SQL Graph-arkitektur
gäller för:![]() SQL Server 2017 (14.x) och senare versioner
SQL Server 2017 (14.x) och senare versioner ![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() SQL-databas i Microsoft Fabric
SQL-databas i Microsoft Fabric
Lär dig mer om arkitekturen i SQL Graph. Genom att känna till grunderna blir det lättare att förstå andra SQL Graph-artiklar.
Användare kan skapa ett diagram per databas. Ett diagram är en samling nod- och kanttabeller. Nod- eller kanttabeller kan skapas under valfritt schema i databasen, men alla tillhör ett logiskt diagram. En nodtabell är en samling av liknande typer av noder. En Person nodtabell innehåller till exempel alla Person noder som tillhör en graf. På samma sätt är en kanttabell en samling av liknande typer av kanter. En Friends kanttabell innehåller till exempel alla kanter som ansluter en Person till en annan Person. Eftersom noder och kanter lagras i tabeller stöds de flesta åtgärder som stöds i vanliga tabeller i nod- eller kanttabeller.
Följande diagram visar SQL Graph-databasarkitekturen.
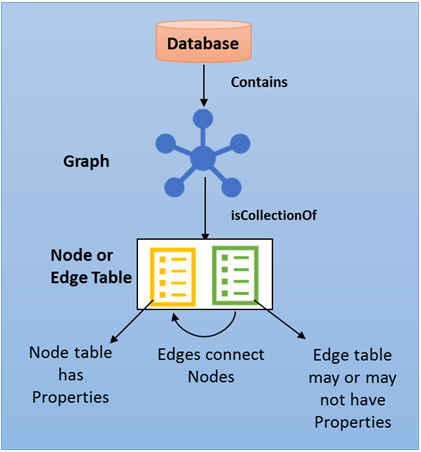
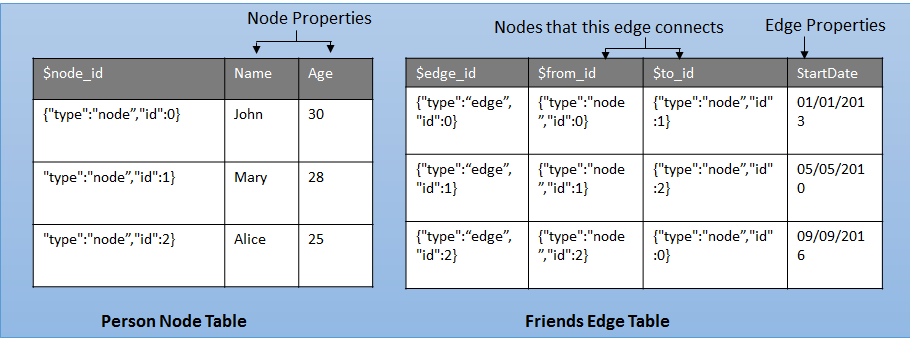
En nodtabell representerar en entitet i ett grafschema. Varje gång en nodtabell skapas, tillsammans med de användardefinierade kolumnerna, skapas en implicit $node_id kolumn som unikt identifierar en viss nod i databasen. Värdena i $node_id genereras automatiskt och är en kombination av objekt-ID för graftabellen i nodtabellen och ett internt genererat bigint- värde. Men när kolumnen $node_id har valts visas ett beräknat värde i form av en JSON-sträng. Dessutom är $node_id en pseudokolumn som mappar till ett internt namn med ett unikt suffix. När du väljer $node_id pseudokolumn från tabellen visas kolumnnamnet som $node_id_<unique suffix>.
Anteckning
Att använda pseudokolumnerna i frågor är det enda sätt som stöds och rekommenderas att köra frågor mot den interna $node_id kolumnen. Du bör inte använda $node_id_<hex_string> kolumner direkt i några frågor.
Dessutom är den beräknade JSON-representationen som visas i pseudokolumnerna en implementeringsinformation. Du bör inte ha ett direkt beroende av formatet för den JSON-representationen. Om du måste hantera den här JSON-representationen bör du överväga att använda NODE_ID_FROM_PARTS() och andra relaterade System Functions.
Vi rekommenderar inte att du använder grafens pseudokolumner direkt ($node_id, $from_id, $to_id) i predikat. Till exempel bör ett predikat som n.$node_id = e.$from_id undvikas. Sådana jämförelser tenderar att vara ineffektiva på grund av konverteringen till JSON-representationen. Förlita dig i stället på FUNKTIONEN MATCH så långt det är möjligt.
Vi rekommenderar att användarna skapar ett unikt villkor eller index i kolumnen $node_id när nodtabellen skapas, men om en inte skapas skapas automatiskt ett unikt, icke-grupperat standardindex. Ett index i en grafs pseudokolumn skapas dock på de underliggande interna kolumnerna. Ett index som skapats i kolumnen $node_id visas alltså i den interna graph_id_<hex_string> kolumnen.
En kanttabell representerar en relation i ett diagram. Kanter dirigeras alltid och ansluter två noder. Med en gränstabell kan användarna modellera många-till-många-relationer i diagrammet. Användardefinierade kolumner ("attribut") är valfria i en kanttabell. Varje gång en gränstabell skapas, tillsammans med de användardefinierade kolumnerna, skapas tre implicita kolumner i gränstabellen:
| Kolumnnamn | Beskrivning |
|---|---|
$edge_id |
Identifierar unikt en angiven kant i databasen. Det är en genererad kolumn och värdet är en kombination av object_id av kanttabellen och ett internt genererat bigint- värde. Men när kolumnen $edge_id har valts visas ett beräknat värde i form av en JSON-sträng.
$edge_id är en pseudokolumn som mappar till ett internt namn med ett unikt suffix. När du väljer $edge_id från tabellen visas kolumnnamnet som $edge_id_<unique suffix>. Att använda pseudokolumnnamn i frågor är det rekommenderade sättet att fråga den interna $edge_id kolumnen och använda internt namn med hexsträng bör undvikas. |
$from_id |
Lagrar nodens $node_id, varifrån gränsen kommer. |
$to_id |
Lagrar nodens $node_id, där gränsen avslutas. |
Noderna som en viss kant kan ansluta till styrs av de data som infogas i kolumnerna $from_id och $to_id. I den första versionen går det inte att definiera begränsningar i gränstabellen, för att begränsa den från att ansluta två typer av noder. En kant kan alltså ansluta två noder i diagrammet, oavsett typ.
På samma sätt som i kolumnen $node_id rekommenderar vi att användarna skapar ett unikt index eller en begränsning för kolumnen $edge_id när gränstabellen skapas, men om en inte skapas skapas ett unikt, icke-grupperat standardindex automatiskt i den här kolumnen. Ett index i en grafs pseudokolumn skapas dock på de underliggande interna kolumnerna. Ett index som skapats i kolumnen $edge_id visas alltså i den interna graph_id_<unique suffix> kolumnen. För OLTP-scenarier rekommenderar vi också att användarna skapar ett index för kolumnerna ($from_id, $to_id) för snabbare sökningar i gränsens riktning.
Följande diagram visar hur nod- och kanttabeller lagras i databasen.
Använd dessa metadatavyer för att se attribut för en nod eller gränstabell.
Följande bit kolumner i sys.tables kan användas för att identifiera graftabeller. Om is_node är inställt på 1 är tabellen en nodtabell, och om is_edge är inställt på 1 är tabellen en kanttabell.
| Kolumnnamn | Datatyp | Beskrivning |
|---|---|---|
| is_node | bit | För nodtabeller är is_node inställt på 1. |
| is_edge | bit | För kanttabeller är is_edge inställt på 1. |
Kolumnerna graph_type och graph_type_desc i sys.columns-vyn är användbara för att förstå de olika typerna av kolumner som används i diagramnoder och kanttabeller:
| Kolumnnamn | Datatyp | Beskrivning |
|---|---|---|
| graph_type | Int | Intern kolumn med en uppsättning värden. Värdena är mellan 1 och 8 för grafkolumner och NULL för andra. |
| graph_type_desc | nvarchar(60) | Intern kolumn med en uppsättning värden. |
I följande tabell visas giltiga värden för graph_type kolumn:
| Kolumnvärde | Beskrivning |
|---|---|
| 1 | GRAPH_ID |
| 2 | GRAPH_ID_COMPUTED |
| 3 | GRAPH_FROM_ID |
| 4 | GRAPH_FROM_OBJ_ID |
| 5 | GRAPH_FROM_ID_COMPUTED |
| 6 | GRAPH_TO_ID |
| 7 | GRAPH_TO_OBJ_ID |
| 8 | GRAPH_TO_ID_COMPUTED |
sys.columns lagrar även information om implicita kolumner som skapats i nod- eller kanttabeller. Följande information kan hämtas från sys.columns, men användarna kan inte välja dessa kolumner från en nod eller kanttabell.
De implicita kolumnerna i en nodtabell är:
| Kolumnnamn | Datatyp | is_hidden | Kommentar |
|---|---|---|---|
graph_id_\<hex_string> |
BIGINT | 1 | Internt diagram-ID-värde. |
$node_id_\<hex_string> |
NVARCHAR | 0 | Extern teckenrepresentation av nod-ID:t. |
De implicita kolumnerna i en kanttabell är:
| Kolumnnamn | Datatyp | is_hidden | Kommentar |
|---|---|---|---|
graph_id_\<hex_string> |
BIGINT | 1 | Internt diagram-ID-värde. |
$edge_id_\<hex_string> |
NVARCHAR | 0 | Teckenrepresentation av kant-ID:t. |
from_obj_id_\<hex_string> |
INT | 1 | Internt object_id värde för "från noden". |
from_id_\<hex_string> |
BIGINT | 1 | Internt diagram-ID-värde för "från noden". |
$from_id_\<hex_string> |
NVARCHAR | 0 | teckenrepresentation av "från noden". |
to_obj_id_\<hex_string> |
INT | 1 | Intern object_id för "till-noden". |
to_id_\<hex_string> |
BIGINT | 1 | Internt graf-ID-värde för "till-noden". |
$to_id_\<hex_string> |
NVARCHAR | 0 | Extern teckenrepresentation av "till noden". |
Du kan använda följande inbyggda funktioner för att interagera med pseudokolumnerna i graftabeller. Detaljerade referenser finns för var och en av dessa funktioner i respektive T-SQL-funktionsreferenser.
| Inbyggd | Beskrivning |
|---|---|
| OBJECT_ID_FROM_NODE_ID | Extrahera objekt-ID:t för graftabellen från en node_id. |
| GRAPH_ID_FROM_NODE_ID | Extrahera graf-ID-värdet från en node_id. |
| NODE_ID_FROM_PARTS | Konstruera en node_id från ett objekt-ID för graftabellen och ett diagram-ID-värde. |
| OBJECT_ID_FROM_EDGE_ID | Extrahera objekt-ID för graftabellen från edge_id. |
| GRAPH_ID_FROM_EDGE_ID | Extrahera graf-ID-värdet för en viss edge_id. |
| EDGE_ID_FROM_PARTS | Konstruera edge_id från objekt-ID för graftabell- och graf-ID-värdet. |
Lär dig Transact-SQL tillägg som introduceras i SQL Server och Azure SQL Database som gör det möjligt att skapa och köra frågor mot grafobjekt. Frågespråktilläggen hjälper till att fråga och bläddra i diagrammet med hjälp av ASCII-konstsyntax.
| Uppgift | Relaterad artikel | Anteckningar |
|---|---|---|
| SKAPA TABELL | CREATE TABLE (Transact-SQL) |
CREATE TABLE utökas nu för att skapa en tabell som nod eller AS EDGE. En gränstabell krävs inte för att ha några användardefinierade attribut. |
| ALTER TABLE | ALTER TABLE (Transact-SQL) | Nod- och kanttabeller kan ändras på samma sätt som en relationstabell, med hjälp av ALTER TABLE. Användare kan lägga till eller ändra användardefinierade kolumner, index eller begränsningar. Att ändra interna grafkolumner, till exempel $node_id eller $edge_id, resulterar dock i ett fel. |
| SKAPA INDEX | CREATE INDEX (Transact-SQL) | Användare kan skapa index på pseudokolumner och användardefinierade kolumner i nod- och kanttabeller. Alla indextyper stöds, inklusive grupperade och icke-grupperade kolumnlagringsindex. |
| SKAPA GRÄNSBEGRÄNSNINGAR | EDGE-begränsningar (Transact-SQL) | Användare kan nu skapa gränsbegränsningar för gränstabeller för att framtvinga specifika semantik och även upprätthålla dataintegritet |
| TA BORT TABELL | DROP TABLE (Transact-SQL) | Nod- och kanttabeller kan tas bort på samma sätt som en relationstabell, med hjälp av DROP TABLE. För närvarande finns det inga mekanismer för att förhindra borttagning av noder, som refereras till av kanter. Det finns inget stöd för kaskadborttagning av kanter vid borttagning av en nod (eller genom att ta bort hela nodtabellen). I alla sådana fall måste alla kanter som är anslutna till de borttagna noderna tas bort manuellt för att upprätthålla diagrammets konsekvens. |
| Uppgift | Relaterad artikel | Anteckningar |
|---|---|---|
| INFOGA | INSERT (Transact-SQL) | Att infoga i en nodtabell skiljer sig inte från att infogas i en relationstabell. Värdena för $node_id kolumn genereras automatiskt. Om du försöker infoga ett värde i $node_id eller $edge_id kolumn uppstår ett fel. Användarna måste ange värden för $from_id och $to_id kolumner när de infogar i en kanttabell.
$from_id och $to_id är de $node_id värdena för noderna som en viss kant ansluter till. |
| TA BORT | DELETE (Transact-SQL) | Data från nod- eller kanttabeller kan tas bort på samma sätt som de tas bort från relationstabeller. I den här versionen finns det dock inga begränsningar för att se till att inga kanter pekar på en borttagen nod och att kanterna tas bort, när en nod tas bort stöds inte. Vi rekommenderar att alla anslutningskanter till noden tas bort när en nod tas bort. |
| UPPDATERA | UPDATE (Transact-SQL) | Värden i användardefinierade kolumner kan uppdateras med update-instruktionen. Du kan inte uppdatera de interna grafkolumnerna, $node_id, $edge_id, $from_id och $to_id. |
| SLÅ IHOP | MERGE (Transact-SQL) |
MERGE-instruktionen stöds på en nod eller kanttabell. |
| Uppgift | Relaterad artikel | Anteckningar |
|---|---|---|
| UTVALD | SELECT (Transact-SQL) | Eftersom noder och kanter lagras som tabeller stöds de flesta tabellåtgärder också på nod- och kanttabeller. |
| TÄNDSTICKA | MATCH (Transact-SQL) | DEN inbyggda MATCH-koden introduceras för att stödja mönstermatchning och bläddering genom grafen. |
Det finns vissa begränsningar för nod- och kanttabeller:
- Lokala eller globala temporära tabeller kan inte vara nod- eller kanttabeller.
- Tabelltyper och tabellvariabler kan inte deklareras som en nod- eller kanttabell.
- Nod- och kanttabeller kan inte skapas som systemversionsbaserade temporala tabeller.
- Nod- och kanttabeller kan inte vara minnesoptimerade tabeller.
- Användare kan inte uppdatera kolumnerna
$from_idoch$to_idför en kant med update-instruktionen. Om du vill uppdatera noder som refereras till av en kant måste användarna infoga en ny kant som pekar på nya noder och ta bort den föregående. - Frågor mellan databaser på grafobjekt stöds inte.
- Pseudokolumner (
node_id,$from_id,$to_idochedge_id) kan inte användas som sorteringskolumner för ett ordnat grupperat kolumnlagringsindex. Försök att använda graf-pseudokolumner som sorteringskolumner för ordnat grupperat kolumnarkiv resulterar i ettMsg 102: Incorrect syntaxfel. - I SQL-databas för infrastrukturresursertillåts SQL Graph, men Nod- och Edge-tabeller speglas inte i Fabric OneLake.
- Information om hur du kommer igång med SQL Graph finns i SQL Graph Database – Exempel