Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
I den här handledningen visas ett komplett exempel på ett Synapse Data Science arbetsflöde i Microsoft Fabric. Den använder både dataresursen nycflights13 och R för att förutsäga om ett plan anländer mer än 30 minuter för sent eller inte. Den använder sedan förutsägelseresultatet för att skapa en interaktiv Power BI-instrumentpanel.
I den här handledningen lär du dig att:
Använd tidymodels-paketen
- recipes
- parsnip
- rsample
- arbetsflöden för att bearbeta data och träna en maskininlärningsmodell
Skriva utdata till ett lakehouse som en deltatabell
Skapa en Power BI-rapport för att direkt få åtkomst till data i det där lakehouset.
Förutsättningar
Skaffa en Microsoft Fabric subscription. Eller registrera dig för en kostnadsfri utvärderingsversion av Microsoft Fabric.
Logga in på Microsoft Fabric.
Växla till Fabric genom att använda upplevelseväxlaren längst ned till vänster på startsidan.

Öppna eller skapa en notebook-fil. Lär dig hur genom att se Så använder du Microsoft Fabric-anteckningsböcker.
Ange språkalternativet SparkR (R) för att ändra det primära språket.
Anslut din anteckningsbok till ett lakehouse. Till vänster väljer du Lägg till för att lägga till ett befintligt sjöhus eller för att skapa ett sjöhus.
Installera paket
Installera paketet nycflights13 för att använda koden i den här självstudien.
install.packages("nycflights13")
# Load the packages
library(tidymodels) # For tidymodels packages
library(nycflights13) # For flight data
Utforska data
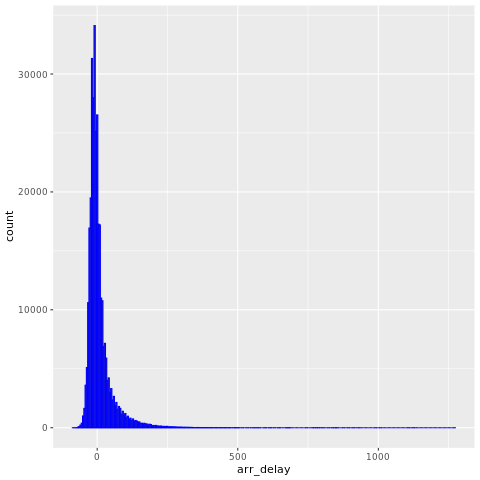
nycflights13 data har information om 325 819 flygningar som anlände nära New York City 2013. Först, undersök fördelningen av flygförseningar. Följande kodcell genererar en graf som visar att fördelningen av ankomstförseningar är högerförskjuten.
ggplot(flights, aes(arr_delay)) + geom_histogram(color="blue", bins = 300)
Den har en lång svans i de höga värdena, som visas i bilden nedan:
Läs in data och gör några ändringar i variablerna:
set.seed(123)
flight_data <-
flights %>%
mutate(
# Convert the arrival delay to a factor
arr_delay = ifelse(arr_delay >= 30, "late", "on_time"),
arr_delay = factor(arr_delay),
# You'll use the date (not date-time) for the recipe that you'll create
date = lubridate::as_date(time_hour)
) %>%
# Include weather data
inner_join(weather, by = c("origin", "time_hour")) %>%
# Retain only the specific columns that you'll use
select(dep_time, flight, origin, dest, air_time, distance,
carrier, date, arr_delay, time_hour) %>%
# Exclude missing data
na.omit() %>%
# For creating models, it's better to have qualitative columns
# encoded as factors (instead of character strings)
mutate_if(is.character, as.factor)
Innan vi bygger modellen, överväg några specifika variabler som är viktiga för både förbearbetning och modellering.
Variabeln arr_delay är en faktorvariabel. För träning av logistiska regressionsmodeller är det viktigt att utfallsvariabeln är en faktorvariabel.
glimpse(flight_data)
Ungefär 16% av flygen i denna datamängd anlände mer än 30 minuter för sent.
flight_data %>%
count(arr_delay) %>%
mutate(prop = n/sum(n))
dest-funktionen har 104 flygdestinationer:
unique(flight_data$dest)
Det finns 16 olika transportörer:
unique(flight_data$carrier)
Dela upp datan
Dela upp den enskilda datamängden i två uppsättningar: en träningsuppsättning och en testuppsättning . Behåll de flesta raderna i den ursprungliga datamängden (som en slumpmässigt vald delmängd) i träningsdatauppsättningen. Använd träningsdatauppsättningen för att passa modellen och använd testdatauppsättningen för att mäta modellens prestanda.
Använd rsample-paketet för att skapa ett objekt som innehåller information om hur du delar upp data. Använd sedan ytterligare två rsample funktioner för att skapa DataFrames för tränings- och testuppsättningarna:
set.seed(123)
# Keep most of the data in the training set
data_split <- initial_split(flight_data, prop = 0.75)
# Create DataFrames for the two sets:
train_data <- training(data_split)
test_data <- testing(data_split)
Skapa ett recept och roller
Skapa ett recept för en enkel logistisk regressionsmodell. Innan du tränar modellen använder du ett recept för att skapa nya prediktorer och utför den förbearbetning som modellen kräver.
Använd update_role()-funktionen med en anpassad roll som heter ID så att recepten vet att flight och time_hour är variabler. En roll kan ha vilket tecken som helst. Formeln inkluderar alla variabler i träningsuppsättningen som prediktorer, förutom arr_delay. Receptet behåller dessa två ID-variabler men använder dem inte som varken utfall eller prediktorer.
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID")
Om du vill visa den aktuella uppsättningen variabler och roller använder du funktionen summary():
summary(flights_rec)
Skapa funktioner
Funktionsteknik kan förbättra din modell. Datumet för flyget kan ha en rimlig effekt på sannolikheten för en sen ankomst.
flight_data %>%
distinct(date) %>%
mutate(numeric_date = as.numeric(date))
Det kan vara till hjälp att lägga till modelltermer, härledda från datumet, som kan ha potentiell betydelse för modellen. Härled följande meningsfulla funktioner från variabeln med ett enda datum:
- Veckodag
- Månad
- Om datumet motsvarar en helgdag eller inte
Lägg till de tre stegen i receptet:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID") %>%
step_date(date, features = c("dow", "month")) %>%
step_holiday(date,
holidays = timeDate::listHolidays("US"),
keep_original_cols = FALSE) %>%
step_dummy(all_nominal_predictors()) %>%
step_zv(all_predictors())
Anpassa en modell med ett recept
Använd logistisk regression för att modellera flygdata. Skapa först en modellspecifikation med parsnip-paketet:
lr_mod <-
logistic_reg() %>%
set_engine("glm")
Använd workflows-paketet för att paketera din parsnip modell (lr_mod) med ditt recept (flights_rec):
flights_wflow <-
workflow() %>%
add_model(lr_mod) %>%
add_recipe(flights_rec)
flights_wflow
Träna modellen
Den här funktionen kan förbereda receptet och träna modellen från de resulterande prediktorerna:
flights_fit <-
flights_wflow %>%
fit(data = train_data)
Använd hjälpfunktionerna xtract_fit_parsnip() och extract_recipe() för att extrahera modell- eller receptobjekt från arbetsflödet. I det här exemplet, hämta det anpassade modellobjektet, använd sedan broom::tidy()-funktionen för att få en prydlig tibble av modellkoefficienter.
flights_fit %>%
extract_fit_parsnip() %>%
tidy()
Förutsäga resultat
Ett enda anrop till predict() använder det tränade arbetsflödet (flights_fit) för att göra förutsägelser med osedda testdata. Metoden predict() tillämpar receptet på nya data och skickar sedan resultatet till den anpassade modellen.
predict(flights_fit, test_data)
Hämta utdata från predict() för att returnera den förutsagda klassen: late jämfört med on_time. För att spara de förutsagda klassannolikheterna för varje flygning tillsammans, använd augment() med modellen och kombinera med testdata.
flights_aug <-
augment(flights_fit, test_data)
Granska datat:
glimpse(flights_aug)
Utvärdera modellen
Vi har nu en tibble med de förutsagda klasssannolikheterna. I de första raderna förutsade modellen korrekt fem flygningar i tid (värden för .pred_on_time är p > 0.50). Däremot behöver vi förutsägelser för totalt 81 455 rader.
Vi behöver en metrisk enhet som visar hur väl modellen förutsagde sena ankomster, jämfört med det faktiska läget för variabeln arr_delay.
Använd area under kurvan för mottagarens driftkarakteristika (AUC-ROC) som mått. Beräkna den med roc_curve() och roc_auc()från yardstick-paketet:
flights_aug %>%
roc_curve(truth = arr_delay, .pred_late) %>%
autoplot()
Skapa en Power BI-rapport
Modellresultatet ser bra ut. Använd förutsägelseresultatet för flygfördröjning för att skapa en interaktiv Power BI-instrumentpanel. Instrumentpanelen visar antalet flygningar per flygbolag och antalet flygningar per mål. Instrumentpanelen kan filtrera utifrån resultaten av förutsägelse om förseningar.

Inkludera transportföretagets namn och flygplatsnamn i datauppsättningen för förutsägelseresultatet:
flights_clean <- flights_aug %>%
# Include the airline data
left_join(airlines, c("carrier"="carrier"))%>%
rename("carrier_name"="name") %>%
# Include the airport data for origin
left_join(airports, c("origin"="faa")) %>%
rename("origin_name"="name") %>%
# Include the airport data for destination
left_join(airports, c("dest"="faa")) %>%
rename("dest_name"="name") %>%
# Retain only the specific columns you'll use
select(flight, origin, origin_name, dest,dest_name, air_time,distance, carrier, carrier_name, date, arr_delay, time_hour, .pred_class, .pred_late, .pred_on_time)
Granska datat:
glimpse(flights_clean)
Konvertera data till en Spark DataFrame:
sparkdf <- as.DataFrame(flights_clean)
display(sparkdf)
Skriv in data i en deltatabell i ditt lakehouse:
# Write data into a delta table
temp_delta<-"Tables/nycflight13"
write.df(sparkdf, temp_delta ,source="delta", mode = "overwrite", header = "true")
Använd deltatabellen för att skapa en semantisk modell.
Välj din arbetsyta i den vänstra navigeringen, och i textrutan uppe till höger, ange namnet på lakehouse som du kopplade till din anteckningsbok. Följande skärmbild visar att vi har valt Min arbetsyta:

Ange namnet på den lakehouse som du har kopplat till din anteckningsbok. Vi anger test_lakehouse1, enligt följande skärmbild:
I området med de filtrerade resultaten, välj lakehouse, som visas i följande skärmdump:

Välj Ny semantisk modell enligt följande skärmbild:

I fönstret Ny semantisk modell anger du ett namn för den nya semantiska modellen, väljer en arbetsyta och väljer de tabeller som ska användas för den nya modellen och väljer sedan Bekräfta enligt följande skärmbild:

Om du vill skapa en ny rapport väljer du Skapa ny rapport enligt följande skärmbild:

Markera eller dra fält från fönstret Data och Visualiseringar till rapportarbetsytan för att skapa rapporten
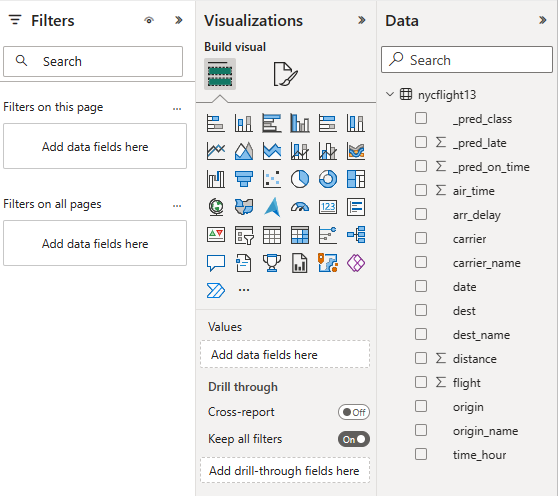






Om du vill skapa rapporten som visas i början av det här avsnittet använder du dessa visualiseringar och data:
-
 Staplat diagram med:
Staplat diagram med: - Y-axel: carrier_name
- X-axel: flyg. Välj Antal för aggregeringen
- Förklaring: origin_name
-
Staplat diagram med:
- Y-axel: dest_name
- X-axel: flygning. Välj Antal för aggregeringen
- Förklaring: origin_name
-
 Skivare med:
Skivare med: - Fält: _pred_class
-
Skivare med:
- Fält: _pred_late