Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
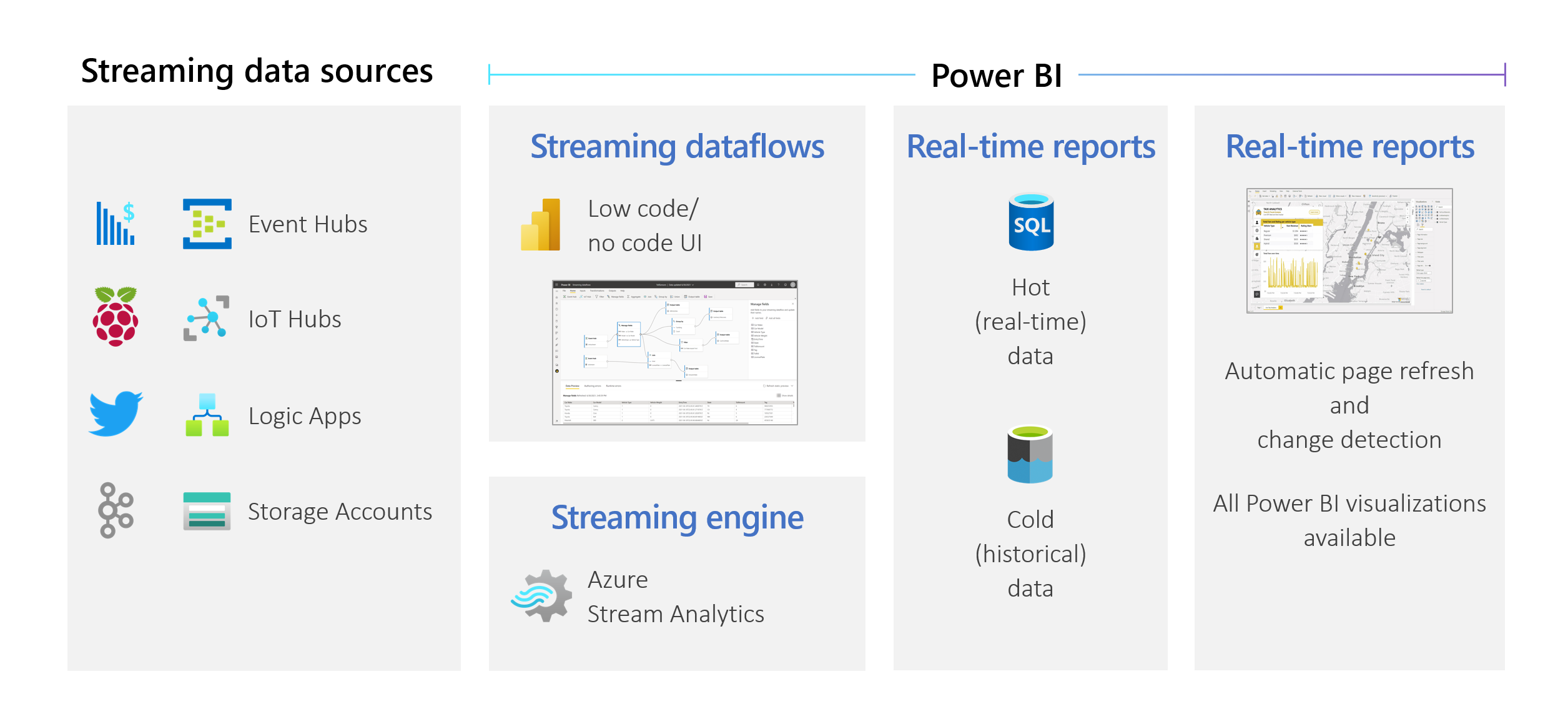
Organisationer vill arbeta med data när de kommer in, inte dagar eller veckor senare. Visionen för Power BI är enkel: skillnaderna mellan batch, realtid och strömning bör försvinna. Användarna bör kunna arbeta med alla data så snart de är tillgängliga. Analytiker behöver vanligtvis teknisk hjälp för att hantera strömmande datakällor, förberedelse av data, komplexa tidsbaserade åtgärder och datavisualisering i realtid. IT-avdelningar förlitar sig ofta på anpassade system och en kombination av tekniker från olika leverantörer för att utföra analyser i tid på data. Utan den här komplexiteten kan de inte ge beslutsfattare information i nära realtid.
Strömmande dataflöden gör det möjligt för författare att ansluta till, mata in, kombinera, modellera och skapa rapporter baserat på direktuppspelning i nästan realtidsdata i Power BI-tjänst. Tjänsten möjliggör dra och släpp-funktioner utan kod. Du kan blanda och matcha strömmande data med batchdata om du behöver via ett användargränssnitt (UI) som innehåller en diagramvy för enkel datakompilering. Det sista objektet som skapas är ett dataflöde som kan användas i realtid för att skapa mycket interaktiv rapportering i nära realtid. Alla funktioner för datavisualisering i Power BI fungerar med strömmande data, precis som med batchdata.
Viktigt!
Strömmande dataflöden har dragits tillbaka och är inte längre tillgängligt.
Azure Stream Analytics har slagit samman funktionerna i strömmande dataflöden. Mer information om tillbakadragande av strömmande dataflöden finns i meddelandet om tillbakadragande.
 Användare kan utföra dataförberedelseåtgärder som kopplingar och filter. De kan också utföra aggregeringar av tidsfönster (till exempel rullande, hoppande och sessionsfönster) för grupp-by-åtgärder.
Strömmande dataflöden i Power BI gör det möjligt för organisationer att:
Användare kan utföra dataförberedelseåtgärder som kopplingar och filter. De kan också utföra aggregeringar av tidsfönster (till exempel rullande, hoppande och sessionsfönster) för grupp-by-åtgärder.
Strömmande dataflöden i Power BI gör det möjligt för organisationer att:
- Fatta säkra beslut i nära realtid. Organisationer kan vara mer flexibla och vidta meningsfulla åtgärder baserat på de senaste insikterna.
- Demokratisera strömmande data. Organisationer kan göra data mer tillgängliga och enklare att tolka med en lösning utan kod, och den här tillgängligheten minskar IT-resurser.
- Påskynda tiden till insikt med hjälp av en lösning för direktuppspelning från slutpunkt till slutpunkt med integrerad datalagring och business intelligence.
Strömmande dataflöden stöder DirectQuery och automatisk siduppdatering/ändringsidentifiering. Med det här stödet kan användare skapa rapporter som uppdateras nästan i realtid, upp till varje sekund, med hjälp av alla visuella objekt som är tillgängliga i Power BI.
Krav
Innan du skapar ditt första strömmande dataflöde måste du uppfylla följande krav:
För att skapa och köra ett strömmande dataflöde behöver du en arbetsyta som ingår i en Premium-kapacitet eller PPU-licens (Premium per användare).
Viktigt!
Om du använder en PPU-licens och vill att andra användare ska använda rapporter som skapats med strömmande dataflöden som uppdateras i realtid behöver de också en PPU-licens. De kan sedan använda rapporterna med samma uppdateringsfrekvens som du har konfigurerat, om uppdateringen är snabbare än var 30:e minut.
Aktivera dataflöden för din klientorganisation. Mer information finns i Aktivera dataflöden i Power BI Premium.
För att säkerställa att strömmande dataflöden fungerar i din Premium-kapacitet måste den förbättrade beräkningsmotorn vara aktiverad. Motorn är aktiverad som standard, men Power BI-kapacitetsadministratörer kan inaktivera den. I så fall kontaktar du administratören för att aktivera den.
Den förbättrade beräkningsmotorn är endast tillgänglig i Premium P- eller Embedded A3-kapaciteter och större kapaciteter. Om du vill använda strömmande dataflöden behöver du antingen PPU, en Premium P-kapacitet av valfri storlek eller en inbäddad A3- eller större kapacitet. Mer information om Premium-SKU:er och deras specifikationer finns i Kapacitet och SKU:er i Power BI Embedded-analys.
Om du vill skapa rapporter som uppdateras i realtid kontrollerar du att din administratör (kapacitet eller Power BI för PPU) har aktiverat automatisk siduppdatering. Kontrollera också att administratören har tillåtit ett minsta uppdateringsintervall som matchar dina behov. Mer information finns i Automatisk siduppdatering i Power BI.
Skapa ett strömmande dataflöde
Ett strömmande dataflöde, som dess dataflödesrelativitet, är en samling entiteter (tabeller) som skapats och hanteras på arbetsytor i Power BI-tjänst. En tabell är en uppsättning fält som används för att lagra data, ungefär som en tabell i en databas.
Du kan lägga till och redigera tabeller i ditt strömmande dataflöde direkt från arbetsytan där dataflödet skapades. Den största skillnaden med vanliga dataflöden är att du inte behöver oroa dig för uppdateringar eller frekvens. På grund av typen av strömmande data kommer det in en kontinuerlig ström. Uppdateringen är konstant eller oändlig om du inte stoppar den.
Kommentar
Du kan bara ha en typ av dataflöde per arbetsyta. Om du redan har ett vanligt dataflöde på din Premium-arbetsyta kan du inte skapa ett strömmande dataflöde (och vice versa).
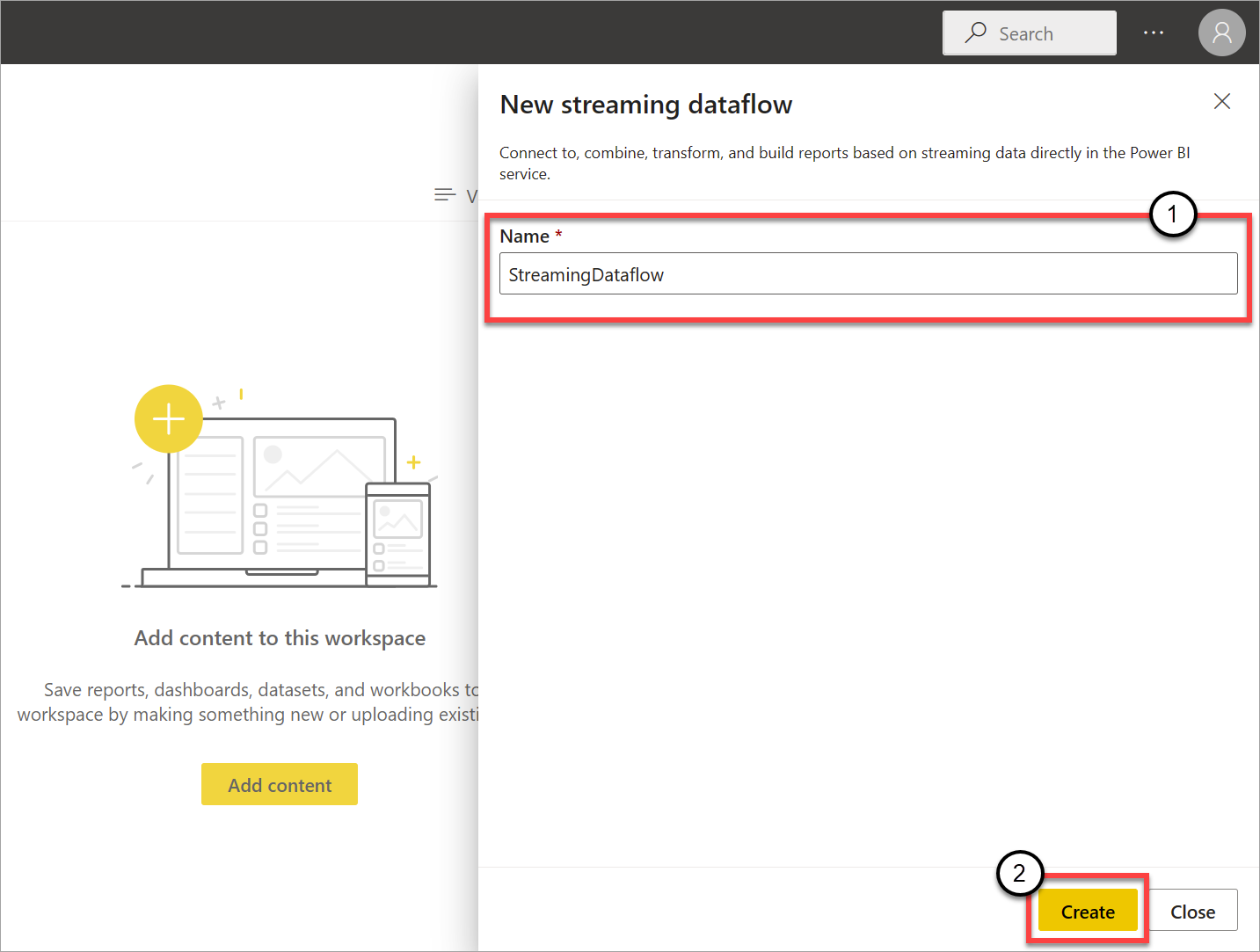
Så här skapar du ett strömmande dataflöde:
Öppna Power BI-tjänst i en webbläsare och välj sedan en Premium-aktiverad arbetsyta. (Strömmande dataflöden, till exempel vanliga dataflöden, är inte tillgängliga i Min arbetsyta.)
Välj listrutan Nytt och välj sedan Strömmande dataflöde.

I sidofönstret som öppnas måste du namnge ditt strömmande dataflöde. Ange ett namn i rutan Namn (1) och välj sedan Skapa (2).
Den tomma diagramvyn för strömmande dataflöden visas.
Följande skärmbild visar ett färdigt dataflöde. Den visar alla avsnitt som är tillgängliga för redigering i användargränssnittet för strömmande dataflöden.

Menyfliksområde: I menyfliksområdet följer avsnitt ordningen på en "klassisk" analysprocess: indata (kallas även datakällor), transformeringar (strömmande ETL-åtgärder), utdata och en knapp för att spara dina framsteg.
Diagramvy: Den här vyn är en grafisk representation av ditt dataflöde, från indata till åtgärder till utdata.
Sidofönster: Beroende på vilken komponent du väljer i diagramvyn har du inställningar för att ändra varje indata, transformering eller utdata.
Flikar för dataförhandsgranskning, redigeringsfel och körningsfel: För varje kort som visas visar dataförhandsgranskningen resultat för det steget (live för indata och på begäran för omvandlingar och utdata).
I det här avsnittet sammanfattas även eventuella redigeringsfel eller varningar som du kan ha i dina dataflöden. Om du väljer varje fel eller varning väljs den transformeringen. Dessutom har du åtkomst till körningsfel när dataflödet körs, till exempel borttagna meddelanden.
Du kan alltid minimera det här avsnittet med strömmande dataflöden genom att välja pilen i det övre högra hörnet.
Ett strömmande dataflöde bygger på tre huvudkomponenter: strömmande indata, transformeringar och utdata. Du kan ha så många komponenter du vill, inklusive flera indata, parallella grenar med flera transformeringar och flera utdata.
Lägga till en strömmande indata
Om du vill lägga till en strömmande indata väljer du ikonen i menyfliksområdet och anger den information som behövs i sidofönstret för att konfigurera den. Från och med juli 2021 stöder förhandsversionen av strömmande dataflöden Azure Event Hubs och Azure IoT Hub som indata.
Azure Event Hubs- och Azure IoT Hub-tjänsterna bygger på en gemensam arkitektur för att underlätta snabb och skalbar inmatning och förbrukning av händelser. IoT Hub är särskilt skräddarsytt som en central meddelandehubb för kommunikation i båda riktningarna mellan ett IoT-program och dess anslutna enheter.
Azure Event Hubs
Azure Event Hubs är en stordataströmningsplattform och händelseinmatningstjänst. Den kan ta emot och behandla miljoner händelser per sekund. Data som skickas till en händelsehubb kan omvandlas och lagras med hjälp av valfri realtidsanalysprovider, eller så kan du använda batch- eller lagringskort.
Om du vill konfigurera en händelsehubb som indata för strömmande dataflöden väljer du ikonen Händelsehubb . Ett kort visas i diagramvyn, inklusive en sidoruta för dess konfiguration.
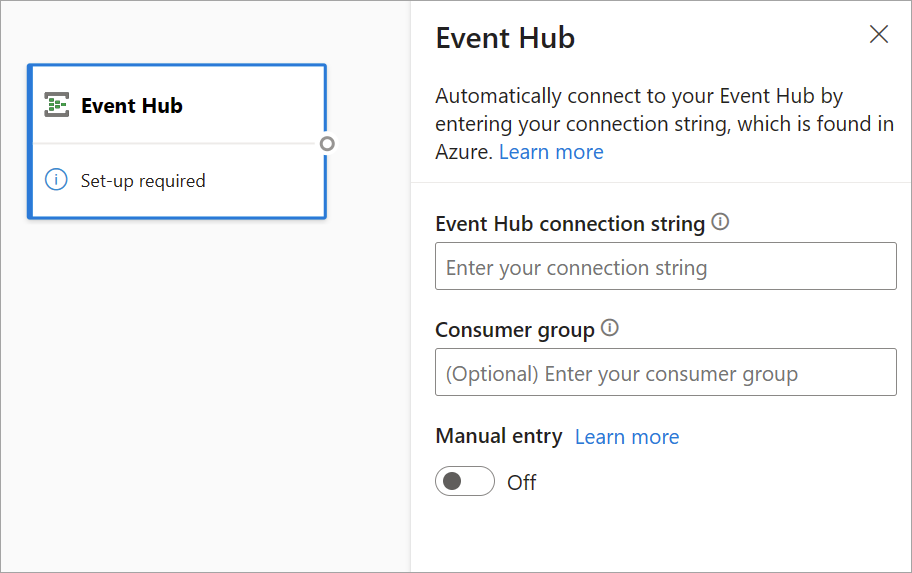
Du kan välja att klistra in Event Hubs-anslutningssträng. Strömmande dataflöden fyller i all nödvändig information, inklusive den valfria konsumentgruppen (som som standard är $Default). Om du vill ange alla fält manuellt kan du aktivera växlingsknappen för manuell post för att visa dem. Mer information finns i Hämta en Event Hubs-anslutningssträng.
När du har konfigurerat dina autentiseringsuppgifter för Event Hubs och valt Anslut kan du lägga till fält manuellt med hjälp av + Lägg till fält om du känner till fältnamnen. Du kan också identifiera fält och datatyper automatiskt baserat på ett exempel på inkommande meddelanden och välja Identifiera fält automatiskt. Om du väljer kugghjulsikonen kan du redigera autentiseringsuppgifterna om det behövs.
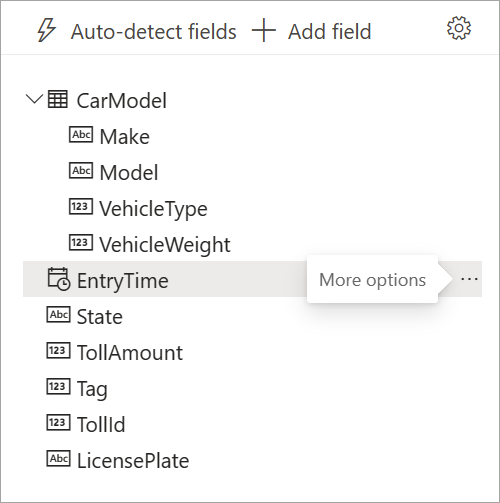
När strömmande dataflöden identifierar fälten kan du se dem i listan. Det finns också en live-förhandsversion av inkommande meddelanden i tabellen Dataförhandsgranskning under diagramvyn.
Du kan alltid redigera fältnamnen eller ta bort eller ändra datatypen genom att välja fler alternativ (...) bredvid varje fält. Du kan också expandera, välja och redigera alla kapslade fält från inkommande meddelanden, enligt följande bild.
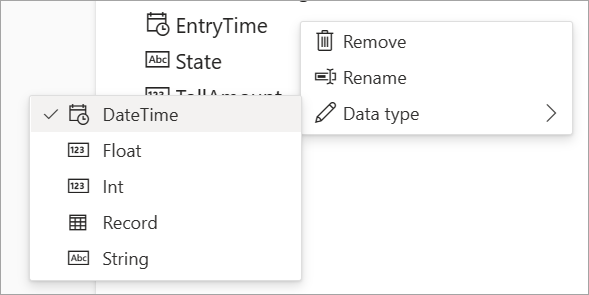
Azure IoT Hub
IoT Hub är en hanterad tjänst som finns i molnet. Den fungerar som en central meddelandehubb för kommunikation i båda riktningarna mellan ett IoT-program och dess anslutna enheter. Du kan ansluta miljontals enheter och deras serverdelslösningar på ett tillförlitligt och säkert sätt. Nästan vilken enhet som helst kan anslutas till en IoT-hubb.
IoT Hub-konfigurationen liknar Event Hubs-konfigurationen på grund av deras gemensamma arkitektur. Det finns dock vissa skillnader, bland annat var du hittar event hubs-kompatibla anslutningssträng för den inbyggda slutpunkten. Mer information finns i Läsa meddelanden från enhet till moln från den inbyggda slutpunkten.
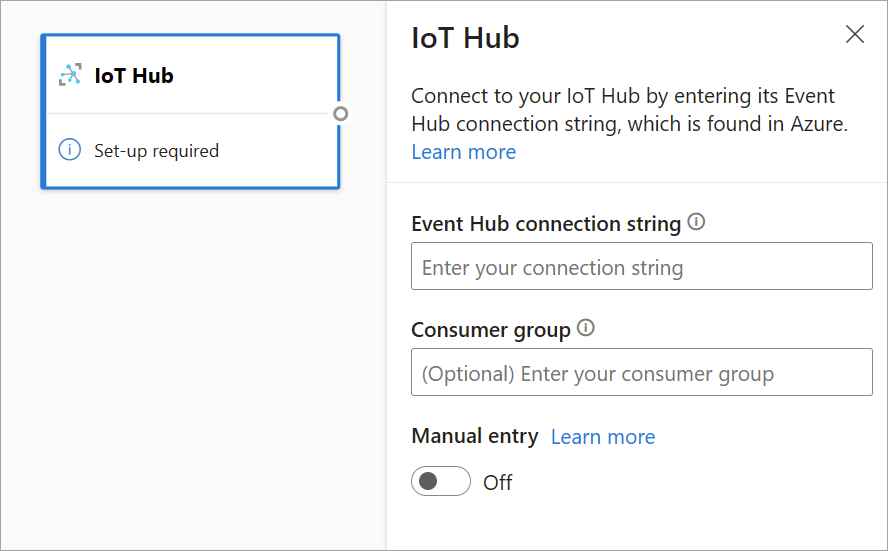
När du har klistrat in anslutningssträng för den inbyggda slutpunkten är alla funktioner för att välja, lägga till, identifiera automatiskt och redigera fält som kommer in från IoT Hub samma som i Event Hubs. Du kan också redigera autentiseringsuppgifterna genom att välja kugghjulsikonen.
Dricks
Om du har åtkomst till Event Hubs eller IoT Hub i organisationens Azure Portal och vill använda den som indata för ditt strömmande dataflöde kan du hitta anslutningssträng på följande platser:
För Event Hubs:
- I avsnittet Analys väljer du Alla tjänster>Event Hubs.
- Välj Event Hubs Namespace>Entiteter/Händelsehubbar och välj sedan händelsehubbens namn.
- I listan Principer för delad åtkomst väljer du en princip.
- Välj Kopiera till Urklipp bredvid fältet Anslutningssträng primärnyckel .
För IoT Hub:
- I avsnittet Sakernas Internet väljer du Alla tjänster>IoT Hubs.
- Välj den IoT-hubb som du vill ansluta till och välj sedan Inbyggda slutpunkter.
- Välj Kopiera till Urklipp bredvid den Event Hubs-kompatibla slutpunkten.
När du använder dataströmdata från Event Hubs eller IoT Hub har du åtkomst till följande metadatatidsfält i ditt strömmande dataflöde:
- EventProcessedUtcTime: Datum och tid då händelsen bearbetades.
- EventEnqueuedUtcTime: Datum och tid då händelsen togs emot.
Inget av dessa fält visas i förhandsversionen av indata. Du måste lägga till dem manuellt.
Blobb-lagring
Azure Blob Storage är Microsofts objektlagringslösning för molnet. Blob Storage är optimerad för lagring av enorma mängder ostrukturerade data. Ostrukturerade data är data som inte följer en viss datamodell eller definition, till exempel text eller binära data.
Du kan använda Azure Blobs som strömmande eller referensindata. Strömmande blobar kontrolleras varje sekund efter uppdateringar. Till skillnad från en direktuppspelningsblob läses en referensblob bara in i början av uppdateringen. Det är statiska data som inte förväntas ändras och den rekommenderade gränsen för statiska data är 50 MB eller mindre.
Power BI förväntar sig att referensblobar används tillsammans med strömmande källor, till exempel via en JOIN. Därför måste ett strömmande dataflöde med en referensblob också ha en strömmande källa.
Konfigurationen för Azure Blobs skiljer sig något från konfigurationen för en Azure Event Hubs-nod. Information om hur du hittar din Azure Blob-anslutningssträng finns i Visa kontoåtkomstnycklar.
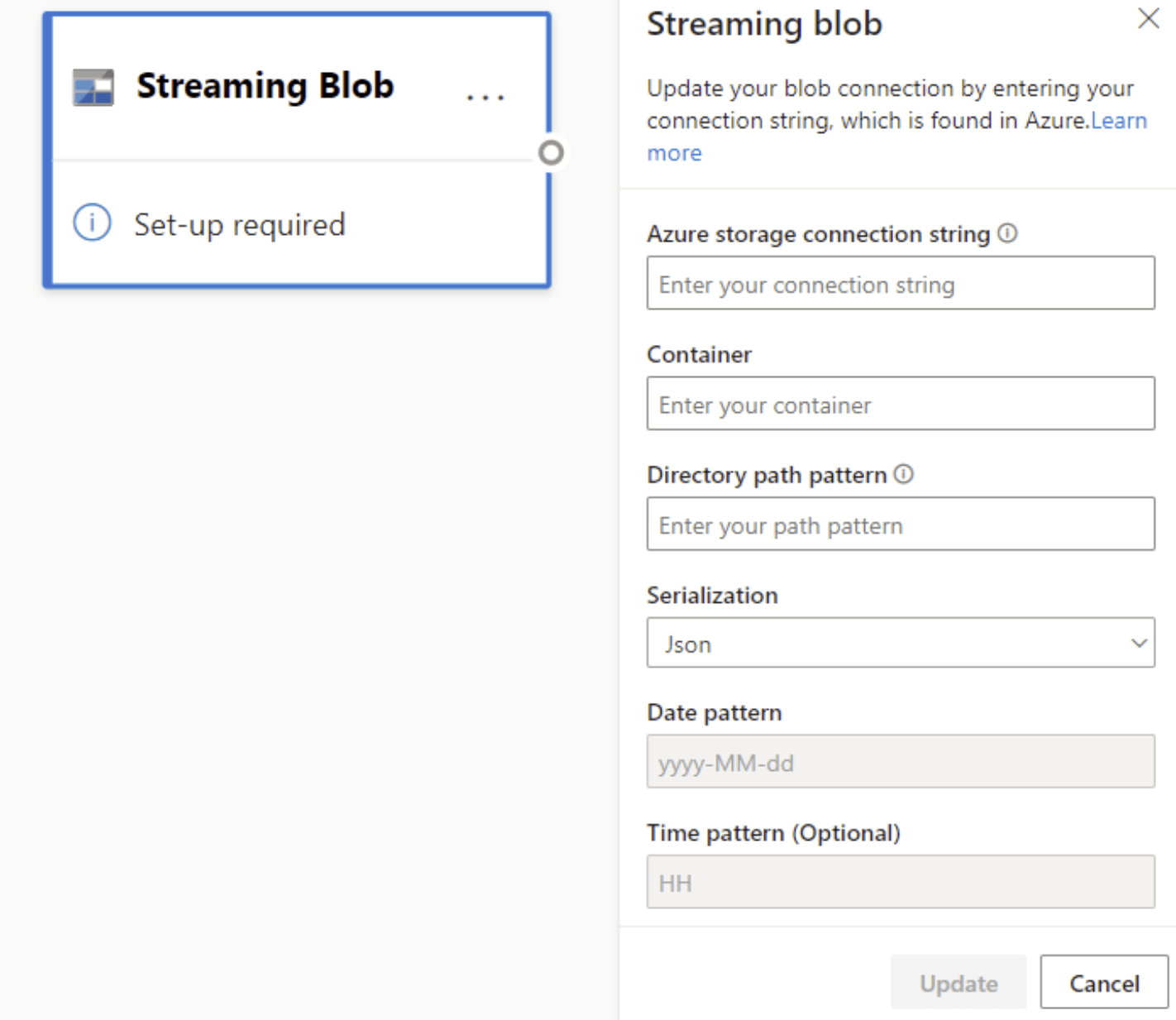
När du har angett Blob anslutningssträng måste du ange namnet på containern. Du måste också ange sökvägsmönstret i katalogen för att få åtkomst till de filer som du vill ange som källa för ditt dataflöde.
För strömmande blobar förväntas katalogsökvägsmönstret vara ett dynamiskt värde. Datumet måste vara en del av filsökvägen för blobben – som refereras till som {date}. Dessutom stöds inte en asterisk (*) i sökvägsmönstret, till exempel {date}/{time}/*.json.
Om du till exempel har en blob med namnet ExampleContainer som du lagrar kapslade .json filer inuti, där den första nivån är datumet då den skapades och den andra nivån är timmen då den skapades (åååå-mm-dd/hh), skulle containerindata vara "ExampleContainer". Sökvägsmönstret för katalog är {date}/{time}, där du kan ändra datum- och tidsmönstret.

När bloben är ansluten till slutpunkten är alla funktioner för att välja, lägga till, automatiskt identifiera och redigera fält som kommer in från Azure Blob samma som i Event Hubs. Du kan också redigera autentiseringsuppgifterna genom att välja kugghjulsikonen.
När du arbetar med realtidsdata komprimeras ofta data och identifierare används för att representera objektet. Ett möjligt användningsfall för blobar kan också vara som referensdata för dina strömmande källor. Med referensdata kan du koppla statiska data till strömmande data för att utöka dina strömmar för analys. Ett snabbt exempel på när den här funktionen skulle vara till hjälp är om du installerar sensorer i olika varuhus för att mäta hur många personer som kommer in i butiken vid en viss tidpunkt. Vanligtvis måste sensor-ID:t kopplas till en statisk tabell för att ange vilket varuhus och vilken plats sensorn finns på. Nu med referensdata är det möjligt att ansluta dessa data under inmatningsfasen för att göra det enkelt att se vilket arkiv som har högst utdata från användare.
Kommentar
Ett strömmande dataflödesjobb hämtar data från Azure Blob Storage eller ADLS Gen2-indata varje sekund om blobfilen är tillgänglig. Om blobfilen inte är tillgänglig finns det en exponentiell backoff med en maximal tidsfördröjning på 90 sekunder.
Datatyper
De tillgängliga datatyperna för fält för strömmande dataflöden är:
- DateTime: Datum- och tidsfält i ISO-format
- Flyttal: Decimaltal
- Int: Heltalsnummer
- Post: Kapslat objekt med flera poster
- Sträng: Text
Viktigt!
De datatyper som valts för strömmande indata har viktiga konsekvenser nedströms för ditt strömmande dataflöde. Välj datatypen så tidigt som möjligt i dataflödet för att undvika att behöva stoppa den senare för redigeringar.
Lägga till en transformering av strömmande data
Transformering av strömmande data skiljer sig i sig från batchdatatransformeringar. Nästan alla strömmande data har en tidskomponent som påverkar alla uppgifter för förberedelse av data.
Om du vill lägga till en transformering av strömmande data i ditt dataflöde väljer du transformeringsikonen i menyfliksområdet för omvandlingen. Respektive kort visas i diagramvyn. När du har valt den visas sidofönstret för omvandlingen för att konfigurera den.
Från och med juli 2021 stöder strömmande dataflöden följande strömningsomvandlingar.
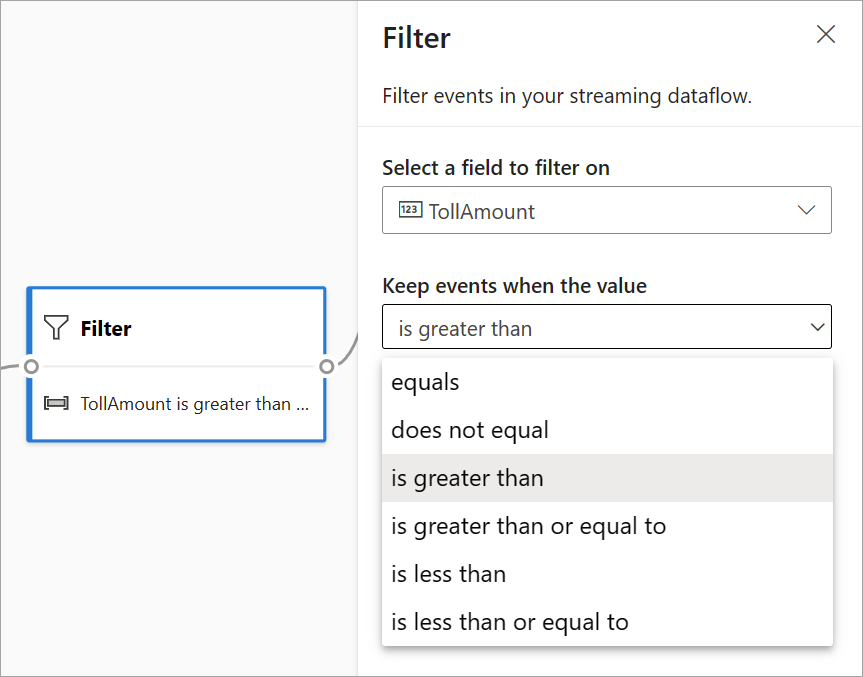
Filtrera
Använd filtertransformeringen för att filtrera händelser baserat på värdet för ett fält i indata. Beroende på datatypen (tal eller text) behåller omvandlingen de värden som matchar det valda villkoret.
Kommentar
I varje kort ser du information om vad mer som krävs för att omvandlingen ska vara klar. När du till exempel lägger till ett nytt kort visas meddelandet "Konfigurera krävs". Om du saknar en nodanslutning visas antingen ett felmeddelande eller ett varningsmeddelande.
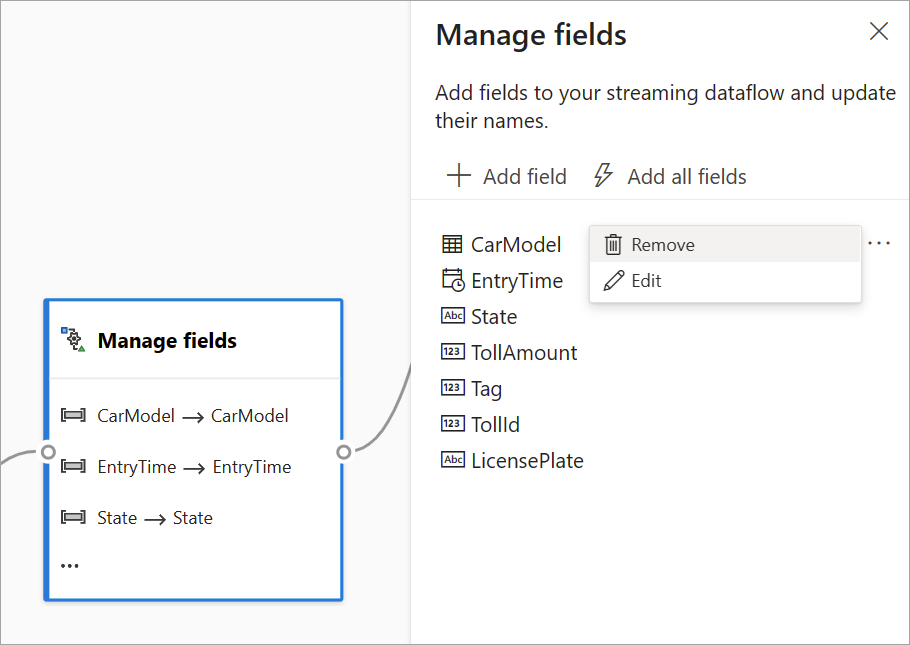
Hantera fält
Med transformering av hantera fält kan du lägga till, ta bort eller byta namn på fält som kommer in från en indata eller en annan transformering. Inställningarna i sidofönstret ger dig möjlighet att lägga till ett nytt genom att välja Lägg till fält eller lägga till alla fält samtidigt.
Dricks
När du har konfigurerat ett kort får du en glimt av inställningarna i själva kortet i diagramvyn. I området Hantera fält i föregående bild kan du till exempel se de tre första fälten som hanteras och de nya namnen som tilldelats dem. Varje kort har information som är relevant för det.
Aggregera
Du kan använda aggregeringstransformationen för att beräkna en aggregering (Summa, Minimum, Maximum eller Average) varje gång en ny händelse inträffar under en tidsperiod. Med den här åtgärden kan du också filtrera eller segmentera aggregeringen baserat på andra dimensioner i dina data. Du kan ha en eller flera sammansättningar i samma transformering.
Om du vill lägga till en aggregering väljer du transformeringsikonen. Anslut sedan indata, välj aggregering, lägg till filter- eller segmentdimensioner och välj tidsperioden när du vill beräkna aggregeringen. I det här exemplet beräknas summan av det avgiftsbelagda värdet efter det tillstånd där fordonet kommer från under de senaste 10 sekunderna.
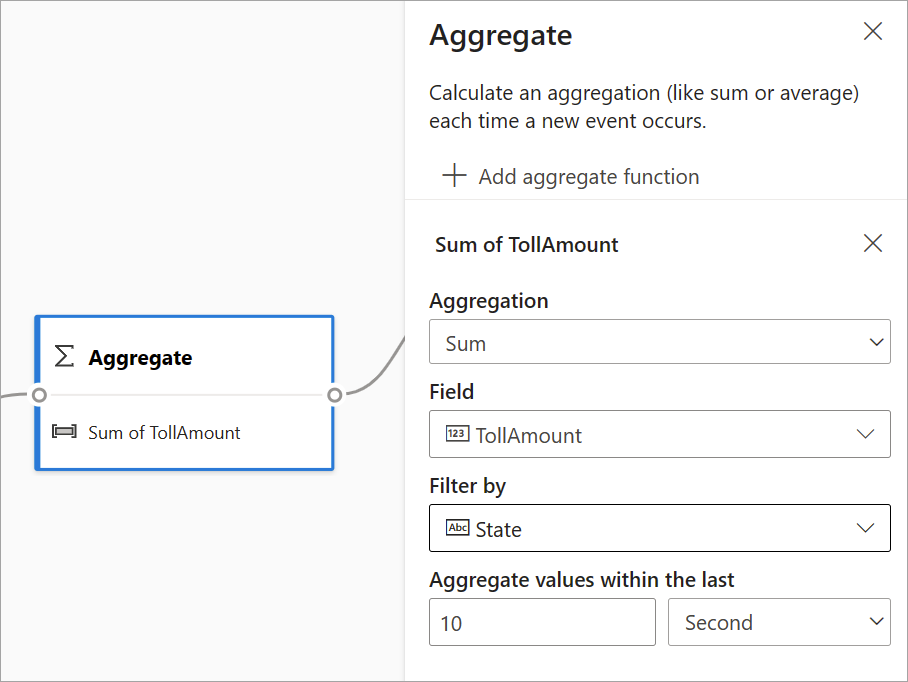
Om du vill lägga till ytterligare en aggregering i samma transformering väljer du Lägg till mängdfunktion. Tänk på att filtret eller sektorn gäller för alla aggregeringar i omvandlingen.
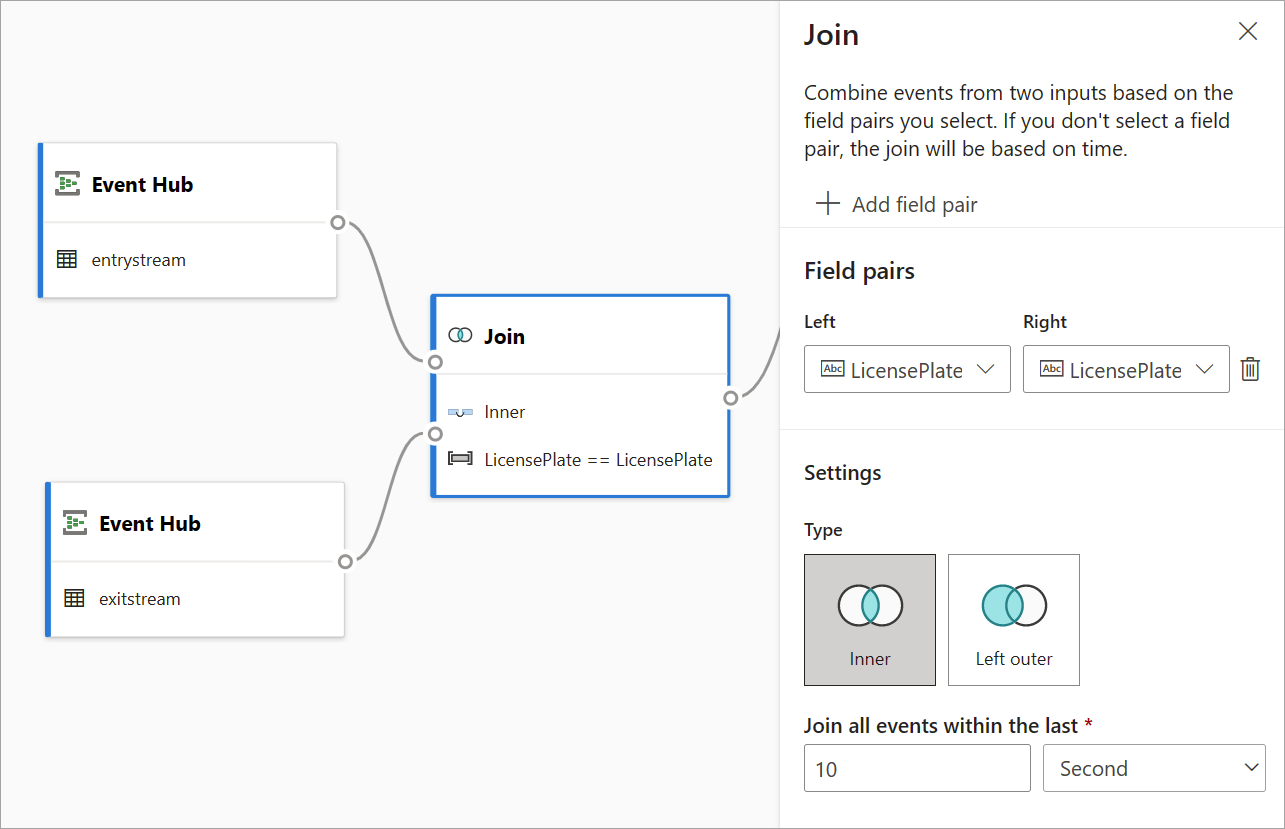
Anslut
Använd kopplingstransformeringen för att kombinera händelser från två indata baserat på de fältpar som du väljer. Om du inte väljer ett fältpar baseras kopplingen som standard på tid. Standardvärdet är det som gör att den här omvandlingen skiljer sig från en batch.
Precis som med vanliga kopplingar har du olika alternativ för din kopplingslogik:
- Inre koppling: Inkludera endast poster från båda tabellerna där paret matchar. I det här exemplet matchar registreringsskylten båda indata.
- Vänster yttre koppling: Inkludera alla poster från den vänstra (första) tabellen och endast posterna från den andra som matchar fältparet. Om det inte finns någon matchning anges fälten från den andra indatan tomma.
Välj typ av koppling genom att välja ikonen för önskad typ i sidofönstret.
Välj slutligen under vilken tidsperiod du vill att kopplingen ska beräknas. I det här exemplet tittar kopplingen på de senaste 10 sekunderna. Tänk på att ju längre perioden är, desto mindre frekvent är utdata – och ju fler bearbetningsresurser du använder för omvandlingen.
Som standard inkluderas alla fält från båda tabellerna. Prefix vänster (första noden) och höger (andra noden) i utdata hjälper dig att särskilja källan.
Gruppera efter
Använd gruppen efter transformering för att beräkna aggregeringar för alla händelser inom ett visst tidsfönster. Du kan gruppera efter värden i ett eller flera fält. Den liknar den aggregerade omvandlingen men innehåller fler alternativ för aggregeringar. Den innehåller också mer komplexa tidsfönsteralternativ. Du kan också lägga till mer än en aggregering per transformering.
De aggregeringar som är tillgängliga i den här omvandlingen är: Average, Count, Maximum, Minimum, Percentile (kontinuerlig och diskret), Standardavvikelse, Summa och Varians.
Så här konfigurerar du den här omvandlingen:
- Välj önskad sammansättning.
- Välj det fält som du vill aggregera på.
- Välj ett valfritt grupp-efter-fält om du vill hämta aggregeringsberäkningen över en annan dimension eller kategori (till exempel Tillstånd).
- Välj din funktion för tidsfönster.
Om du vill lägga till ytterligare en aggregering i samma transformering väljer du Lägg till mängdfunktion. Tänk på att fältet Gruppera efter och fönsterfunktionen gäller för alla sammansättningar i omvandlingen.
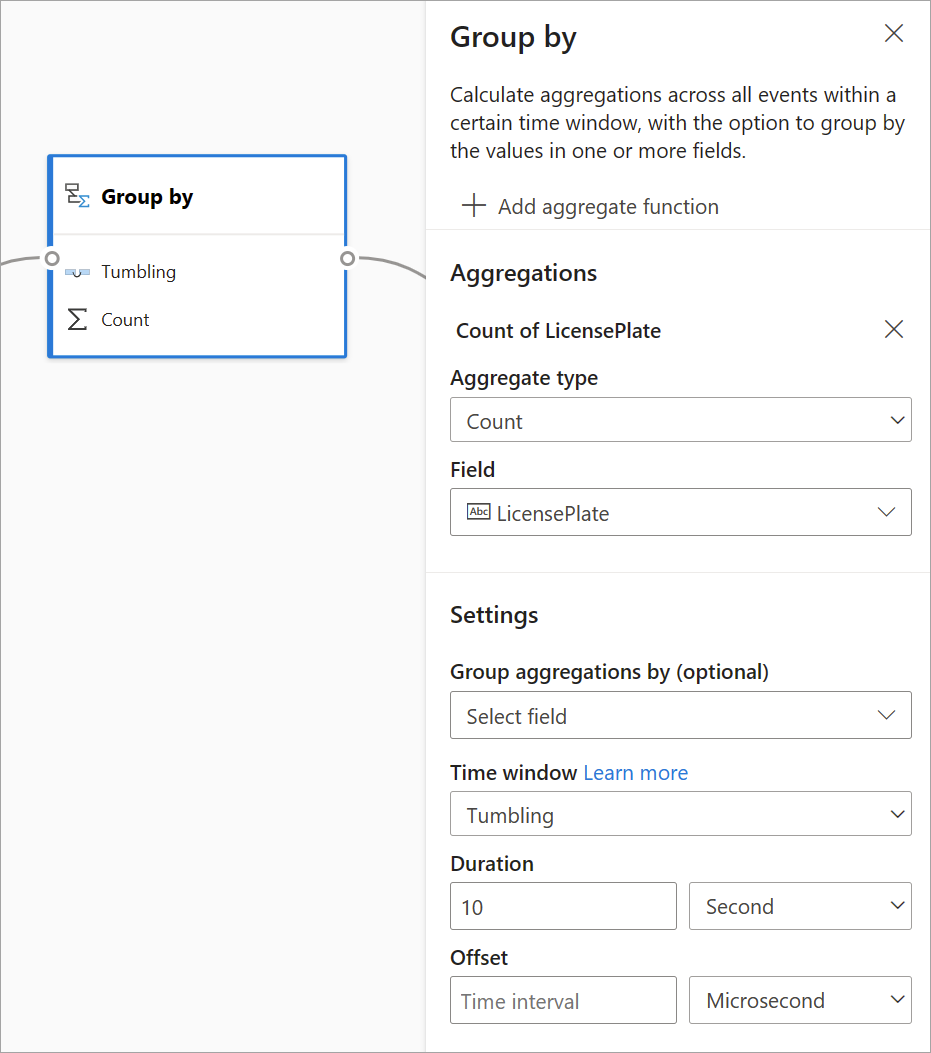
En tidsstämpel för slutet av tidsfönstret tillhandahålls som en del av transformeringsutdata som referens.
I ett avsnitt senare i den här artikeln beskrivs varje typ av tidsfönster som är tillgängligt för den här omvandlingen.
Union
Använd Unionstransformeringen för att ansluta två eller flera indata för att lägga till händelser med delade fält (med samma namn och datatyp) i en tabell. Fält som inte matchar tas bort och ingår inte i utdata.
Konfigurera tidsfönsterfunktioner
Tidsfönster är ett av de mest komplexa begreppen inom strömmande data. Det här konceptet är kärnan i strömningsanalys.
Med strömmande dataflöden kan du konfigurera tidsfönster när du aggregerar data som ett alternativ för gruppen efter transformering.
Kommentar
Tänk på att alla utdataresultat för fönsteråtgärder beräknas i slutet av tidsfönstret. Utdata från fönstret är en enskild händelse som baseras på aggregeringsfunktionen. Den här händelsen har tidsstämpeln för slutet av fönstret och alla fönsterfunktioner definieras med en fast längd.
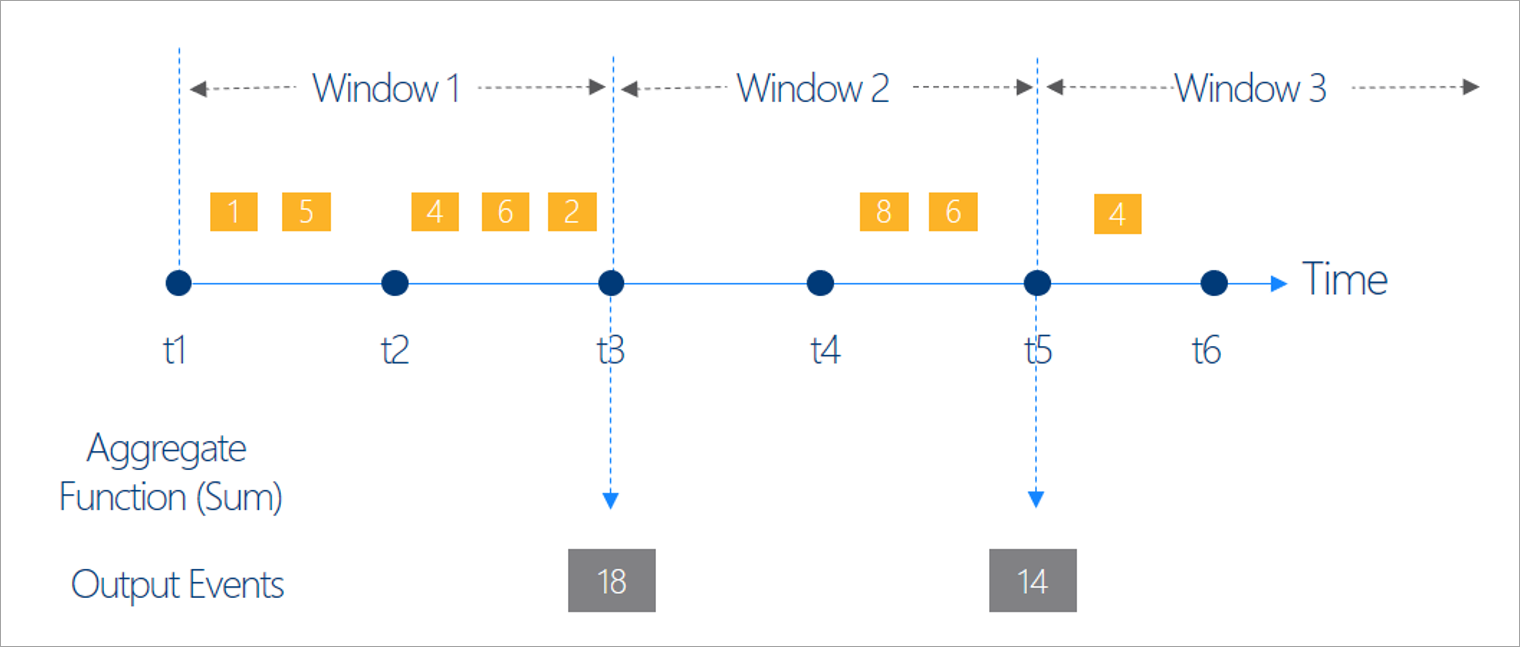
Det finns fem typer av tidsfönster att välja mellan: rullande, hoppande, glidande, session och ögonblicksbild.
Rullande fönster
Rullande är den vanligaste typen av tidsfönster. De viktigaste egenskaperna för rullande fönster är att de upprepas, har samma tidslängd och inte överlappar varandra. En händelse kan inte tillhöra fler än ett rullande fönster.
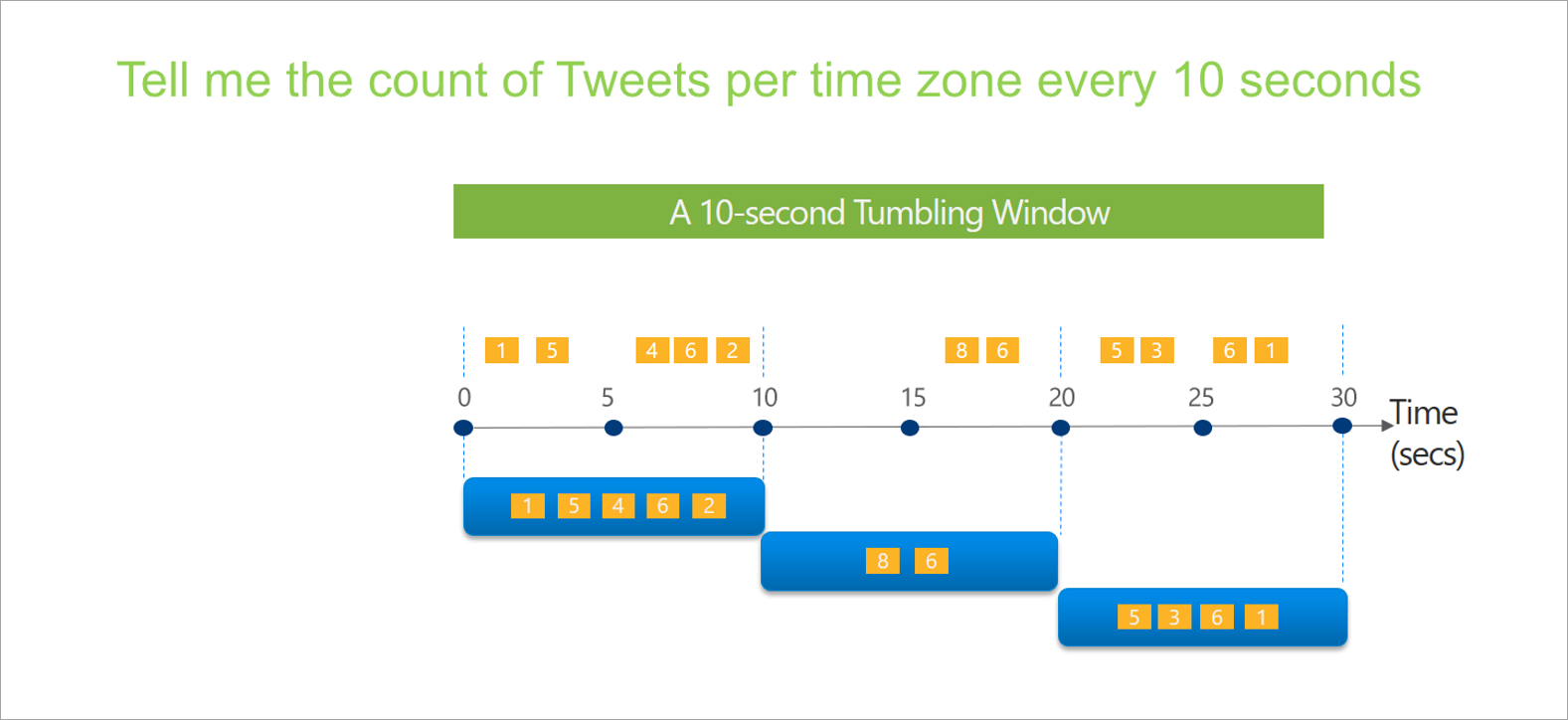
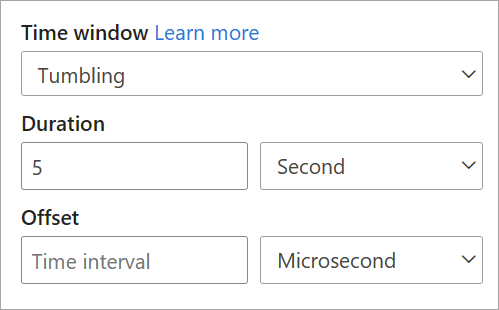
När du konfigurerar ett rullande fönster i strömmande dataflöden måste du ange varaktigheten för fönstret (samma för alla fönster i det här fallet). Du kan också ange en valfri förskjutning. Som standard innehåller rullande fönster slutet av fönstret och exkluderar början. Du kan använda den här parametern för att ändra det här beteendet och inkludera händelserna i början av fönstret och exkludera dem i slutet.
Hoppande fönster
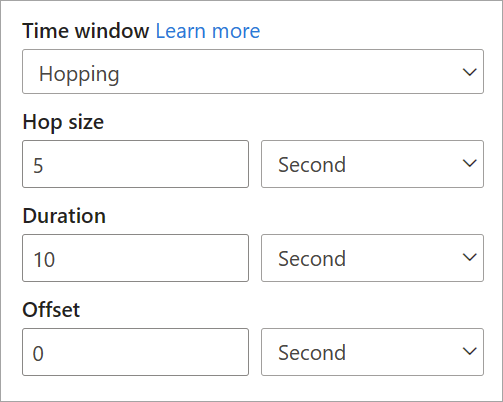
Hoppar windows "hop" framåt i tid med en fast period. Du kan se dem som rullande fönster som kan överlappa och genereras oftare än fönsterstorleken. Händelser kan tillhöra mer än en resultatuppsättning för ett hoppfönster. Om du vill göra ett hoppfönster till samma som ett rullande fönster kan du ange att hoppstorleken ska vara samma som fönsterstorleken.
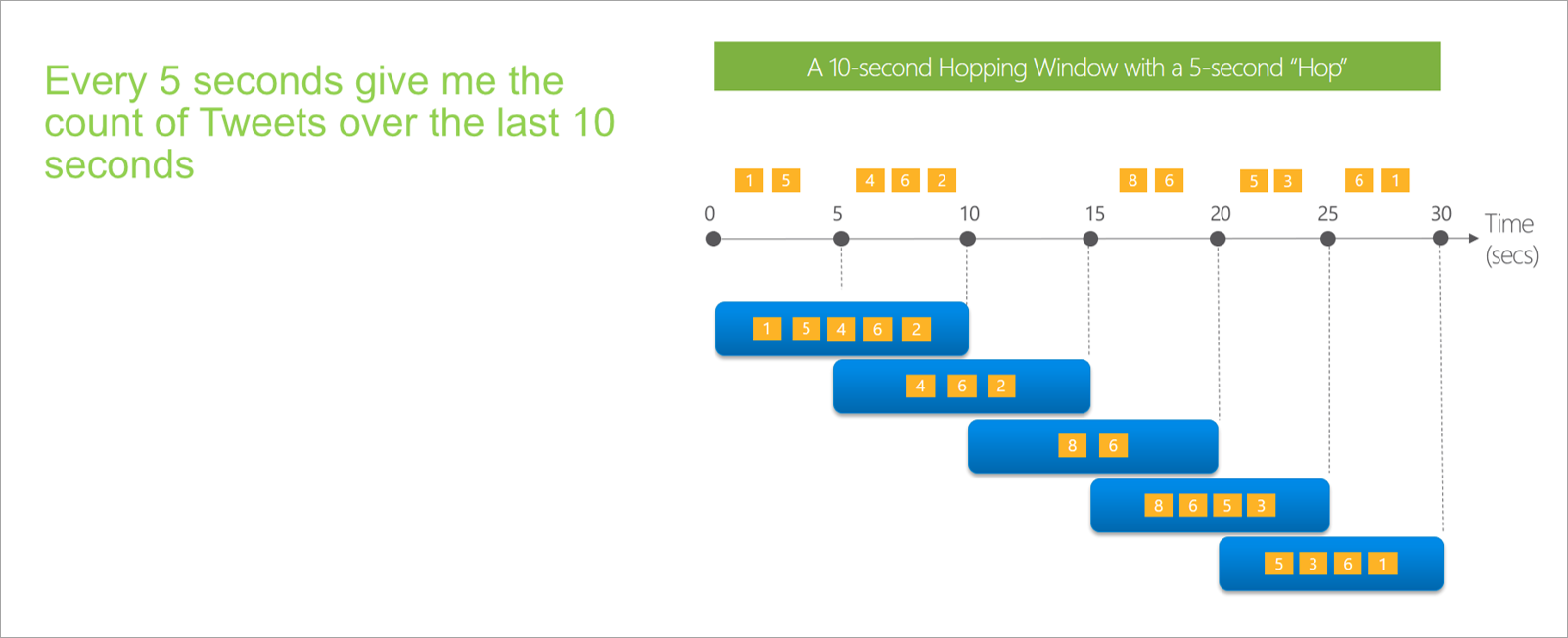
När du konfigurerar ett hoppfönster i strömmande dataflöden måste du ange varaktigheten för fönstret (samma som med rullande fönster). Du måste också ange hoppstorleken, vilket talar om för strömmande dataflöden hur ofta du vill att aggregeringen ska beräknas för den definierade varaktigheten.
Förskjutningsparametern är också tillgänglig i hoppande fönster av samma anledning som i rullande fönster. Den definierar logiken för att inkludera och exkludera händelser för början och slutet av hoppningsfönstret.
Skjutfönster
Skjutfönster, till skillnad från rullande eller hoppande fönster, beräknar aggregeringen endast för tidpunkter då innehållet i fönstret faktiskt ändras. När en händelse kommer in i eller avslutar fönstret beräknas aggregeringen. Så varje fönster har minst en händelse. På samma sätt som hoppande fönster kan händelser tillhöra mer än ett skjutfönster.
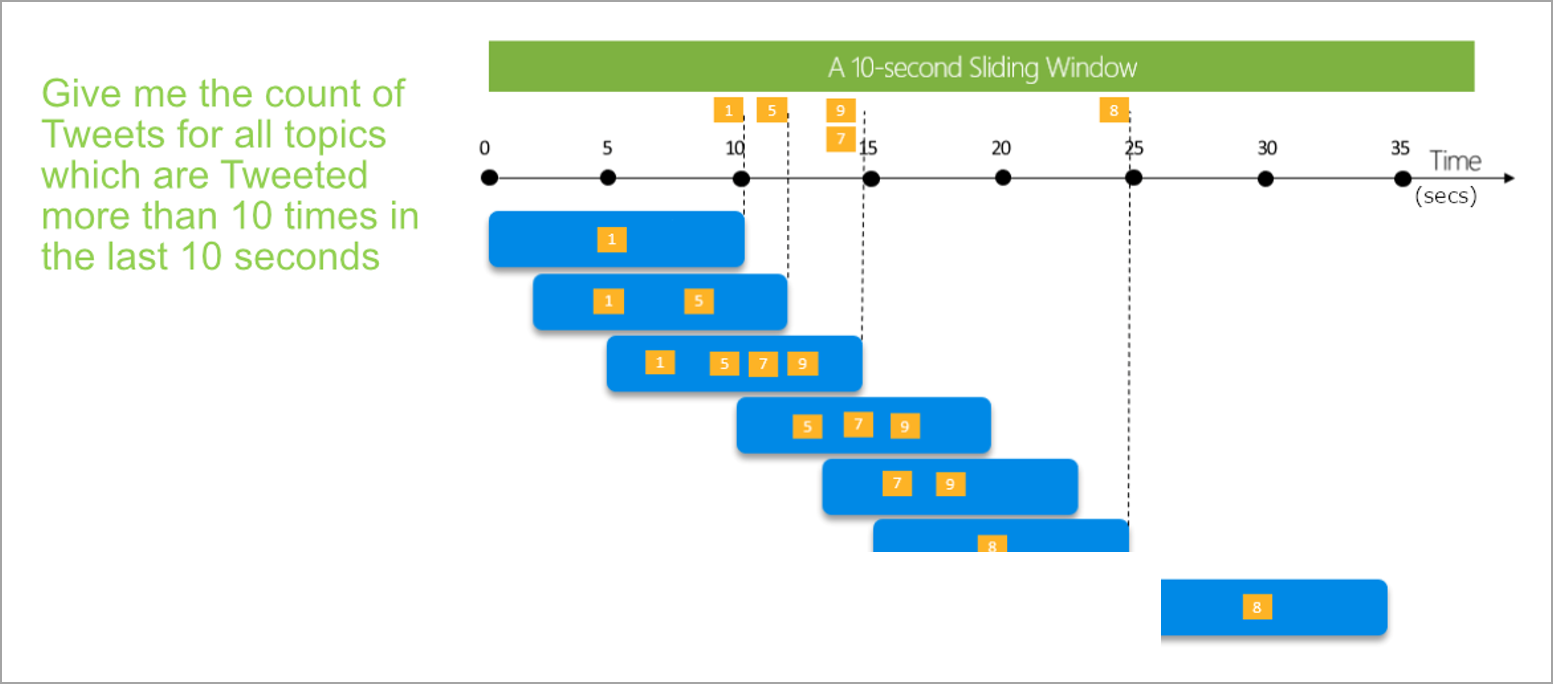
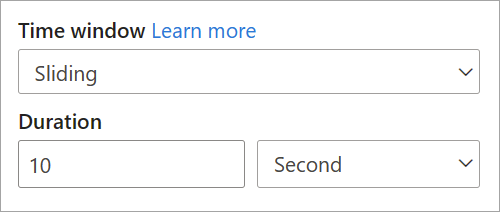
Den enda parameter som du behöver för ett skjutfönster är varaktigheten, eftersom själva händelserna definierar när fönstret startar. Ingen förskjutningslogik krävs.
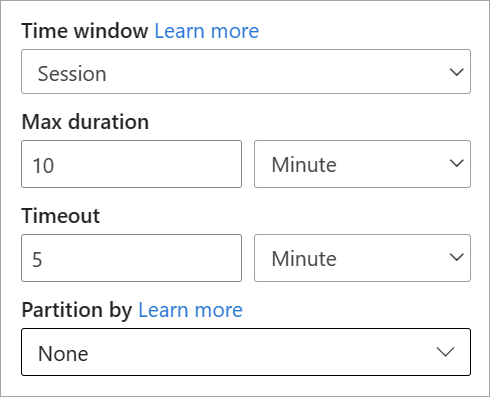
Sessionsfönster
Sessionsfönster är den mest komplexa typen. De grupperar händelser som kommer vid liknande tidpunkter och filtrerar bort tidsperioder där det inte finns några data. För det här fönstret är det nödvändigt att ange:
- En timeout: hur lång tid det tar att vänta om det inte finns några nya data.
- En maximal varaktighet: den längsta tid som aggregeringen beräknar om data fortsätter att komma.
Du kan också definiera en partition om du vill.
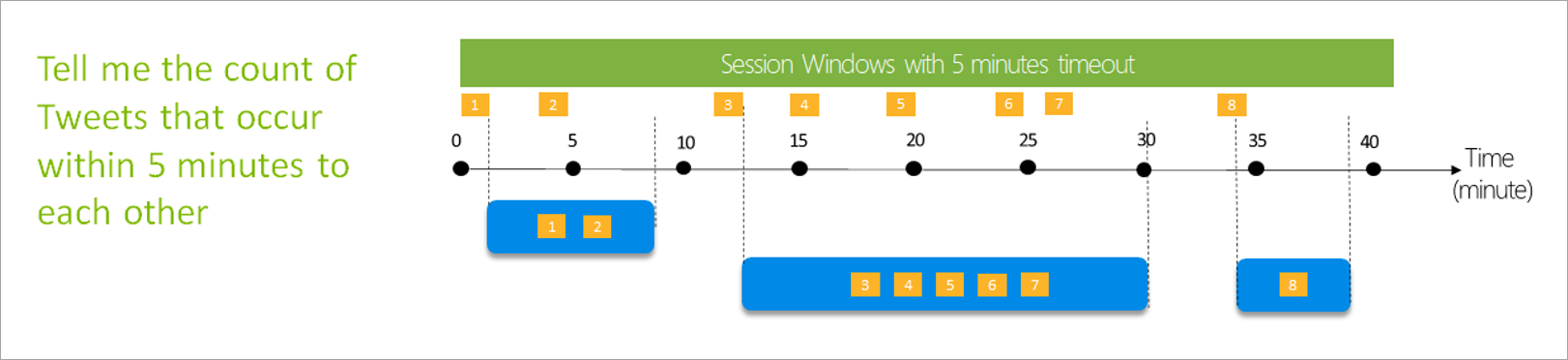
Du konfigurerar ett sessionsfönster direkt i sidofönstret för omvandlingen. Om du anger en partition grupperar aggregeringen bara händelser tillsammans för samma nyckel.
Fönstret Ögonblicksbild
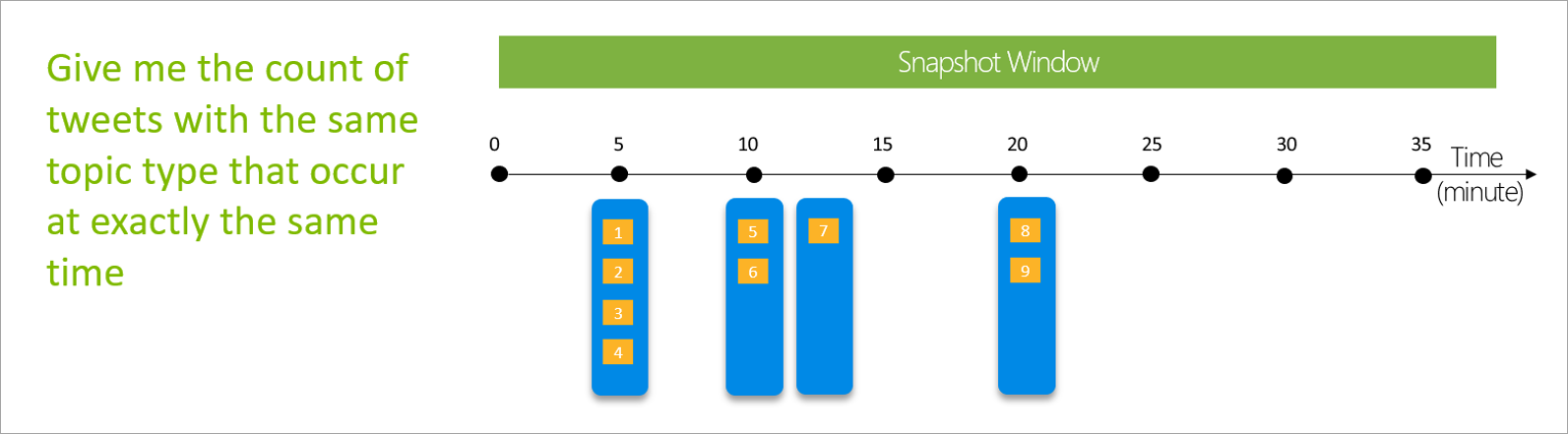
Ögonblicksbild av windows-grupphändelser som har samma tidsstämpel. Till skillnad från andra fönster kräver en ögonblicksbild inga parametrar eftersom den använder tiden från systemet.
Definiera utmatningar
När du har konfigurerat indata och transformeringar är det dags att definiera en eller flera utdata. Från och med juli 2021 stöder strömmande dataflöden Power BI-tabeller som den enda typen av utdata.
Det här utdata är en dataflödestabell (dvs. en entitet) som du kan använda för att skapa rapporter i Power BI Desktop. Du måste ansluta noderna i föregående steg med de utdata som du skapar för att det ska fungera. Därefter namnger du tabellen.
När du har anslutit till dataflödet blir den här tabellen tillgänglig för dig att skapa visuella objekt som uppdateras i realtid för dina rapporter.
Förhandsgranskning av data och fel
Strömmande dataflöden innehåller verktyg som hjälper dig att skapa, felsöka och utvärdera prestanda för din analyspipeline för strömmande data.
Förhandsversion av livedata för indata
När du ansluter till en händelsehubb eller IoT-hubb och väljer dess kort i diagramvyn ( fliken Dataförhandsgranskning ) får du en liveförhandsgranskning av data som kommer in om allt följande är sant:
- Data push-överförs.
- Indata är korrekt konfigurerade.
- Fält har lagts till.
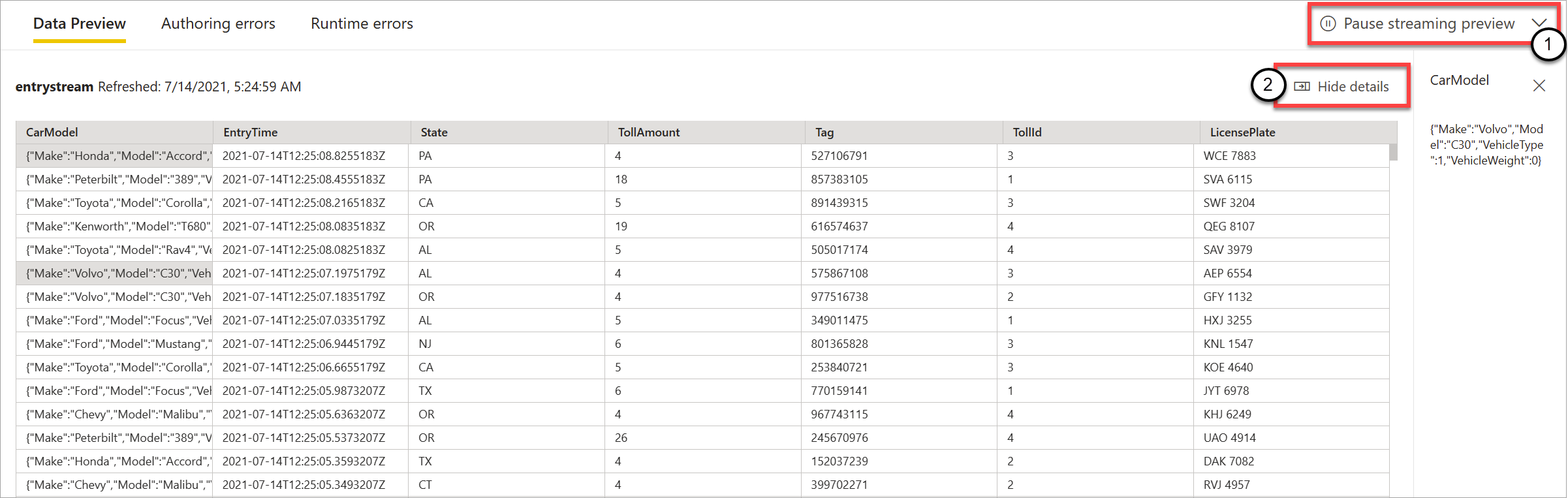
Som du ser i följande skärmbild kan du pausa förhandsgranskningen (1) om du vill se eller öka detaljnivån i något specifikt. Eller så kan du starta den igen om du är klar.
Du kan också se information om en specifik post (en "cell" i tabellen) genom att välja den och sedan välja Visa information eller Dölj information (2). Skärmbilden visar den detaljerade vyn av ett kapslat objekt i en post.
Statisk förhandsgranskning för omvandlingar och utdata
När du har lagt till och konfigurerat några steg i diagramvyn kan du testa deras beteende genom att välja knappen statiska data.

När du har det utvärderar strömmande dataflöden alla omvandlingar och utdata som är korrekt konfigurerade. Strömmande dataflöden visar sedan resultatet i förhandsversionen av statiska data, enligt följande bild.
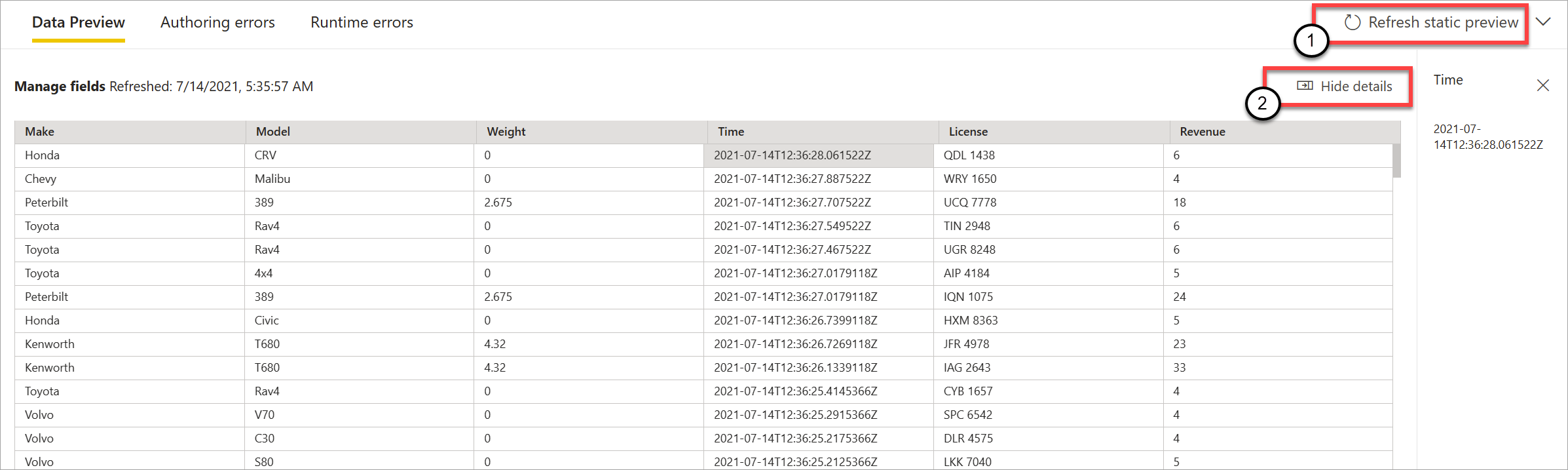
Du kan uppdatera förhandsversionen genom att välja Uppdatera statisk förhandsversion (1). När du gör detta tar strömmande dataflöden nya data från indata och utvärderar alla transformeringar och utdata igen med eventuella uppdateringar som du kan utföra. Alternativet Visa eller dölj information är också tillgängligt (2).
Redigeringsfel
Om du har några redigeringsfel eller varningar visar fliken Redigeringsfel (1) dem, enligt följande skärmbild. Listan innehåller information om felet eller varningen, typ av kort (indata, transformering eller utdata), felnivån och en beskrivning av felet eller varningen (2). När du väljer något av felen eller varningarna väljs respektive kort och fönstret på konfigurationssidan öppnas så att du kan göra de ändringar som behövs.

Körningsfel
Den senaste tillgängliga fliken i förhandsversionen är Runtime-fel (1), som du ser i följande skärmbild. På den här fliken visas eventuella fel i processen för att mata in och analysera strömmande dataflöde när du har startat det. Du kan till exempel få ett körningsfel om ett meddelande har skadats och dataflödet inte kunde mata in det och utföra de definierade omvandlingarna.
Eftersom dataflöden kan köras under en längre tid erbjuder den här fliken möjlighet att filtrera efter tidsperiod och ladda ned listan över fel och uppdatera den om det behövs (2).

Ändra inställningar för strömmande dataflöden
Precis som med vanliga dataflöden kan inställningar för strömmande dataflöden ändras beroende på ägares och författares behov. Följande inställningar är unika för strömmande dataflöden. För resten av inställningarna, på grund av den delade infrastrukturen mellan de två typerna av dataflöden, kan du anta att användningen är densamma.
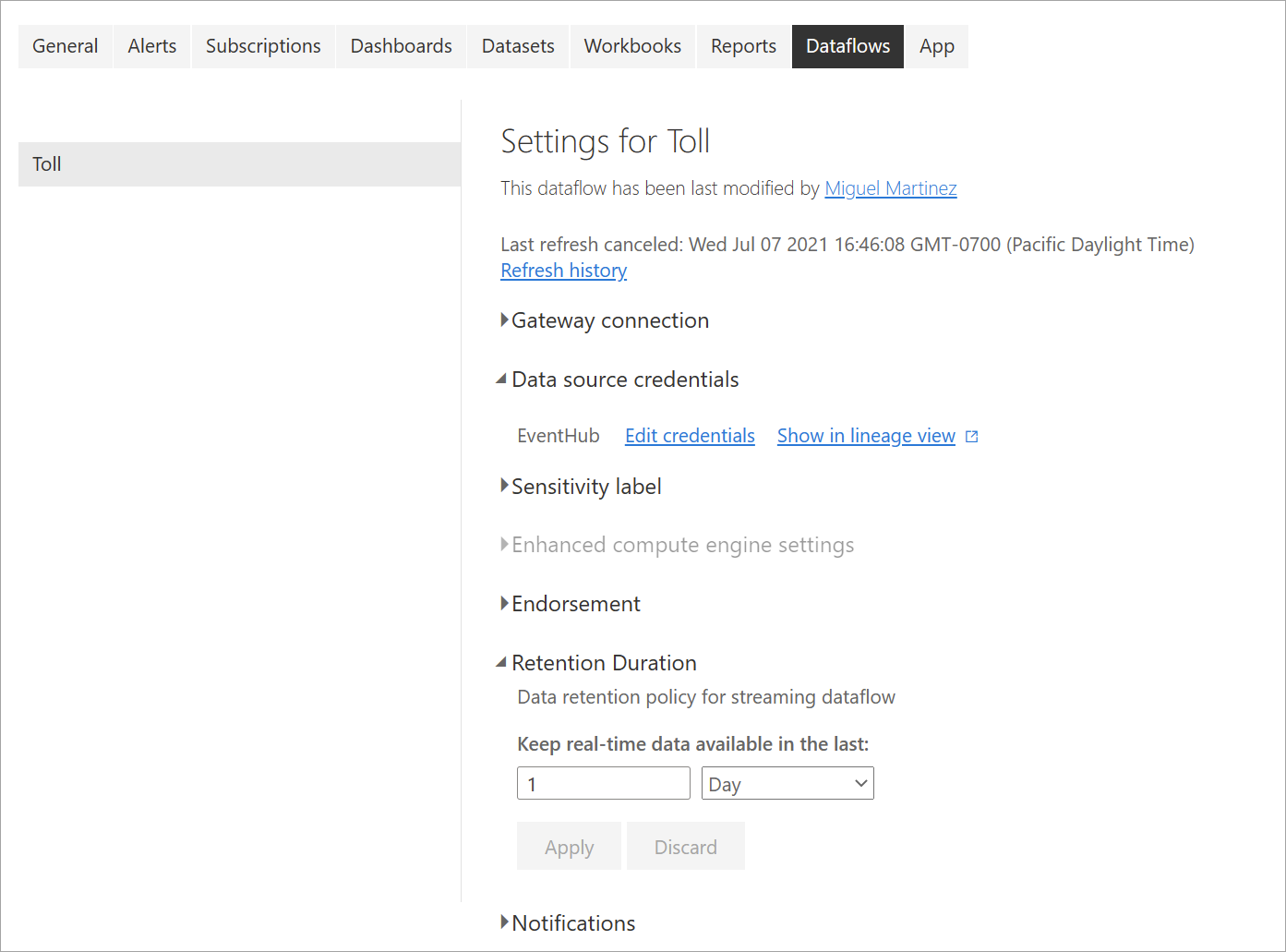
Uppdateringshistorik: Eftersom strömmande dataflöden körs kontinuerligt visar uppdateringshistoriken endast information om när dataflödet startar, när det avbryts eller när det misslyckas (med information och felkoder när det är tillämpligt). Den här informationen liknar vad som visas för vanliga dataflöden. Du kan använda den här informationen för att felsöka problem eller för att tillhandahålla Power BI-support med begärd information.
Autentiseringsuppgifter för datakälla: Den här inställningen visar de indata som har konfigurerats för det specifika strömmande dataflödet.
Förbättrade inställningar för beräkningsmotorn: Strömmande dataflöden behöver den förbättrade beräkningsmotorn för att tillhandahålla visuella objekt i realtid, så den här inställningen är aktiverad som standard och kan inte ändras.
Varaktighet för kvarhållning: Den här inställningen är specifik för strömmande dataflöden. Här kan du definiera hur länge du vill behålla realtidsdata för att visualisera i rapporter. Historiska data sparas som standard i Azure Blob Storage. Den här inställningen är specifik för realtidssidan av dina data (frekvent lagring). Minimivärdet är 1 dag eller 24 timmar.
Viktigt!
Mängden frekventa data som lagras med den här kvarhållningstiden påverkar direkt prestandan för visuella objekt i realtid när du skapar rapporter ovanpå dessa data. Ju mer kvarhållning du har här, desto fler visuella objekt i realtid i rapporter kan påverkas av låga prestanda. Om du behöver utföra historisk analys bör du använda den kalla lagring som tillhandahålls för strömmande dataflöden.
Köra och redigera ett strömmande dataflöde
När du har sparat och konfigurerat ditt strömmande dataflöde är allt klart för dig att köra det. Du kan sedan börja mata in data i Power BI med den logik för strömningsanalys som du har definierat.
Kör ditt strömmande dataflöde
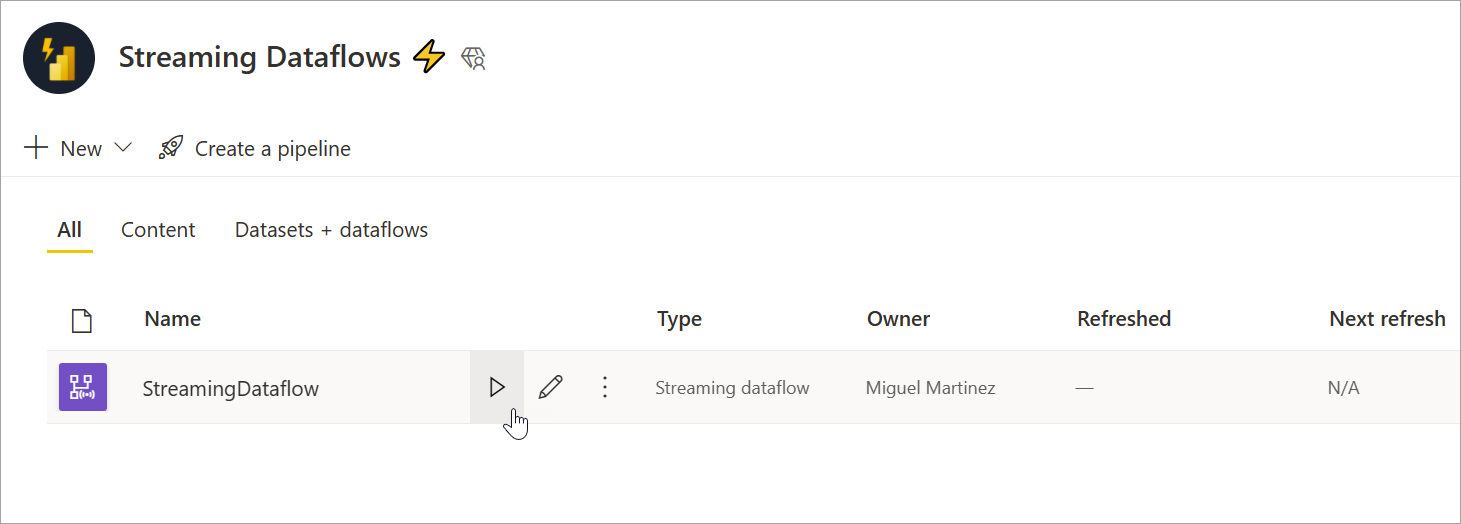
Om du vill starta ditt strömmande dataflöde sparar du först dataflödet och går till arbetsytan där du skapade det. Hovra över strömmande dataflöde och välj uppspelningsknappen som visas. Ett popup-meddelande visar att det strömmande dataflödet startas.
Kommentar
Det kan ta upp till fem minuter innan data börjar matas in och du kan se data som kommer in för att skapa rapporter och instrumentpaneler i Power BI Desktop.
Redigera ditt strömmande dataflöde
När ett strömmande dataflöde körs kan det inte redigeras. Men du kan gå in i ett strömmande dataflöde som körs och se analyslogik som dataflödet bygger på.
När du går in i ett strömmande dataflöde inaktiveras alla redigeringsalternativ och ett meddelande visas: "Dataflödet kan inte redigeras när det körs. Stoppa dataflödet om du vill fortsätta." Dataförhandsgranskningen är också inaktiverad.
Om du vill redigera ditt strömmande dataflöde måste du stoppa det. Ett stoppat dataflöde resulterar i att data saknas.
Den enda tillgängliga upplevelsen när ett strömmande dataflöde körs är fliken Körningsfel , där du kan övervaka dataflödets beteende för eventuella borttagna meddelanden och liknande situationer.

Överväg datalagring när du redigerar ditt dataflöde
När du redigerar ett dataflöde måste du ta hänsyn till andra överväganden. Om du gör ändringar i en utdatatabell kan du förlora data som redan har push-överförts och sparats i Power BI om du gör ändringar i en utdatatabell. Gränssnittet innehåller tydlig information om konsekvenserna av någon av dessa ändringar i ditt strömmande dataflöde, tillsammans med val för ändringar som du gör innan du sparar.
Den här upplevelsen visas bättre med ett exempel. Följande skärmbild visar meddelandet du får när du lägger till en kolumn i en tabell, ändrar namnet på en andra tabell och lämnar en tredje tabell på samma sätt som tidigare.

I det här exemplet tas data som redan sparats i båda tabellerna med schema- och namnändringar bort om du sparar ändringarna. För tabellen som förblev densamma får du möjlighet att ta bort gamla data och börja från början, eller spara dem för senare analys tillsammans med nya data som kommer in.
Tänk på dessa nyanser när du redigerar ditt strömmande dataflöde, särskilt om du behöver historiska data som är tillgängliga senare för ytterligare analys.
Använda ett strömmande dataflöde
När ditt strömmande dataflöde har körts är du redo att börja skapa innehåll ovanpå dina strömmande data. Det finns inga strukturella ändringar jämfört med vad du måste göra för att skapa rapporter som uppdateras i realtid. Det finns vissa nyanser och uppdateringar att tänka på så att du kan dra nytta av den här nya typen av dataförberedelser för strömmande data.
Konfigurera datalagring
Som vi nämnde tidigare sparar strömmande dataflöden data på följande två platser. Användningen av dessa källor beror på vilken typ av analys du försöker göra.
- Frekvent lagring (realtidsanalys): När data kommer till Power BI från strömmande dataflöden lagras data på en frekvent plats där du kan komma åt dem med visuella realtidsobjekt. Hur mycket data som sparas i den här lagringen beror på det värde som du definierade under kvarhållningstiden i inställningarna för strömmande dataflöde. Standardvärdet (och minimum) är 24 timmar.
- Kall lagring (historisk analys): Alla tidsperioder som inte faller under den period som du definierade för kvarhållningsvaraktighet sparas i kall lagring (blobbar) i Power BI så att du kan använda om det behövs.
Kommentar
Det finns överlappningar mellan dessa två datalagringsplatser. Om du behöver använda båda platserna tillsammans (till exempel ändring per dag jämfört med dag) kan du behöva deduplicera dina poster. Det beror på de tidsinformationsberäkningar som du gör och kvarhållningsprincipen.
Ansluta till strömmande dataflöden från Power BI Desktop
Power BI Desktop erbjuder en anslutningsapp med namnet Dataflöden som du kan använda. Som en del av den här anslutningsappen för strömmande dataflöden ser du två tabeller som matchar datalagringen som beskrevs tidigare.
Så här ansluter du till dina data för strömmande dataflöden:
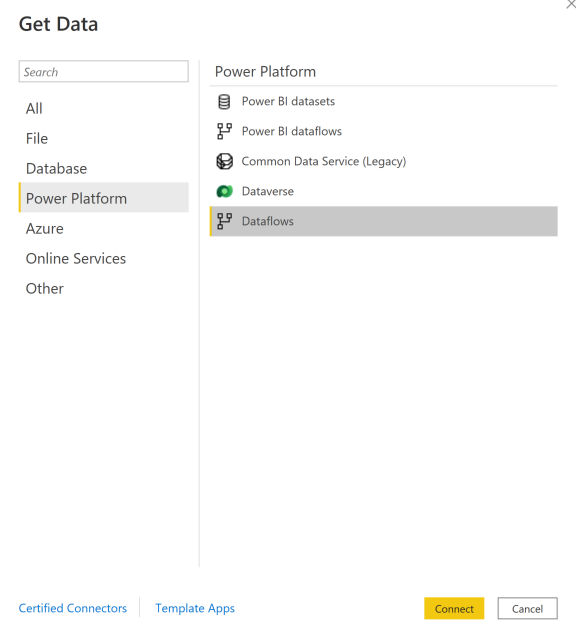
Gå till Hämta data, välj Power Platform och välj sedan anslutningsappen Dataflöden .
Logga in med dina Power BI-autentiseringsuppgifter.
Välj arbetsytor. Leta efter det som innehåller ditt strömmande dataflöde och välj det dataflödet. (I det här exemplet anropas strömmande dataflödeAvgiftsbelagt.)
Observera att alla utdatatabeller visas två gånger: en för strömmande data (frekvent) och en för arkiverade data (kall). Du kan särskilja dem efter de etiketter som har lagts till efter tabellnamnen och ikonerna.
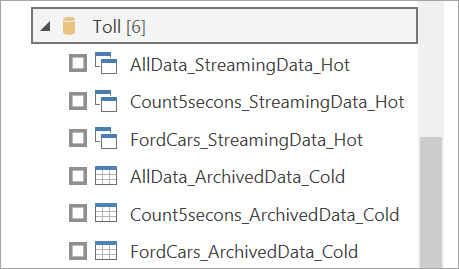
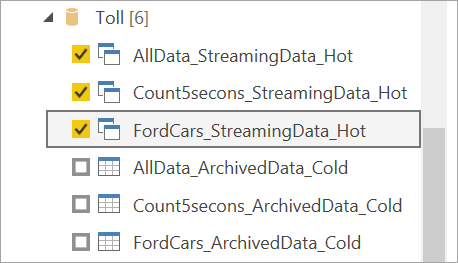
Anslut till strömmande data. Det arkiverade datafallet är detsamma, endast tillgängligt i importläge. Välj de tabeller som innehåller etiketterna Direktuppspelning och Frekvent och välj sedan Läs in.
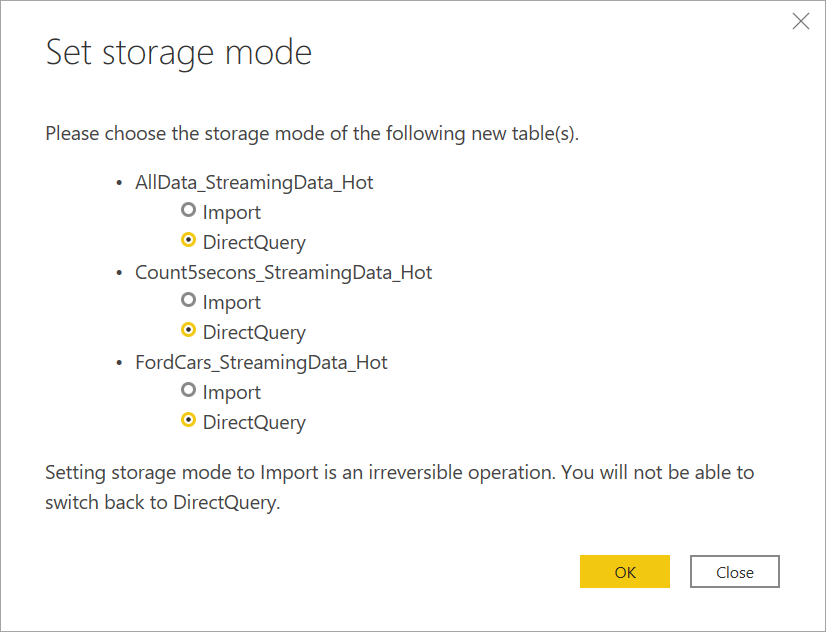
När du uppmanas att välja ett lagringsläge väljer du DirectQuery om målet är att skapa visuella objekt i realtid.
Nu kan du skapa visuella objekt, mått med mera med hjälp av de funktioner som är tillgängliga i Power BI Desktop.
Kommentar
Den vanliga Power BI-dataflödesanslutningen är fortfarande tillgänglig och fungerar med strömmande dataflöden med två varningar:
- Du kan bara ansluta till frekvent lagring.
- Dataförhandsgranskningen i anslutningsappen fungerar inte med strömmande dataflöden.
Aktivera automatisk siduppdatering för visuella objekt i realtid
När rapporten är klar och du har lagt till allt innehåll som du vill dela är det enda steget kvar att se till att dina visuella objekt uppdateras i realtid. Du kan använda en funktion som kallas automatisk siduppdatering. Med den här funktionen kan du uppdatera visuella objekt från en DirectQuery-källa så ofta som en sekund.
Mer information om funktionen finns i Automatisk siduppdatering i Power BI. Den artikeln innehåller information om hur du använder den, hur du konfigurerar den och hur du kontaktar administratören om du har problem. Följande är grunderna i hur du konfigurerar det:
Gå till rapportsidan där du vill att de visuella objekten ska uppdateras i realtid.
Rensa alla visuella objekt på sidan. Om möjligt väljer du sidans bakgrund.
Gå till formatfönstret (1) och aktivera Siduppdatering (2).
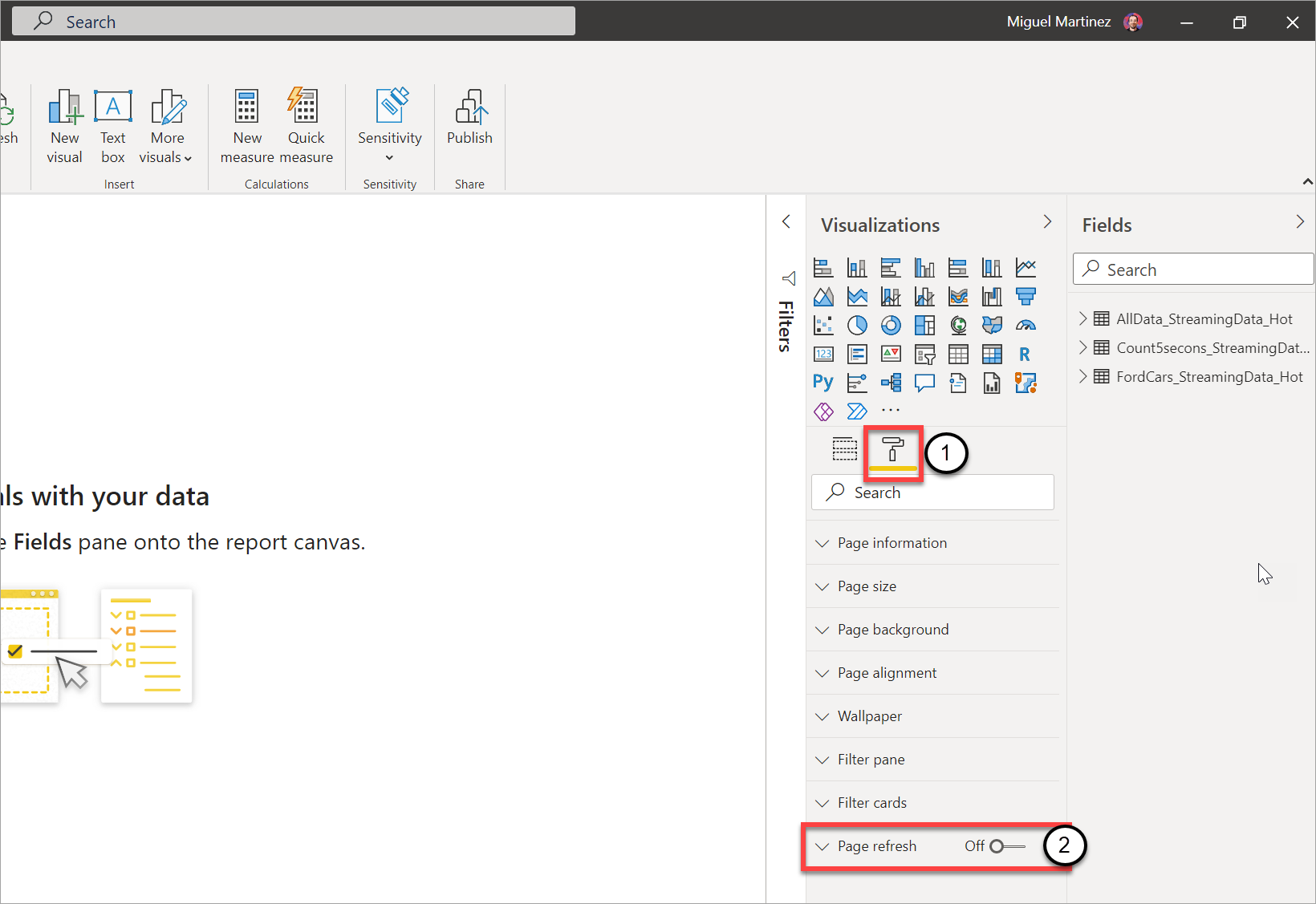
Konfigurera önskad frekvens (upp till varje sekund om administratören har tillåtit det).
Om du vill dela en realtidsrapport publicerar du först tillbaka till Power BI-tjänst. Sedan kan du konfigurera dina autentiseringsuppgifter för dataflödet för den semantiska modellen och dela.
Dricks
Om rapporten inte uppdateras så snabbt som du behöver den för att vara eller i realtid kan du läsa dokumentationen för automatisk siduppdatering. Följ vanliga frågor och svar och felsökningsanvisningarna för att ta reda på varför det här problemet kan inträffa.
Beaktanden och begränsningar
Allmänna begränsningar
- En Power BI Premium-prenumeration (kapacitet eller PPU) krävs för att skapa och köra strömmande dataflöden.
- Endast en typ av dataflöde tillåts per arbetsyta.
- Det går inte att länka vanliga dataflöden och strömmande dataflöden.
- Kapaciteter som är mindre än A3 tillåter inte användning av strömmande dataflöden.
- Om dataflöden eller den förbättrade beräkningsmotorn inte är aktiverad i en klientorganisation kan du inte skapa eller köra strömmande dataflöden.
- Arbetsytor som är anslutna till ett lagringskonto stöds inte.
- Varje strömmande dataflöde kan ge upp till 1 MB per sekund dataflöde.
Tillgänglighet
Förhandsversionen av strömmande dataflöden är inte tillgänglig i följande regioner:
- Indien, centrala
- Tyskland, norra
- Norge, östra
- Norge, västra
- Förenade Arabemiraten, centrala
- Sydafrika, norra
- Sydafrika, västra
- Schweiz, norra
- Schweiz, västra
- Brasilien, sydöstra
Licensiering
Antalet strömmande dataflöden som tillåts per klient beror på vilken licens som används:
För vanliga kapaciteter använder du följande formel för att beräkna det maximala antalet strömmande dataflöden som tillåts i en kapacitet:
Maximalt antal strömmande dataflöden per kapacitet = virtuella kärnor i kapaciteten x 5
P1 har till exempel 8 virtuella kärnor: 8 * 5 = 40 strömmande dataflöden.
För Premium per användare tillåts ett strömmande dataflöde per användare. Om en annan användare vill använda ett strömmande dataflöde på en PPU-arbetsyta behöver de också en PPU-licens.
Redigering av dataflöde
När du redigerar strömmande dataflöden bör du tänka på följande:
- Ägaren till strömmande dataflöden kan bara göra ändringar och de kan bara göra ändringar om dataflödet inte körs.
- Strömmande dataflöden är inte tillgängliga i Min arbetsyta.
Ansluta från Power BI Desktop
Du kan endast komma åt kall lagring med hjälp av dataflödesanslutningsappen som är tillgänglig från och med juli 2021 Power BI Desktop-uppdateringen. Den tidigare Power BI-dataflödesanslutningen tillåter endast anslutningar till strömmande datalagring (frekvent). Anslutningsappens dataförhandsgranskning fungerar inte.
Relaterat innehåll
Den här artikeln innehåller en översikt över förberedelse av direktuppspelning via självbetjäning med hjälp av strömmande dataflöden. Följande artiklar innehåller information om hur du testar den här funktionen och hur du använder andra funktioner för strömmande data i Power BI: