Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
Den här självstudien hjälper dig att påskynda utvärderingsprocessen för Data Factory i Microsoft Fabric genom att tillhandahålla stegen för ett fullständigt dataintegreringsscenario inom en timme. I slutet av den här självstudien förstår du värdet och de viktigaste funktionerna i Data Factory och vet hur du slutför ett vanligt dataintegreringsscenario från slutpunkt till slutpunkt.
Scenariot är indelat i en introduktion och tre moduler:
- Inledning till handledningen och varför du bör använda Data Factory i Microsoft Fabric.
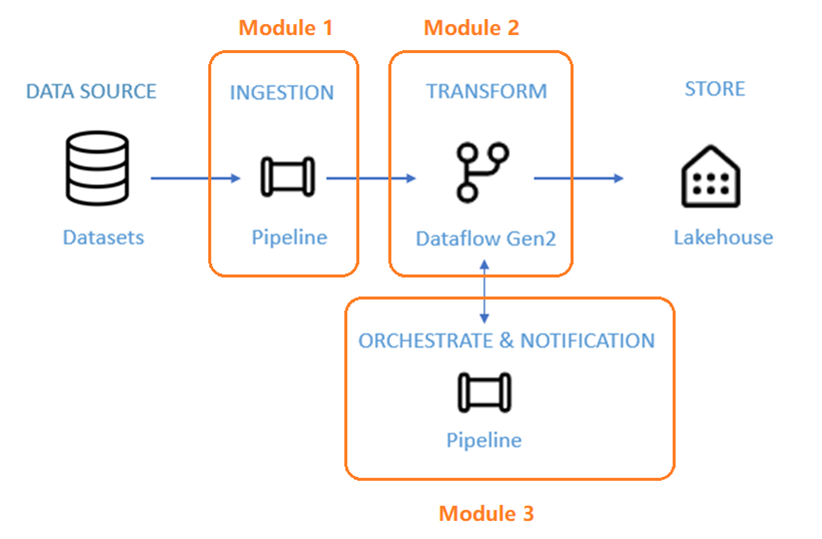
- Modul 1: Skapa en pipeline med Data Factory för att mata in rådata från en Blob-lagring till en tabell med bronsdatalager i ett Data Lakehouse.
- Modul 2: Transformera data med ett dataflöde i Data Factory för att bearbeta rådata från bronstabellen och flytta dem till en gulddatalagertabell i data Lakehouse.
- Modul 3: Slutför din första dataintegreringsresa och skicka ett e-postmeddelande för att meddela dig när alla jobb är klara och slutligen konfigurera hela flödet så att det körs enligt ett schema.
Varför datafabrik i Microsoft Fabric?
Microsoft Fabric tillhandahåller en enda plattform för alla analysbehov i ett företag. Den omfattar spektrumet av analyser, inklusive dataflytt, datasjöar, datateknik, dataintegrering, datavetenskap, realtidsanalys och business intelligence. Med Fabric behöver du inte sy ihop olika tjänster från flera leverantörer. I stället får användarna en omfattande produkt som är lätt att förstå, skapa, registrera och använda.
Data Factory i Fabric kombinerar enkel användning av Power Query med skalning och kraft i Azure Data Factory. Det för samman det bästa av båda produkterna till en enda upplevelse. Målet är att både medborgar- och professionella datautvecklare ska ha rätt verktyg för dataintegrering. Data Factory tillhandahåller AI-drivna lågkodsverktyg för databeredning och -omvandling, petabyteskalig transformering och hundratals kopplingar med hybrid- och multimolnanslutning.
Tre viktiga funktioner i Data Factory
- Datainmatning: Med kopieringsaktiviteten i pipelines (eller det fristående kopieringsjobbet) kan du flytta petabyteskalade data från hundratals datakällor till data Lakehouse för vidare bearbetning.
- Datatransformering och förberedelse: Dataflow Gen2 tillhandahåller ett lågkodsgränssnitt för att transformera dina data med över 300 datatransformeringar, med möjlighet att läsa in de omvandlade resultaten till flera mål som Azure SQL-databaser, Lakehouse med mera.
- Automatisering från slutpunkt till slutpunkt: Pipelines tillhandahåller orkestrering av aktiviteter som inkluderar Copy, Dataflow och Notebook-aktiviteter med mera. Aktiviteter i en pipeline kan kopplas samman för att fungera sekventiellt, eller så kan de fungera separat parallellt. Hela dataintegreringsflödet körs automatiskt och kan övervakas på ett och samma ställe.
Handledningsarkitektur
Under de kommande 50 minuterna lär du dig igenom alla tre viktiga funktioner i Data Factory när du slutför ett dataintegreringsscenario från slutpunkt till slutpunkt.
Scenariot är indelat i tre moduler:
- Modul 1: Skapa en pipeline med Data Factory för att mata in rådata från en Blob-lagring till en tabell med bronsdatalager i ett Data Lakehouse.
- Modul 2: Transformera data med ett dataflöde i Data Factory för att bearbeta rådata från bronstabellen och flytta dem till en gulddatalagertabell i data Lakehouse.
- Modul 3: Slutför din första dataintegreringsresa och skicka ett e-postmeddelande för att meddela dig när alla jobb är klara och slutligen konfigurera hela flödet så att det körs enligt ett schema.
Du använder exempeldatauppsättningen NYC-Taxi som datakälla för självstudien. När du är klar kan du få insikter om dagliga rabatter på taxipriser under en viss tidsperiod med datafabriken i Microsoft Fabric.
Nästa steg
Fortsätt till nästa avsnitt för att skapa din pipeline.