Hämta data från Azure Storage
I den här artikeln får du lära dig hur du hämtar data från Azure Storage (ADLS Gen2-container, blobcontainer eller enskilda blobar) till antingen en ny eller befintlig tabell.
Förutsättningar
- En arbetsyta med en Microsoft Fabric-aktiverad kapacitet
- En KQL-databas med redigeringsbehörigheter
- Ett lagringskonto
Källa
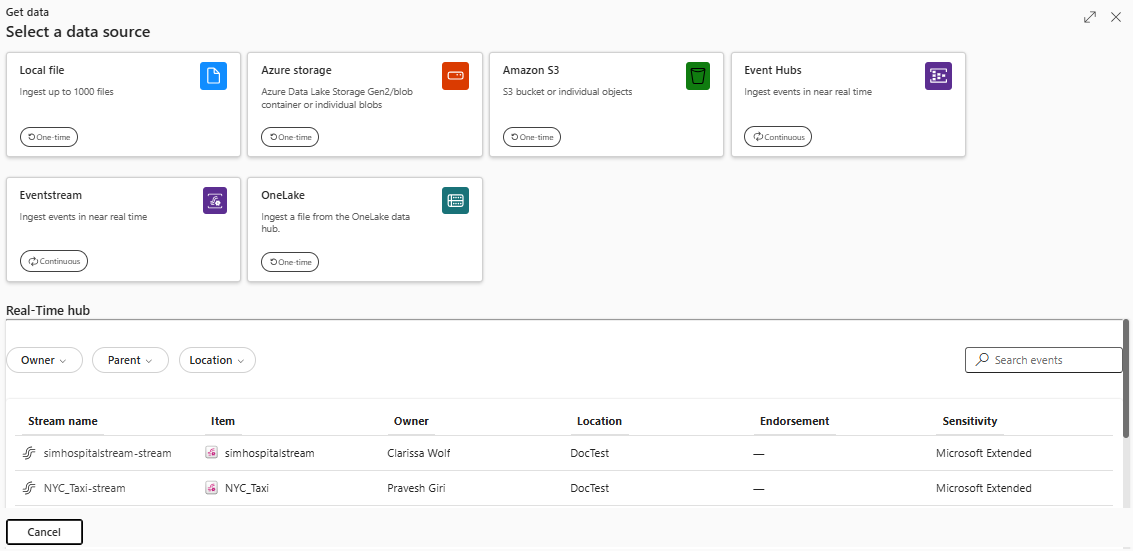
I det nedre menyfliksområdet i din KQL-databas väljer du Hämta data.
I fönstret Hämta data är fliken Källa markerad.
Välj datakällan i den tillgängliga listan. I det här exemplet matar du in data från Azure Storage.

Konfigurera
Välj en måltabell. Om du vill mata in data i en ny tabell väljer du + Ny tabell och anger ett tabellnamn.
Kommentar
Tabellnamn kan innehålla upp till 1 024 tecken, inklusive blanksteg, alfanumeriskt, bindestreck och understreck. Specialtecken stöds inte.
Om du vill lägga till datakällan klistrar du in lagrings-niska veze i URI-fältet och väljer +sedan . I följande tabell visas de autentiseringsmetoder som stöds och de behörigheter som krävs för att mata in data från Azure Storage.
Autentiseringsmetod Enskild blob Blobcontainer Azure Data Lake Storage Gen2 SAS-token (Shared Access) Läsa och skriva Läsa och lista Läsa och lista Åtkomstnyckel för lagringskonto Kommentar
- Du kan antingen lägga till upp till 10 enskilda blobar eller mata in upp till 5 000 blobar från en enda container. Du kan inte mata in båda samtidigt.
- Varje blob kan vara högst 1 GB okomprimerad.
Om du klistrade in en niska veze för en blobcontainer eller en Azure Data Lake Storage Gen2 kan du lägga till följande valfria filter:
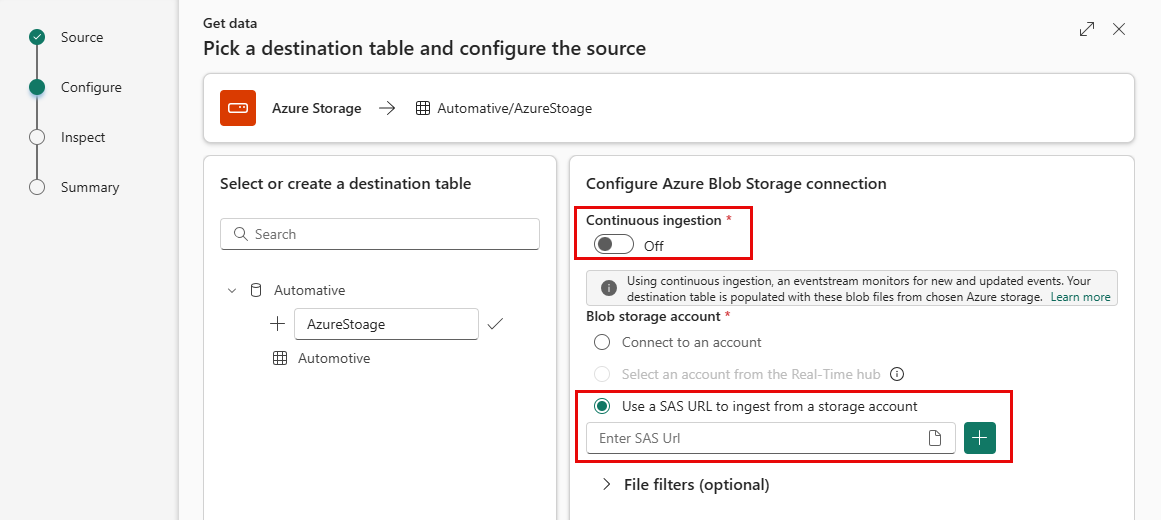
Inställning Fältbeskrivning Filfilter (valfritt) Folder path Filtrerar data för att mata in filer med en specifik mappsökväg. Filnamnstillägg Filtrerar data för att mata in filer med ett specifikt filnamnstillägg.
Välj Nästa

Undersöka
Fliken Inspektera öppnas med en förhandsgranskning av data.
Slutför inmatningsprocessen genom att välja Slutför.

Valfritt:
- Välj Kommandovisningsprogram för att visa och kopiera de automatiska kommandon som genereras från dina indata.
- Använd listrutan Schemadefinitionsfil för att ändra den fil som schemat härleds från.
- Ändra det automatiskt härledda dataformatet genom att välja önskat format i listrutan. Mer information finns i Dataformat som stöds av Realtidsinformation.
- Redigera kolumner.
- Utforska Avancerade alternativ baserat på datatyp.
Redigera kolumner
Kommentar
- För tabellformat (CSV, TSV, PSV) kan du inte mappa en kolumn två gånger. Om du vill mappa till en befintlig kolumn tar du först bort den nya kolumnen.
- Du kan inte ändra en befintlig kolumntyp. Om du försöker mappa till en kolumn med ett annat format kan du få tomma kolumner.
Vilka ändringar du kan göra i en tabell beror på följande parametrar:
- Tabelltypen är ny eller befintlig
- Mappningstypen är ny eller befintlig
| Tabelltyp | Mappningstyp | Tillgängliga justeringar |
|---|---|---|
| Ny tabell | Ny mappning | Byt namn på kolumn, ändra datatyp, ändra datakälla, mappningstransformering, lägga till kolumn, ta bort kolumn |
| Befintlig tabell | Ny mappning | Lägg till kolumn (där du sedan kan ändra datatyp, byta namn på och uppdatera) |
| Befintlig tabell | Befintlig mappning | inget |

Mappa transformeringar
Vissa dataformatmappningar (Parquet, JSON och Avro) stöder enkla inmatningstidstransformeringar. Om du vill använda mappningstransformeringar skapar eller uppdaterar du en kolumn i fönstret Redigera kolumner .
Mappningstransformeringar kan utföras på en kolumn av typen sträng eller datetime, där källan har datatypen int eller long. Mappningstransformeringar som stöds är:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Avancerade alternativ baserat på datatyp
Tabell (CSV, TSV, PSV):
Om du matar in tabellformat i en befintlig tabell kan du välja Avancerat>behåll tabellschema. Tabelldata innehåller inte nödvändigtvis de kolumnnamn som används för att mappa källdata till befintliga kolumner. När det här alternativet är markerat görs mappningen i ordning och tabellschemat förblir detsamma. Om det här alternativet är avmarkerat skapas nya kolumner för inkommande data, oavsett datastruktur.
Om du vill använda den första raden som kolumnnamn väljer du Avancerad>första rad är kolumnrubrik.

JSON:
Välj Avancerade>kapslade nivåer mellan 1 och 100 för att fastställa kolumndelningen för JSON-data.
Om du väljer Avancerade>Hoppa över JSON-rader med fel matas data in i JSON-format. Om du lämnar den här kryssrutan avmarkerad matas data in i multijson-format.

Sammanfattning
I fönstret Dataförberedelse markeras alla tre stegen med gröna bockmarkeringar när datainmatningen har slutförts. Du kan välja ett kort för att fråga, släppa inmatade data eller se en instrumentpanel för inmatningssammanfattningen.

Relaterat innehåll
- Information om hur du hanterar databasen finns i Hantera data
- Information om hur du skapar, lagrar och exporterar frågor finns i Fråga efter data i en KQL-frågeuppsättning