Exportera Dataverse data i Delta Lake-format
Använd Azure Synapse Link for Dataverse för att exportera dina Microsoft Dataverse data till Azure Synapse Analytics i Delta Lake-format. Utforska dina data och öka hastigheten på tiden för att få insikt. Den här artikeln innehåller följande information och beskriver hur du utför följande åtgärder:
- Förklarar Delta Lake och Parquet och varför du bör exportera data i detta format.
- Exportera dina Dataverse data till din Azure Synapse Analytics arbetsyta i Delta Lake-format med Azure Synapse Link.
- Övervaka din Azure Synapse Link och datakonvertering.
- Visa data från Azure Data Lake Storage Gen2.
- Visa data från Synapse-arbetsyta.
Viktigt
- Om du uppgraderar från CSV till Delta Lake med befintliga anpassade vyer rekommenderar vi att du uppdaterar skriptet så att alla partitionerade tabeller uppdateras till icke-partitionerade. Gör detta genom att söka efter
_partitioned-instanser och ersätta dem med en tom sträng. - För Dataverse konfigurationen, är tillägg aktiverat som standard för att exportera CSV-data i
appendonly-läge. Tabellen Delta Lake-tabellen inkluderar emellertid en uppdateringsstruktur eftersom Delta Lake-konvertering omfattar en periodisk sammanfogningsprocess. - Det uppstår inga kostnader för generering av Spark-pooler. Avgifter uppstår endast när ett Spark-jobb har körts på mål-Spark-poolen och Spark-instansen instansieras på begäran. Dessa kostnader är relaterade till användningen av Azure Synapse workspace Spark och faktureras månadsvis. Kostnaden för att utföra Spark-beräkning beror i huvudsak på tidsintervallen för inkrementell uppdatering och datavolymerna. Mer information: Azure Synapse Analytics-prissättning
- Det är viktigt att ta med dessa extra kostnader i beräkningen när du bestämmer dig för att använda funktionen eftersom dessa inte är valfria och måste betalas för att kunna fortsätta använda den här funktionen.
- Slutet av livscykeln meddelat (EOLA) för Azure Synapse körtid för Apache Spark 3.1 tillkännagavs den 26 januari 2023. I enlighet med Synapse körtid för Apache Spark livscykelpolicy, Azure Synapse körtid för Apache Spark 3.1 att avvecklas och inaktiveras från och med den 26 januari 2024. Efter EOL-datumet är de utrangerade körtiderna inte tillgängliga för nya Spark-pooler och befintliga arbetsflöden kan inte köras. Metadata kommer tillfälligt att finnas kvar i Synapse workspace. Mer information: Azure Synapse körtid för Apache Spark 3.1 (EOLA). Om du vill att Synapse Link för Dataverse med export till Delta Lake ska uppgraderas till Spark 3.3 utför du en lokal uppgradering för dina befintliga profiler. Mer information: Uppgradering på plats till Apache Spark 3.3 med Delta Lake 2.2
- Från och med den 4 januari 2024 kommer endast Spark Pool version 3.3 att stödjas när länken skapas.
Anteckning
Azure Synapse Link-statusen i Power Apps (make.powerapps.com) återspeglar omvandlingsstatusen för Delta Lake:
Countvisar antalet poster i tabellen Delta Lake-tabellen.Last synchronized onDatetime representerar den sista lyckade tidsstämpeln för konverteringen.Sync statusvisas som aktiv när datasynkronisering och Delta Lake-konvertering har slutförts, vilket indikerar att datan är klara för användning.
Vad är Delta Lake?
Delta Lake är ett projekt med öppen källkod som gör det möjligt att bygga en data sjöhusarkitektur ovanpå datasjöar. Delta Lake tillhandahåller ACID-transaktioner (atomicitet, konsekvens, isolering och varaktighet), skalbar metadatahantering och förenar streaming och batchdatabehandling ovanpå befintliga datasjöar. Azure Synapse Analytics är kompatibelt med Linux Foundation Delta Lake. Den aktuella versionen av Delta Lake som ingår i Azure Synapse har språkstöd för Scala, PySpark och .NET. Mer information: Vad är Delta Lake?. Du kan också lära dig mer i videon Introduktion till Delta.
Apache Parquet är grundformatet för Delta Lake som gör att du kan använda de effektiva komprimerings- och kodningsscheman som ingår i formatet. Parquet-filformat använder kolumnvis komprimering. Det är effektivt och sparar lagringsutrymme. Frågor som hämtar specifika kolumnvärden behöver inte läsa hela raddata och på så sätt förbättra prestanda. Därför behöver serverlös SQL-pool mindre tid och färre lagringsförfrågningar för att läsa data.
Varför använda Delta Lake?
- Skalbarhet: Delta Lake är byggd ovanpå Apache-licensen med öppen källkod, som är designad för att möta industristandarder för hantering av storskalig databearbetningslaster.
- Tillförlitlighet: Delta Lake tillhandahåller ACID-transaktioner som säkerställer datakonsistens och tillförlitlighet även vid misslyckanden eller samtidig åtkomst.
- Prestanda: Delta Lake använder kolumnlagringsformatet för Parquet, vilket ger bättre komprimering och kodning, vilket kan leda till bättre frågeprestanda jämfört med CSV-filer.
- Kostnadseffektivt: Delta-filformatet är en mycket komprimerad datalagringsteknik som erbjuder stora potentiella lagringssparande åtgärder för företag. Formatet är speciellt utformat för att optimera databearbetning och potentiellt minska den totala mängden data som bearbetas eller körs som krävs för databehandling på begäran.
- Regelefterlevnad av dataskydd: Delta Lake med Azure Synapse Link tillhandahåller verktyg och funktioner inklusive mjuk borttagning och permanent borttagning för att följa olika datasekretessbestämmelser, inklusive allmän dataskyddsförordning (GDPR).
Hur fungerar Delta Lake med Azure Synapse Link for Dataverse?
När du skapar en Azure Synapse Link for Dataverse kan du aktivera export till funktionen Delta Lake och ansluta till en Synapse-arbetsyta och Spark-pool. Azure Synapse Link exporterar de valda Dataverse-tabellerna i CSV-format med angivna tidsintervall och bearbetar dem med hjälp av ett Delta Lake konverteringsjobb för Spark. När konverteringsprocessen har slutförts används CSV-data för att spara lagringsutrymme. Dessutom schemaläggs en serie underhållsjobb varje dag, med automatiskt komprimerande och fungerande processer för att sammanfoga och rensa datafiler för att optimera lagringsutrymmet och förbättra frågeprestanda.
Förutsättningar
- Dataverse: Du måste ha säkerhetsrollen Dataverse systemadministratör. Dessutom måste tabeller du vill exportera via Azure Synapse Link ha egenskapen Spåra ändringar aktiverad. Mer information: Avancerad sökning
- Azure Data Lake Storage Gen2: Du måste ha ett Azure Data Lake Storage Gen2-konto i samt åtkomst till rollerna Ägare och Storage Blob-datadeltagare. Ditt lagringskonto måste aktivera hierarkisk namnrymd och offentlig nätverksåtkomst både för den första installationen och deltasynkronisering. Tillåt åtkomst till lagringskontonyckel krävs endast vid den första installationen.
- Synapse workspace: Du måste ha en Synapse workspace och rollen Ägare i åtkomstkontroll (IAM) och rollåtkomst Synapse-administratör i Synapse Studio. Synapse-arbetsytan måste finnas i samma region som ditt Azure Data Lake Storage Gen2-konto. Lagringskontot måste läggas till som en länkad tjänst i Synapse Studio. Skapa en Synapse-arbetsyta genom att gå till Skapa en Synapse-arbetsyta.
- En Spark Pool i den anslutna Azure Synapse workspace med Apache Spark version 3.3 som använder rekommenderade konfigurationen av Spark Pool. Information om hur du skapar en lösning med Spark Pool finns i Skapa ny Apache Spark pool.
- Microsoft Dynamics 365 minsta version kravet för att använda denna funktion är 9.2.22082. Mer information: Anmäl dig för tidig åtkomst till uppdateringar
Rekommenderad Spark Pool-konfiguration
Den här konfigurationen kan betraktas som ett bootstrap-steg för genomsnittligt användningsfall.
- Nodstorlek: liten (4 vCores/32 GB)
- Autoskalning: Aktiverad
- Antalet noder: 5 till 10
- Automatisk pausning: Aktiverad
- Antal minuter inaktiv: 5
- Apache Spark: 3.3
- Dynamiskt allokerade verkställare: Aktiverad
- Standardantal verkställare: 1 till 9
Anslut Dataverse till Synapse-arbetsyta och exportera data i Delta Lake-format
Logga in på Power Apps och välj den miljö du vill använda.
I vänstra navigeringsfönstret, välj Azure Synapse Link. Om objektet inte finns i sidopanelsfönstret väljer du ... Mer och markerar sedan det objekt du vill använda.
Markera + Ny länk i kommandofältet
Välj Anslut till Azure Synapse Analytics arbetsytan och välj sedan prenumeration, resursgrupp och arbetsytans namn.
Välj Använd Spark-pool för bearbetning och välj sedan den förinställda Spark-pool och Lagringskontot.
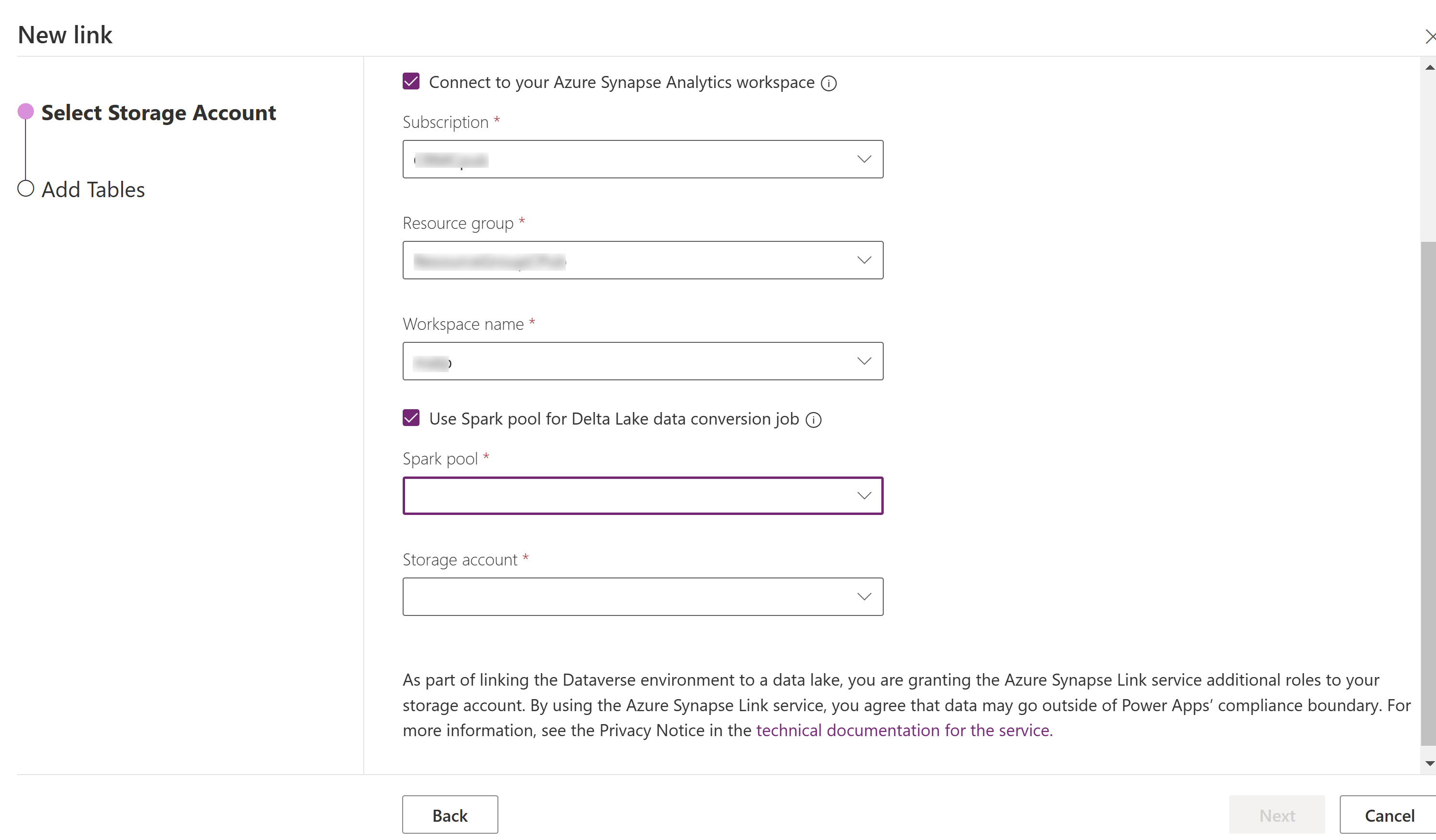
Välj Nästa.
Lägg till de tabeller du vill exportera och välj sedan Avancerad.
Alternativt kan du välja Visa avancerade konfigurationsinställningar och ange tidsintervallet, i minuter, för hur ofta de inkrementella uppdateringarna ska registreras.
Välj Spara.
Övervaka din Azure Synapse Link och datakonvertering
- Välj önskad Azure Synapse Link och välj sedan Gå till Azure Synapse Analytics arbetsyta i kommandofältet.
- Välj Övervala > Apache Spark-appar. Mer information: Använd Synapse Studio för att övervaka dina Apache Spark-appar
Visa data från Synapse-arbetsyta
- Välj önskad Azure Synapse Link och välj sedan Gå till Azure Synapse Analytics arbetsyta i kommandofältet.
- Expandera Lake-databaser i den vänstra panelen, välj dataverse-environmentNameorganizationUniqueName och expandera sedan Tabeller. Alla Parquet-tabeller visas och kan analyseras med namnkonventionerna DataverseTableName. (Non_partitioned tabell).
Visa data från Azure Data Lake Storage Gen2
- Välj önskad Azure Synapse Link och välj Gå till Azure Data Lake i kommandofältet.
- Markera behållare under Datalagring.
- Välj *dataverse- *environmentName-organizationUniqueName. Alla parquet-filer lagras i mappen deltalake.
Uppgradering på plats till Apache Spark 3.3 med Delta Lake 2.2
Förutsättningar
- Du måste ha en befintlig Azure Synapse Link for Dataverse Delta Lake-profil som körs med en Synapse Spark i version 3.1.
- Du måste skapa en ny Synapse Spark-pool med Spark version 3.3, med samma eller högre noder hårdvarukonfiguration inom samma Synapse workspace. Information om hur du skapar en lösning med Spark Pool finns i Skapa ny Apache Spark pool. Denna Spark-pool bör skapas oberoende av den nuvarande 3.1-poolen.
Uppgradering på plats till Spark 3.3:
- Logga in i Power Apps och välj önskad miljö.
- I vänstra navigeringsfönstret, välj Azure Synapse Link. Om objektet inte finns i det vänstra navigeringsfönstret väljer du ... Mer och markerar sedan det objekt du vill använda.
- Öppna Azure Synapse Link-profil och välj sedan Uppgradera Apache Spark 3.3 med Delta Lake 2.2.
- Välj den tillgängliga Spark-poolen från listan och välj sedan Uppdatera.
Anteckning
Uppgraderingen av Spark-poolen sker endast när ett nytt Delta Lake-konvertering Spark-jobb utlöses. Se till att du har minst en dataändring efter att du har valt Uppdatering.
Se även
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för