnader.
- Anpassade livepooler (förhandsversion): Skapa dedikerade, förvärmda Spark-pooler som minskar starttiden för sessioner. Anpassade livepooler för Runtime 2.0-arbetsbelastningar är tillgängliga som förhandsversion.
Begränsningar och anteckningar
- Delta Lake 4.x-specifika funktioner är experimentella och fungerar bara med Spark-upplevelser, till exempel notebook-filer och Spark-jobbdefinitioner. Om du behöver använda samma Delta Lake-tabeller i flera Fabric-arbetsbelastningar ska du inte aktivera dessa funktioner. Mer information finns i Delta Lake-tabellformatets samverkan.
- Runtime 2.0 finns i offentlig förhandsversion. Vissa funktioner och API:er kan ändras före allmän tillgänglighet.
- VS Code-tillägget för Fabric Spark stöder Runtime 2.0 för utveckling av notebook- och Spark-jobbdefinition.
Relaterat innehåll
- Apache Spark-miljöer i Fabric – översikt, versionshantering och stöd för flera körmiljöer
- Migreringsguide för Spark Core
- Migreringsguider för SQL, datauppsättningar och DataFrame
- Migreringsguide för strukturerad direktuppspelning
- Migreringsguide för MLlib (strojové učenie)
- Migreringsguide för PySpark (Python på Spark)
- Migreringsguide för SparkR (R on Spark)