Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
I den här handledningen använder du notebooks med Spark-runtime för att transformera och förbereda rådata i din lakehouse.
Prerequisites
Innan du börjar måste du slutföra de tidigare självstudierna i den här serien:
- Skapa ett sjöhus
- Mata in data i sjöhuset
- Se till att lakehouse-scheman är aktiverade i ditt lakehouse.
Förberedelse av data
Från de föregående handledningarna har du rådata som har importerats från källan till Filer-avsnittet i lakehouse. Nu kan du transformera dessa data och förbereda dem för att skapa Delta-tabeller.
Ladda ned anteckningsböckerna från mappen Lakehouse Tutorial Source Code .
I webbläsaren går du till din Fabric-arbetsyta i Fabric-portalen.
Välj Importera>anteckningsbok>från den här datorn.
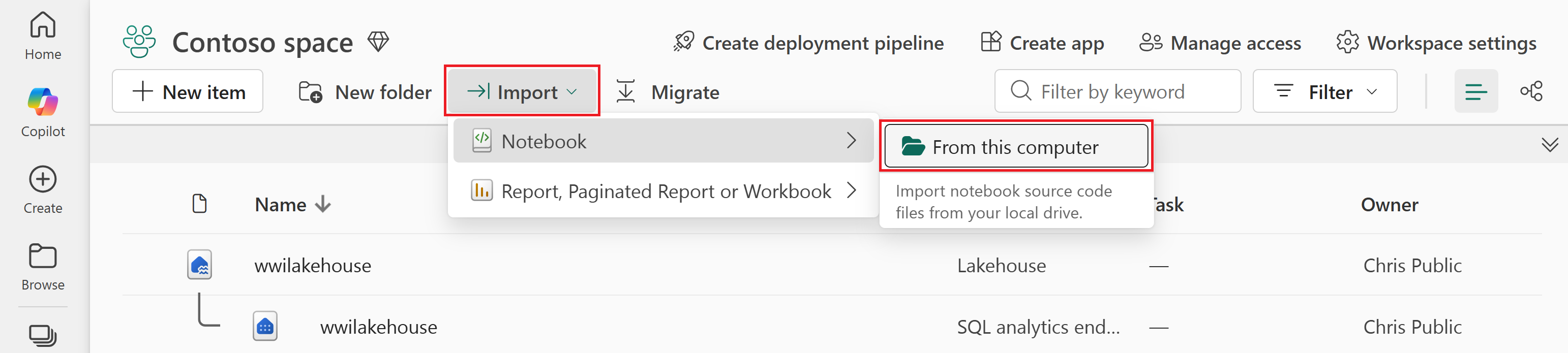
Välj Ladda upp från fönstret Importera status som öppnas till höger på skärmen.
Välj endast den notebook som matchar det kodspråk du föredrar.
-
PySpark (
Prepare and transform data - PySpark.ipynb) -
Spark SQL (
Prepare and transform data - Spark SQL.ipynb)
-
PySpark (
Välj Öppna. Ett meddelande som anger status för importen visas i det övre högra hörnet i webbläsarfönstret.
När importen har slutförts går du till objektvyn på arbetsytan för att verifiera den importerade notebook-filen.
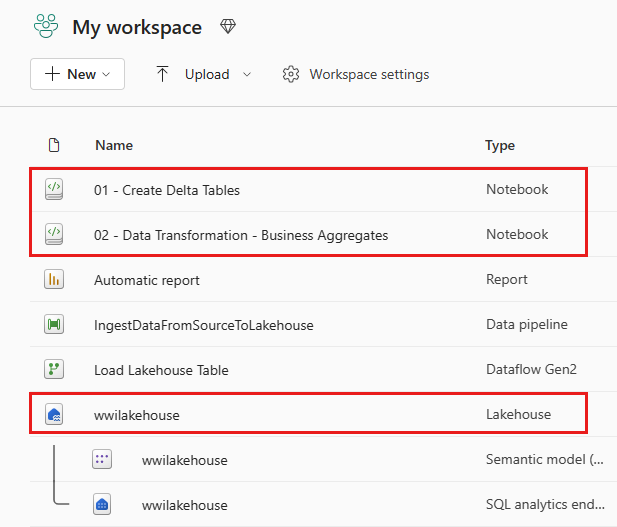
Välj wwilakehouse lakehouse för att öppna det, så att anteckningsboken du öppnar härnäst är länkad till den.
På den översta navigeringsmenyn väljer du Öppna anteckningsbok>Befintlig anteckningsbok.
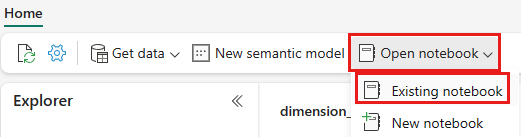
Välj din importerade notebook-fil för PySpark eller Spark SQL och välj Öppna. Anteckningsboken är redan länkad till ditt öppnade lakehouse, som du ser i Lakehouse Explorer.



Nu är du redo att köra anteckningsbokcellerna som skapar och transformerar dina Delta-tabeller.
I följande avsnitt kör du notebook-cellerna sekventiellt. Om du vill köra en cell väljer du ikonen Kör som visas till vänster om cellen vid hovring. Du kan också välja Kör alla i det övre menyfliksområdet (Start) för att köra alla celler i följd.
Viktigt!
Den här självstudien kräver att lakehouse-scheman är aktiverade. Om scheman inte är aktiverade fungerar inte koden i den här handledningen som avsett.
I den importerade anteckningsboken visas avsnitten Sökväg 1 och Sökväg 2. I den här självstudien använder du Path 1 (lakehouse-scheman aktiverade) och ignorerar Path 2 (lakehouse-scheman är inte aktiverade).
Skapa Delta-tabeller
I det här avsnittet kör du notebook-cellerna för att skapa Delta-tabeller från rådata.
Tabellerna följer ett stjärnschema, vilket är ett vanligt mönster för att organisera analysdata:
- En faktatabell (
fact_sale) innehåller de mätbara händelserna i verksamheten – i det här fallet enskilda försäljningstransaktioner med kvantiteter, priser och vinst. -
Dimensionstabeller (
dimension_city,dimension_customer,dimension_date,dimension_employee,dimension_stock_item) innehåller de beskrivande attribut som ger kontext till fakta, till exempel var en försäljning skedde, vem som gjorde den och när.
På den här självstudiesidan väljer du den flik som matchar anteckningsboken som du har importerat och fortsätter att använda samma flik för alla steg. Flikarna finns i den här artikeln, inte i notebook-filen.
Cell 1 – Konfiguration av Spark-session. Den här cellen möjliggör två Fabric-funktioner som optimerar hur data skrivs och läss i efterföljande celler. V-order optimerar parquet-fillayouten för snabbare läsningar och bättre komprimering. Optimera skrivning minskar antalet filer som skrivs och ökar den enskilda filstorleken.
Kör den här cellen och vänta tills den har slutförts innan du går vidare till nästa steg.
Cell 2 - Fakta - Försäljning. Den här cellen läser rådata från
Files/wwi-raw-data/full/fact_sale_1y_full, lägger till datumdelskolumner (år, kvartal och månad) och skriverfact_salesom en Delta-tabell partitionerad efter år och kvartal.Kör den här cellen och vänta tills den har slutförts innan du går vidare till nästa steg.
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/dbo/" + table_name)Cell 3 – Dimensioner. Den här cellen läser de fem dimensionsparquet-datauppsättningarna och skriver dem som Delta-tabeller (
dimension_city, ,dimension_customerdimension_date,dimension_employeeochdimension_stock_item) underTables/dbo/....Kör den här cellen och vänta tills den har slutförts innan du går vidare till nästa steg.
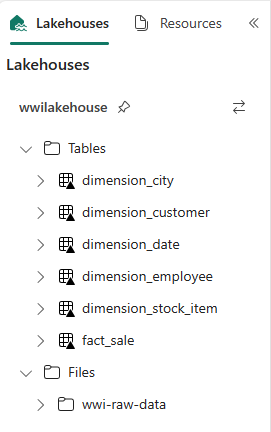
def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/dbo/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)Om du vill verifiera de skapade tabellerna högerklickar du på wwilakehouse lakehouse i utforskaren och väljer sedan Uppdatera. Tabellerna visas.

Transformera data för företagsaggregeringar
I det här avsnittet fortsätter du i samma anteckningsbok och kör nästa celler för att skapa aggregerade tabeller från deltatabellerna som du skapade i föregående avsnitt.
Kontrollera att anteckningsboken fortfarande är länkad till wwilakehouse.
Cell 4 – Läs in källtabeller för transformering (endast PySpark). Om du använder PySpark notebook, kör den här cellen för att ladda Delta-tabeller i DataFrames för de kommande aggregeringsstegen.
Kör den här cellen och vänta tills den har slutförts innan du går vidare till nästa steg.
Cell 5 – Skapa
aggregate_sale_by_date_city. Den här cellen kopplar samman försäljnings-, datum- och stadsdata och skapar sedan aggregeringstabellen på stadsnivå.Kör den här cellen och vänta tills den har slutförts innan du går vidare till nästa steg.
sale_by_date_city = ( df_fact_sale.alias("sale") .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit") .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory") .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit") .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax") .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount") .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax") .withColumnRenamed("sum(Profit)", "SumOfProfit") .orderBy("date.Date", "city.StateProvince", "city.City") ) sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/dbo/aggregate_sale_by_date_city")Cell 6 – Skapa
aggregate_sale_by_date_employee. Den här cellen kopplar samman försäljnings-, datum- och medarbetardata och skapar sedan aggregeringstabellen på personalnivå.Kör den här cellen och vänta tills den har slutförts innan du går vidare till nästa steg.
spark.sql(""" CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year , DE.PreferredName, DE.Employee , SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax , SUM(FS.TaxAmount) SumOfTaxAmount , SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax , SUM(FS.Profit) SumOfProfit FROM delta.`Tables/dbo/fact_sale` FS INNER JOIN delta.`Tables/dbo/dimension_date` DD ON FS.InvoiceDateKey = DD.Date INNER JOIN delta.`Tables/dbo/dimension_employee` DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASC """) sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/dbo/aggregate_sale_by_date_employee")Om du vill verifiera de skapade tabellerna högerklickar du på wwilakehouse lakehouse i utforskaren och väljer sedan Uppdatera. Aggregeringstabellerna visas.

Den här handledningen skriver data som Delta Lake-filer. Fabric identifierar och registrerar automatiskt dessa tabeller i metadatabutiken, så du behöver inte köra separata CREATE TABLE satser.