Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Bibliotek ger återanvändbar kod som du kanske vill inkludera i dina program eller projekt för Microsoft Fabric Spark.
Microsoft Fabric stöder en R-körning med många populära R-paket med öppen källkod, inklusive TidyVerse, förinstallerat. När en Spark-instans startar inkluderas dessa bibliotek automatiskt och är tillgängliga för användning direkt i notebook-filer eller Spark-jobbdefinitioner.
Du kan behöva uppdatera dina R-bibliotek av olika skäl. Ett av dina kärnberoenden har till exempel släppt en ny version, eller så har ditt team skapat ett anpassat paket som du behöver i dina Spark-kluster.
Det finns två typer av bibliotek som du kanske vill inkludera baserat på ditt scenario:
Feed-bibliotek refererar till de som finns i offentliga källor eller arkiv, till exempel CRAN eller GitHub.
anpassade bibliotek är koden som skapats av dig eller din organisation, .tar.gz kan hanteras via bibliotekshanteringsportaler.
Det finns två paketnivåer installerade på Microsoft Fabric:
Environment: Hantera bibliotek genom en miljö för att återanvända samma uppsättning bibliotek i flera anteckningsböcker eller jobb.
Session : En installation på sessionsnivå skapar en miljö för en specifik notebook-session. Ändringen av bibliotek på sessionsnivå sparas inte mellan sessioner.
Sammanfattar de aktuella tillgängliga R-bibliotekshanteringsbeteendena:
| Bibliotekstyp | Miljöinstallation | Installation på sessionsnivå |
|---|---|---|
| R-feed (CRAN) | Stöds inte | Stödd |
| R Anpassad | Stödd | Stödd |
Förutsättningar
Skaffa en Microsoft Fabric-prenumeration. Eller registrera dig för en kostnadsfri Microsoft Fabric-utvärderingsversion.
Logga in på Microsoft Fabric.
Använd upplevelseväxlaren längst ner till vänster på din startsida för att växla till Fabric.

R-bibliotek på sessionsnivå
När du utför interaktiv dataanalys eller maskininlärning kan du prova nyare paket eller så kan du behöva paket som för närvarande inte är tillgängliga på din arbetsyta. I stället för att uppdatera inställningarna för arbetsytan kan du använda sessionsomfattande paket för att lägga till, hantera och uppdatera sessionsberoenden.
- När du installerar sessionsspecifika bibliotek har endast den aktuella anteckningsboken åtkomst till de angivna biblioteken.
- De här biblioteken påverkar inte andra sessioner eller jobb som använder samma Spark-pool.
- De här biblioteken installeras ovanpå basruntimebiblioteken och biblioteken på poolnivå.
- Notebook-bibliotek har högst prioritet.
- Sessionsomfångade R-bibliotek bevaras inte mellan sessioner. Dessa bibliotek installeras i början av varje session när de relaterade installationskommandona körs.
- Sessionsomfattande R-bibliotek installeras automatiskt över både drivrutins- och arbetsnoderna.
Notera
Kommandona för att hantera R-bibliotek inaktiveras när du kör pipelinejobb. Om du vill installera ett paket i en pipeline måste du använda bibliotekshanteringsfunktionerna på arbetsytans nivå.
Installera R-paket från CRAN
Du kan enkelt installera ett R-bibliotek från CRAN.
# install a package from CRAN
install.packages(c("nycflights13", "Lahman"))
Du kan också använda CRAN-ögonblicksbilder som lagringsplats för att se till att ladda ned samma paketversion varje gång.
# install a package from CRAN snapsho
install.packages("highcharter", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
Installera R-paket med devtools
Biblioteket devtools förenklar paketutvecklingen för att påskynda vanliga uppgifter. Det här biblioteket installeras inom standardkörningen för Microsoft Fabric.
Du kan använda devtools för att ange en specifik version av ett bibliotek som ska installeras. De här biblioteken installeras på alla noder i klustret.
# Install a specific version.
install_version("caesar", version = "1.0.0")
På samma sätt kan du installera ett bibliotek direkt från GitHub.
# Install a GitHub library.
install_github("jtilly/matchingR")
För närvarande stöds följande devtools funktioner i Microsoft Fabric:
| Befallning | Beskrivning |
|---|---|
| install_github() | Installerar ett R-paket från GitHub |
| install_gitlab() | Installerar ett R-paket från GitLab |
| install_bitbucket() | Installerar ett R-paket från BitBucket |
| install_url() | Installerar ett R-paket från en godtycklig URL |
| install_git() | Installerar från en godtycklig git-lagringsplats |
| install_local() | Installerar från en lokal fil på disk |
| install_version() | Installerar från en specifik version på CRAN |
Installera anpassade R-bibliotek
Om du vill använda ett anpassat bibliotek på sessionsnivå måste du först ladda upp det till ett bifogat Lakehouse.
Öppna anteckningsboken som du vill använda det anpassade biblioteket i.
Till vänster väljer du Lägg till för att lägga till ett befintligt sjöhus eller skapa ett sjöhus.
Högerklicka eller välj "..." bredvid Filer för att ladda upp din .tar.gz-fil.
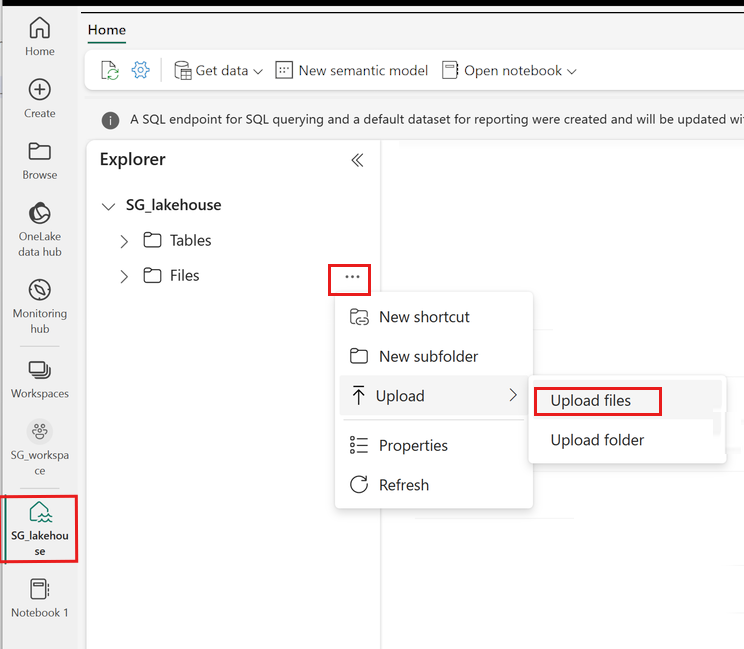
När du har laddat upp går du tillbaka till anteckningsboken. Använd följande kommando för att installera det anpassade biblioteket i sessionen:
install.packages("filepath/filename.tar.gz", repos = NULL, type = "source")
Visa installerade bibliotek
Fråga alla bibliotek som är installerade i sessionen med hjälp av kommandot library.
# query all the libraries installed in current session
library()
Använd funktionen packageVersion för att kontrollera bibliotekets version:
# check the package version
packageVersion("caesar")
Ta bort ett R-paket från en session
Du kan använda funktionen detach för att ta bort ett bibliotek från namnområdet. De här biblioteken finns kvar på disken tills de läses in igen.
# detach a library
detach("package: caesar")
För att ta bort ett sessionsbaserat paket från en anteckningsbok, använd kommandot remove.packages(). Den här biblioteksändringen påverkar inte andra sessioner i samma kluster. Användare kan inte avinstallera eller ta bort inbyggda bibliotek för standardkörningen i Microsoft Fabric.
Note
Du kan inte ta bort kärnpaket som SparkR, SparklyR eller R.
remove.packages("caesar")
R-bibliotek med sessionsomfattning och SparkR
Bibliotek med notebook-omfång är tillgängliga för SparkR-arbetare.
install.packages("stringr")
library(SparkR)
str_length_function <- function(x) {
library(stringr)
str_length(x)
}
docs <- c("Wow, I really like the new light sabers!",
"That book was excellent.",
"R is a fantastic language.",
"The service in this restaurant was miserable.",
"This is neither positive or negative.")
spark.lapply(docs, str_length_function)
R-bibliotek som är begränsade till sessioner och sparklyr
Med spark_apply() i sparklyr kan du använda alla R-paket i Spark. I sparklyr::spark_apply()anges som standard argumentet packages till FALSE. Detta kopierar biblioteken i de aktuella libPaths till arbetarna, så att du kan importera och använda dem på arbetarna. Du kan till exempel köra följande för att generera ett caesarkrypterat meddelande med sparklyr::spark_apply():
install.packages("caesar", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
spark_version <- sparkR.version()
config <- spark_config()
sc <- spark_connect(master = "yarn", version = spark_version, spark_home = "/opt/spark", config = config)
apply_cases <- function(x) {
library(caesar)
caesar("hello world")
}
sdf_len(sc, 5) %>%
spark_apply(apply_cases, packages=FALSE)
Relaterat innehåll
Läs mer om R-funktionerna: