Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här artikeln beskriver hur du använder kopieringsaktiviteten i datapipelinen för att kopiera data från och till Azure Database for PostgreSQL.
Konfiguration som stöds
För konfigurationen av varje flik under kopieringsaktivitet går du till följande avsnitt.
Allmänt
Se Allmänna-inställningar vägledning för att konfigurera inställningsfliken Allmänt.
Källa
Gå till fliken Källa för att konfigurera kopieringsaktivitetskällan. Se följande innehåll för den detaljerade konfigurationen.
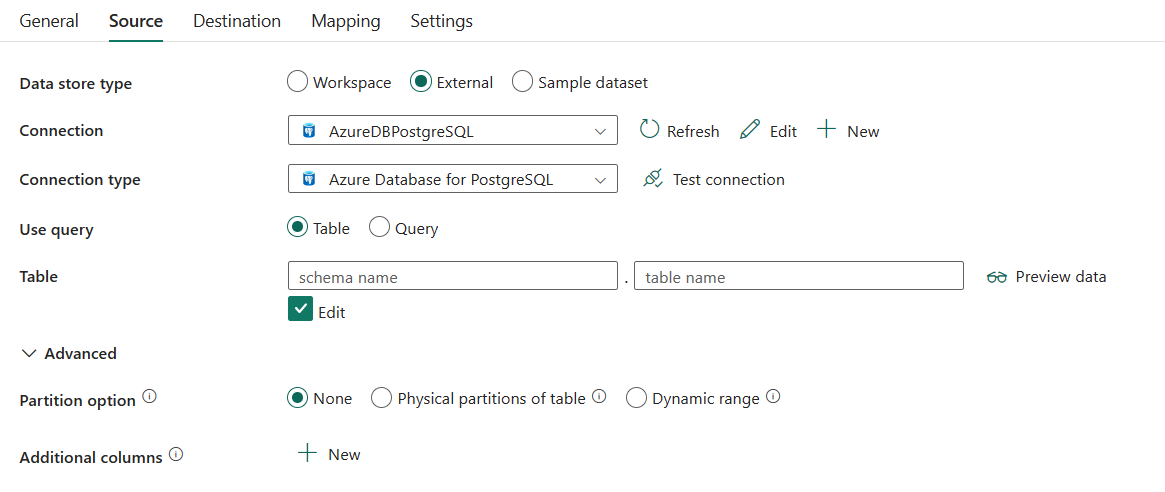
Följande tre egenskaper krävs:
Anslutning: Välj en Azure Database for PostgreSQL-anslutning i anslutningslistan. Om det inte finns någon anslutning skapar du en ny Azure Database for PostgreSQL-anslutning.
Använd fråga: Välj Tabell om du vill läsa data från den angivna tabellen eller välja Query för att läsa data med hjälp av frågor.
Om du väljer Tabell:
Tabell: Välj tabellen i listrutan eller välj Ange manuellt för att manuellt ange den för att läsa data.

Om du väljer Fråga:
Query: Ange den anpassade SQL-frågan för att läsa data. Till exempel:
SELECT * FROM mytableellerSELECT * FROM "MyTable".Anteckning
I PostgreSQL behandlas entitetsnamnet som skiftlägesokänsligt om det inte anges.

Version: Den version som du anger. Rekommenderar att du uppgraderar till den senaste versionen för att dra nytta av de senaste förbättringarna. När du väljer version 2.0 använder anslutningstjänsten SSL kräv läge om du krypterar anslutningen. Mer information om SSL-läge finns i den här artikeln.
Under Advancedkan du ange följande fält:
Tidsgräns för frågor (minuter): Ange väntetiden innan du avslutar försöket att köra ett kommando. Standardvärdet är 120 minuter, vilket genererar ett fel. Om parametern har angetts för den här egenskapen är tillåtna värden tidsintervall, till exempel "02:00:00" (120 minuter). Mer information finns i CommandTimeout.
partitionsalternativet: Anger de datapartitioneringsalternativ som används för att läsa in data från Azure Database for PostgreSQL. När ett partitionsalternativ är aktiverat (dvs. inte Ingen) styrs graden av parallellitet för att samtidigt läsa in data från en Azure Database for PostgreSQL av grad av kopieringsparallellitet på fliken inställningar för kopieringsaktivitet.
Om du väljer Ingenväljer du att inte använda partition.
Om du väljer fysiska partitioner i tabellen:
Partitionsnamn: Ange listan över fysiska partitioner som måste kopieras.
Om du använder en fråga för att hämta källdata, haka upp
?AdfTabularPartitionNamei WHERE-satsen. Ett exempel finns i avsnittet Parallell kopia från Azure Database for PostgreSQL.
Om du väljer dynamiskt intervall:
Partition kolumnnamn: Ange namnet på källkolumnen i heltal eller datum/datetime typ (
int,smallint,bigint,date,timestamp without time zone,timestamp with time zoneellertime without time zone) som ska användas av intervallpartitionering för parallell kopiering. Om den inte anges identifieras den primära nyckeln i tabellen automatiskt och används som partitionskolumn.Om du använder en fråga för att hämta källdata, haka upp
?AdfRangePartitionColumnNamei WHERE-satsen. Ett exempel finns i avsnittet Parallell kopia från Azure Database for PostgreSQL.Partition övre gräns: Ange det maximala värdet för partitionskolumnen för att kopiera ut data.
Om du använder en fråga för att hämta källdata, haka upp
?AdfRangePartitionUpboundi WHERE-satsen. Ett exempel finns i avsnittet Parallell kopia från Azure Database for PostgreSQL. .Partition med lägre bindning: Ange det lägsta värdet för partitionskolumnen för att kopiera ut data.
Om du använder en fråga för att hämta källdata, haka upp
?AdfRangePartitionLowboundi WHERE-satsen. Ett exempel finns i avsnittet Parallell kopia från Azure Database for PostgreSQL.
Ytterligare kolumner: Lägg till ytterligare datakolumner för att lagra källfilernas relativa sökväg eller statiska värde. Uttrycket stöds för det senare fallet.
Resmål
Gå till fliken Destination för att konfigurera mål för kopieringsaktiviteten. Se följande innehåll för den detaljerade konfigurationen.
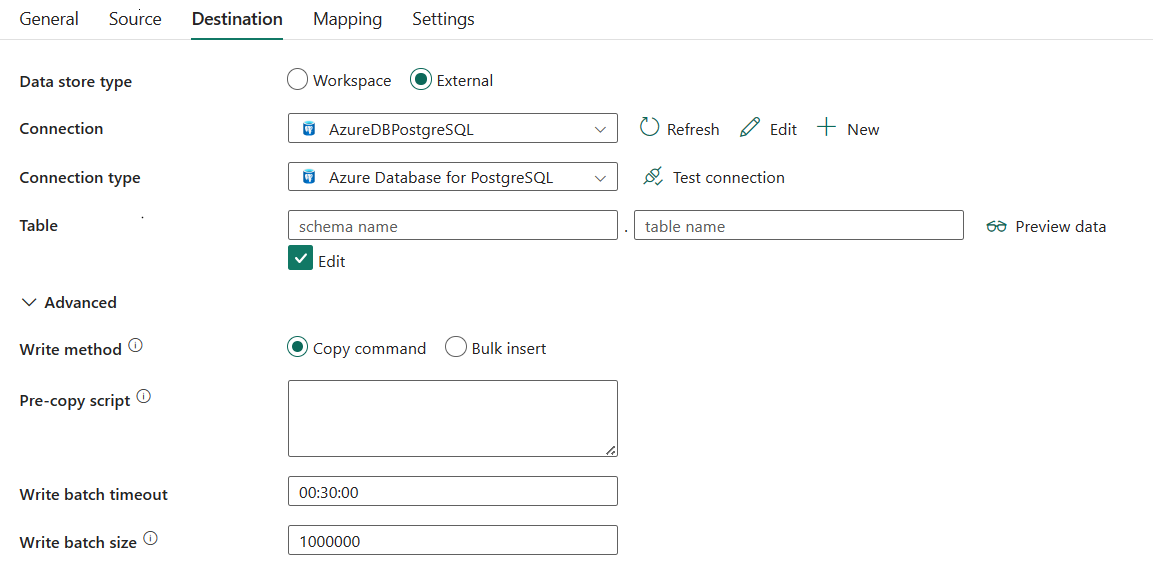
Följande tre egenskaper krävs:
Anslutning: Välj en Azure Database for PostgreSQL-anslutning i anslutningslistan. Om det inte finns någon anslutning skapar du en ny Azure Database for PostgreSQL-anslutning.
Tabell: Välj tabellen i listrutan eller välj Ange manuellt för att ange den för att skriva data.
Version: Den version som du anger. Rekommenderar att du uppgraderar till den senaste versionen för att dra nytta av de senaste förbättringarna. När du väljer version 2.0 använder anslutningstjänsten SSL kräv läge om du krypterar anslutningen. Mer information om SSL-läge finns i den här artikeln.
Under Advancedkan du ange följande fält:
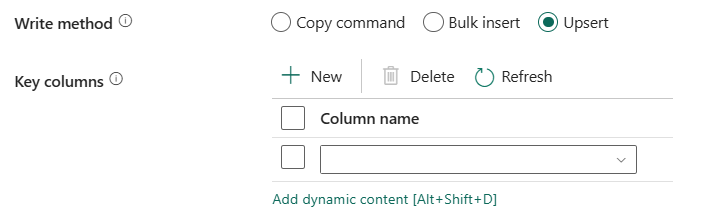
Write-metoden: Välj den metod som används för att skriva data till Azure Database for PostgreSQL. Välj mellan Kommandot Kopiera (förvalt, vilket ger bättre prestanda), Massinfogning och Upsert (för version 2.0).
-
Upsert: Välj det här alternativet om dina källdata har både infogningar och uppdateringar.
-
Nyckelkolumner: Välj vilken kolumn som ska användas för att avgöra om en rad från källan matchar en rad från målet.
-
Nyckelkolumner: Välj vilken kolumn som ska användas för att avgöra om en rad från källan matchar en rad från målet.
-
Upsert: Välj det här alternativet om dina källdata har både infogningar och uppdateringar.
förkopieringsskript: Ange en SQL-fråga för kopieringsaktiviteten som ska köras innan du skriver data till Azure Database for PostgreSQL i varje körning. Du kan använda den här egenskapen för att rensa inlästa data.
Tidsgräns för skrivbatch: Ange väntetiden för batchinsertoperationen att slutföra innan det når tidsgränsen. Det tillåtna värdet är tidsintervall. Standardvärdet är 00:30:00 (30 minuter).
Skriv batchstorlek: Ange antalet rader som läses in i Azure Database for PostgreSQL per batch. Tillåtet värde är ett heltal som representerar antalet rader. Standardvärdet är 1 000 000.
Kartläggning
För konfiguration av fliken Mappning, se Konfigurera dina mappningar under fliken Mappning.
Inställningar
För Inställningar flikkonfiguration går du till Konfigurera dina andra inställningar under fliken Inställningar.
Parallell kopia från Azure Database for PostgreSQL
Azure Database for PostgreSQL-anslutningsappen i kopieringsaktiviteten tillhandahåller inbyggd datapartitionering för att kopiera data parallellt. Du hittar alternativ för datapartitionering på fliken Source i kopieringsaktiviteten.
När du aktiverar partitionerad kopiering kör kopieringsaktiviteten parallella frågor mot din Azure Database for PostgreSQL-källa för att läsa in data efter partitioner. Den parallella graden styrs av grad av kopieringsparallellitet på fliken inställningar för kopieringsaktivitet. Om du till exempel anger grad av kopieringsparallellitet till fyra, genererar och kör tjänsten samtidigt fyra frågor baserat på det angivna partitionsalternativet och inställningarna, och varje fråga hämtar en del data från Azure Database for PostgreSQL.
Du rekommenderas att aktivera parallell kopiering med datapartitionering, särskilt när du läser in stora mängder data från din Azure Database for PostgreSQL. Följande är föreslagna konfigurationer för olika scenarier. När du kopierar data till filbaserat datalager rekommenderar vi att du skriver till en mapp som flera filer (anger endast mappnamn), i vilket fall prestandan är bättre än att skriva till en enda fil.
| Scenarium | Föreslagna inställningar |
|---|---|
| Fullständig belastning från en stor tabell med fysiska partitioner. |
partitionsalternativ: Fysiska partitioner i tabellen. Under körningsprocessen identifierar tjänsten automatiskt de fysiska partitionerna och kopierar data genom partitioner. |
| Full belastning från stor tabell, utan fysiska partitioner, men med en heltalskolumn för datapartitionering. |
Partitionsalternativ: Dynamiskt intervall. partitionskolumn: Ange den kolumn som används för att partitionera data. Om den inte anges används primärnyckelkolumnen. |
| Läs in en stor mängd data med hjälp av en anpassad fråga med fysiska partitioner. |
partitionsalternativ: Fysiska partitioner i tabellen. Fråga: SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>.Partitionsnamn: Ange partitionsnamnen som du vill kopiera data från. Om det inte anges identifierar tjänsten automatiskt de fysiska partitionerna i tabellen som du angav i PostgreSQL-datauppsättningen. Under körningen ersätter tjänsten ?AdfTabularPartitionName med det faktiska partitionsnamnet och skickar det till Azure Database for PostgreSQL. |
| Läs in en stor mängd data med hjälp av en anpassad fråga, utan fysiska partitioner, medan du har en heltalskolumn för datapartitionering. |
Partitionsalternativ: Dynamiskt intervall. Fråga: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.partitionskolumn: Ange den kolumn som används för att partitionera data. Du kan partitionera på kolumnen med heltals- eller datum/datum-tid-datatyp. Partition övre gräns och Partition lägre gräns: Ange om du vill filtrera mot partitionskolumnen för att hämta data endast mellan det lägre och det övre området. Under körningen ersätter tjänsten ?AdfRangePartitionColumnName, ?AdfRangePartitionUpboundoch ?AdfRangePartitionLowbound med det faktiska kolumnnamnet och värdeintervallen för varje partition och skickar till Azure Database for PostgreSQL. Om till exempel partitionskolumnen "ID" har angetts med den nedre gränsen som 1 och den övre gränsen som 80, med parallell kopiering inställd som 4, hämtar tjänsten data med 4 partitioner. Deras ID:n är mellan [1,20], [21, 40], [41, 60] respektive [61, 80]. |
Metodtips för att läsa in data med partitionsalternativet:
- Välj distinkt kolumn som partitionskolumn (till exempel primärnyckel eller unik nyckel) för att undvika datasnedvridning.
- Om tabellen har inbyggd partition använder du partitionsalternativet "Fysiska partitioner av tabellen" för att få bättre prestanda.
Tabellsammanfattning
Följande tabell innehåller mer information om kopieringsaktiviteten i Azure Database for PostgreSQL.
Källinformation
| Namn | Beskrivning | Värde | Krävs | JSON-skriptegenskap |
|---|---|---|---|---|
| Anslutning | Din anslutning till källdatalagret. | < din Azure Database for PostgreSQL-anslutning > | Ja | anslutning |
| Använd fråga | Sättet att läsa data. Använd Table för att läsa data från den angivna tabellen eller tillämpa Query för att läsa data med hjälp av frågor. | • Tabell • Sökfråga |
Ja | • typeProperties (under typeProperties ->source)-Schemat -bord •fråga |
| Version: | Den version som du anger. Rekommenderar att du uppgraderar till den senaste versionen för att dra nytta av de senaste förbättringarna. När du väljer version 2.0 använder anslutningstjänsten SSL kräv läge om du krypterar anslutningen. Mer information om SSL-läge finns i den här artikeln. | • 2.0 • 1.0 |
Ja | version: • 2.0 • 1.0 |
| Tidsgräns för frågor (minuter) | Väntetiden innan du avslutar försöket att köra ett kommando och generera ett fel är standardvärdet 120 minuter. Om parametern har angetts för den här egenskapen är tillåtna värden tidsintervall, till exempel "02:00:00" (120 minuter). Mer information finns i CommandTimeout. | tidsintervall | Nej | förfråganTidsgräns |
| Namn på partitioner | Listan över fysiska partitioner som måste kopieras. Om du använder en fråga för att hämta källdata, haka upp ?AdfTabularPartitionName i WHERE-satsen. |
< dina partitionsnamn > | Nej | partitionnamn |
| Kolumnnamn för partition | Namnet på källkolumnen i heltal eller datum/datetime-typ (int, smallint, bigint, date, timestamp without time zone, timestamp with time zone eller time without time zone) som ska användas av intervallpartitionering för parallell kopiering. Om den inte anges identifieras den primära nyckeln i tabellen automatiskt och används som partitionskolumn. |
< dina partitionskolumnnamn > | Nej | partitionskolumnNamn |
| Partiotions övre gräns | Det maximala värdet för partitionskolumnen för att kopiera ut data. Om du använder en fråga för att hämta källdata ansluter du ?AdfRangePartitionUpbound i WHERE-satsen. |
< partitionens övre gräns > | Nej | partitionens övre gräns |
| Nedre gräns för partition | Det minsta värdet för partitionskolumnen för att kopiera ut data. Om du använder en fråga för att hämta källdata ansluter du ?AdfRangePartitionLowbound i WHERE-satsen. |
< partitionens nedre gräns > | Nej | partitionens nedre gräns |
| Ytterligare kolumner | Lägg till ytterligare datakolumner för att lagra källfilernas relativa sökväg eller statiska värde. Uttrycket stöds för det senare fallet. | •Namn •Värde |
Nej | ytterligareKolumner •Namn • värde |
Destinationsinformation
| Namn | Beskrivning | Värde | Krävs | JSON-skriptegenskap |
|---|---|---|---|---|
| Anslutning | Din anslutning till måldatalagret. | < din Azure Database for PostgreSQL-anslutning > | Ja | anslutning |
| tabell | Din måldatatabell för att skriva data. | < namn på måltabellen > | Ja | typeProperties (under typeProperties –>sink):-Schemat -bord |
| Version: | Den version som du anger. Rekommenderar att du uppgraderar till den senaste versionen för att dra nytta av de senaste förbättringarna. När du väljer version 2.0 använder anslutningstjänsten SSL kräv läge om du krypterar anslutningen. Mer information om SSL-läge finns i den här artikeln. | • 2.0 • 1.0 |
Ja | version: • 2.0 • 1.0 |
| Skrivmetod | Den metod som används för att skriva data till Azure Database for PostgreSQL. | • Kopiera kommando (standard) • Massinfog • Upsert (för version 2.0) |
Nej | skrivMetod: • CopyCommand (Kopieringskommando) • BulkInsert • Uppdatera eller infoga |
| Nyckelkolumner | Välj vilken kolumn som ska användas för att avgöra om en rad från källan matchar en rad från målet. | < din nyckelkolumn> | Nej | Nycklar |
| förkopieringsskript | En SQL-fråga för kopieringsaktiviteten som ska köras innan du skriver data till Azure Database for PostgreSQL i varje körning. Du kan använda den här egenskapen för att rensa inlästa data. | < ditt förkopieringsskript > | Nej | preCopyScript |
| Tidsgräns för batchskrivning | Väntetiden för att batchinfogningsåtgärden ska slutföras innan tidsgränsen uppnås. | tidsintervall (standardvärdet är 00:30:00 – 30 minuter) |
Nej | writeBatchTimeout |
| Skriv batchstorlek | Antalet rader som läses in i Azure Database for PostgreSQL per batch. | heltal (standardvärdet är 1 000 000) |
Nej | writeBatchSize |