Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Tidyverse är en samling R-paket som dataexperter ofta använder i vardagliga dataanalyser. Den innehåller paket för dataimport (readr), datavisualisering (ggplot2), datamanipulering (dplyr, tidyr), funktionell programmering (purrr) och modellskapande (tidymodels) osv. Paketen i tidyverse är utformade för att fungera sömlöst och följa en konsekvent uppsättning designprinciper.
Microsoft Fabric distribuerar den senaste stabila versionen av tidyverse med varje körningsversion. Importera och börja använda dina välbekanta R-paket.
Förutsättningar
Skaffa en Microsoft Fabric-prenumeration. Eller registrera dig för en kostnadsfri utvärderingsversion av Microsoft Fabric.
Logga in på Microsoft Fabric.
Använd upplevelseväxlaren längst ner till vänster på startsidan för att växla till Fabric.

Öppna eller skapa en notebook-fil. Mer information finns i Använda Microsoft Fabric-notebook-filer.
Ange språkalternativet SparkR (R) för att ändra det primära språket.
Bifoga anteckningsboken till ett sjöhus. Till vänster väljer du Lägg till för att lägga till ett befintligt sjöhus eller för att skapa ett sjöhus.
Last tidyverse
# load tidyverse
library(tidyverse)
Dataimport
readr är ett R-paket som innehåller verktyg för att läsa rektangulära datafiler som CSV, TSV och filer med fast bredd.
readr ger ett snabbt och användarvänligt sätt att läsa rektangulära datafiler som att tillhandahålla funktioner read_csv() och read_tsv() för att läsa CSV- respektive TSV-filer.
Nu ska vi först skapa en R-dataram, skriva den till lakehouse med hjälp av readr::write_csv() och läsa tillbaka den med readr::read_csv().
Kommentar
Om du vill komma åt Lakehouse-filer med hjälp av readrmåste du använda sökvägen till fil-API:et. I Lakehouse-utforskaren högerklickar du på den fil eller mapp som du vill komma åt och kopierar sökvägen till fil-API:et från snabbmenyn.
# create an R data frame
set.seed(1)
stocks <- data.frame(
time = as.Date('2009-01-01') + 0:9,
X = rnorm(10, 20, 1),
Y = rnorm(10, 20, 2),
Z = rnorm(10, 20, 4)
)
stocks
Sedan skriver vi data till lakehouse med sökvägen Fil-API.
# write data to lakehouse using the File API path
temp_csv_api <- "/lakehouse/default/Files/stocks.csv"
readr::write_csv(stocks,temp_csv_api)
Läs data från Lakehouse.
# read data from lakehouse using the File API path
stocks_readr <- readr::read_csv(temp_csv_api)
# show the content of the R date.frame
head(stocks_readr)
Datastädning
tidyr är ett R-paket som innehåller verktyg för att arbeta med röriga data. Huvudfunktionerna i tidyr är utformade för att hjälpa dig att omforma data till ett snyggt format. Prydliga data har en specifik struktur där varje variabel är en kolumn och varje observation är en rad, vilket gör det enklare att arbeta med data i R och andra verktyg.
Funktionen i gather() kan till exempel tidyr användas för att konvertera breda data till långa data. Här är ett exempel:
# convert the stock data into longer data
library(tidyr)
stocksL <- gather(data = stocks, key = stock, value = price, X, Y, Z)
stocksL
Funktionell programmering
purrr är ett R-paket som förbättrar R:s funktionella programmeringsverktyg genom att tillhandahålla en komplett och konsekvent uppsättning verktyg för att arbeta med funktioner och vektorer. Det bästa stället att börja med är serien purrr med map() funktioner som gör att du kan ersätta många för loopar med kod som är både mer kortfattad och lättare att läsa. Här är ett exempel på hur du använder map() för att tillämpa en funktion på varje element i en lista:
# double the stock values using purrr
library(purrr)
stocks_double = map(stocks %>% select_if(is.numeric), ~.x*2)
stocks_double
Datamanipulering
dplyr är ett R-paket som ger en konsekvent uppsättning verb som hjälper dig att lösa de vanligaste problemen med datamanipulering, till exempel att välja variabler baserat på namnen, välja fall baserat på värdena, minska flera värden till en enda sammanfattning och ändra ordningen på raderna osv. Här följer några exempel:
# pick variables based on their names using select()
stocks_value <- stocks %>% select(X:Z)
stocks_value
# pick cases based on their values using filter()
filter(stocks_value, X >20)
# add new variables that are functions of existing variables using mutate()
library(lubridate)
stocks_wday <- stocks %>%
select(time:Z) %>%
mutate(
weekday = wday(time)
)
stocks_wday
# change the ordering of the rows using arrange()
arrange(stocks_wday, weekday)
# reduce multiple values down to a single summary using summarise()
stocks_wday %>%
group_by(weekday) %>%
summarize(meanX = mean(X), n= n())
Datavisualisering
ggplot2 är ett R-paket för deklarativt skapande av grafik, baserat på Grafikens grammatik. Du anger data, berättar ggplot2 hur du mappar variabler till estetik, vilka grafiska primitiver som ska användas och det tar hand om informationen. Nedan följer några exempel:
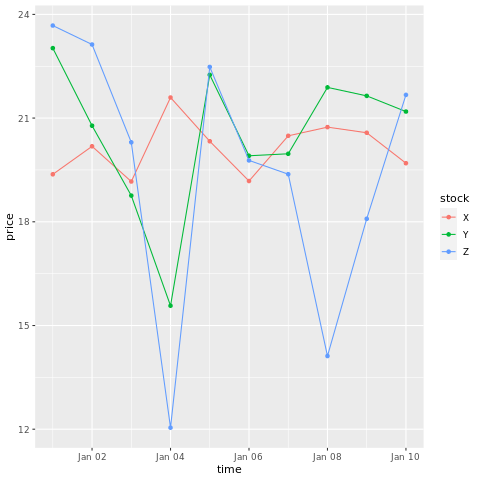
# draw a chart with points and lines all in one
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_point()+
geom_line()
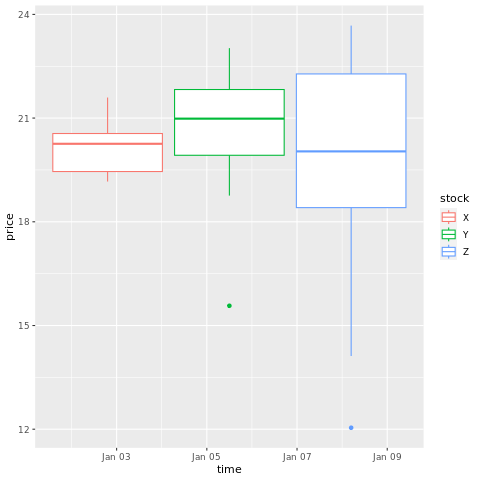
# draw a boxplot
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_boxplot()
Modellbyggnad
Ramverket tidymodels är en samling paket för modellering och maskininlärning med hjälp av tidyverse principer. Den omfattar en lista över kärnpaket för en mängd olika modellskapande uppgifter, till exempel rsample för att dela upp exempel på tränings-/testdatauppsättningar, parsnip för modellspecifikation, recipes för förbearbetning av data, workflows för modellering av arbetsflöden, tune för justering av hyperparametrar, yardstick för modellutvärdering, broom för att städa modellutdata och dials för att hantera justeringsparametrar. Du kan lära dig mer om paketen genom att besöka tidymodels webbplats. Här är ett exempel på hur du skapar en linjär regressionsmodell för att förutsäga miles per gallon (mpg) för en bil baserat på dess vikt (wt):
# look at the relationship between the miles per gallon (mpg) of a car and its weight (wt)
ggplot(mtcars, aes(wt,mpg))+
geom_point()
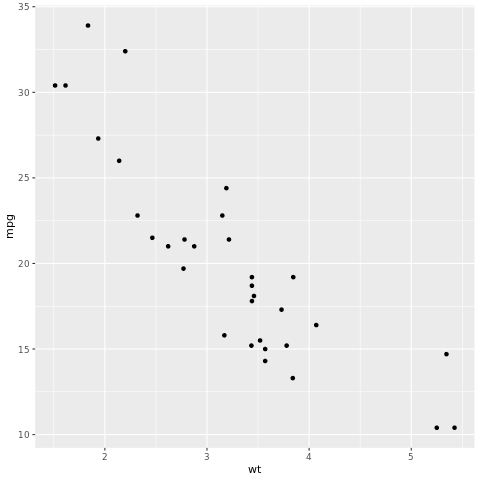
Från punktdiagrammet ser relationen ungefär linjär ut och variansen ser konstant ut. Nu ska vi försöka modellera detta med linjär regression.
library(tidymodels)
# split test and training dataset
set.seed(123)
split <- initial_split(mtcars, prop = 0.7, strata = "cyl")
train <- training(split)
test <- testing(split)
# config the linear regression model
lm_spec <- linear_reg() %>%
set_engine("lm") %>%
set_mode("regression")
# build the model
lm_fit <- lm_spec %>%
fit(mpg ~ wt, data = train)
tidy(lm_fit)
Använd den linjära regressionsmodellen för att förutsäga testdatauppsättningen.
# using the lm model to predict on test dataset
predictions <- predict(lm_fit, test)
predictions
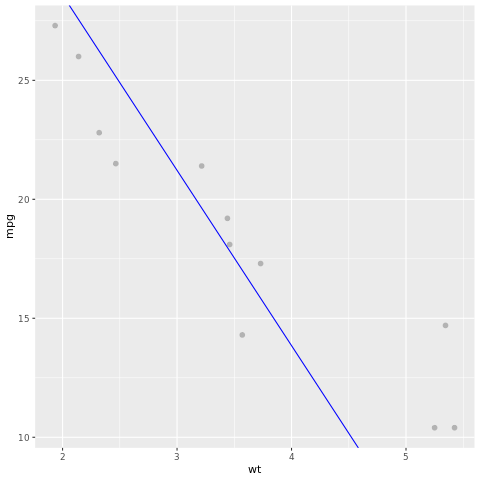
Låt oss ta en titt på modellresultatet. Vi kan rita modellen som ett linjediagram och testa sanningsdata som punkter i samma diagram. Modellen ser bra ut.
# draw the model as a line chart and the test data groundtruth as points
lm_aug <- augment(lm_fit, test)
ggplot(lm_aug, aes(x = wt, y = mpg)) +
geom_point(size=2,color="grey70") +
geom_abline(intercept = lm_fit$fit$coefficients[1], slope = lm_fit$fit$coefficients[2], color = "blue")